 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Augmented Non-Local Attention for Video Super-Resolution
Paper and Code
Aug 25, 2021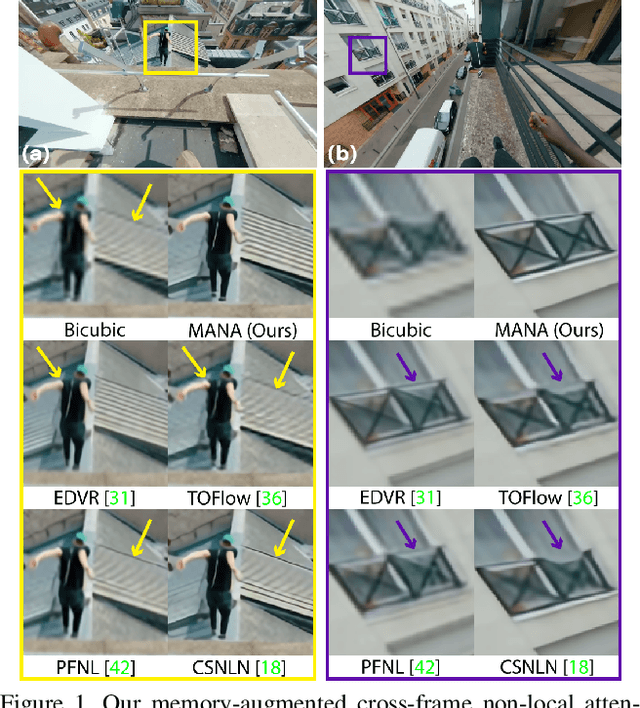
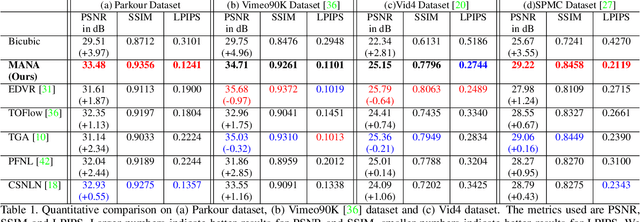
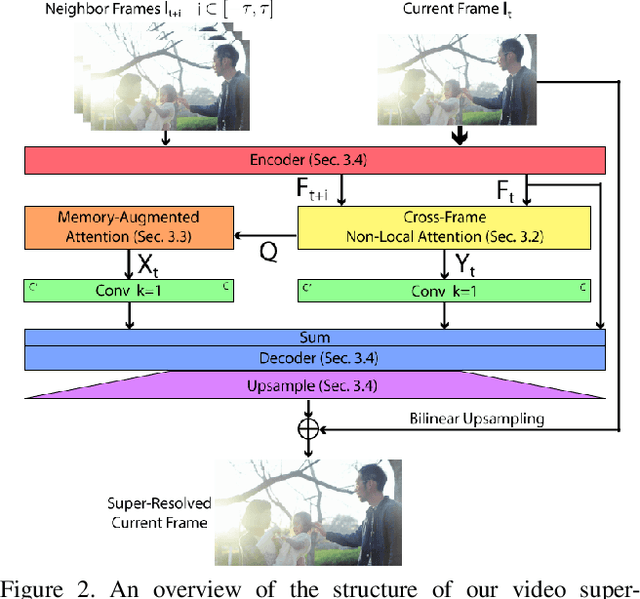
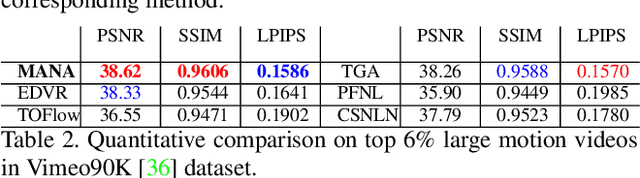
In this paper, we propose a novel video super-resolution method that aims at generating high-fidelity high-resolution (HR) videos from low-resolution (LR) ones. Previous methods predominantly leverage temporal neighbor frames to assist the super-resolution of the current frame. Those methods achieve limited performance as they suffer from the challenge in spatial frame alignment and the lack of useful information from similar LR neighbor frames. In contrast, we devise a cross-frame non-local attention mechanism that allows video super-resolution without frame alignment, leading to be more robust to large motions in the video. In addition, to acquire the information beyond neighbor frames, we design a novel memory-augmented attention module to memorize general video details during the super-resolution training. Experimental results indicate that our method can achieve superior performance on large motion videos comparing to the state-of-the-art methods without aligning frames. Our source code will be released.