 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Euclidean Network Trajectories: Second-Moment Geometry, Attribution, and Change Points
May 06, 2026A central challenge in dynamic network analysis is to represent temporal evolution in a way that is both geometrically meaningful and statistically identifiable. One approach embeds a sequence of network snapshots as trajectories in a Euclidean space and relates these trajectories to node embeddings. In multilayer and unfolded spectral constructions, however, node embeddings and their underlying latent positions are identifiable only up to general linear transformations. Although this ambiguity preserves edge probabilities, it can distort geometry and invalidate distance based temporal comparisons at both the trajectory and node-levels. We develop Multiscale Euclidean Network Trajectories (MENT), a framework for multiscale temporal trajectories based on second-moment geometry. By imposing an isotropic normalization on the anchor latent positions, we reduce the relevant ambiguity to orthogonal transformations and prevent distortion of the second-moment geometry. In this canonical representation, we define a trace variation distance and mode-wise variation distances along orthogonal directions, and use multidimensional scaling to obtain low-dimensional trajectories of time points at both global and mode-wise levels. The resulting trajectories support interpretation and inference. They admit mode-wise decompositions, support attribution of global and mode-wise temporal changes to nodes, and enable change point detection through 1D trajectories. We prove consistency of the proposed unfolded spectral embedding and of the induced temporal trajectories. Experiments on two synthetic and two real dynamic networks illustrate stable and interpretable recovery of temporal structure and show strong performance against existing change point detection baselines.
Capturing Legal Reasoning Paths from Facts to Law in Court Judgments using Knowledge Graphs
Aug 24, 2025Court judgments reveal how legal rules have been interpreted and applied to facts, providing a foundation for understanding structured legal reasoning. However, existing automated approaches for capturing legal reasoning, including large language models, often fail to identify the relevant legal context, do not accurately trace how facts relate to legal norms, and may misrepresent the layered structure of judicial reasoning. These limitations hinder the ability to capture how courts apply the law to facts in practice. In this paper, we address these challenges by constructing a legal knowledge graph from 648 Japanese administrative court decisions. Our method extracts components of legal reasoning using prompt-based large language models, normalizes references to legal provisions, and links facts, norms, and legal applications through an ontology of legal inference. The resulting graph captures the full structure of legal reasoning as it appears in real court decisions, making implicit reasoning explicit and machine-readable. We evaluate our system using expert annotated data, and find that it achieves more accurate retrieval of relevant legal provisions from facts than large language model baselines and retrieval-augmented methods.
Unfolded Laplacian Spectral Embedding: A Theoretically Grounded Approach to Dynamic Network Representation
Aug 18, 2025



Dynamic relational structures play a central role in many AI tasks, but their evolving nature presents challenges for consistent and interpretable representation. A common approach is to learn time-varying node embeddings, whose effectiveness depends on satisfying key stability properties. In this paper, we propose Unfolded Laplacian Spectral Embedding, a new method that extends the Unfolded Adjacency Spectral Embedding framework to normalized Laplacians while preserving both cross-sectional and longitudinal stability. We provide formal proof that our method satisfies these stability conditions. In addition, as a bonus of using the Laplacian matrix, we establish a new Cheeger-style inequality that connects the embeddings to the conductance of the underlying dynamic graphs. Empirical evaluations on synthetic and real-world datasets support our theoretical findings and demonstrate the strong performance of our method. These results establish a principled and stable framework for dynamic network representation grounded in spectral graph theory.
Hierarchical Narrative Analysis: Unraveling Perceptions of Generative AI
Sep 17, 2024



Written texts reflect an author's perspective, making the thorough analysis of literature a key research method in fields such as the humanities and social sciences. However, conventional text mining techniques like sentiment analysis and topic modeling are limited in their ability to capture the hierarchical narrative structures that reveal deeper argumentative patterns. To address this gap, we propose a method that leverages large language models (LLMs) to extract and organize these structures into a hierarchical framework. We validate this approach by analyzing public opinions on generative AI collected by Japan's Agency for Cultural Affairs, comparing the narratives of supporters and critics. Our analysis provides clearer visualization of the factors influencing divergent opinions on generative AI, offering deeper insights into the structures of agreement and disagreement.
Nondiagonal Mixture of Dirichlet Network Distributions for Analyzing a Stock Ownership Network
Sep 08, 2020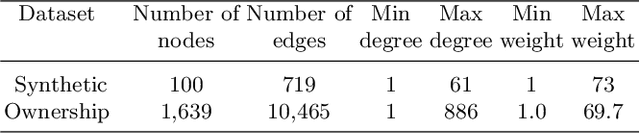
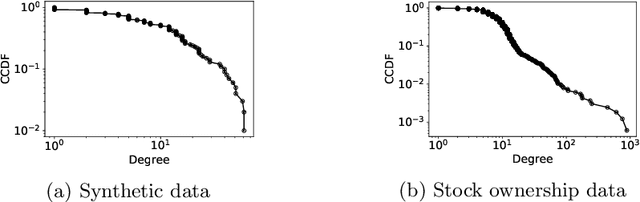
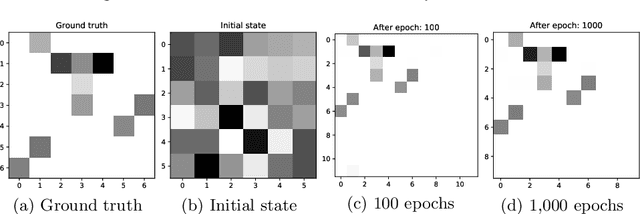
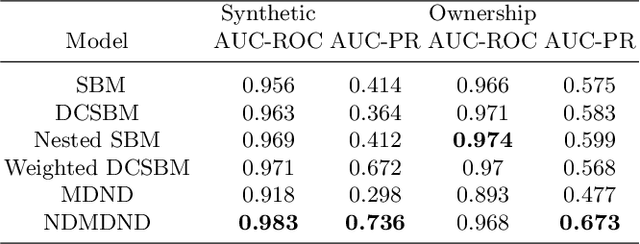
Block modeling is widely used in studies on complex networks. The cornerstone model is the stochastic block model (SBM), widely used over the past decades. However, the SBM is limited in analyzing complex networks as the model is, in essence, a random graph model that cannot reproduce the basic properties of many complex networks, such as sparsity and heavy-tailed degree distribution. In this paper, we provide an edge exchangeable block model that incorporates such basic features and simultaneously infers the latent block structure of a given complex network. Our model is a Bayesian nonparametric model that flexibly estimates the number of blocks and takes into account the possibility of unseen nodes. Using one synthetic dataset and one real-world stock ownership dataset, we show that our model outperforms state-of-the-art SBMs for held-out link prediction tasks.
Gaussian Hierarchical Latent Dirichlet Allocation: Bringing Polysemy Back
Feb 25, 2020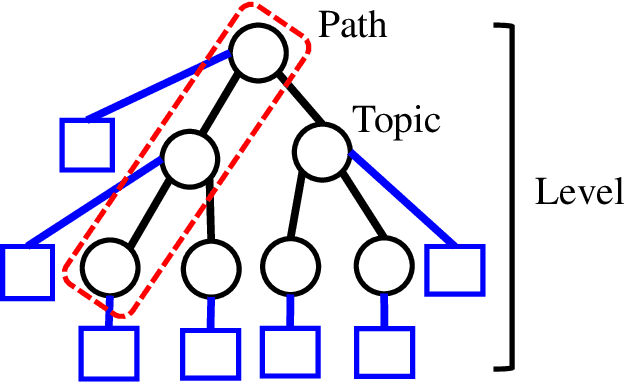
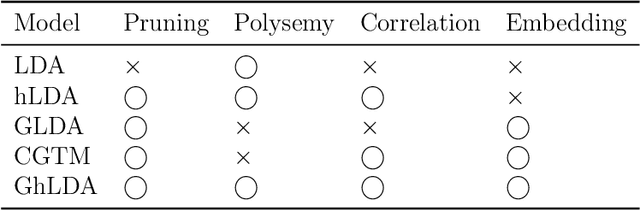
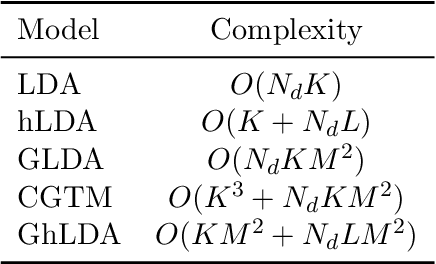
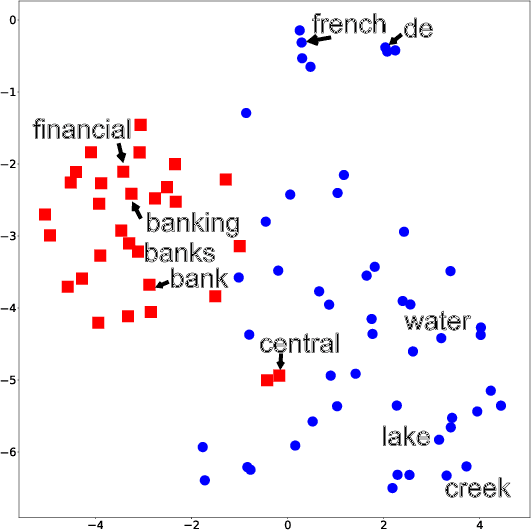
Topic models are widely used to discover the latent representation of a set of documents. The two canonical models are latent Dirichlet allocation, and Gaussian latent Dirichlet allocation, where the former uses multinomial distributions over words, and the latter uses multivariate Gaussian distributions over pre-trained word embedding vectors as the latent topic representations, respectively. Compared with latent Dirichlet allocation, Gaussian latent Dirichlet allocation is limited in the sense that it does not capture the polysemy of a word such as ``bank.'' In this paper, we show that Gaussian latent Dirichlet allocation could recover the ability to capture polysemy by introducing a hierarchical structure in the set of topics that the model can use to represent a given document. Our Gaussian hierarchical latent Dirichlet allocation significantly improves polysemy detection compared with Gaussian-based models and provides more parsimonious topic representations compared with hierarchical latent Dirichlet allocation. Our extensive quantitative experiments show that our model also achieves better topic coherence and held-out document predictive accuracy over a wide range of corpus and word embedding vectors.
Predicting Adverse Media Risk using a Heterogeneous Information Network
Nov 09, 2018
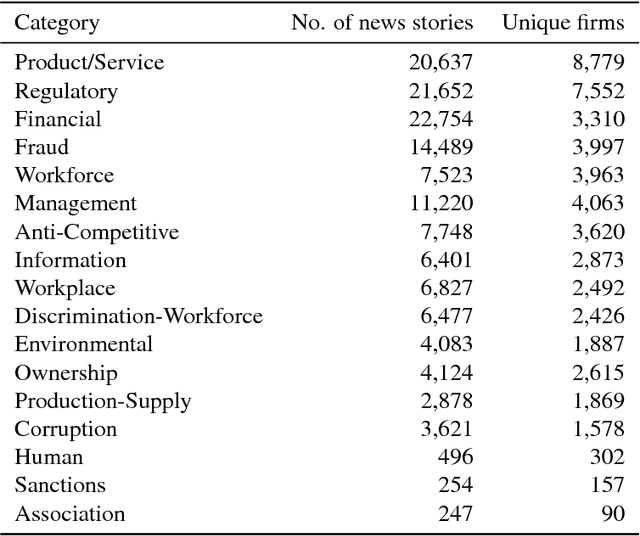
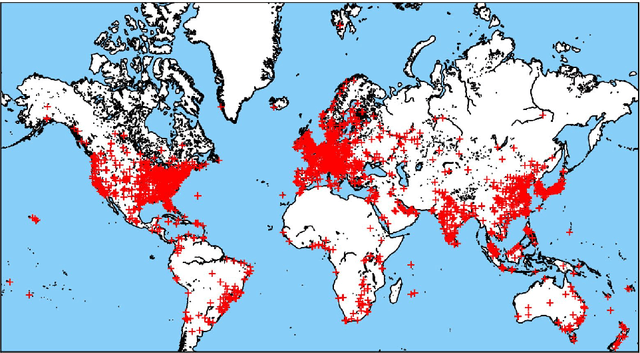

The media plays a central role in monitoring powerful institutions and identifying any activities harmful to the public interest. In the investing sphere constituted of 46,583 officially listed domestic firms on the stock exchanges worldwide, there is a growing interest `to do the right thing', i.e., to put pressure on companies to improve their environmental, social and government (ESG) practices. However, how to overcome the sparsity of ESG data from non-reporting firms, and how to identify the relevant information in the annual reports of this large universe? Here, we construct a vast heterogeneous information network that covers the necessary information surrounding each firm, which is assembled using seven professionally curated datasets and two open datasets, resulting in about 50 million nodes and 400 million edges in total. Exploiting this heterogeneous information network, we propose a model that can learn from past adverse media coverage patterns and predict the occurrence of future adverse media coverage events on the whole universe of firms. Our approach is tested using the adverse media coverage data of more than 35,000 firms worldwide from January 2012 to May 2018. Comparing with state-of-the-art methods with and without the network, we show that the predictive accuracy is substantially improved when using the heterogeneous information network. This work suggests new ways to consolidate the diffuse information contained in big data in order to monitor dominant institutions on a global scale for more socially responsible investment, better risk management, and the surveillance of powerful institutions.
Learning Topic Models by Neighborhood Aggregation
Aug 28, 2018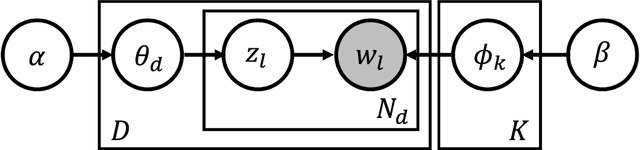
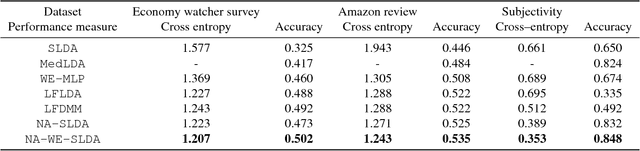
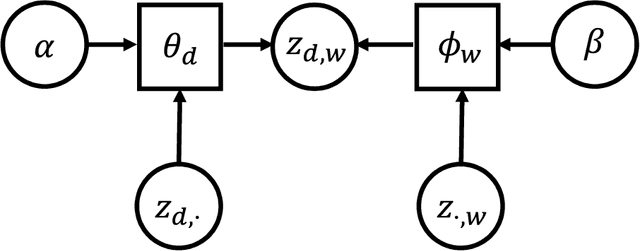
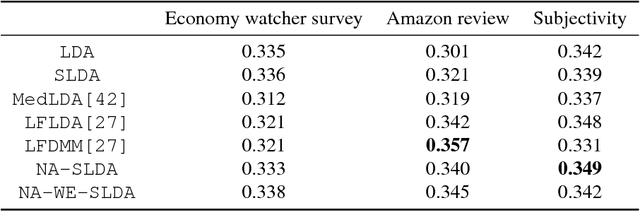
Topic models are frequently used in machine learning owing to their high interpretability and modular structure. However, extending a topic model to include a supervisory signal, to incorporate pre-trained word embedding vectors and to include a nonlinear output function is not an easy task because one has to resort to a highly intricate approximate inference procedure. The present paper shows that topic modeling with pre-trained word embedding vectors can be viewed as implementing a neighborhood aggregation algorithm where messages are passed through a network defined over words. From the network view of topic models, nodes correspond to words in a document and edges correspond to either a relationship describing co-occurring words in a document or a relationship describing the same word in the corpus. The network view allows us to extend the model to include supervisory signals, incorporate pre-trained word embedding vectors and include a nonlinear output function in a simple manner. In experiments, we show that our approach outperforms the state-of-the-art supervised Latent Dirichlet Allocation implementation in terms of both held-out document classification tasks and topic coherence.
Semi-supervised Graph Embedding Approach to Dynamic Link Prediction
Oct 14, 2016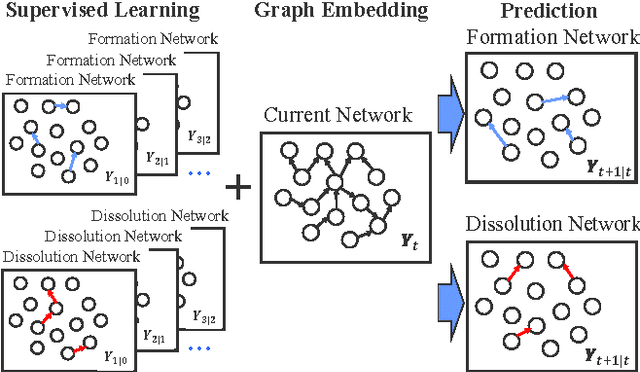

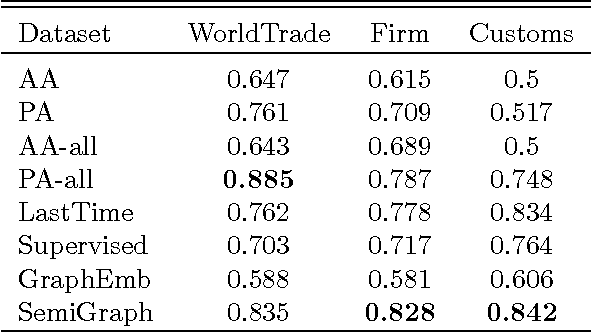
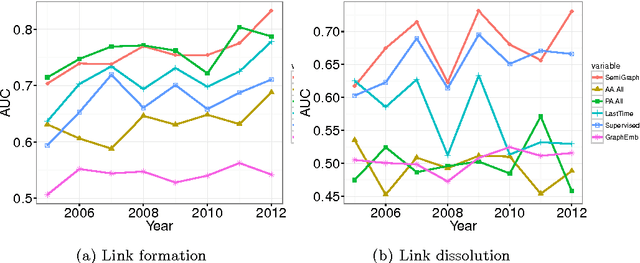
We propose a simple discrete time semi-supervised graph embedding approach to link prediction in dynamic networks. The learned embedding reflects information from both the temporal and cross-sectional network structures, which is performed by defining the loss function as a weighted sum of the supervised loss from past dynamics and the unsupervised loss of predicting the neighborhood context in the current network. Our model is also capable of learning different embeddings for both formation and dissolution dynamics. These key aspects contributes to the predictive performance of our model and we provide experiments with three real--world dynamic networks showing that our method is comparable to state of the art methods in link formation prediction and outperforms state of the art baseline methods in link dissolution prediction.
A New Approach to Building the Interindustry Input--Output Table
May 29, 2016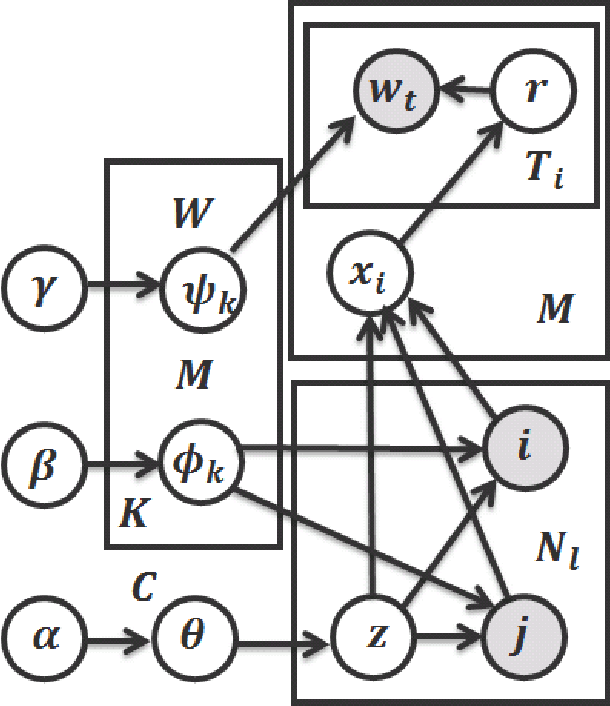

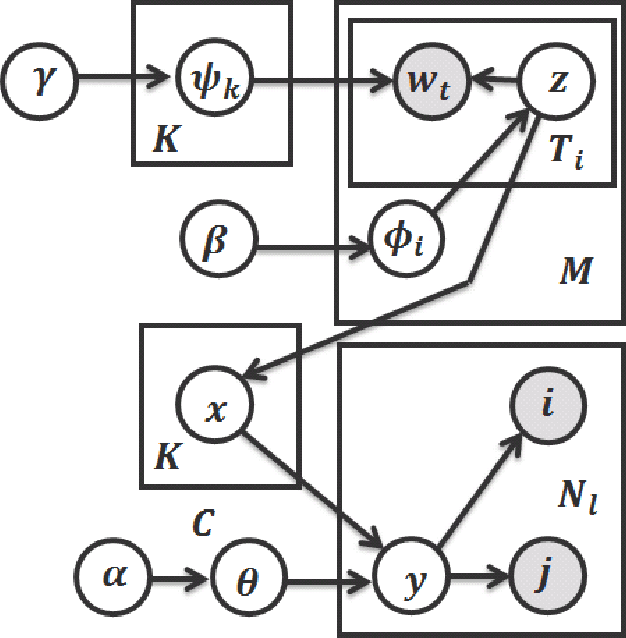
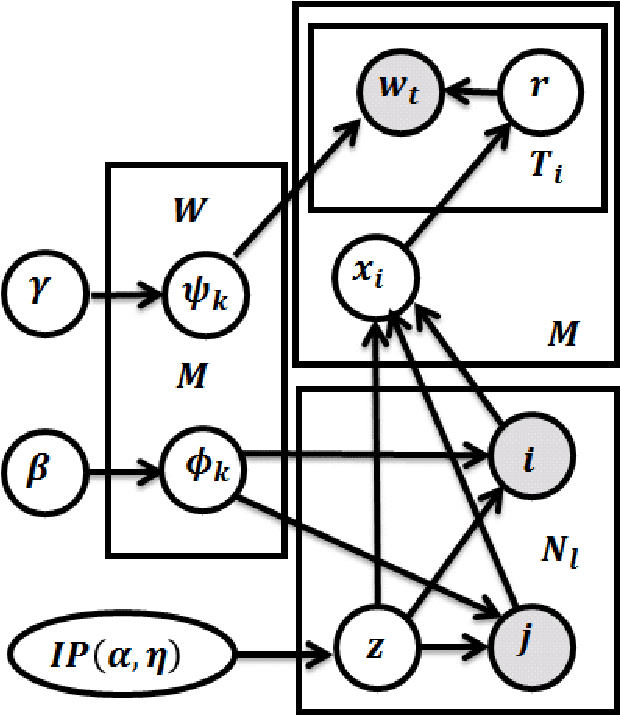
We present a new approach to estimating the interdependence of industries in an economy by applying data science solutions. By exploiting interfirm buyer--seller network data, we show that the problem of estimating the interdependence of industries is similar to the problem of uncovering the latent block structure in network science literature. To estimate the underlying structure with greater accuracy, we propose an extension of the sparse block model that incorporates node textual information and an unbounded number of industries and interactions among them. The latter task is accomplished by extending the well-known Chinese restaurant process to two dimensions. Inference is based on collapsed Gibbs sampling, and the model is evaluated on both synthetic and real-world datasets. We show that the proposed model improves in predictive accuracy and successfully provides a satisfactory solution to the motivated problem. We also discuss issues that affect the future performance of this approach.