 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interpreting Machine Learning Models for Room Temperature Prediction in Non-domestic Buildings
Nov 23, 2021
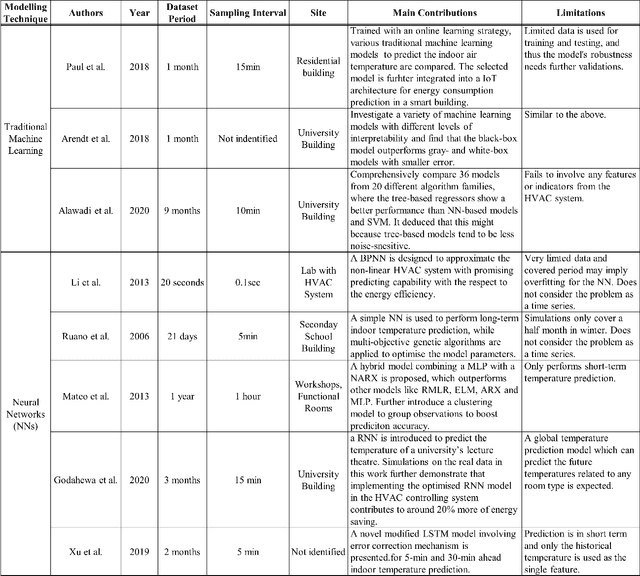
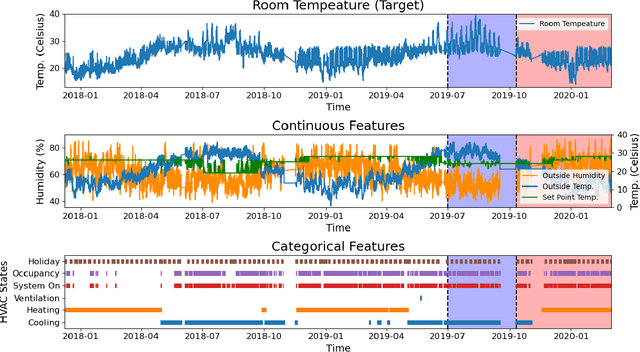
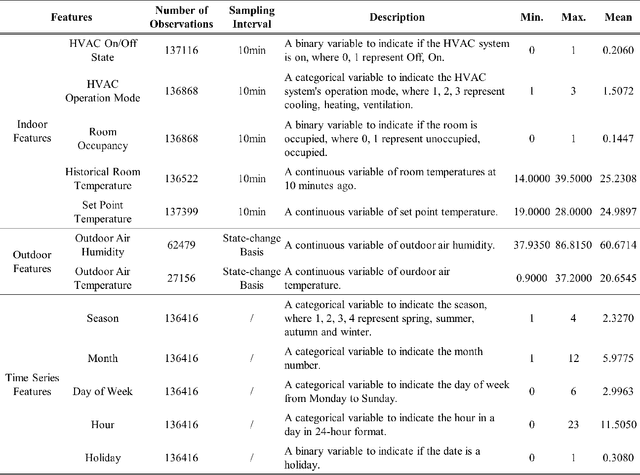
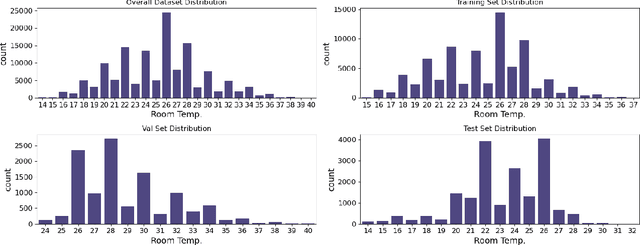
An ensuing challenge in Artificial Intelligence (AI) is the perceived difficulty in interpreting sophisticated machine learning models, whose ever-increasing complexity makes it hard for such models to be understood, trusted and thus accepted by human beings. The lack, if not complete absence, of interpretability for these so-called black-box models can lead to serious economic and ethical consequences, thereby hindering the development and deployment of AI in wider fields, particularly in those involving critical and regulatory applications. Yet, the building services industry is a highly-regulated domain requiring transparency and decision-making processes that can be understood and trusted by humans. To this end, the design and implementation of autonomous Heating, Ventilation and Air Conditioning systems for the automatic but concurrently interpretable optimisation of energy efficiency and room thermal comfort is of topical interest. This work therefore presents an interpretable machine learning model aimed at predicting room temperature in non-domestic buildings, for the purpose of optimising the use of the installed HVAC system. We demonstrate experimentally that the proposed model can accurately forecast room temperatures eight hours ahead in real-time by taking into account historical RT information, as well as additional environmental and time-series features. In this paper, an enhanced feature engineering process is conducted based on the Exploratory Data Analysis results. Furthermore, beyond the commonly used Interpretable Machine Learning techniques, we propose a Permutation Feature-based Frequency Response Analysis (PF-FRA) method for quantifying the contributions of the different predictors in the frequency domain. Based on the generated reason codes, we find that the historical RT feature is the dominant factor that has most impact on the model prediction.
Semantics-STGCNN: A Semantics-guided Spatial-Temporal Graph Convolutional Network for Multi-class Trajectory Prediction
Aug 10, 2021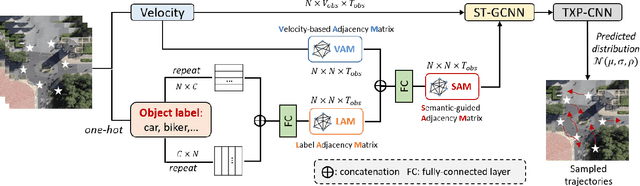
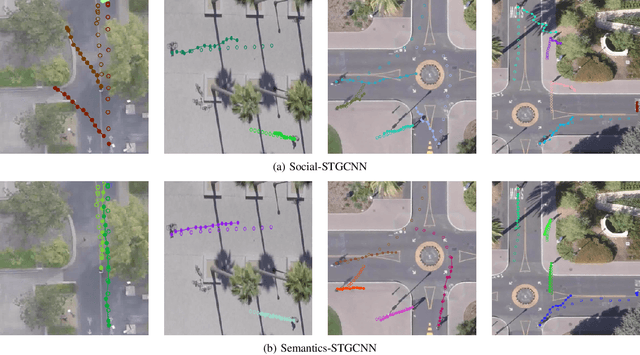


Predicting the movement trajectories of multiple classes of road users in real-world scenarios is a challenging task due to the diverse trajectory patterns. While recent works of pedestrian trajectory prediction successfully modelled the influence of surrounding neighbours based on the relative distances, they are ineffective on multi-class trajectory prediction. This is because they ignore the impact of the implicit correlations between different types of road users on the trajectory to be predicted - for example, a nearby pedestrian has a different level of influence from a nearby car. In this paper, we propose to introduce class information into a graph convolutional neural network to better predict the trajectory of an individual. We embed the class labels of the surrounding objects into the label adjacency matrix (LAM), which is combined with the velocity-based adjacency matrix (VAM) comprised of the objects' velocity, thereby generating a semantics-guided graph adjacency (SAM). SAM effectively models semantic information with trainable parameters to automatically learn the embedded label features that will contribute to the fixed velocity-based trajectory. Such information of spatial and temporal dependencies is passed to a graph convolutional and temporal convolutional network to estimate the predicted trajectory distributions. We further propose new metrics, known as Average2 Displacement Error (aADE) and Average Final Displacement Error (aFDE), that assess network accuracy more accurately. We call our framework Semantics-STGCNN. It consistently shows superior performance to the state-of-the-arts in existing and the newly proposed metrics.
Normative Epistemology for Lethal Autonomous Weapons Systems
Oct 25, 2021The rise of human-information systems, cybernetic systems, and increasingly autonomous systems requires the application of epistemic frameworks to machines and human-machine teams. This chapter discusses higher-order design principles to guide the design, evaluation, deployment, and iteration of Lethal Autonomous Weapons Systems (LAWS) based on epistemic models. Epistemology is the study of knowledge. Epistemic models consider the role of accuracy, likelihoods, beliefs, competencies, capabilities, context, and luck in the justification of actions and the attribution of knowledge. The aim is not to provide ethical justification for or against LAWS, but to illustrate how epistemological frameworks can be used in conjunction with moral apparatus to guide the design and deployment of future systems. The models discussed in this chapter aim to make Article 36 reviews of LAWS systematic, expedient, and evaluable. A Bayesian virtue epistemology is proposed to enable justified actions under uncertainty that meet the requirements of the Laws of Armed Conflict and International Humanitarian Law. Epistemic concepts can provide some of the apparatus to meet explainability and transparency requirements in the development, evaluation, deployment, and review of ethical AI.
Predicting Adverse Media Risk using a Heterogeneous Information Network
Nov 09, 2018
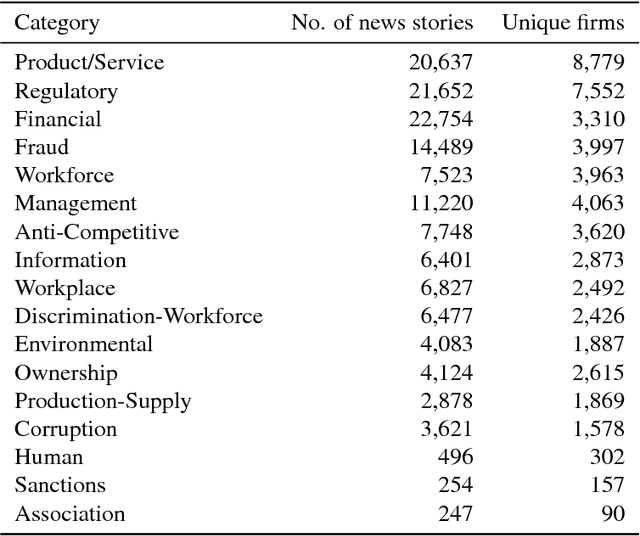
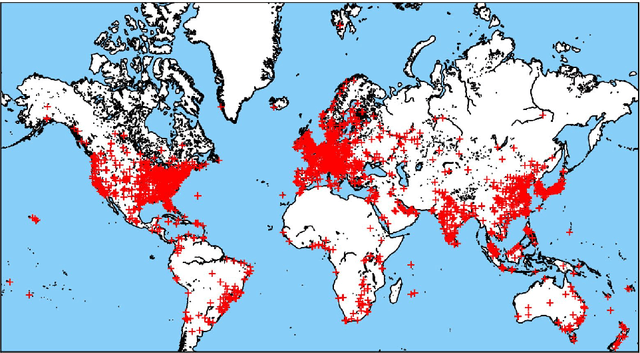

The media plays a central role in monitoring powerful institutions and identifying any activities harmful to the public interest. In the investing sphere constituted of 46,583 officially listed domestic firms on the stock exchanges worldwide, there is a growing interest `to do the right thing', i.e., to put pressure on companies to improve their environmental, social and government (ESG) practices. However, how to overcome the sparsity of ESG data from non-reporting firms, and how to identify the relevant information in the annual reports of this large universe? Here, we construct a vast heterogeneous information network that covers the necessary information surrounding each firm, which is assembled using seven professionally curated datasets and two open datasets, resulting in about 50 million nodes and 400 million edges in total. Exploiting this heterogeneous information network, we propose a model that can learn from past adverse media coverage patterns and predict the occurrence of future adverse media coverage events on the whole universe of firms. Our approach is tested using the adverse media coverage data of more than 35,000 firms worldwide from January 2012 to May 2018. Comparing with state-of-the-art methods with and without the network, we show that the predictive accuracy is substantially improved when using the heterogeneous information network. This work suggests new ways to consolidate the diffuse information contained in big data in order to monitor dominant institutions on a global scale for more socially responsible investment, better risk management, and the surveillance of powerful institutions.
A Partition Filter Network for Joint Entity and Relation Extraction
Aug 30, 2021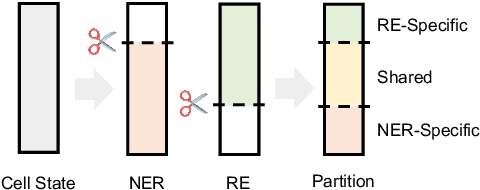
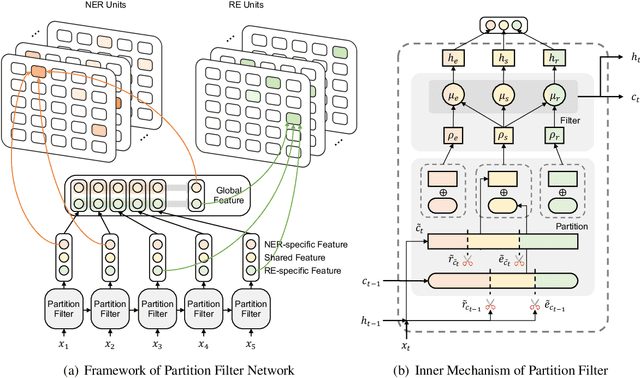
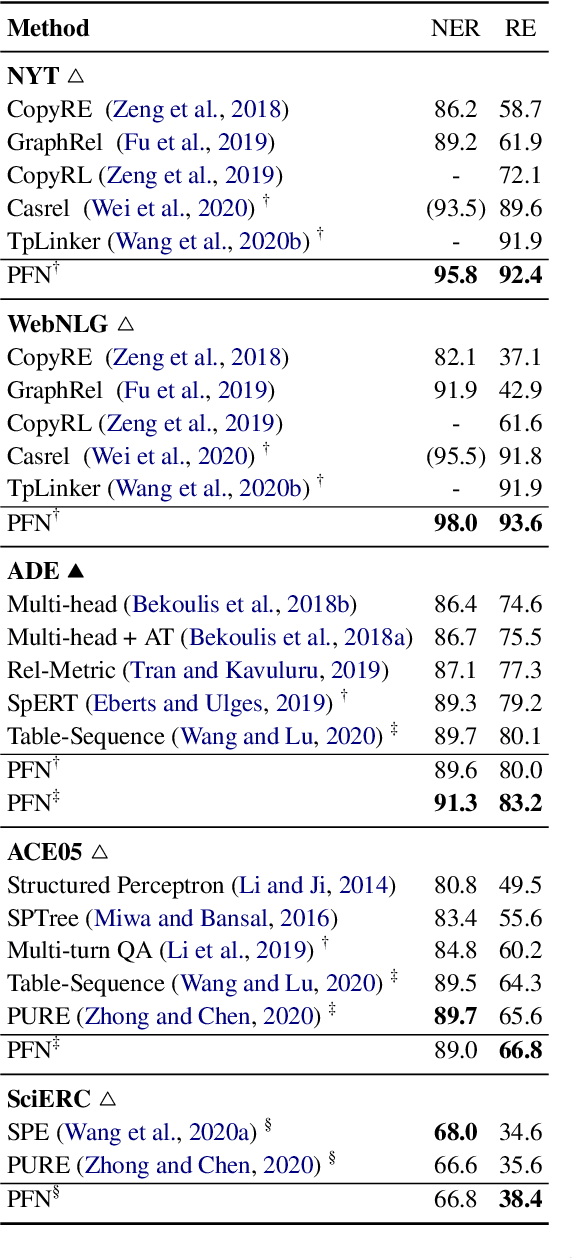
In joint entity and relation extraction, existing work either sequentially encode task-specific features, leading to an imbalance in inter-task feature interaction where features extracted later have no direct contact with those that come first. Or they encode entity features and relation features in a parallel manner, meaning that feature representation learning for each task is largely independent of each other except for input sharing. We propose a partition filter network to model two-way interaction between tasks properly, where feature encoding is decomposed into two steps: partition and filter. In our encoder, we leverage two gates: entity and relation gate, to segment neurons into two task partitions and one shared partition. The shared partition represents inter-task information valuable to both tasks and is evenly shared across two tasks to ensure proper two-way interaction. The task partitions represent intra-task information and are formed through concerted efforts of both gates, making sure that encoding of task-specific features are dependent upon each other. Experiment results on five public datasets show that our model performs significantly better than previous approaches. The source code can be found in https://github.com/Coopercoppers/PFN.
Economics of Semantic Communication System in Wireless Powered Internet of Things
Oct 04, 2021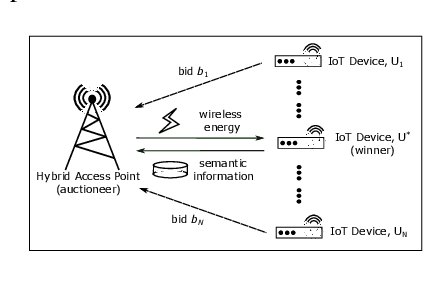
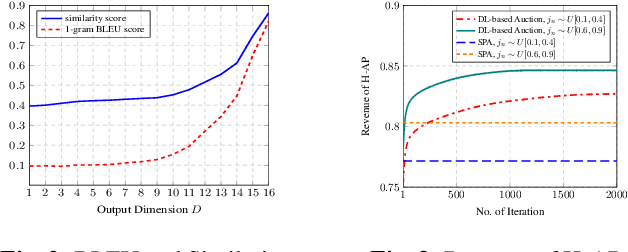

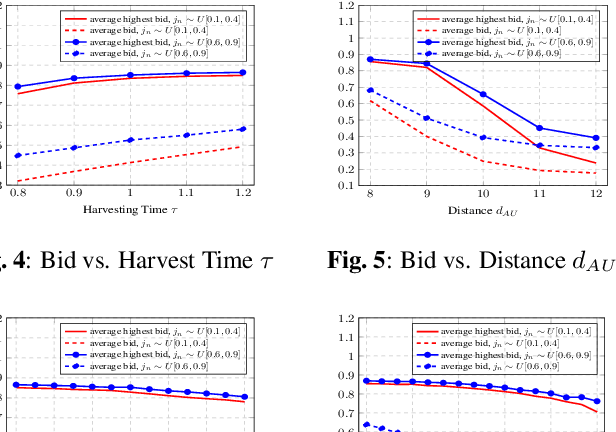
The semantic communication system enables wireless devices to communicate effectively with the semantic meaning of the data. Wireless powered Internet of Things (IoT) that adopts the semantic communication system relies on harvested energy to transmit semantic information. However, the issue of energy constraint in the semantic communication system is not well studied. In this paper, we propose a semantic-based energy valuation and take an economic approach to solve the energy allocation problem as an incentive mechanism design. In our model, IoT devices (bidders) place their bids for the energy and power transmitter (auctioneer) decides the winner and payment by using deep learning based optimal auction. Results show that the revenue of wireless power transmitter is maximized while satisfying Individual Rationality (IR) and Incentive Compatibility (IC).
A Method for Handling Multi-class Imbalanced Data by Geometry based Information Sampling and Class Prioritized Synthetic Data Generation (GICaPS)
Oct 11, 2020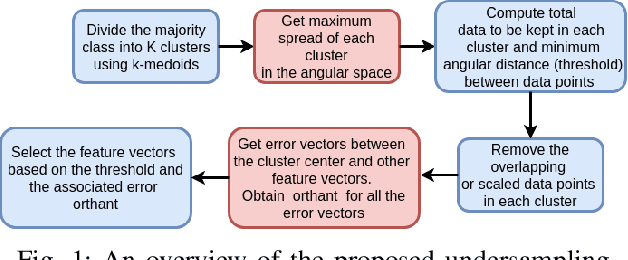
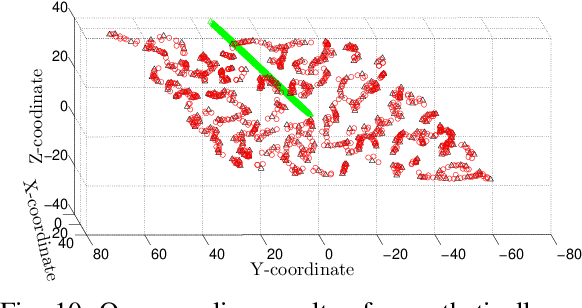
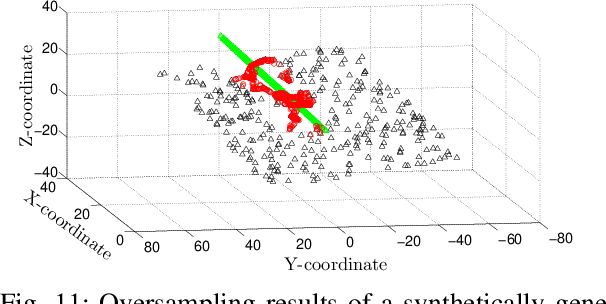
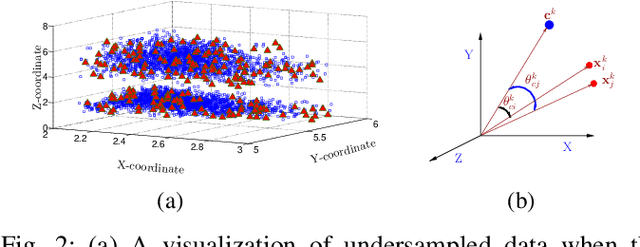
This paper looks into the problem of handling imbalanced data in a multi-label classification problem. The problem is solved by proposing two novel methods that primarily exploit the geometric relationship between the feature vectors. The first one is an undersampling algorithm that uses angle between feature vectors to select more informative samples while rejecting the less informative ones. A suitable criterion is proposed to define the informativeness of a given sample. The second one is an oversampling algorithm that uses a generative algorithm to create new synthetic data that respects all class boundaries. This is achieved by finding \emph{no man's land} based on Euclidean distance between the feature vectors. The efficacy of the proposed methods is analyzed by solving a generic multi-class recognition problem based on mixture of Gaussians. The superiority of the proposed algorithms is established through comparison with other state-of-the-art methods, including SMOTE and ADASYN, over ten different publicly available datasets exhibiting high-to-extreme data imbalance. These two methods are combined into a single data processing framework and is labeled as ``GICaPS'' to highlight the role of geometry-based information (GI) sampling and Class-Prioritized Synthesis (CaPS) in dealing with multi-class data imbalance problem, thereby making a novel contribution in this field.
A Probabilistic Hard Attention Model For Sequentially Observed Scenes
Nov 15, 2021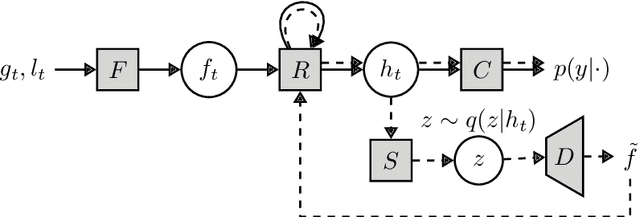
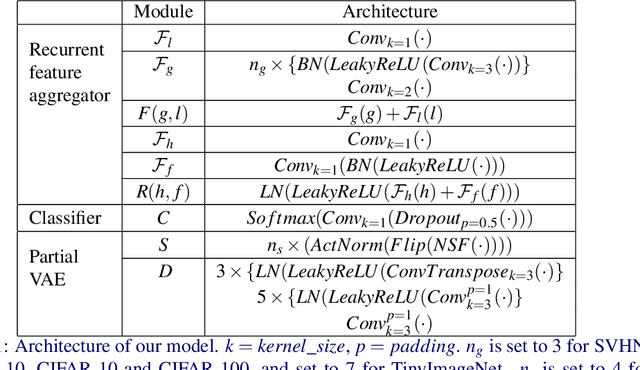
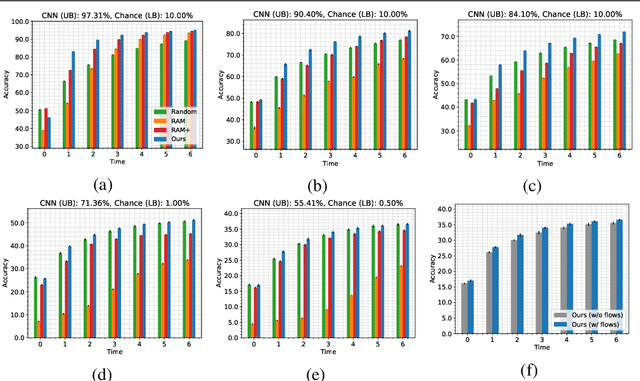
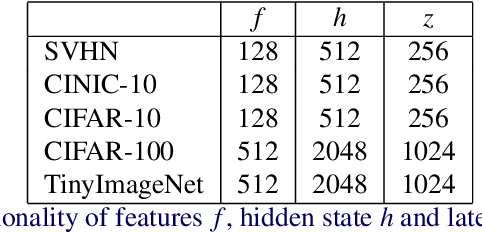
A visual hard attention model actively selects and observes a sequence of subregions in an image to make a prediction. The majority of hard attention models determine the attention-worthy regions by first analyzing a complete image. However, it may be the case that the entire image is not available initially but instead sensed gradually through a series of partial observations. In this paper, we design an efficient hard attention model for classifying such sequentially observed scenes. The presented model never observes an image completely. To select informative regions under partial observability, the model uses Bayesian Optimal Experiment Design. First, it synthesizes the features of the unobserved regions based on the already observed regions. Then, it uses the predicted features to estimate the expected information gain (EIG) attained, should various regions be attended. Finally, the model attends to the actual content on the location where the EIG mentioned above is maximum. The model uses a) a recurrent feature aggregator to maintain a recurrent state, b) a linear classifier to predict the class label, c) a Partial variational autoencoder to predict the features of unobserved regions. We use normalizing flows in Partial VAE to handle multi-modality in the feature-synthesis problem. We train our model using a differentiable objective and test it on five datasets. Our model gains 2-10% higher accuracy than the baseline models when both have seen only a couple of glimpses.
Between welcome culture and border fence. A dataset on the European refugee crisis in German newspaper reports
Nov 19, 2021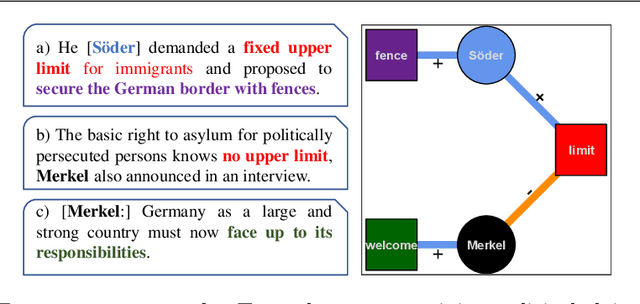
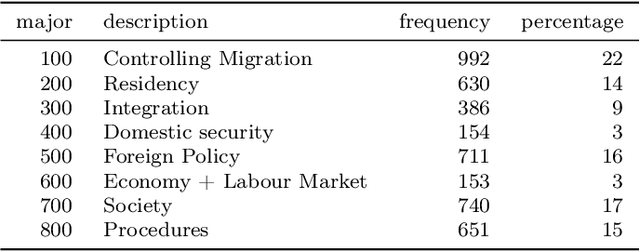
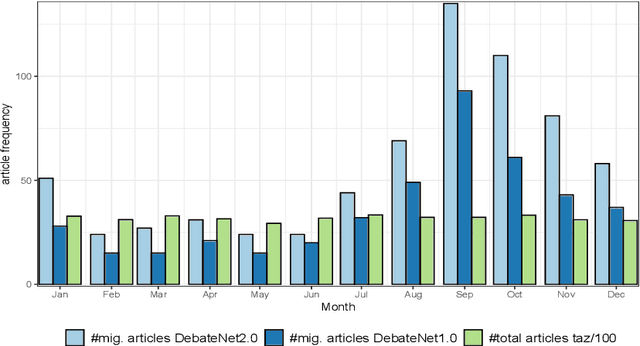
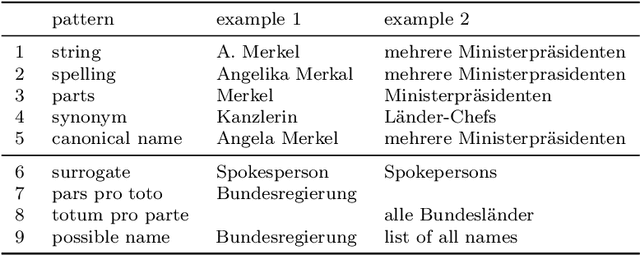
Newspaper reports provide a rich source of information on the unfolding of public debate on specific policy fields that can serve as basis for inquiry in political science. Such debates are often triggered by critical events, which attract public attention and incite the reactions of political actors: crisis sparks the debate. However, due to the challenges of reliable annotation and modeling, few large-scale datasets with high-quality annotation are available. This paper introduces DebateNet2.0, which traces the political discourse on the European refugee crisis in the German quality newspaper taz during the year 2015. The core units of our annotation are political claims (requests for specific actions to be taken within the policy field) and the actors who make them (politicians, parties, etc.). The contribution of this paper is twofold. First, we document and release DebateNet2.0 along with its companion R package, mardyR, guiding the reader through the practical and conceptual issues related to the annotation of policy debates in newspapers. Second, we outline and apply a Discourse Network Analysis (DNA) to DebateNet2.0, comparing two crucial moments of the policy debate on the 'refugee crisis': the migration flux through the Mediterranean in April/May and the one along the Balkan route in September/October. Besides the released resources and the case-study, our contribution is also methodological: we talk the reader through the steps from a newspaper article to a discourse network, demonstrating that there is not just one discourse network for the German migration debate, but multiple ones, depending on the topic of interest (political actors, policy fields, time spans).
Hierarchical Deep Residual Reasoning for Temporal Moment Localization
Oct 31, 2021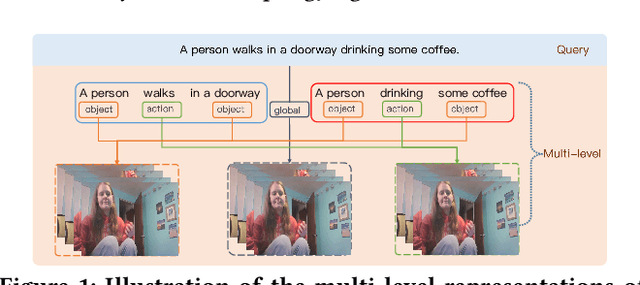
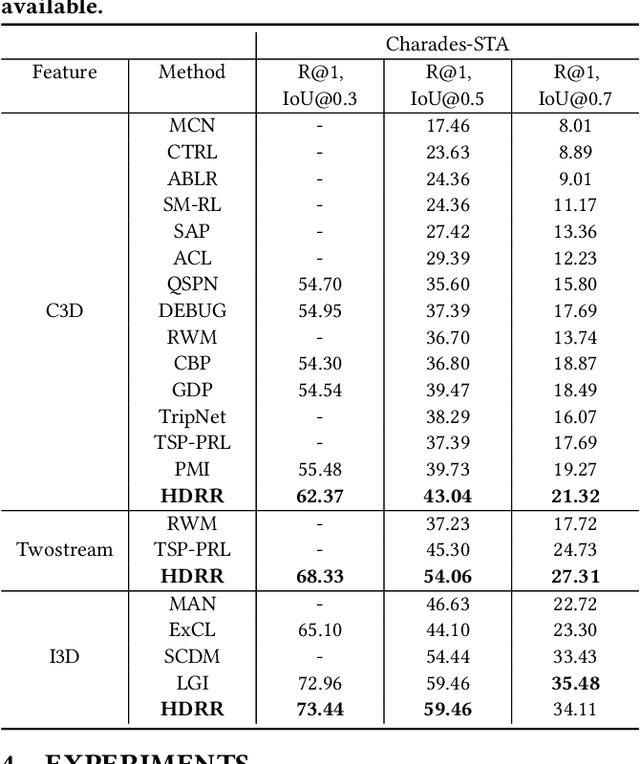
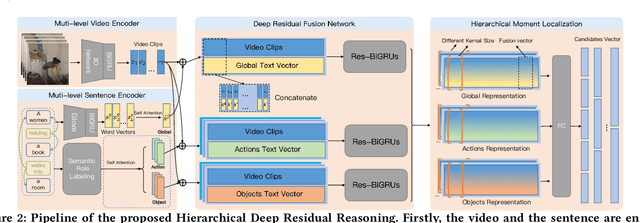
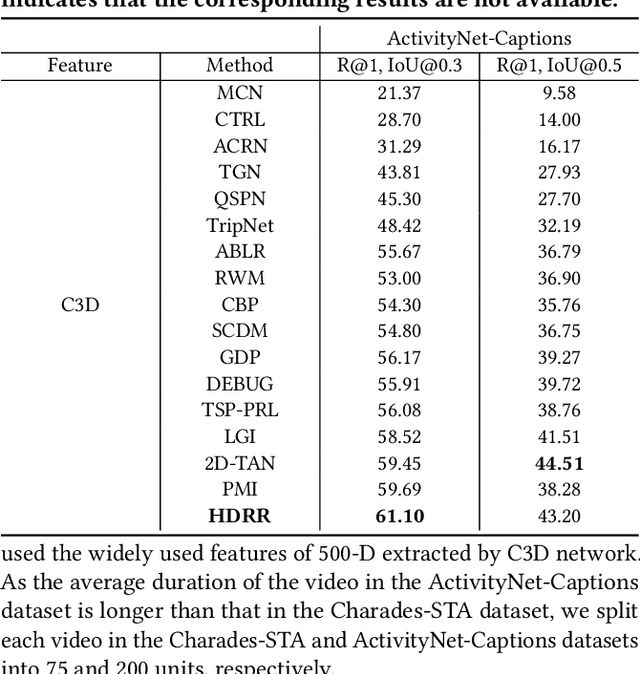
Temporal Moment Localization (TML) in untrimmed videos is a challenging task in the field of multimedia, which aims at localizing the start and end points of the activity in the video, described by a sentence query. Existing methods mainly focus on mining the correlation between video and sentence representations or investigating the fusion manner of the two modalities. These works mainly understand the video and sentence coarsely, ignoring the fact that a sentence can be understood from various semantics, and the dominant words affecting the moment localization in the semantics are the action and object reference. Toward this end, we propose a Hierarchical Deep Residual Reasoning (HDRR) model, which decomposes the video and sentence into multi-level representations with different semantics to achieve a finer-grained localization. Furthermore, considering that videos with different resolution and sentences with different length have different difficulty in understanding, we design the simple yet effective Res-BiGRUs for feature fusion, which is able to grasp the useful information in a self-adapting manner. Extensive experiments conducted on Charades-STA and ActivityNet-Captions datasets demonstrate the superiority of our HDRR model compared with other state-of-the-art methods.