 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Homography-based Visual Servoing with Remote Center of Motion for Semi-autonomous Robotic Endoscope Manipulation
Oct 25, 2021
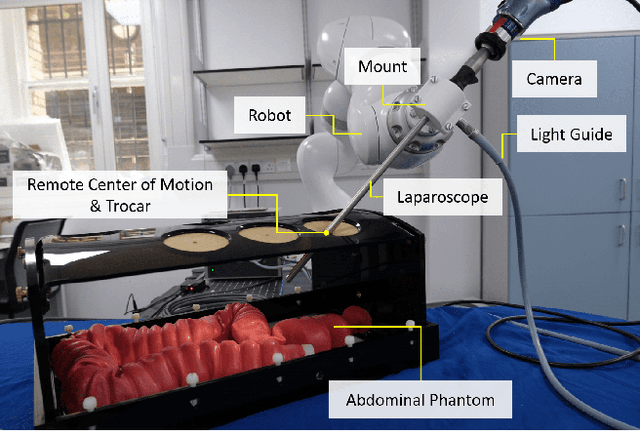
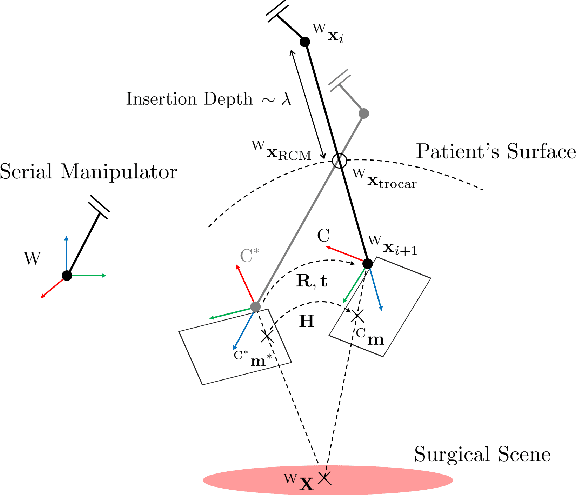
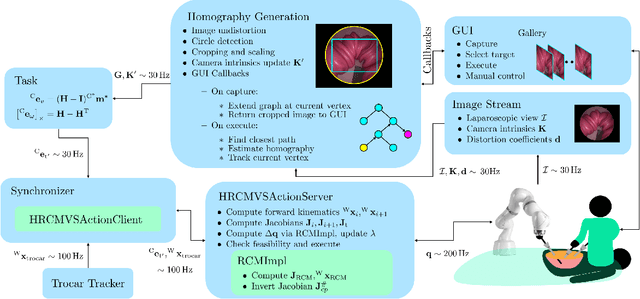
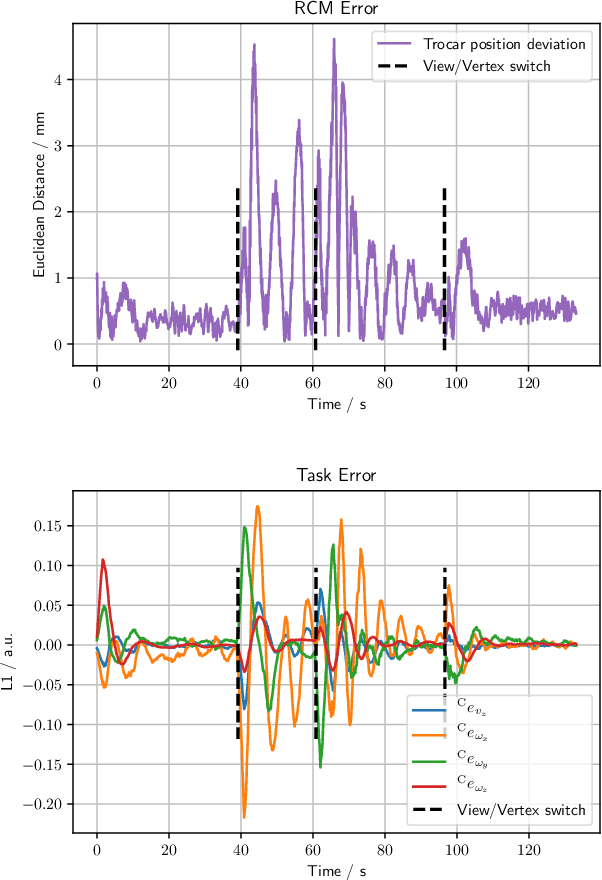
The dominant visual servoing approaches in Minimally Invasive Surgery (MIS) follow single points or adapt the endoscope's field of view based on the surgical tools' distance. These methods rely on point positions with respect to the camera frame to infer a control policy. Deviating from the dominant methods, we formulate a robotic controller that allows for image-based visual servoing that requires neither explicit tool and camera positions nor any explicit image depth information. The proposed method relies on homography-based image registration, which changes the automation paradigm from point-centric towards surgical-scene-centric approach. It simultaneously respects a programmable Remote Center of Motion (RCM). Our approach allows a surgeon to build a graph of desired views, from which, once built, views can be manually selected and automatically servoed to irrespective of robot-patient frame transformation changes. We evaluate our method on an abdominal phantom and provide an open source ROS Moveit integration for use with any serial manipulator.
Inference-InfoGAN: Inference Independence via Embedding Orthogonal Basis Expansion
Oct 02, 2021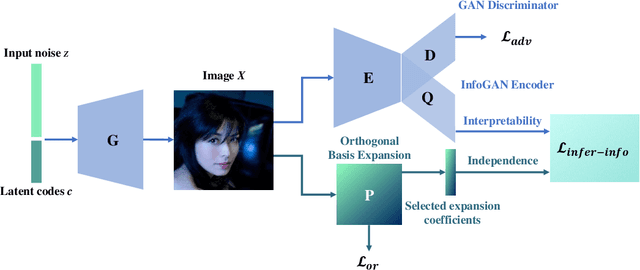
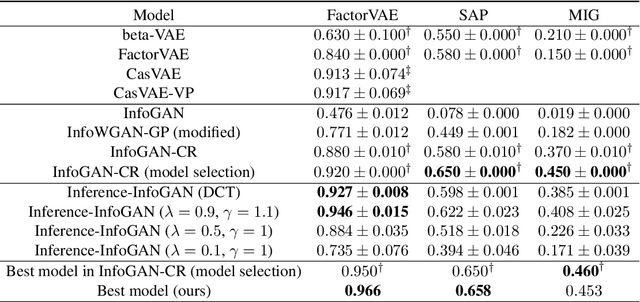
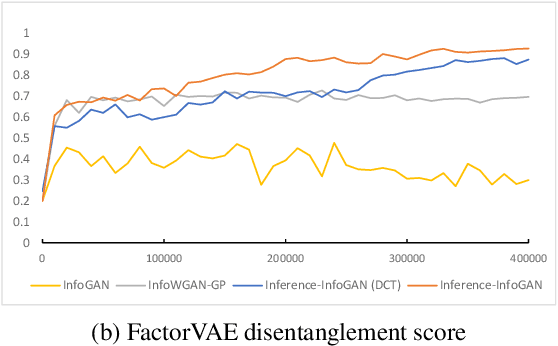
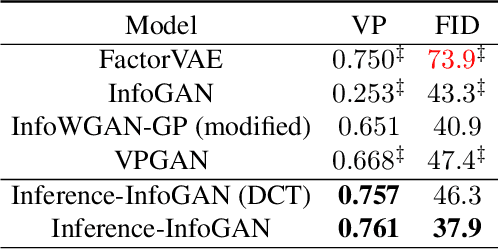
Disentanglement learning aims to construct independent and interpretable latent variables in which generative models are a popular strategy. InfoGAN is a classic method via maximizing Mutual Information (MI) to obtain interpretable latent variables mapped to the target space. However, it did not emphasize independent characteristic. To explicitly infer latent variables with inter-independence, we propose a novel GAN-based disentanglement framework via embedding Orthogonal Basis Expansion (OBE) into InfoGAN network (Inference-InfoGAN) in an unsupervised way. Under the OBE module, one set of orthogonal basis can be adaptively found to expand arbitrary data with independence property. To ensure the target-wise interpretable representation, we add a consistence constraint between the expansion coefficients and latent variables on the base of MI maximization. Additionally, we design an alternating optimization step on the consistence constraint and orthogonal requirement updating, so that the training of Inference-InfoGAN can be more convenient. Finally, experiments validate that our proposed OBE module obtains adaptive orthogonal basis, which can express better independent characteristics than fixed basis expression of Discrete Cosine Transform (DCT). To depict the performance in downstream tasks, we compared with the state-of-the-art GAN-based and even VAE-based approaches on different datasets. Our Inference-InfoGAN achieves higher disentanglement score in terms of FactorVAE, Separated Attribute Predictability (SAP), Mutual Information Gap (MIG) and Variation Predictability (VP) metrics without model fine-tuning. All the experimental results illustrate that our method has inter-independence inference ability because of the OBE module, and provides a good trade-off between it and target-wise interpretability of latent variables via jointing the alternating optimization.
Searching to Learn with Instructional Scaffolding
Nov 29, 2021


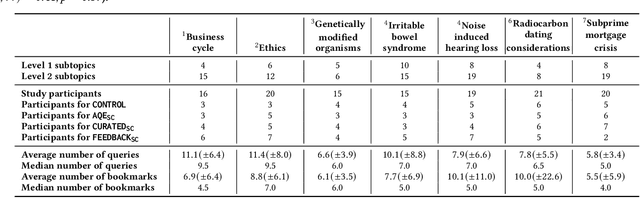
Search engines are considered the primary tool to assist and empower learners in finding information relevant to their learning goals-be it learning something new, improving their existing skills, or just fulfilling a curiosity. While several approaches for improving search engines for the learning scenario have been proposed, instructional scaffolding has not been studied in the context of search as learning, despite being shown to be effective for improving learning in both digital and traditional learning contexts. When scaffolding is employed, instructors provide learners with support throughout their autonomous learning process. We hypothesize that the usage of scaffolding techniques within a search system can be an effective way to help learners achieve their learning objectives whilst searching. As such, this paper investigates the incorporation of scaffolding into a search system employing three different strategies (as well as a control condition): (I) AQE_{SC}, the automatic expansion of user queries with relevant subtopics; (ii) CURATED_{SC}, the presenting of a manually curated static list of relevant subtopics on the search engine result page; and (iii) FEEDBACK_{SC}, which projects real-time feedback about a user's exploration of the topic space on top of the CURATED_{SC} visualization. To investigate the effectiveness of these approaches with respect to human learning, we conduct a user study (N=126) where participants were tasked with searching and learning about topics such as `genetically modified organisms'. We find that (I) the introduction of the proposed scaffolding methods does not significantly improve learning gains. However, (ii) it does significantly impact search behavior. Furthermore, (iii) immediate feedback of the participants' learning leads to undesirable user behavior, with participants focusing on the feedback gauges instead of learning.
Amodal segmentation just like doing a jigsaw
Jul 15, 2021
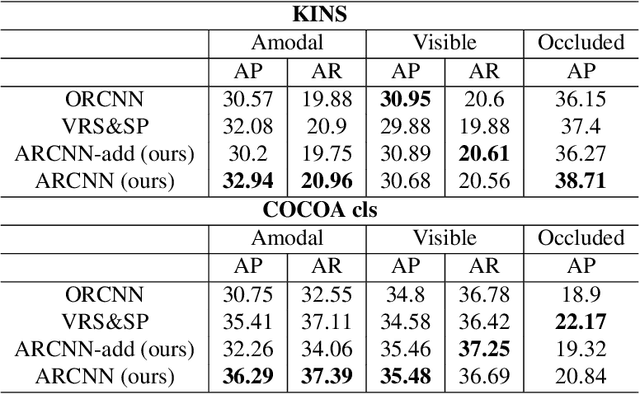
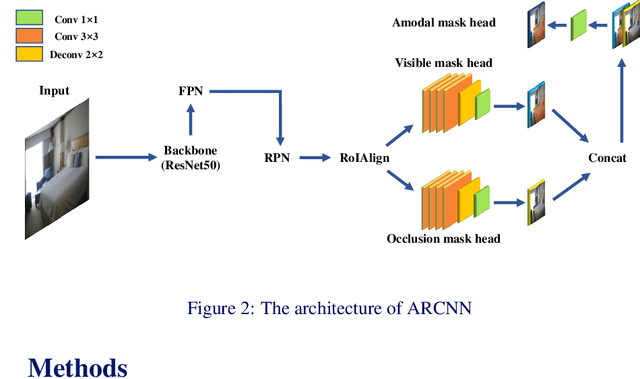
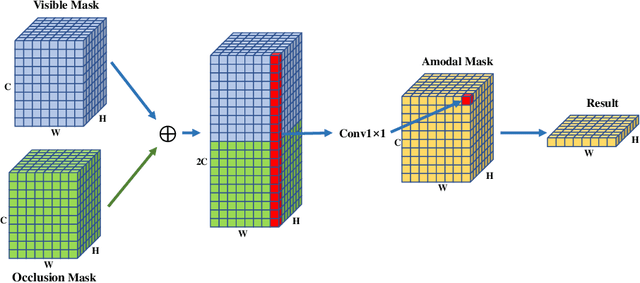
Amodal segmentation is a new direction of instance segmentation while considering the segmentation of the visible and occluded parts of the instance. The existing state-of-the-art method uses multi-task branches to predict the amodal part and the visible part separately and subtract the visible part from the amodal part to obtain the occluded part. However, the amodal part contains visible information. Therefore, the separated prediction method will generate duplicate information. Different from this method, we propose a method of amodal segmentation based on the idea of the jigsaw. The method uses multi-task branches to predict the two naturally decoupled parts of visible and occluded, which is like getting two matching jigsaw pieces. Then put the two jigsaw pieces together to get the amodal part. This makes each branch focus on the modeling of the object. And we believe that there are certain rules in the occlusion relationship in the real world. This is a kind of occlusion context information. This jigsaw method can better model the occlusion relationship and use the occlusion context information, which is important for amodal segmentation. Experiments on two widely used amodally annotated datasets prove that our method exceeds existing state-of-the-art methods. The source code of this work will be made public soon.
Maximum Entropy Weighted Independent Set Pooling for Graph Neural Networks
Jul 03, 2021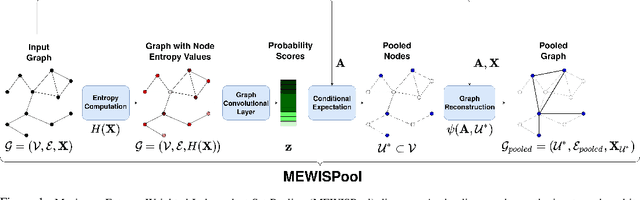
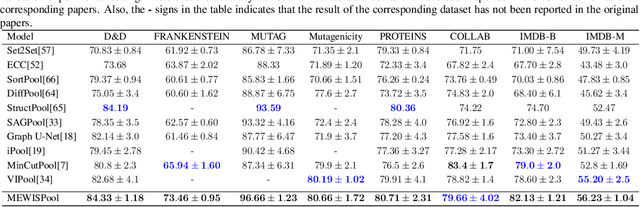
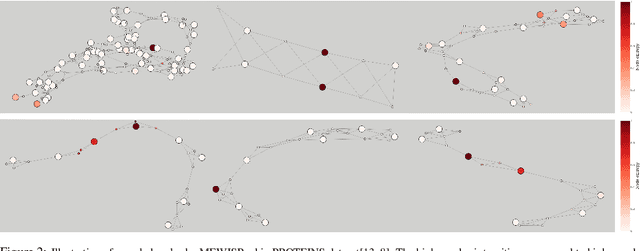
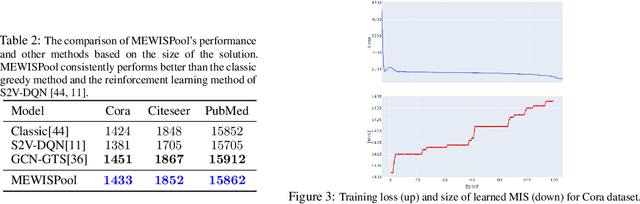
In this paper, we propose a novel pooling layer for graph neural networks based on maximizing the mutual information between the pooled graph and the input graph. Since the maximum mutual information is difficult to compute, we employ the Shannon capacity of a graph as an inductive bias to our pooling method. More precisely, we show that the input graph to the pooling layer can be viewed as a representation of a noisy communication channel. For such a channel, sending the symbols belonging to an independent set of the graph yields a reliable and error-free transmission of information. We show that reaching the maximum mutual information is equivalent to finding a maximum weight independent set of the graph where the weights convey entropy contents. Through this communication theoretic standpoint, we provide a distinct perspective for posing the problem of graph pooling as maximizing the information transmission rate across a noisy communication channel, implemented by a graph neural network. We evaluate our method, referred to as Maximum Entropy Weighted Independent Set Pooling (MEWISPool), on graph classification tasks and the combinatorial optimization problem of the maximum independent set. Empirical results demonstrate that our method achieves the state-of-the-art and competitive results on graph classification tasks and the maximum independent set problem in several benchmark datasets.
Memory-Augmented Non-Local Attention for Video Super-Resolution
Aug 25, 2021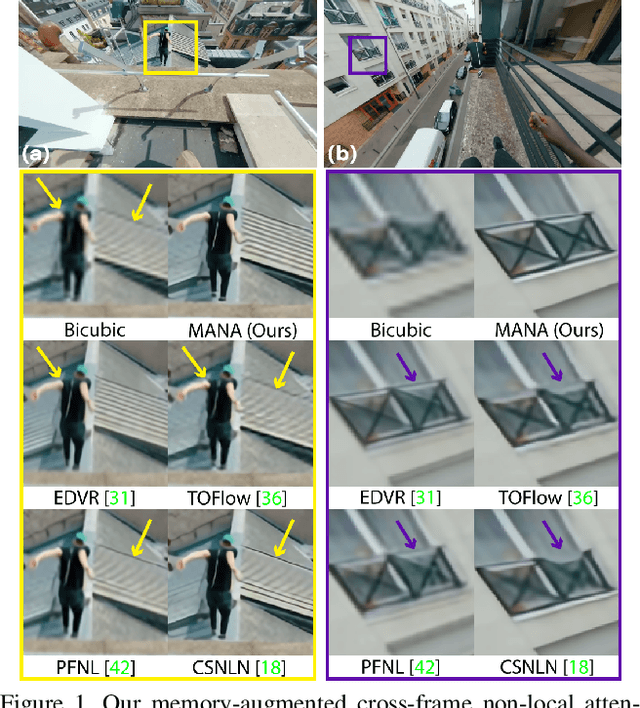
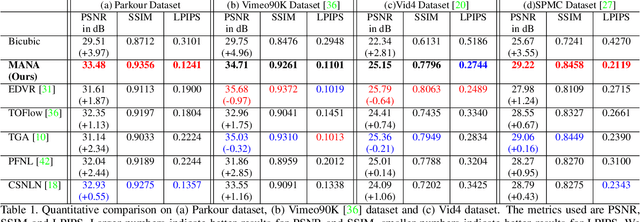
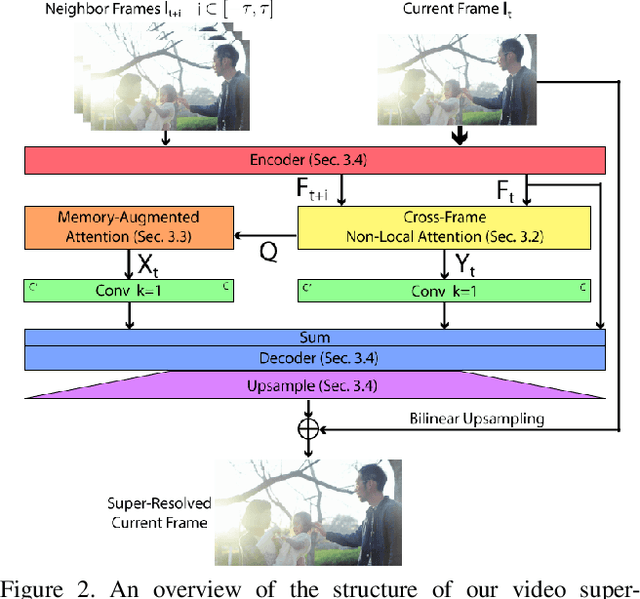
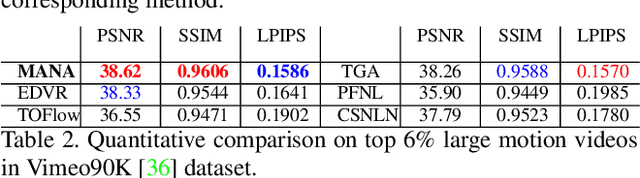
In this paper, we propose a novel video super-resolution method that aims at generating high-fidelity high-resolution (HR) videos from low-resolution (LR) ones. Previous methods predominantly leverage temporal neighbor frames to assist the super-resolution of the current frame. Those methods achieve limited performance as they suffer from the challenge in spatial frame alignment and the lack of useful information from similar LR neighbor frames. In contrast, we devise a cross-frame non-local attention mechanism that allows video super-resolution without frame alignment, leading to be more robust to large motions in the video. In addition, to acquire the information beyond neighbor frames, we design a novel memory-augmented attention module to memorize general video details during the super-resolution training. Experimental results indicate that our method can achieve superior performance on large motion videos comparing to the state-of-the-art methods without aligning frames. Our source code will be released.
Federated Social Recommendation with Graph Neural Network
Nov 21, 2021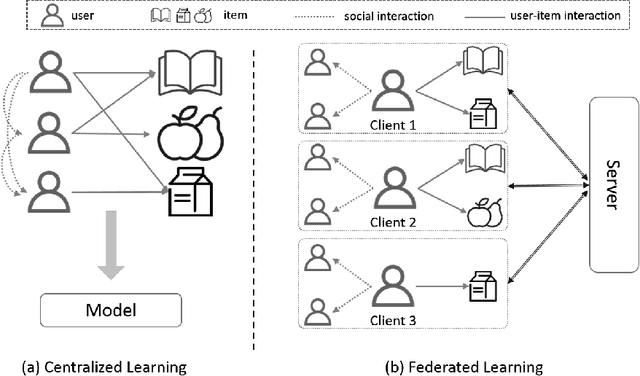


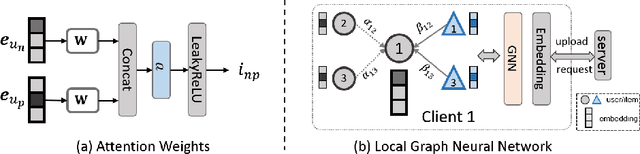
Recommender systems have become prosperous nowadays, designed to predict users' potential interests in items by learning embeddings. Recent developments of the Graph Neural Networks~(GNNs) also provide recommender systems with powerful backbones to learn embeddings from a user-item graph. However, only leveraging the user-item interactions suffers from the cold-start issue due to the difficulty in data collection. Hence, current endeavors propose fusing social information with user-item interactions to alleviate it, which is the social recommendation problem. Existing work employs GNNs to aggregate both social links and user-item interactions simultaneously. However, they all require centralized storage of the social links and item interactions of users, which leads to privacy concerns. Additionally, according to strict privacy protection under General Data Protection Regulation, centralized data storage may not be feasible in the future, urging a decentralized framework of social recommendation. To this end, we devise a novel framework \textbf{Fe}drated \textbf{So}cial recommendation with \textbf{G}raph neural network (FeSoG). Firstly, FeSoG adopts relational attention and aggregation to handle heterogeneity. Secondly, FeSoG infers user embeddings using local data to retain personalization. Last but not least, the proposed model employs pseudo-labeling techniques with item sampling to protect the privacy and enhance training. Extensive experiments on three real-world datasets justify the effectiveness of FeSoG in completing social recommendation and privacy protection. We are the first work proposing a federated learning framework for social recommendation to the best of our knowledge.
Joint Maneuver and Beamforming Design for UAV-Enabled Integrated Sensing and Communication
Oct 06, 2021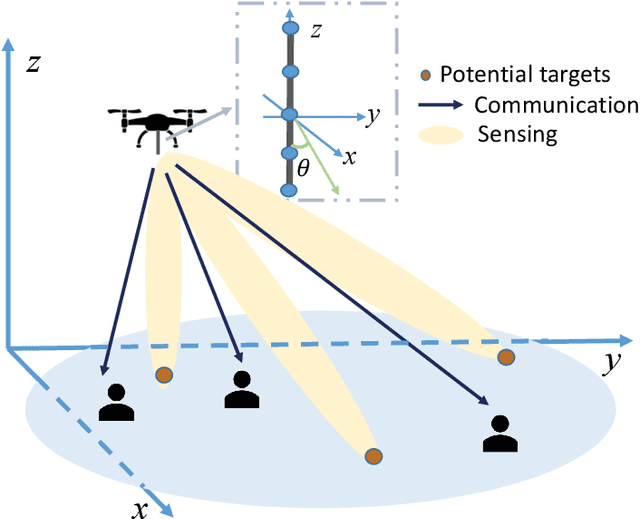
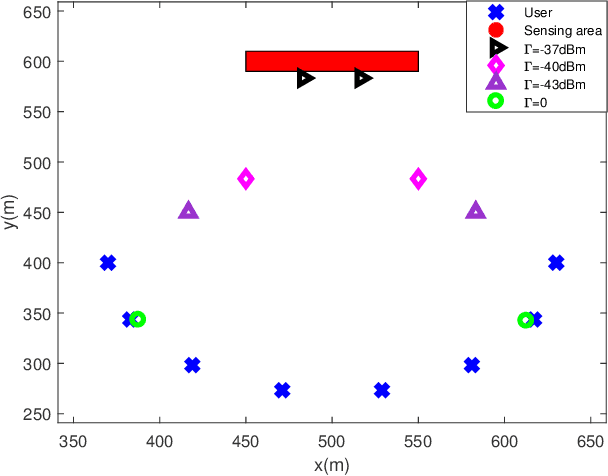
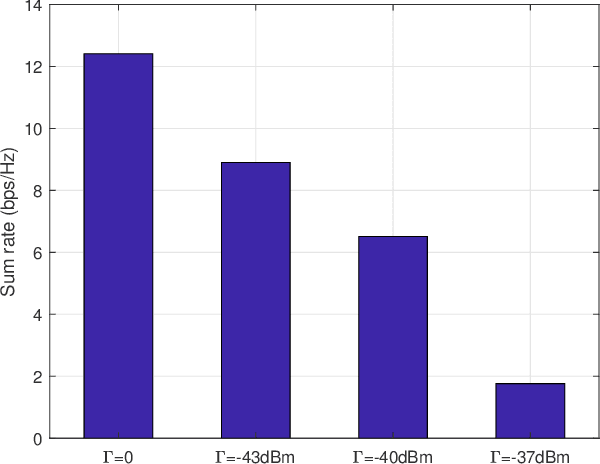
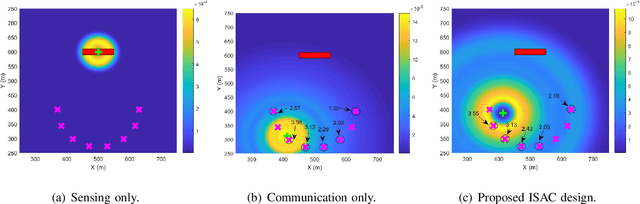
This paper studies the UAV-enabled integrated sensing and communication (ISAC), in which UAVs are dispatched as aerial dual-functional access points (APs) for efficient ISAC. In particular, we consider a scenario with one UAV-AP equipped with a vertically placed uniform linear array (ULA), which sends combined information and sensing signals to communicate with multiple users and sense potential targets at interested areas on the ground simultaneously. Our objective is to jointly design the UAV maneuver with the transmit beamforming for optimizing the communication performance while ensuring the sensing requirements. First, we consider the quasi-stationary UAV scenario, in which the UAV is deployed at an optimizable location over the whole ISAC mission period. In this case, we jointly optimize the UAV deployment location, as well as the transmit information and sensing beamforming to maximize the weighted sum-rate throughput, subject to the sensing beampattern gain requirements and transmit power constraint. Although the above problem is non-convex, we find a high-quality solution by using the techniques of SCA and SDR, together with a 2D location search. Next, we consider the fully mobile UAV scenario, in which the UAV can fly over different locations during the ISAC mission period. In this case, we optimize the UAV flight trajectory, jointly with the transmit beamforming over time, to maximize the average weighted sum-rate throughput, subject to the sensing beampattern gain requirements and transmit power constraints as well as practical flight constraints. While the joint UAV trajectory and beamforming problem is more challenging to solve, we propose an efficient algorithm by adopting the alternating optimization together with SCA. Finally, numerical results are provided to validate the superiority of our proposed designs as compared to various benchmark schemes.
Decoupled Low-light Image Enhancement
Nov 29, 2021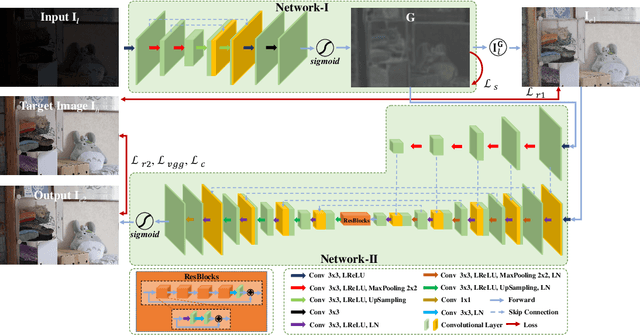
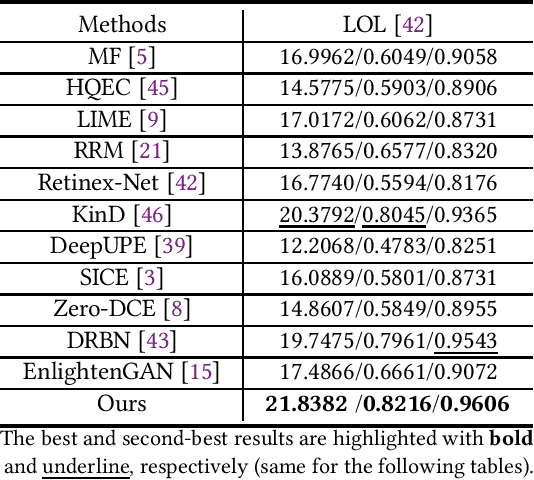

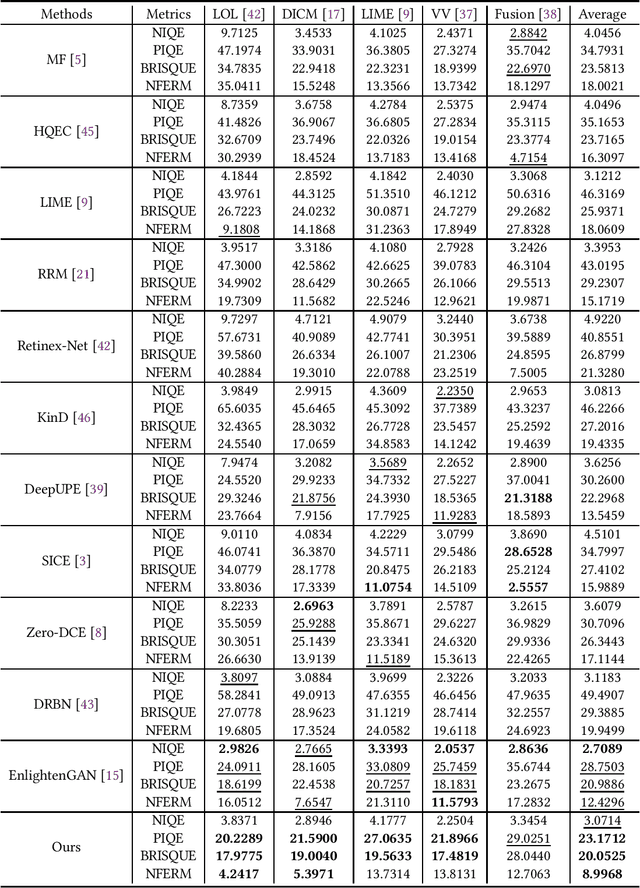
The visual quality of photographs taken under imperfect lightness conditions can be degenerated by multiple factors, e.g., low lightness, imaging noise, color distortion and so on. Current low-light image enhancement models focus on the improvement of low lightness only, or simply deal with all the degeneration factors as a whole, therefore leading to a sub-optimal performance. In this paper, we propose to decouple the enhancement model into two sequential stages. The first stage focuses on improving the scene visibility based on a pixel-wise non-linear mapping. The second stage focuses on improving the appearance fidelity by suppressing the rest degeneration factors. The decoupled model facilitates the enhancement in two aspects. On the one hand, the whole low-light enhancement can be divided into two easier subtasks. The first one only aims to enhance the visibility. It also helps to bridge the large intensity gap between the low-light and normal-light images. In this way, the second subtask can be shaped as the local appearance adjustment. On the other hand, since the parameter matrix learned from the first stage is aware of the lightness distribution and the scene structure, it can be incorporated into the second stage as the complementary information. In the experiments, our model demonstrates the state-of-the-art performance in both qualitative and quantitative comparisons, compared with other low-light image enhancement models. In addition, the ablation studies also validate the effectiveness of our model in multiple aspects, such as model structure and loss function. The trained model is available at https://github.com/hanxuhfut/Decoupled-Low-light-Image-Enhancement.
Self-Supervised Monocular DepthEstimation with Internal Feature Fusion
Oct 18, 2021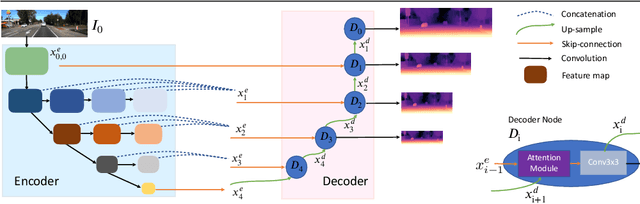
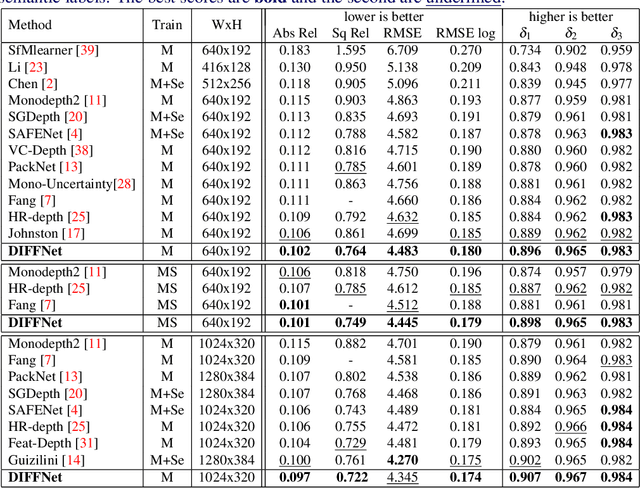

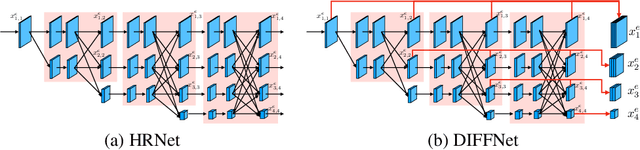
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.