 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LMVP: Video Predictor with Leaked Motion Information
Jun 24, 2019
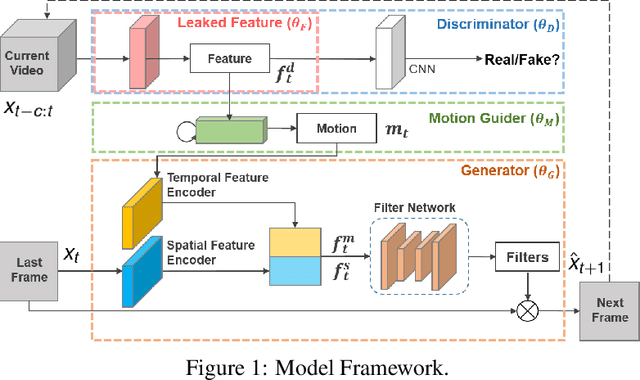
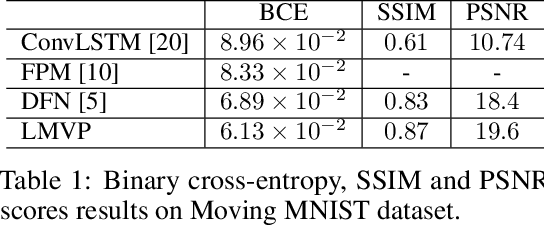


We propose a Leaked Motion Video Predictor (LMVP) to predict future frames by capturing the spatial and temporal dependencies from given inputs. The motion is modeled by a newly proposed component, motion guider, which plays the role of both learner and teacher. Specifically, it {\em learns} the temporal features from real data and {\em guides} the generator to predict future frames. The spatial consistency in video is modeled by an adaptive filtering network. To further ensure the spatio-temporal consistency of the prediction, a discriminator is also adopted to distinguish the real and generated frames. Further, the discriminator leaks information to the motion guider and the generator to help the learning of motion. The proposed LMVP can effectively learn the static and temporal features in videos without the need for human labeling. Experiments on synthetic and real data demonstrate that LMVP can yield state-of-the-art results.
M2A: Motion Aware Attention for Accurate Video Action Recognition
Nov 18, 2021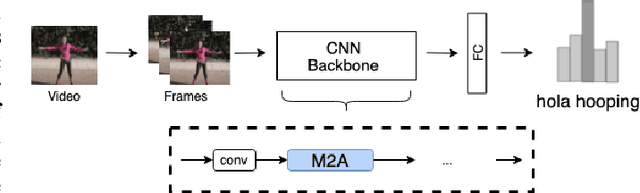
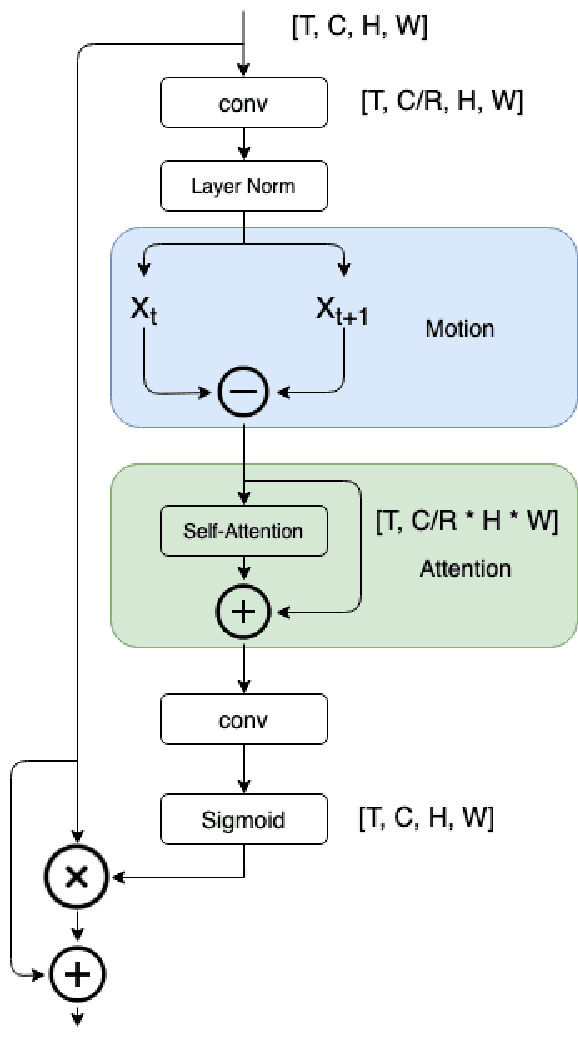


Advancements in attention mechanisms have led to significant performance improvements in a variety of areas in machine learning due to its ability to enable the dynamic modeling of temporal sequences. A particular area in computer vision that is likely to benefit greatly from the incorporation of attention mechanisms in video action recognition. However, much of the current research's focus on attention mechanisms have been on spatial and temporal attention, which are unable to take advantage of the inherent motion found in videos. Motivated by this, we develop a new attention mechanism called Motion Aware Attention (M2A) that explicitly incorporates motion characteristics. More specifically, M2A extracts motion information between consecutive frames and utilizes attention to focus on the motion patterns found across frames to accurately recognize actions in videos. The proposed M2A mechanism is simple to implement and can be easily incorporated into any neural network backbone architecture. We show that incorporating motion mechanisms with attention mechanisms using the proposed M2A mechanism can lead to a +15% to +26% improvement in top-1 accuracy across different backbone architectures, with only a small increase in computational complexity. We further compared the performance of M2A with other state-of-the-art motion and attention mechanisms on the Something-Something V1 video action recognition benchmark. Experimental results showed that M2A can lead to further improvements when combined with other temporal mechanisms and that it outperforms other motion-only or attention-only mechanisms by as much as +60% in top-1 accuracy for specific classes in the benchmark.
Automated Human Mind Reading Using EEG Signals for Seizure Detection
Nov 05, 2021Epilepsy is one of the most occurring neurological disease globally emerged back in 4000 BC. It is affecting around 50 million people of all ages these days. The trait of this disease is recurrent seizures. In the past few decades, the treatments available for seizure control have improved a lot with the advancements in the field of medical science and technology. Electroencephalogram (EEG) is a widely used technique for monitoring the brain activity and widely popular for seizure region detection. It is performed before surgery and also to predict seizure at the time operation which is useful in neuro stimulation device. But in most of cases visual examination is done by neurologist in order to detect and classify patterns of the disease but this requires a lot of pre-domain knowledge and experience. This all in turns put a pressure on neurosurgeons and leads to time wastage and also reduce their accuracy and efficiency. There is a need of some automated systems in arena of information technology like use of neural networks in deep learning which can assist neurologists. In the present paper, a model is proposed to give an accuracy of 98.33% which can be used for development of automated systems. The developed system will significantly help neurologists in their performance.
* 11 Pages, 12 Figures, 5 Tables
Conditional Variational Autoencoder for Learned Image Reconstruction
Oct 25, 2021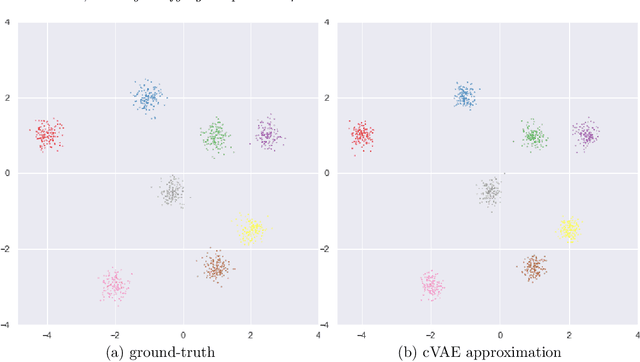

Learned image reconstruction techniques using deep neural networks have recently gained popularity, and have delivered promising empirical results. However, most approaches focus on one single recovery for each observation, and thus neglect the uncertainty information. In this work, we develop a novel computational framework that approximates the posterior distribution of the unknown image at each query observation. The proposed framework is very flexible: It handles implicit noise models and priors, it incorporates the data formation process (i.e., the forward operator), and the learned reconstructive properties are transferable between different datasets. Once the network is trained using the conditional variational autoencoder loss, it provides a computationally efficient sampler for the approximate posterior distribution via feed-forward propagation, and the summarizing statistics of the generated samples are used for both point-estimation and uncertainty quantification. We illustrate the proposed framework with extensive numerical experiments on positron emission tomography (with both moderate and low count levels) showing that the framework generates high-quality samples when compared with state-of-the-art methods.
Edge-Native Intelligence for 6G Communications Driven by Federated Learning: A Survey of Trends and Challenges
Nov 14, 2021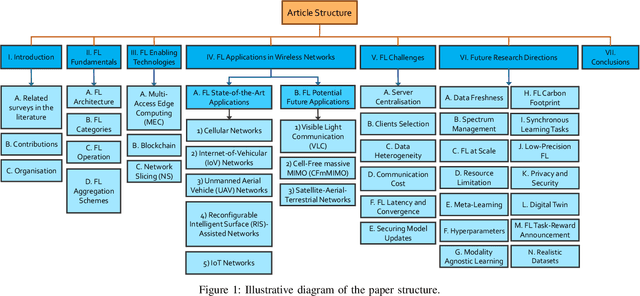
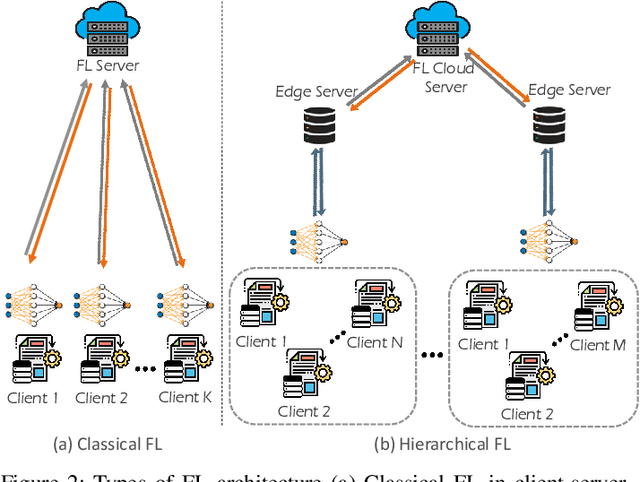
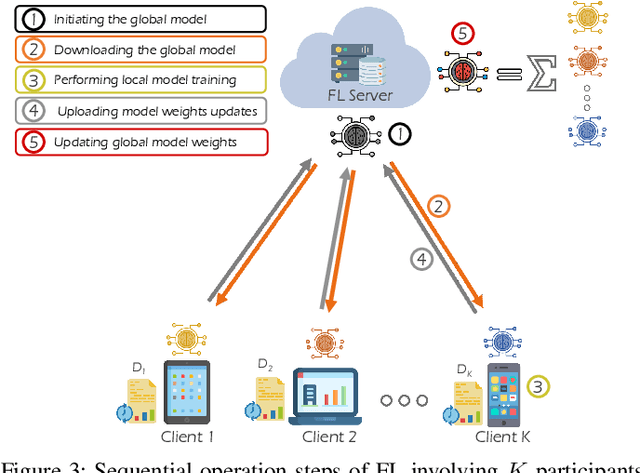
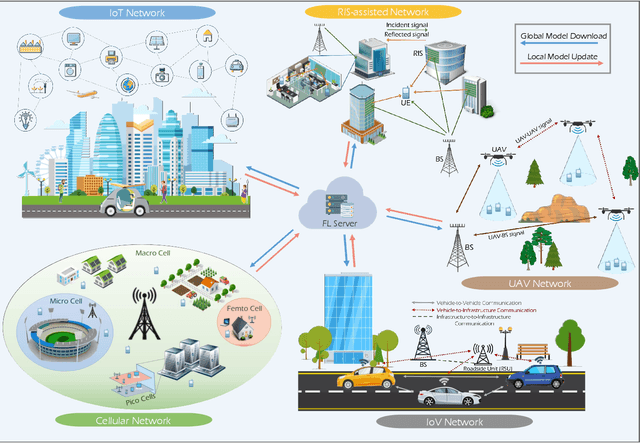
The unprecedented surge of data volume in wireless networks empowered with artificial intelligence (AI) opens up new horizons for providing ubiquitous data-driven intelligent services. Traditional cloud-centric machine learning (ML)-based services are implemented by collecting datasets and training models centrally. However, this conventional training technique encompasses two challenges: (i) high communication and energy cost due to increased data communication, (ii) threatened data privacy by allowing untrusted parties to utilise this information. Recently, in light of these limitations, a new emerging technique, coined as federated learning (FL), arose to bring ML to the edge of wireless networks. FL can extract the benefits of data silos by training a global model in a distributed manner, orchestrated by the FL server. FL exploits both decentralised datasets and computing resources of participating clients to develop a generalised ML model without compromising data privacy. In this article, we introduce a comprehensive survey of the fundamentals and enabling technologies of FL. Moreover, an extensive study is presented detailing various applications of FL in wireless networks and highlighting their challenges and limitations. The efficacy of FL is further explored with emerging prospective beyond fifth generation (B5G) and sixth generation (6G) communication systems. The purpose of this survey is to provide an overview of the state-of-the-art of FL applications in key wireless technologies that will serve as a foundation to establish a firm understanding of the topic. Lastly, we offer a road forward for future research directions.
Relation-aware Video Reading Comprehension for Temporal Language Grounding
Oct 18, 2021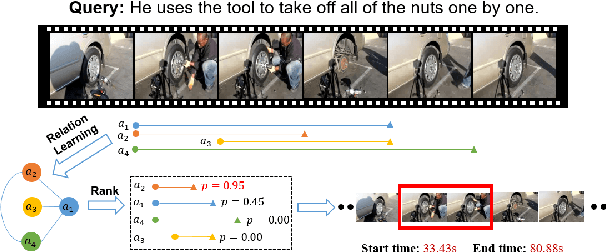
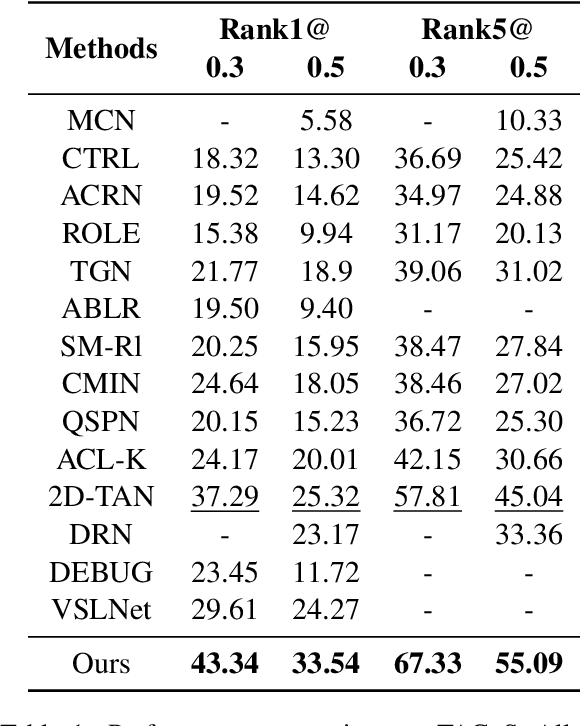
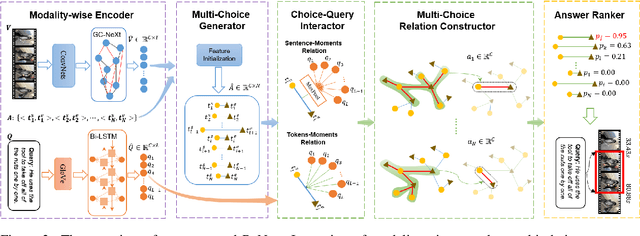
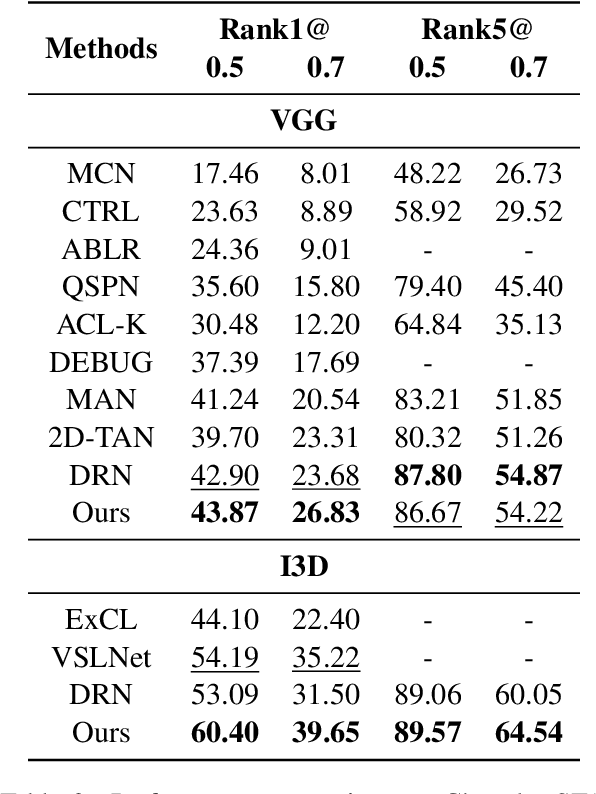
Temporal language grounding in videos aims to localize the temporal span relevant to the given query sentence. Previous methods treat it either as a boundary regression task or a span extraction task. This paper will formulate temporal language grounding into video reading comprehension and propose a Relation-aware Network (RaNet) to address it. This framework aims to select a video moment choice from the predefined answer set with the aid of coarse-and-fine choice-query interaction and choice-choice relation construction. A choice-query interactor is proposed to match the visual and textual information simultaneously in sentence-moment and token-moment levels, leading to a coarse-and-fine cross-modal interaction. Moreover, a novel multi-choice relation constructor is introduced by leveraging graph convolution to capture the dependencies among video moment choices for the best choice selection. Extensive experiments on ActivityNet-Captions, TACoS, and Charades-STA demonstrate the effectiveness of our solution. Codes will be released soon.
Privacy in Open Search: A Review of Challenges and Solutions
Oct 24, 2021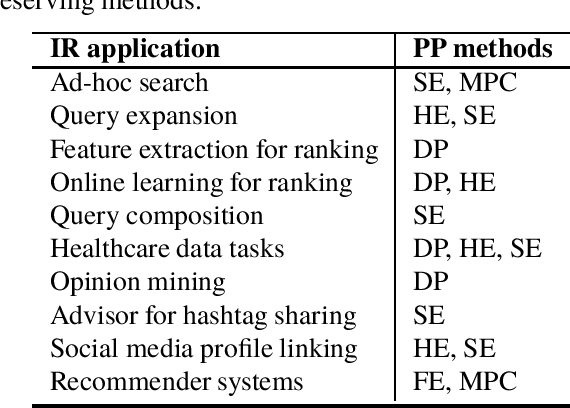
Privacy is of worldwide concern regarding activities and processes that include sensitive data. For this reason, many countries and territories have been recently approving regulations controlling the extent to which organizations may exploit data provided by people. Artificial intelligence areas, such as machine learning and natural language processing, have already successfully employed privacy-preserving mechanisms in order to safeguard data privacy in a vast number of applications. Information retrieval (IR) is likewise prone to privacy threats, such as attacks and unintended disclosures of documents and search history, which may cripple the security of users and be penalized by data protection laws. This work aims at highlighting and discussing open challenges for privacy in the recent literature of IR, focusing on tasks featuring user-generated text data. Our contribution is threefold: firstly, we present an overview of privacy threats to IR tasks; secondly, we discuss applicable privacy-preserving mechanisms which may be employed in solutions to restrain privacy hazards; finally, we bring insights on the tradeoffs between privacy preservation and utility performance for IR tasks.
Ground material classification and for UAV-based photogrammetric 3D data A 2D-3D Hybrid Approach
Sep 24, 2021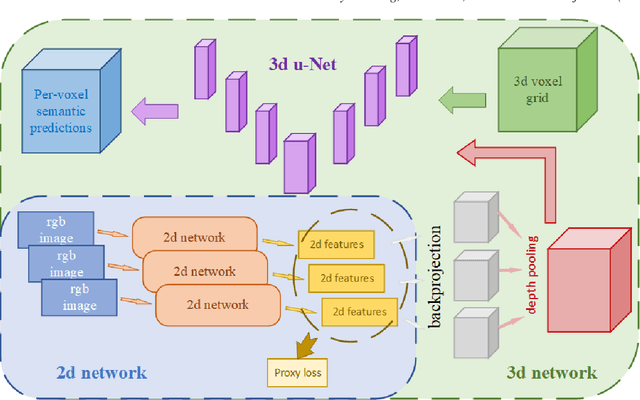
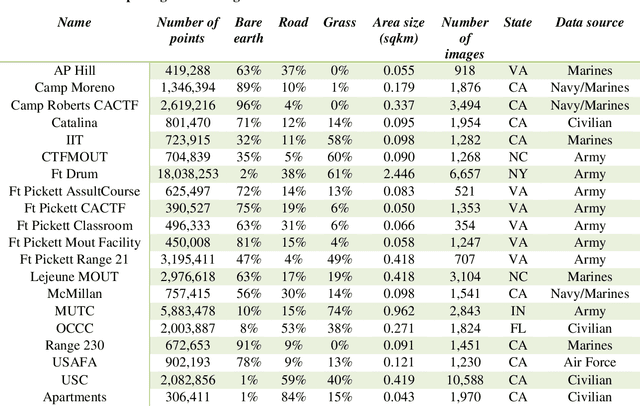

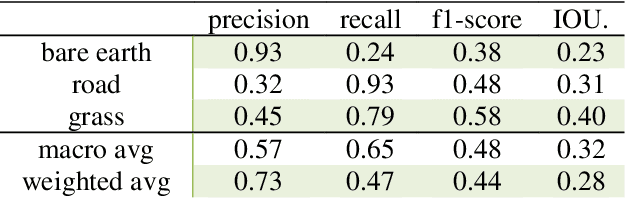
In recent years, photogrammetry has been widely used in many areas to create photorealistic 3D virtual data representing the physical environment. The innovation of small unmanned aerial vehicles (sUAVs) has provided additional high-resolution imaging capabilities with low cost for mapping a relatively large area of interest. These cutting-edge technologies have caught the US Army and Navy's attention for the purpose of rapid 3D battlefield reconstruction, virtual training, and simulations. Our previous works have demonstrated the importance of information extraction from the derived photogrammetric data to create semantic-rich virtual environments (Chen et al., 2019). For example, an increase of simulation realism and fidelity was achieved by segmenting and replacing photogrammetric trees with game-ready tree models. In this work, we further investigated the semantic information extraction problem and focused on the ground material segmentation and object detection tasks. The main innovation of this work was that we leveraged both the original 2D images and the derived 3D photogrammetric data to overcome the challenges faced when using each individual data source. For ground material segmentation, we utilized an existing convolutional neural network architecture (i.e., 3DMV) which was originally designed for segmenting RGB-D sensed indoor data. We improved its performance for outdoor photogrammetric data by introducing a depth pooling layer in the architecture to take into consideration the distance between the source images and the reconstructed terrain model. To test the performance of our improved 3DMV, a ground truth ground material database was created using data from the One World Terrain (OWT) data repository. Finally, a workflow for importing the segmented ground materials into a virtual simulation scene was introduced, and visual results are reported in this paper.
An Optimal Control Framework for Joint-channel Parallel MRI Reconstruction without Coil Sensitivities
Sep 20, 2021
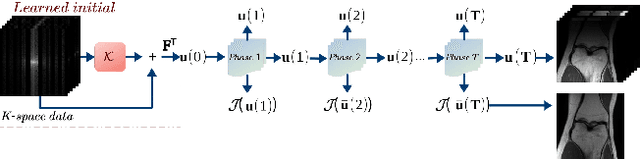
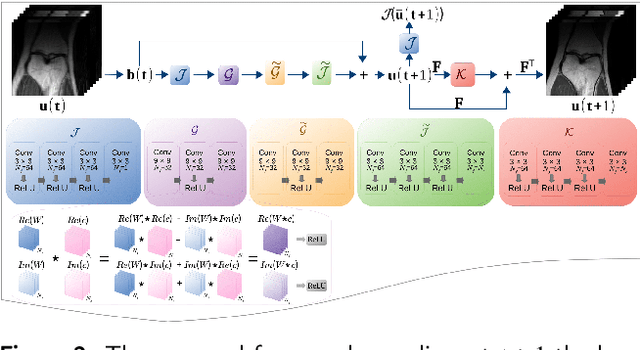
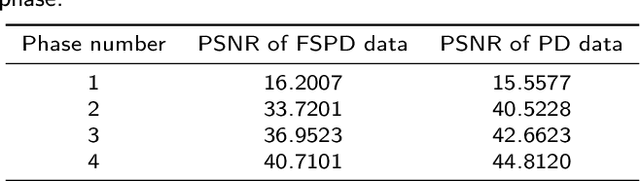
Goal: This work aims at developing a novel calibration-free fast parallel MRI (pMRI) reconstruction method incorporate with discrete-time optimal control framework. The reconstruction model is designed to learn a regularization that combines channels and extracts features by leveraging the information sharing among channels of multi-coil images. We propose to recover both magnitude and phase information by taking advantage of structured multiplayer convolutional networks in image and Fourier spaces. Methods: We develop a novel variational model with a learnable objective function that integrates an adaptive multi-coil image combination operator and effective image regularization in the image and Fourier spaces. We cast the reconstruction network as a structured discrete-time optimal control system, resulting in an optimal control formulation of parameter training where the parameters of the objective function play the role of control variables. We demonstrate that the Lagrangian method for solving the control problem is equivalent to back-propagation, ensuring the local convergence of the training algorithm. Results: We conduct a large number of numerical experiments of the proposed method with comparisons to several state-of-the-art pMRI reconstruction networks on real pMRI datasets. The numerical results demonstrate the promising performance of the proposed method evidently. Conclusion: The proposed method provides a general deep network design and training framework for efficient joint-channel pMRI reconstruction. Significance: By learning multi-coil image combination operator and performing regularizations in both image domain and k-space domain, the proposed method achieves a highly efficient image reconstruction network for pMRI.
EIHW-MTG: Second DiCOVA Challenge System Report
Oct 18, 2021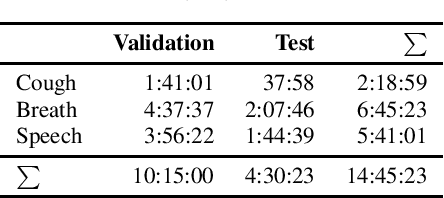
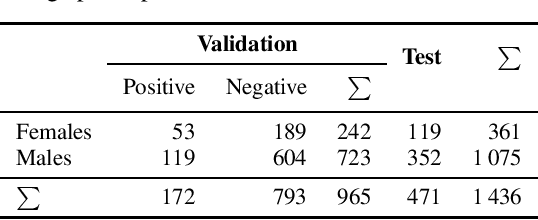
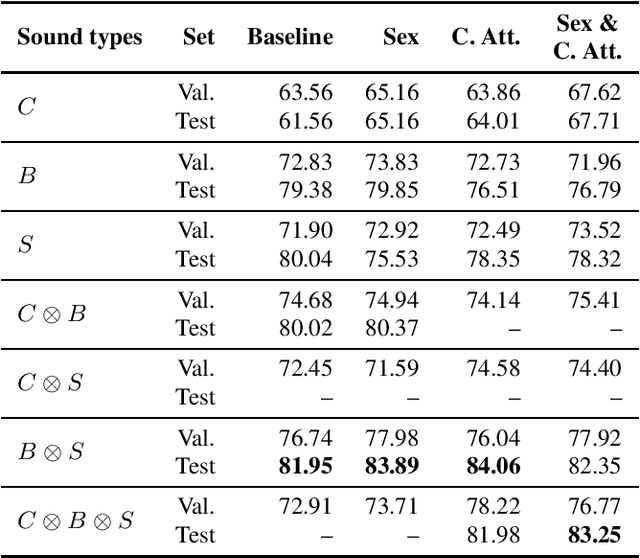
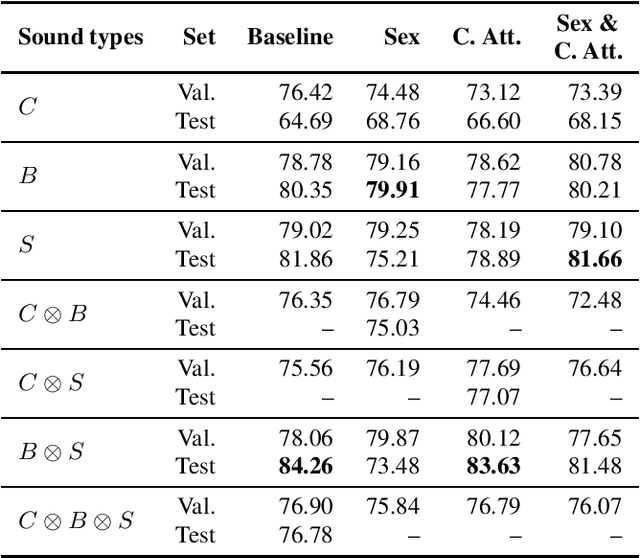
This work presents an outer product-based approach to fuse the embedded representations generated from the spectrograms of cough, breath, and speech samples for the automatic detection of COVID-19. To extract deep learnt representations from the spectrograms, we compare the performance of a CNN trained from scratch and a ResNet18 architecture fine-tuned for the task at hand. Furthermore, we investigate whether the patients' sex and the use of contextual attention mechanisms is beneficial. Our experiments use the dataset released as part of the Second Diagnosing COVID-19 using Acoustics (DiCOVA) Challenge. The results suggest the suitability of fusing breath and speech information to detect COVID-19. An Area Under the Curve (AUC) of 84.06% is obtained on the test partition when using a CNN trained from scratch with contextual attention mechanisms. When using the ResNet18 architecture for feature extraction, the baseline model scores the highest performance with an AUC of 84.26%.