 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RBSRICNN: Raw Burst Super-Resolution through Iterative Convolutional Neural Network
Nov 10, 2021



Modern digital cameras and smartphones mostly rely on image signal processing (ISP) pipelines to produce realistic colored RGB images. However, compared to DSLR cameras, low-quality images are usually obtained in many portable mobile devices with compact camera sensors due to their physical limitations. The low-quality images have multiple degradations i.e., sub-pixel shift due to camera motion, mosaick patterns due to camera color filter array, low-resolution due to smaller camera sensors, and the rest information are corrupted by the noise. Such degradations limit the performance of current Single Image Super-resolution (SISR) methods in recovering high-resolution (HR) image details from a single low-resolution (LR) image. In this work, we propose a Raw Burst Super-Resolution Iterative Convolutional Neural Network (RBSRICNN) that follows the burst photography pipeline as a whole by a forward (physical) model. The proposed Burst SR scheme solves the problem with classical image regularization, convex optimization, and deep learning techniques, compared to existing black-box data-driven methods. The proposed network produces the final output by an iterative refinement of the intermediate SR estimates. We demonstrate the effectiveness of our proposed approach in quantitative and qualitative experiments that generalize robustly to real LR burst inputs with onl synthetic burst data available for training.
Quality Map Fusion for Adversarial Learning
Oct 24, 2021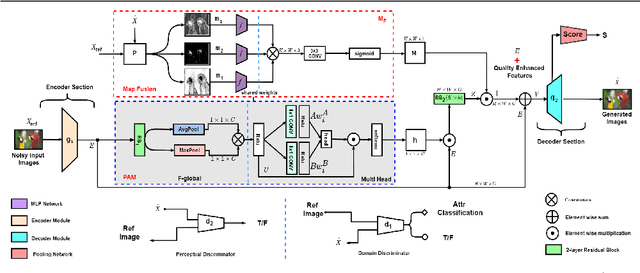
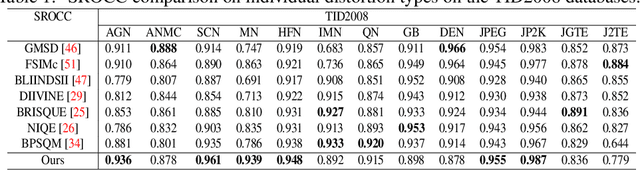
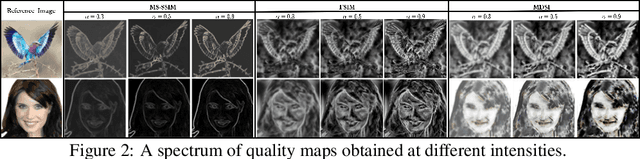
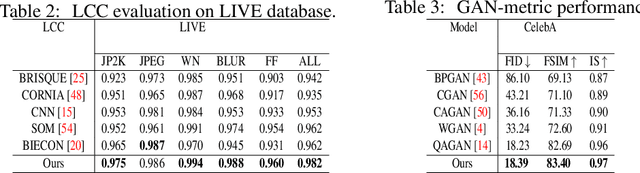
Generative adversarial models that capture salient low-level features which convey visual information in correlation with the human visual system (HVS) still suffer from perceptible image degradations. The inability to convey such highly informative features can be attributed to mode collapse, convergence failure and vanishing gradients. In this paper, we improve image quality adversarially by introducing a novel quality map fusion technique that harnesses image features similar to the HVS and the perceptual properties of a deep convolutional neural network (DCNN). We extend the widely adopted l2 Wasserstein distance metric to other preferable quality norms derived from Banach spaces that capture richer image properties like structure, luminance, contrast and the naturalness of images. We also show that incorporating a perceptual attention mechanism (PAM) that extracts global feature embeddings from the network bottleneck with aggregated perceptual maps derived from standard image quality metrics translate to a better image quality. We also demonstrate impressive performance over other methods.
AoI-minimizing Scheduling in UAV-relayed IoT Networks
Jul 13, 2021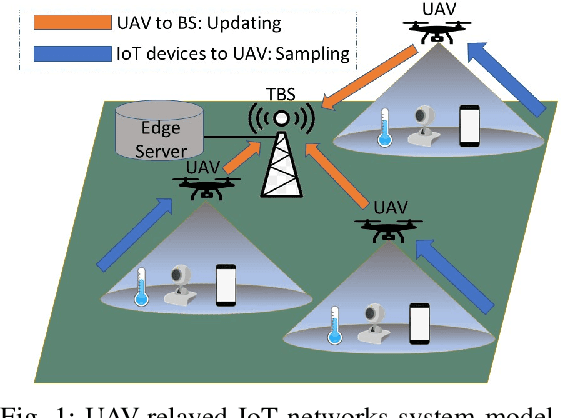
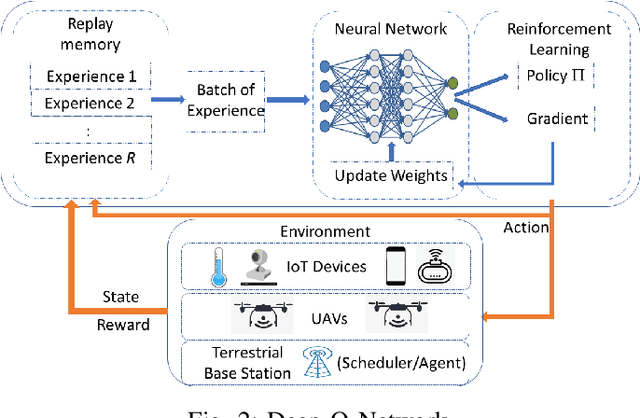
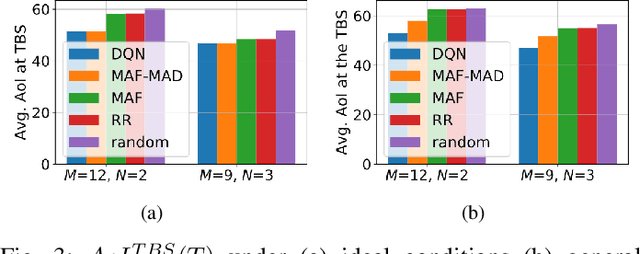
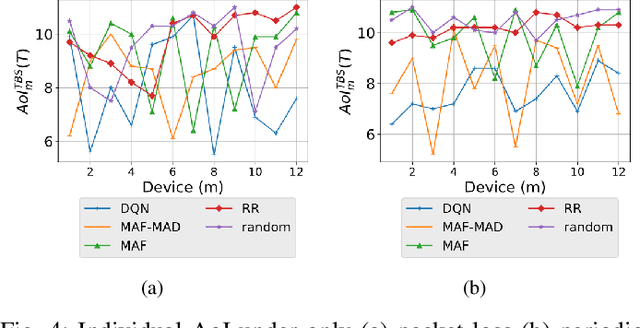
Due to flexibility, autonomy and low operational cost, unmanned aerial vehicles (UAVs), as fixed aerial base stations, are increasingly being used as \textit{relays} to collect time-sensitive information (i.e., status updates) from IoT devices and deliver it to the nearby terrestrial base station (TBS), where the information gets processed. In order to ensure timely delivery of information to the TBS (from all IoT devices), optimal scheduling of time-sensitive information over two hop UAV-relayed IoT networks (i.e., IoT device to the UAV [hop 1], and UAV to the TBS [hop 2]) becomes a critical challenge. To address this, we propose scheduling policies for Age of Information (AoI) minimization in such two-hop UAV-relayed IoT networks. To this end, we present a low-complexity MAF-MAD scheduler, that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop 1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop 2). We show that MAF-MAD is the optimal scheduler under ideal conditions, i.e., error-free channels and generate-at-will traffic generation at IoT devices. On the contrary, for realistic conditions, we propose a Deep-Q-Networks (DQN) based scheduler. Our simulation results show that DQN-based scheduler outperforms MAF-MAD scheduler and three other baseline schedulers, i.e., Maximal AoI First (MAF), Round Robin (RR) and Random, employed at both hops under general conditions when the network is small (with 10's of IoT devices). However, it does not scale well with network size whereas MAF-MAD outperforms all other schedulers under all considered scenarios for larger networks.
When expertise gone missing: Uncovering the loss of prolific contributors in Wikipedia
Sep 21, 2021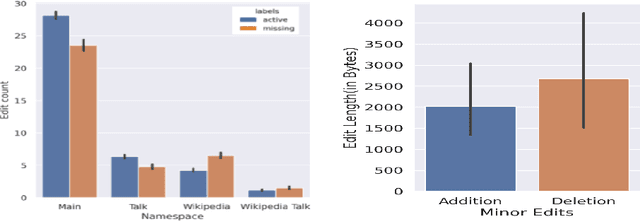

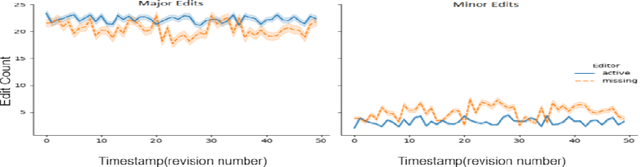

Success of planetary-scale online collaborative platforms such as Wikipedia is hinged on active and continued participation of its voluntary contributors. The phenomenal success of Wikipedia as a valued multilingual source of information is a testament to the possibilities of collective intelligence. Specifically, the sustained and prudent contributions by the experienced prolific editors play a crucial role to operate the platform smoothly for decades. However, it has been brought to light that growth of Wikipedia is stagnating in terms of the number of editors that faces steady decline over time. This decreasing productivity and ever increasing attrition rate in both newcomer and experienced editors is a major concern for not only the future of this platform but also for several industry-scale information retrieval systems such as Siri, Alexa which depend on Wikipedia as knowledge store. In this paper, we have studied the ongoing crisis in which experienced and prolific editors withdraw. We performed extensive analysis of the editor activities and their language usage to identify features that can forecast prolific Wikipedians, who are at risk of ceasing voluntary services. To the best of our knowledge, this is the first work which proposes a scalable prediction pipeline, towards detecting the prolific Wikipedians, who might be at a risk of retiring from the platform and, thereby, can potentially enable moderators to launch appropriate incentive mechanisms to retain such `would-be missing' valued Wikipedians.
Making the Last Iterate of SGD Information Theoretically Optimal
May 29, 2019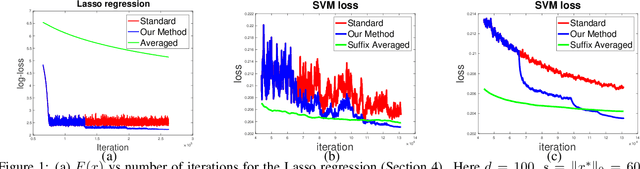
Stochastic gradient descent (SGD) is one of the most widely used algorithms for large scale optimization problems. While classical theoretical analysis of SGD for convex problems studies (suffix) \emph{averages} of iterates and obtains information theoretically optimal bounds on suboptimality, the \emph{last point} of SGD is, by far, the most preferred choice in practice. The best known results for last point of SGD \cite{shamir2013stochastic} however, are suboptimal compared to information theoretic lower bounds by a $\log T$ factor, where $T$ is the number of iterations. \cite{harvey2018tight} shows that in fact, this additional $\log T$ factor is tight for standard step size sequences of $\OTheta{\frac{1}{\sqrt{t}}}$ and $\OTheta{\frac{1}{t}}$ for non-strongly convex and strongly convex settings, respectively. Similarly, even for subgradient descent (GD) when applied to non-smooth, convex functions, the best known step-size sequences still lead to $O(\log T)$-suboptimal convergence rates (on the final iterate). The main contribution of this work is to design new step size sequences that enjoy information theoretically optimal bounds on the suboptimality of \emph{last point} of SGD as well as GD. We achieve this by designing a modification scheme, that converts one sequence of step sizes to another so that the last point of SGD/GD with modified sequence has the same suboptimality guarantees as the average of SGD/GD with original sequence. We also show that our result holds with high-probability. We validate our results through simulations which demonstrate that the new step size sequence indeed improves the final iterate significantly compared to the standard step size sequences.
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 10, 2021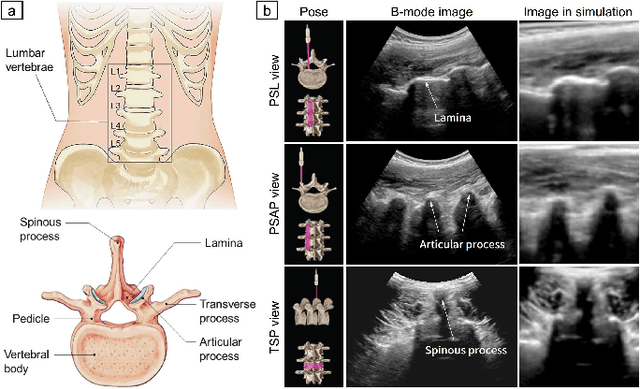
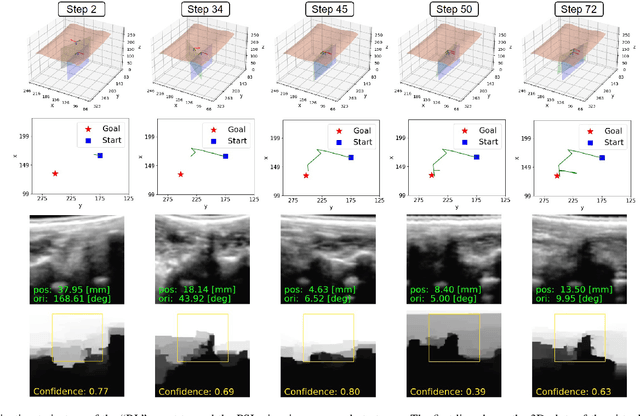
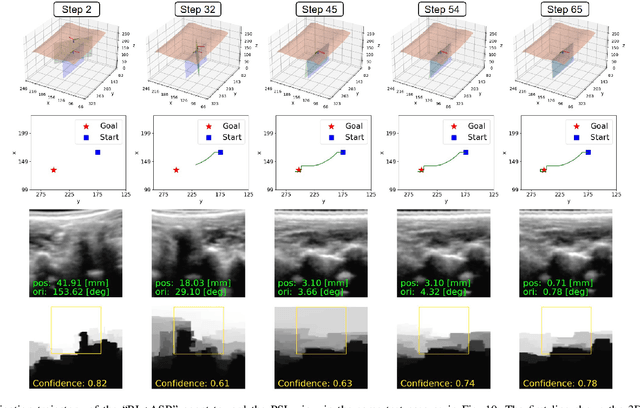
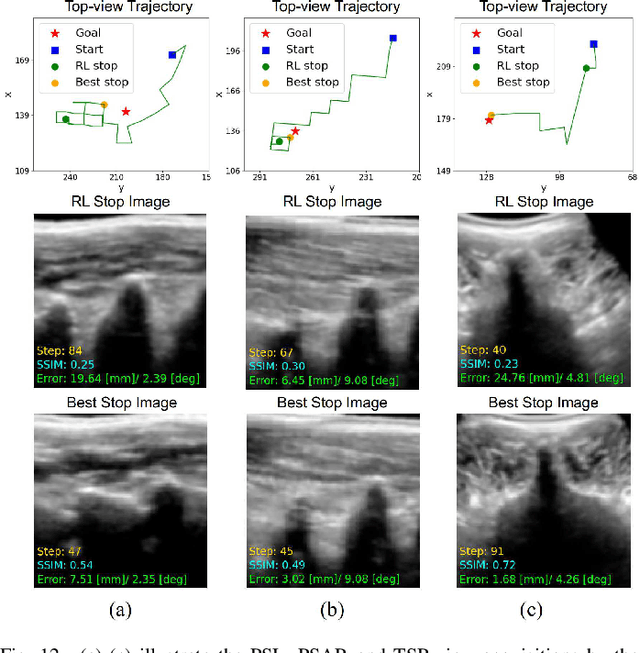
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from 17 volunteers. The average navigation accuracy toward different standard views achieves 5.18mm/5.25deg and 12.87mm/17.49deg in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.
Adding more data does not always help: A study in medical conversation summarization with PEGASUS
Nov 15, 2021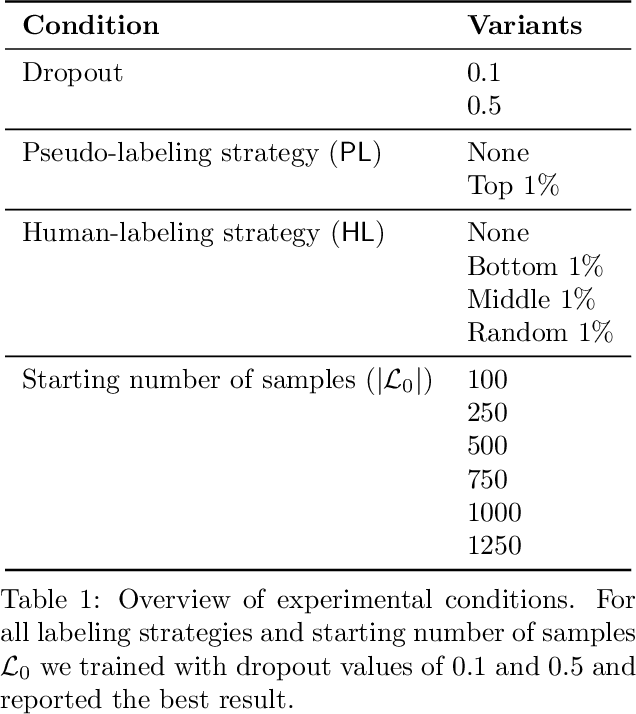
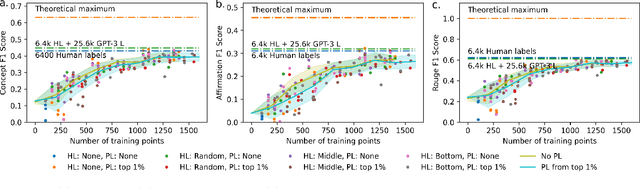
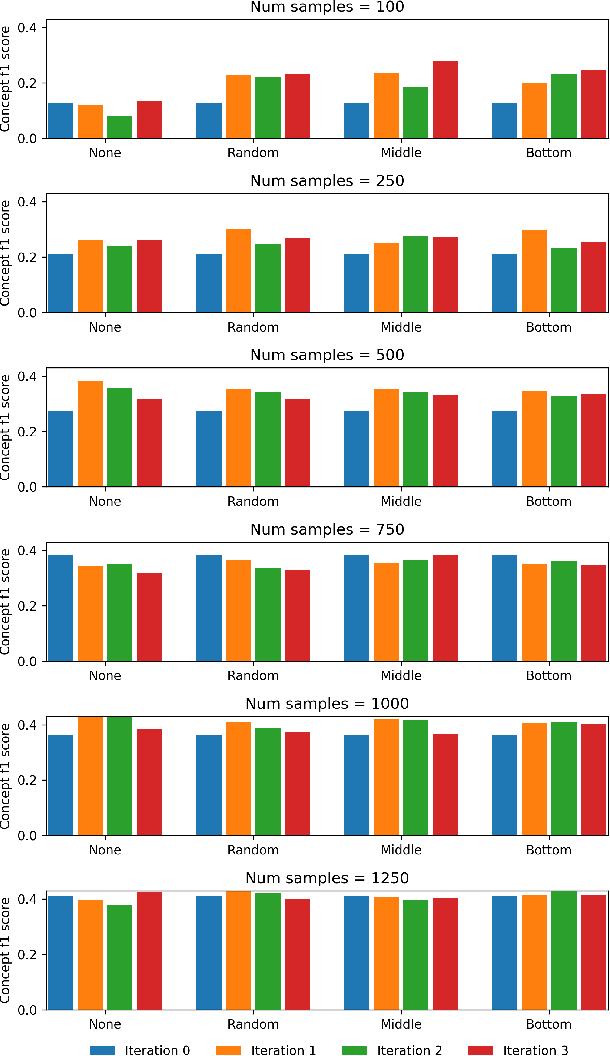
Medical conversation summarization is integral in capturing information gathered during interactions between patients and physicians. Summarized conversations are used to facilitate patient hand-offs between physicians, and as part of providing care in the future. Summaries, however, can be time-consuming to produce and require domain expertise. Modern pre-trained NLP models such as PEGASUS have emerged as capable alternatives to human summarization, reaching state-of-the-art performance on many summarization benchmarks. However, many downstream tasks still require at least moderately sized datasets to achieve satisfactory performance. In this work we (1) explore the effect of dataset size on transfer learning medical conversation summarization using PEGASUS and (2) evaluate various iterative labeling strategies in the low-data regime, following their success in the classification setting. We find that model performance saturates with increase in dataset size and that the various active-learning strategies evaluated all show equivalent performance consistent with simple dataset size increase. We also find that naive iterative pseudo-labeling is on-par or slightly worse than no pseudo-labeling. Our work sheds light on the successes and challenges of translating low-data regime techniques in classification to medical conversation summarization and helps guides future work in this space. Relevant code available at \url{https://github.com/curai/curai-research/tree/main/medical-summarization-ML4H-2021}.
Information Scaling Law of Deep Neural Networks
Feb 13, 2018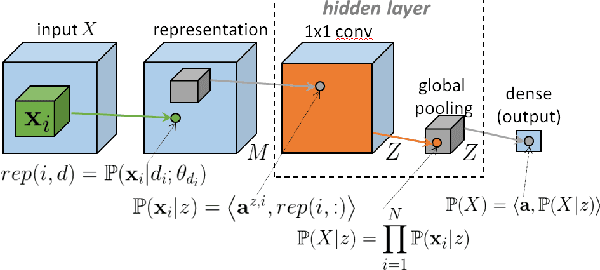
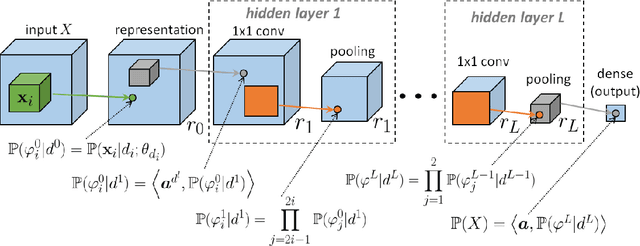
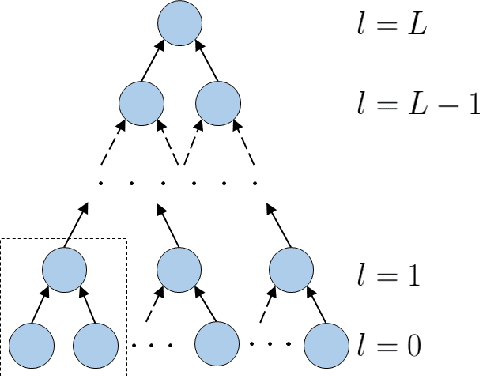
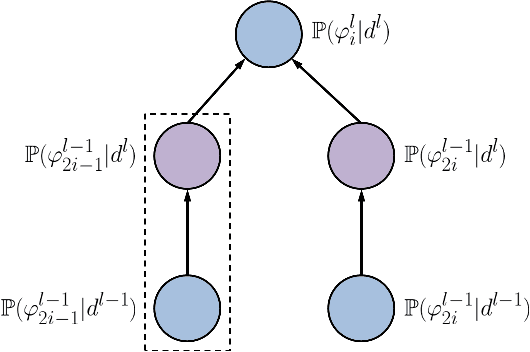
With the rapid development of Deep Neural Networks (DNNs), various network models that show strong computing power and impressive expressive power are proposed. However, there is no comprehensive informational interpretation of DNNs from the perspective of information theory. Due to the nonlinear function and the uncertain number of layers and neural units used in the DNNs, the network structure shows nonlinearity and complexity. With the typical DNNs named Convolutional Arithmetic Circuits (ConvACs), the complex DNNs can be converted into mathematical formula. Thus, we can use rigorous mathematical theory especially the information theory to analyse the complicated DNNs. In this paper, we propose a novel information scaling law scheme that can interpret the network's inner organization by information theory. First, we show the informational interpretation of the activation function. Secondly, we prove that the information entropy increases when the information is transmitted through the ConvACs. Finally, we propose the information scaling law of ConvACs through making a reasonable assumption.
Fast Camouflaged Object Detection via Edge-based Reversible Re-calibration Network
Nov 05, 2021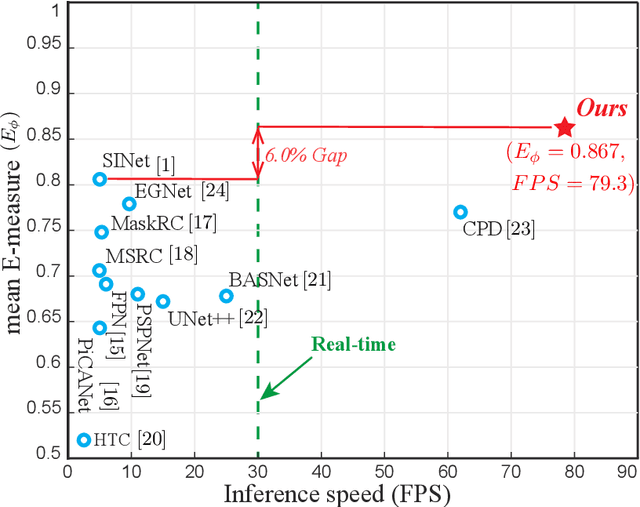
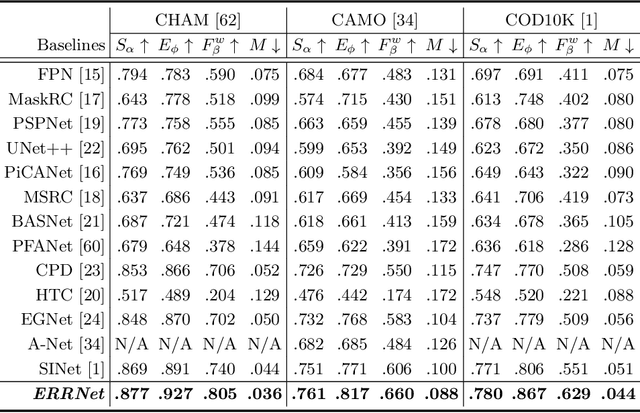
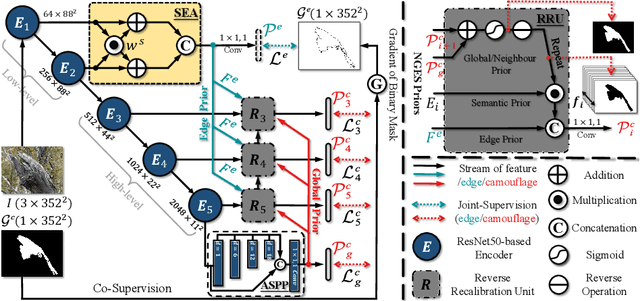
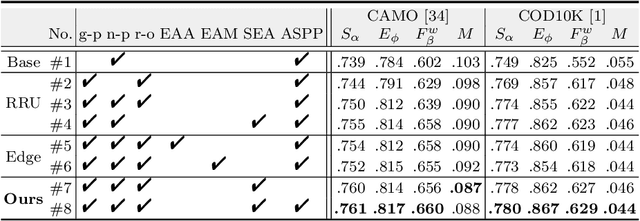
Camouflaged Object Detection (COD) aims to detect objects with similar patterns (e.g., texture, intensity, colour, etc) to their surroundings, and recently has attracted growing research interest. As camouflaged objects often present very ambiguous boundaries, how to determine object locations as well as their weak boundaries is challenging and also the key to this task. Inspired by the biological visual perception process when a human observer discovers camouflaged objects, this paper proposes a novel edge-based reversible re-calibration network called ERRNet. Our model is characterized by two innovative designs, namely Selective Edge Aggregation (SEA) and Reversible Re-calibration Unit (RRU), which aim to model the visual perception behaviour and achieve effective edge prior and cross-comparison between potential camouflaged regions and background. More importantly, RRU incorporates diverse priors with more comprehensive information comparing to existing COD models. Experimental results show that ERRNet outperforms existing cutting-edge baselines on three COD datasets and five medical image segmentation datasets. Especially, compared with the existing top-1 model SINet, ERRNet significantly improves the performance by $\sim$6% (mean E-measure) with notably high speed (79.3 FPS), showing that ERRNet could be a general and robust solution for the COD task.
Nonparanormal Information Estimation
Feb 24, 2017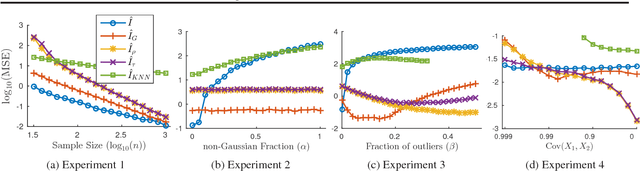
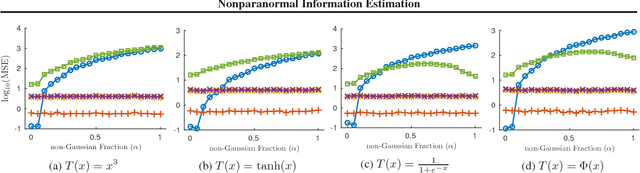
We study the problem of using i.i.d. samples from an unknown multivariate probability distribution $p$ to estimate the mutual information of $p$. This problem has recently received attention in two settings: (1) where $p$ is assumed to be Gaussian and (2) where $p$ is assumed only to lie in a large nonparametric smoothness class. Estimators proposed for the Gaussian case converge in high dimensions when the Gaussian assumption holds, but are brittle, failing dramatically when $p$ is not Gaussian. Estimators proposed for the nonparametric case fail to converge with realistic sample sizes except in very low dimensions. As a result, there is a lack of robust mutual information estimators for many realistic data. To address this, we propose estimators for mutual information when $p$ is assumed to be a nonparanormal (a.k.a., Gaussian copula) model, a semiparametric compromise between Gaussian and nonparametric extremes. Using theoretical bounds and experiments, we show these estimators strike a practical balance between robustness and scaling with dimensionality.