 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Vendor CT Image Data Harmonization Using CVH-CT
Oct 19, 2021
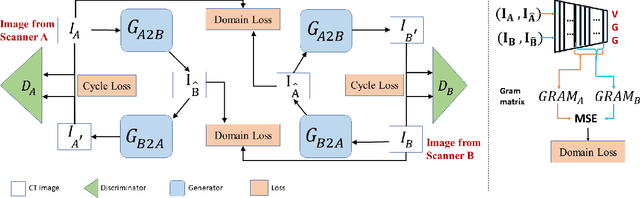

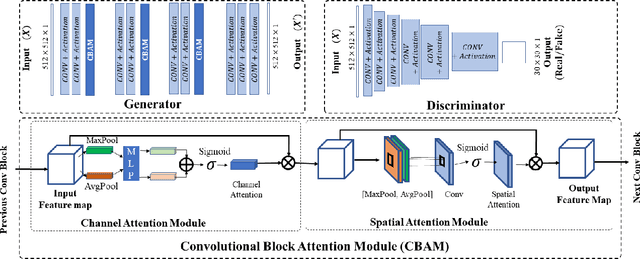
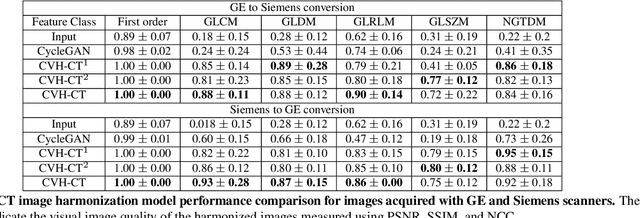
While remarkable advances have been made in Computed Tomography (CT), most of the existing efforts focus on imaging enhancement while reducing radiation dose. How to harmonize CT image data captured using different scanners is vital in cross-center large-scale radiomics studies but remains the boundary to explore. Furthermore, the lack of paired training image problem makes it computationally challenging to adopt existing deep learning models. %developed for CT image standardization. %this problem more challenging. We propose a novel deep learning approach called CVH-CT for harmonizing CT images captured using scanners from different vendors. The generator of CVH-CT uses a self-attention mechanism to learn the scanner-related information. We also propose a VGG feature-based domain loss to effectively extract texture properties from unpaired image data to learn the scanner-based texture distributions. The experimental results show that CVH-CT is clearly better than the baselines because of the use of the proposed domain loss, and CVH-CT can effectively reduce the scanner-related variability in terms of radiomic features.
Discriminative Latent Semantic Graph for Video Captioning
Aug 10, 2021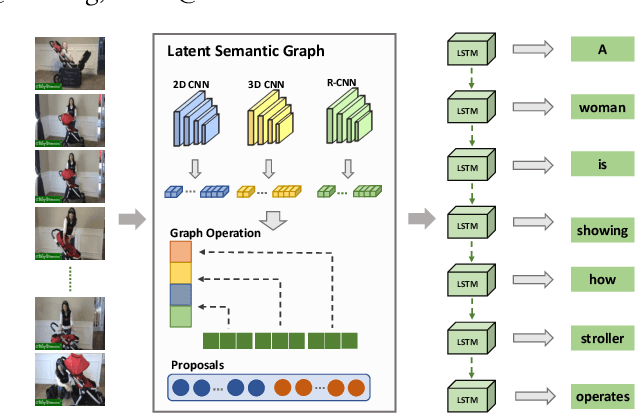
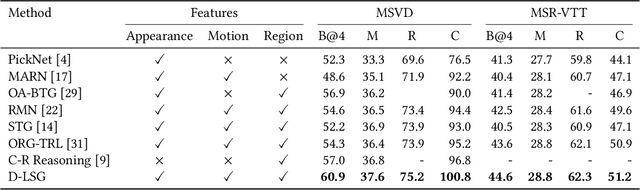
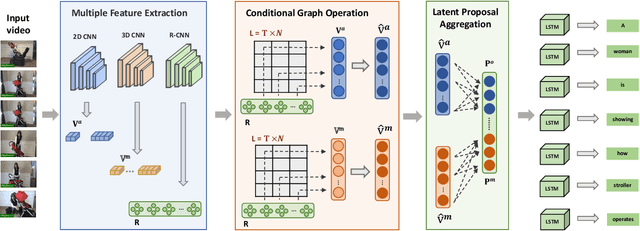
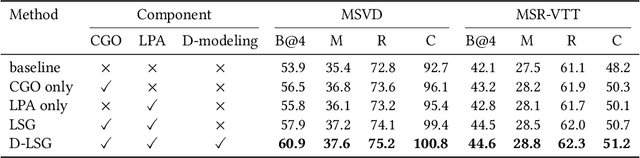
Video captioning aims to automatically generate natural language sentences that can describe the visual contents of a given video. Existing generative models like encoder-decoder frameworks cannot explicitly explore the object-level interactions and frame-level information from complex spatio-temporal data to generate semantic-rich captions. Our main contribution is to identify three key problems in a joint framework for future video summarization tasks. 1) Enhanced Object Proposal: we propose a novel Conditional Graph that can fuse spatio-temporal information into latent object proposal. 2) Visual Knowledge: Latent Proposal Aggregation is proposed to dynamically extract visual words with higher semantic levels. 3) Sentence Validation: A novel Discriminative Language Validator is proposed to verify generated captions so that key semantic concepts can be effectively preserved. Our experiments on two public datasets (MVSD and MSR-VTT) manifest significant improvements over state-of-the-art approaches on all metrics, especially for BLEU-4 and CIDEr. Our code is available at https://github.com/baiyang4/D-LSG-Video-Caption.
Frame-level multi-channel speaker verification with large-scale ad-hoc microphone arrays
Oct 12, 2021Automatic speaker verification (ASV) with ad-hoc microphone arrays has received attention. Unlike traditional microphone arrays, the number of microphones and their spatial arrangement in an ad-hoc microphone array is unknown, which makes conventional multi-channel ASV techniques ineffective in ad-hoc microphone array settings. Recently, an utterance-level ASV with ad-hoc microphone arrays has been proposed, which first extracts utterance-level speaker embeddings from each channel of an ad-hoc microphone array, and then fuses the embeddings for the final verification. However, this method cannot make full use of the cross-channel information. In this paper, we present a novel multi-channel ASV model at the frame-level. Specifically, we add spatio-temporal processing blocks (STB) before the pooling layer, which models the contextual relationship within and between channels and across time, respectively. The channel-attended outputs from STB are sent to the pooling layer to obtain an utterance-level speaker representation. Experimental results demonstrate the effectiveness of the proposed method.
Improving Distantly-Supervised Named Entity Recognition with Self-Collaborative Denoising Learning
Oct 09, 2021
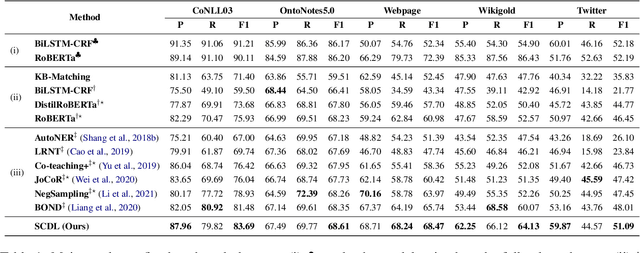
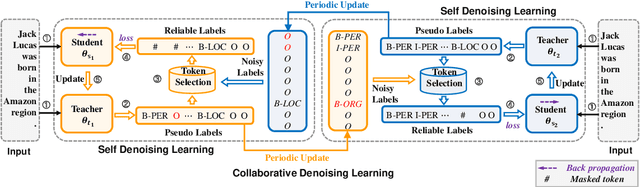
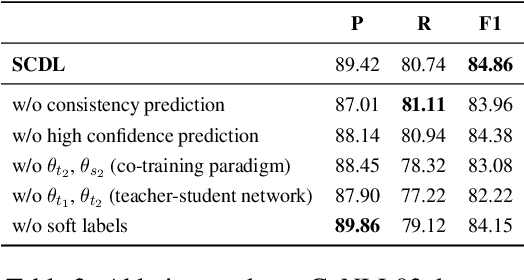
Distantly supervised named entity recognition (DS-NER) efficiently reduces labor costs but meanwhile intrinsically suffers from the label noise due to the strong assumption of distant supervision. Typically, the wrongly labeled instances comprise numbers of incomplete and inaccurate annotation noise, while most prior denoising works are only concerned with one kind of noise and fail to fully explore useful information in the whole training set. To address this issue, we propose a robust learning paradigm named Self-Collaborative Denoising Learning (SCDL), which jointly trains two teacher-student networks in a mutually-beneficial manner to iteratively perform noisy label refinery. Each network is designed to exploit reliable labels via self denoising, and two networks communicate with each other to explore unreliable annotations by collaborative denoising. Extensive experimental results on five real-world datasets demonstrate that SCDL is superior to state-of-the-art DS-NER denoising methods.
Multi-way Clustering and Discordance Analysis through Deep Collective Matrix Tri-Factorization
Sep 27, 2021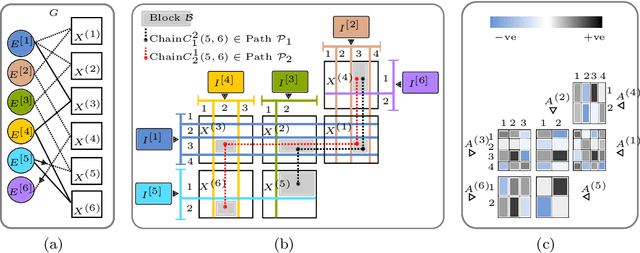
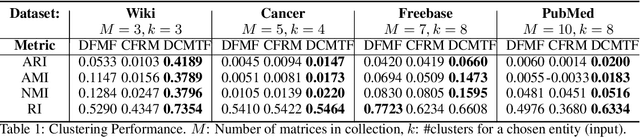
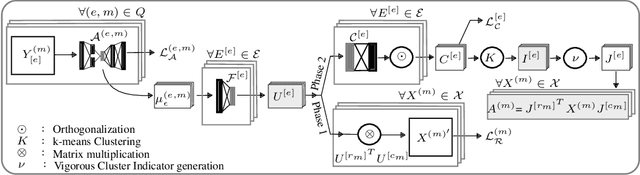
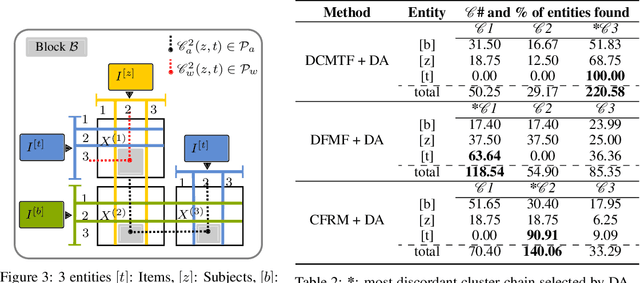
Heterogeneous multi-typed, multimodal relational data is increasingly available in many domains and their exploratory analysis poses several challenges. We advance the state-of-the-art in neural unsupervised learning to analyze such data. We design the first neural method for collective matrix tri-factorization of arbitrary collections of matrices to perform spectral clustering of all constituent entities and learn cluster associations. Experiments on benchmark datasets demonstrate its efficacy over previous non-neural approaches. Leveraging signals from multi-way clustering and collective matrix completion we design a unique technique, called Discordance Analysis, to reveal information discrepancies across subsets of matrices in a collection with respect to two entities. We illustrate its utility in quality assessment of knowledge bases and in improving representation learning.
A Systematic Review on the Detection of Fake News Articles
Oct 18, 2021
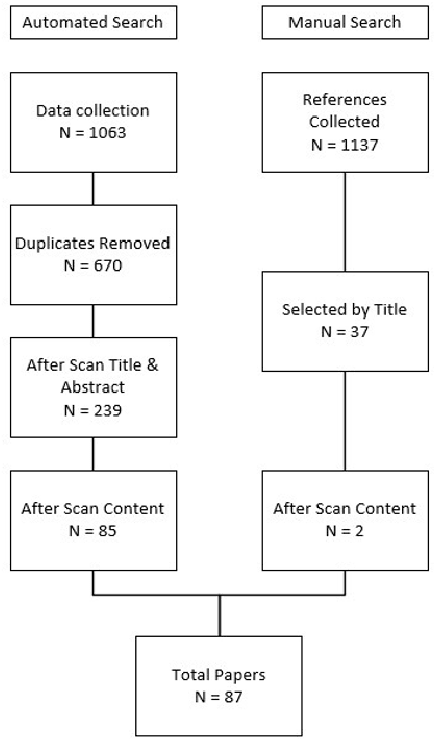
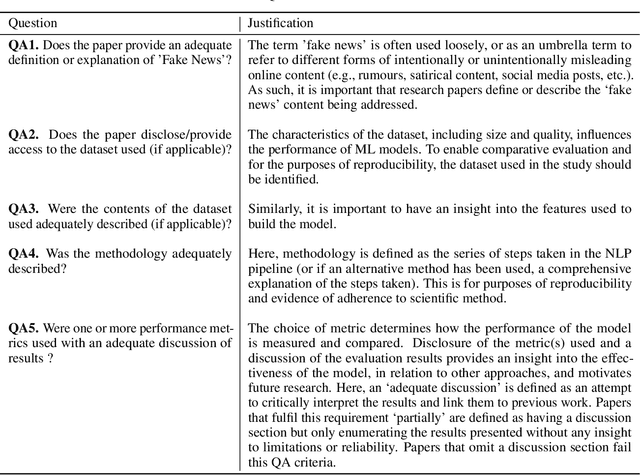
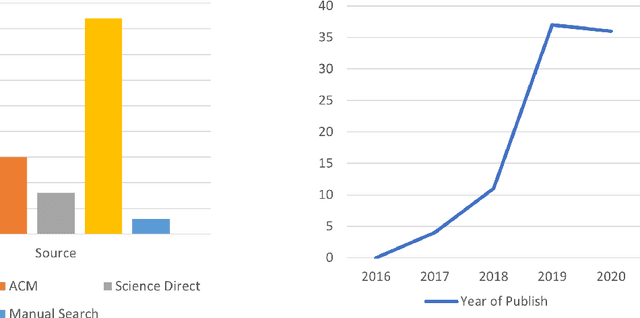
It has been argued that fake news and the spread of false information pose a threat to societies throughout the world, from influencing the results of elections to hindering the efforts to manage the COVID-19 pandemic. To combat this threat, a number of Natural Language Processing (NLP) approaches have been developed. These leverage a number of datasets, feature extraction/selection techniques and machine learning (ML) algorithms to detect fake news before it spreads. While these methods are well-documented, there is less evidence regarding their efficacy in this domain. By systematically reviewing the literature, this paper aims to delineate the approaches for fake news detection that are most performant, identify limitations with existing approaches, and suggest ways these can be mitigated. The analysis of the results indicates that Ensemble Methods using a combination of news content and socially-based features are currently the most effective. Finally, it is proposed that future research should focus on developing approaches that address generalisability issues (which, in part, arise from limitations with current datasets), explainability and bias.
Visual Question Answering based on Formal Logic
Nov 08, 2021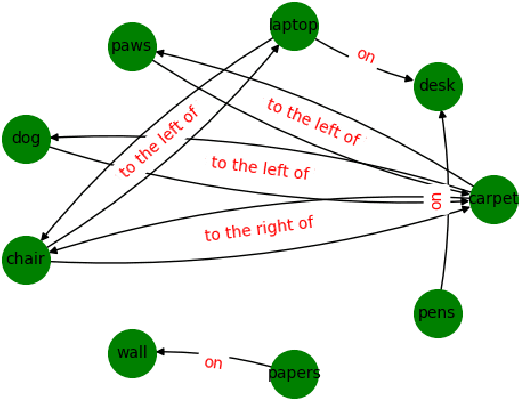

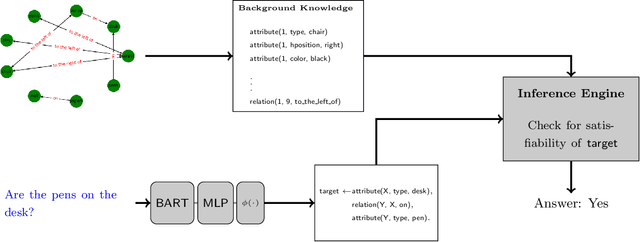
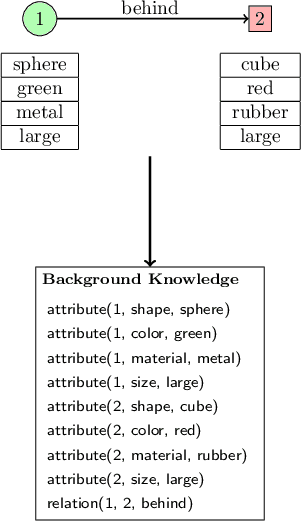
Visual question answering (VQA) has been gaining a lot of traction in the machine learning community in the recent years due to the challenges posed in understanding information coming from multiple modalities (i.e., images, language). In VQA, a series of questions are posed based on a set of images and the task at hand is to arrive at the answer. To achieve this, we take a symbolic reasoning based approach using the framework of formal logic. The image and the questions are converted into symbolic representations on which explicit reasoning is performed. We propose a formal logic framework where (i) images are converted to logical background facts with the help of scene graphs, (ii) the questions are translated to first-order predicate logic clauses using a transformer based deep learning model, and (iii) perform satisfiability checks, by using the background knowledge and the grounding of predicate clauses, to obtain the answer. Our proposed method is highly interpretable and each step in the pipeline can be easily analyzed by a human. We validate our approach on the CLEVR and the GQA dataset. We achieve near perfect accuracy of 99.6% on the CLEVR dataset comparable to the state of art models, showcasing that formal logic is a viable tool to tackle visual question answering. Our model is also data efficient, achieving 99.1% accuracy on CLEVR dataset when trained on just 10% of the training data.
Topic Modeling Based Extractive Text Summarization
Jun 29, 2021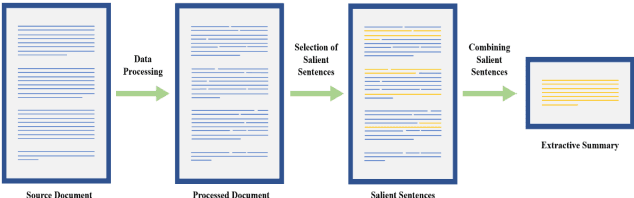
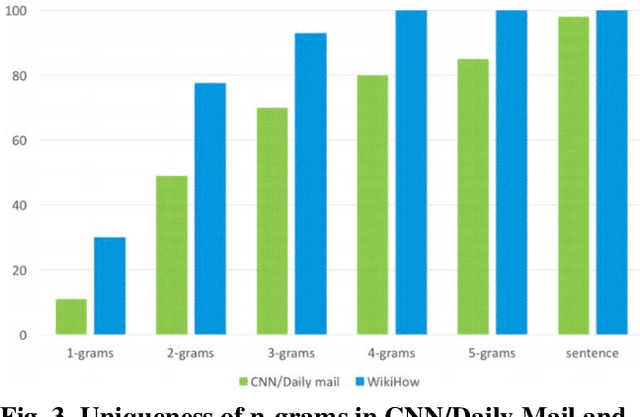
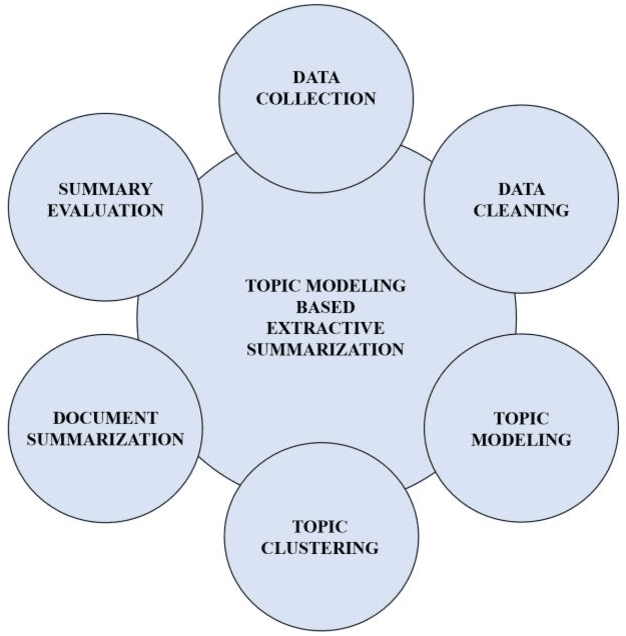
Text summarization is an approach for identifying important information present within text documents. This computational technique aims to generate shorter versions of the source text, by including only the relevant and salient information present within the source text. In this paper, we propose a novel method to summarize a text document by clustering its contents based on latent topics produced using topic modeling techniques and by generating extractive summaries for each of the identified text clusters. All extractive sub-summaries are later combined to generate a summary for any given source document. We utilize the lesser used and challenging WikiHow dataset in our approach to text summarization. This dataset is unlike the commonly used news datasets which are available for text summarization. The well-known news datasets present their most important information in the first few lines of their source texts, which make their summarization a lesser challenging task when compared to summarizing the WikiHow dataset. Contrary to these news datasets, the documents in the WikiHow dataset are written using a generalized approach and have lesser abstractedness and higher compression ratio, thus proposing a greater challenge to generate summaries. A lot of the current state-of-the-art text summarization techniques tend to eliminate important information present in source documents in the favor of brevity. Our proposed technique aims to capture all the varied information present in source documents. Although the dataset proved challenging, after performing extensive tests within our experimental setup, we have discovered that our model produces encouraging ROUGE results and summaries when compared to the other published extractive and abstractive text summarization models.
* 10 pages, 13 figures, 3 tables
Meaning to Form: Measuring Systematicity as Information
Jun 13, 2019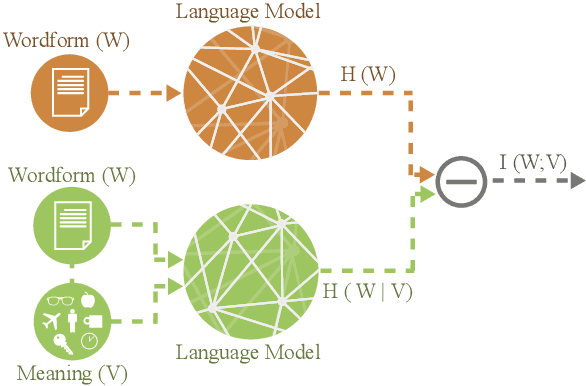
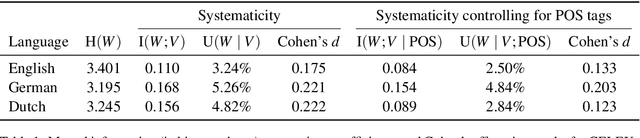
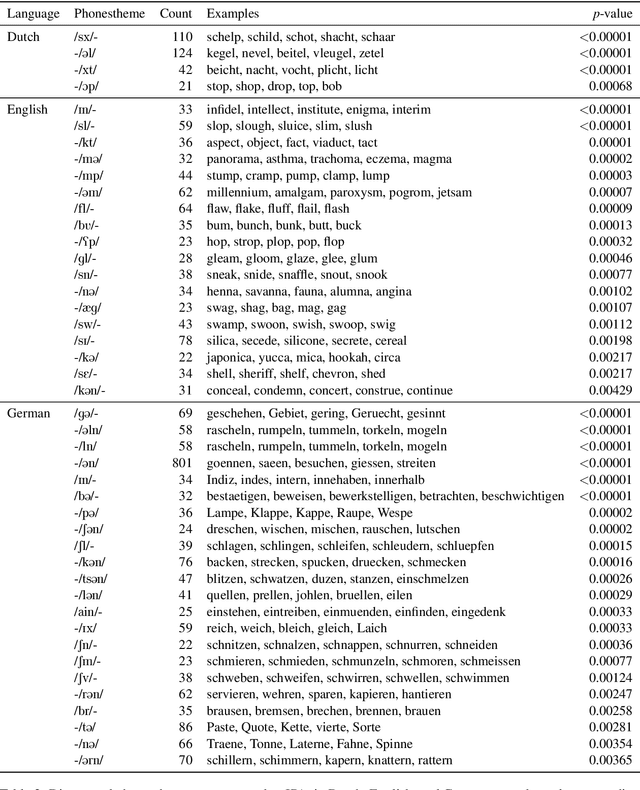
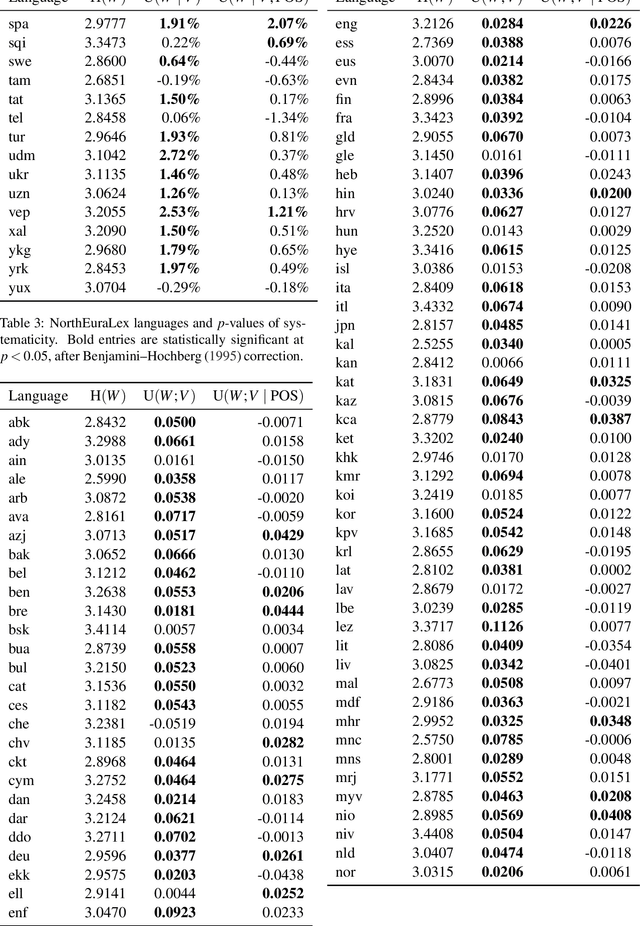
A longstanding debate in semiotics centers on the relationship between linguistic signs and their corresponding semantics: is there an arbitrary relationship between a word form and its meaning, or does some systematic phenomenon pervade? For instance, does the character bigram \textit{gl} have any systematic relationship to the meaning of words like \textit{glisten}, \textit{gleam} and \textit{glow}? In this work, we offer a holistic quantification of the systematicity of the sign using mutual information and recurrent neural networks. We employ these in a data-driven and massively multilingual approach to the question, examining 106 languages. We find a statistically significant reduction in entropy when modeling a word form conditioned on its semantic representation. Encouragingly, we also recover well-attested English examples of systematic affixes. We conclude with the meta-point: Our approximate effect size (measured in bits) is quite small---despite some amount of systematicity between form and meaning, an arbitrary relationship and its resulting benefits dominate human language.
Towards Real-world X-ray Security Inspection: A High-Quality Benchmark and Lateral Inhibition Module for Prohibited Items Detection
Aug 23, 2021
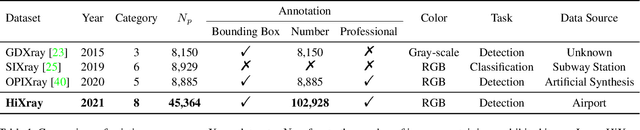
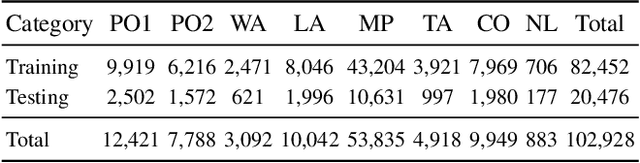

Prohibited items detection in X-ray images often plays an important role in protecting public safety, which often deals with color-monotonous and luster-insufficient objects, resulting in unsatisfactory performance. Till now, there have been rare studies touching this topic due to the lack of specialized high-quality datasets. In this work, we first present a High-quality X-ray (HiXray) security inspection image dataset, which contains 102,928 common prohibited items of 8 categories. It is the largest dataset of high quality for prohibited items detection, gathered from the real-world airport security inspection and annotated by professional security inspectors. Besides, for accurate prohibited item detection, we further propose the Lateral Inhibition Module (LIM) inspired by the fact that humans recognize these items by ignoring irrelevant information and focusing on identifiable characteristics, especially when objects are overlapped with each other. Specifically, LIM, the elaborately designed flexible additional module, suppresses the noisy information flowing maximumly by the Bidirectional Propagation (BP) module and activates the most identifiable charismatic, boundary, from four directions by Boundary Activation (BA) module. We evaluate our method extensively on HiXray and OPIXray and the results demonstrate that it outperforms SOTA detection methods.