 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 22, 2021
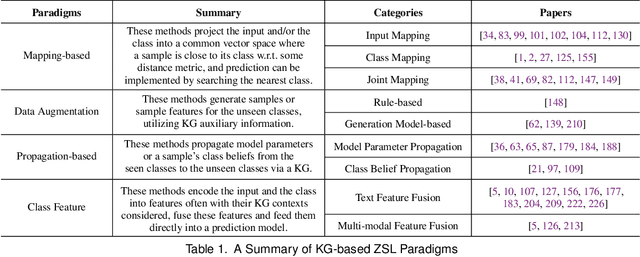
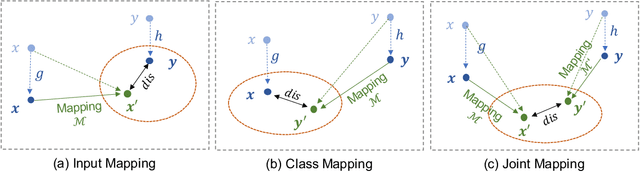
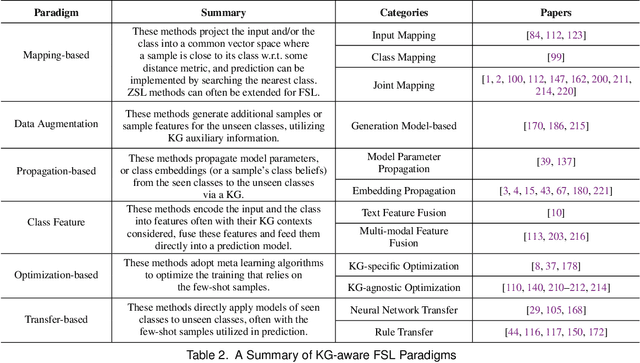
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
Joint State and Input Estimation of Agent Based on Recursive Kalman Filter Given Prior Knowledge
Nov 15, 2021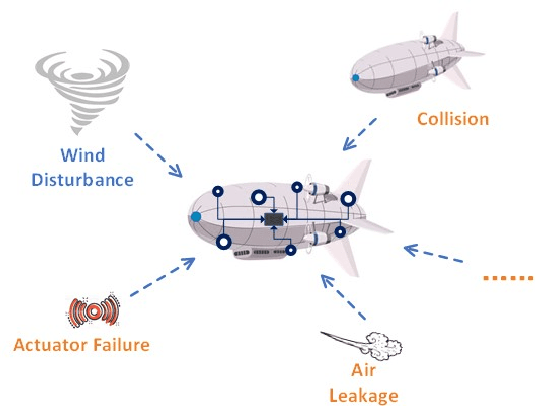
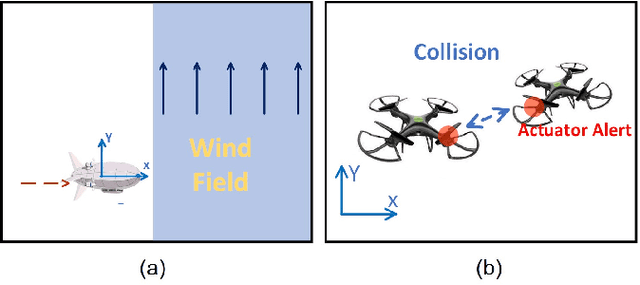
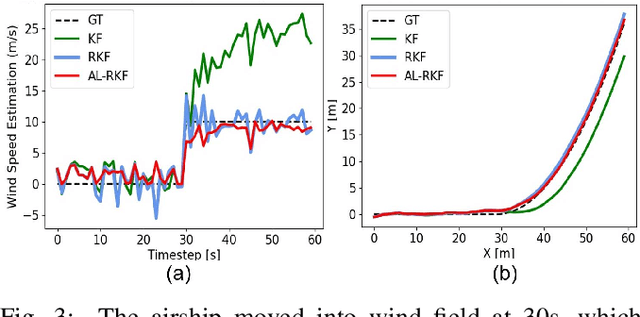
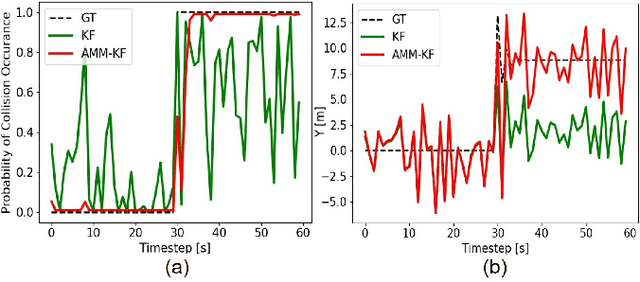
Modern autonomous systems are purposed for many challenging scenarios, where agents will face unexpected events and complicated tasks. The presence of disturbance noise with control command and unknown inputs can negatively impact robot performance. Previous research of joint input and state estimation separately study the continuous and discrete cases without any prior information. This paper combines the continuous space and discrete space estimation into a unified theory based on the Expectation-Maximum (EM) algorithm. By introducing prior knowledge of events as the constraint, inequality optimization problems are formulated to determine a gain matrix or dynamic weights to realize an optimal input estimation with lower variance and more accurate decision-making. Finally, statistical results from experiments show that our algorithm owns 81\% improvement of the variance than KF and 47\% improvement than RKF in continuous space; a remarkable improvement of right decision-making probability of our input estimator in discrete space, identification ability is also analyzed by experiments.
Video-Text Pre-training with Learned Regions
Dec 02, 2021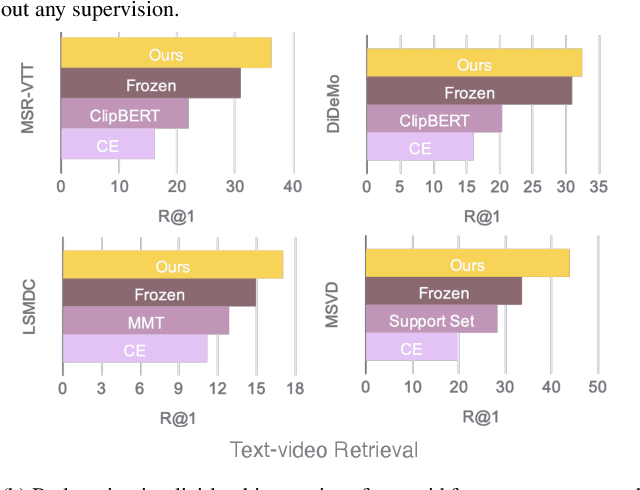
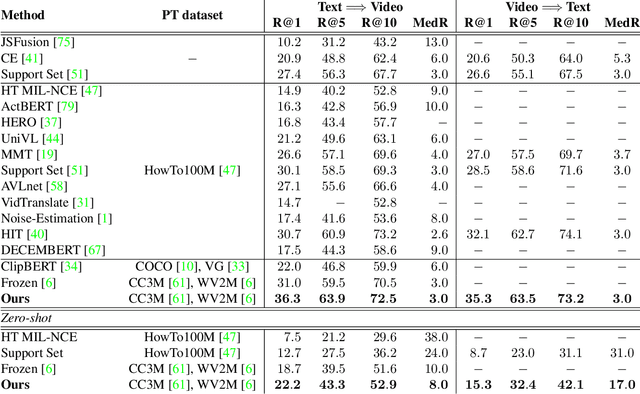
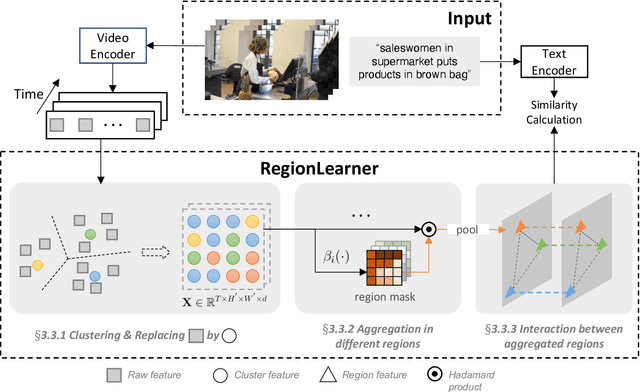
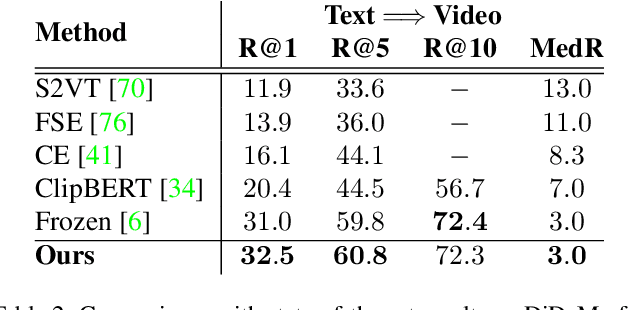
Video-Text pre-training aims at learning transferable representations from large-scale video-text pairs via aligning the semantics between visual and textual information. State-of-the-art approaches extract visual features from raw pixels in an end-to-end fashion. However, these methods operate at frame-level directly and thus overlook the spatio-temporal structure of objects in video, which yet has a strong synergy with nouns in textual descriptions. In this work, we propose a simple yet effective module for video-text representation learning, namely RegionLearner, which can take into account the structure of objects during pre-training on large-scale video-text pairs. Given a video, our module (1) first quantizes visual features into semantic clusters, then (2) generates learnable masks and uses them to aggregate the features belonging to the same semantic region, and finally (3) models the interactions between different aggregated regions. In contrast to using off-the-shelf object detectors, our proposed module does not require explicit supervision and is much more computationally efficient. We pre-train the proposed approach on the public WebVid2M and CC3M datasets. Extensive evaluations on four downstream video-text retrieval benchmarks clearly demonstrate the effectiveness of our RegionLearner. The code will be available at https://github.com/ruiyan1995/Region_Learner.
Boosting Neural Image Compression for Machines Using Latent Space Masking
Dec 15, 2021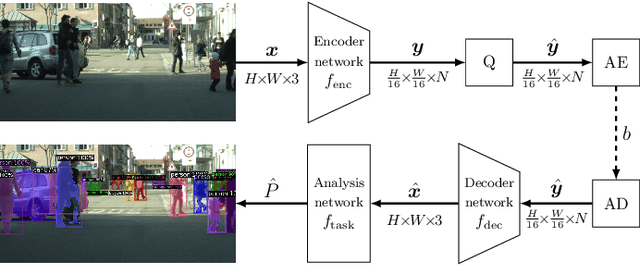
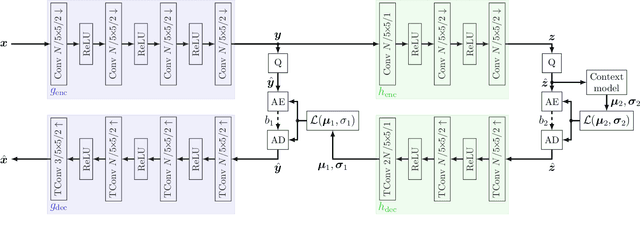
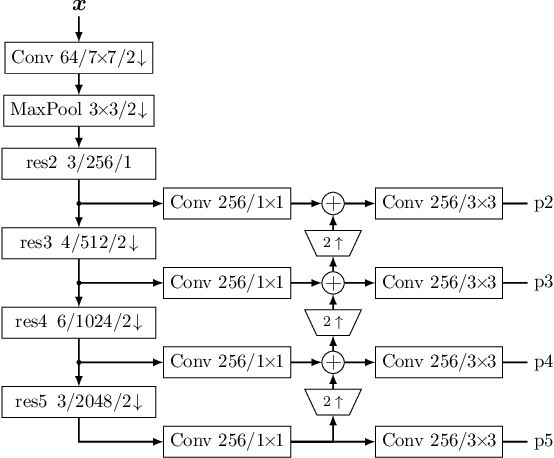
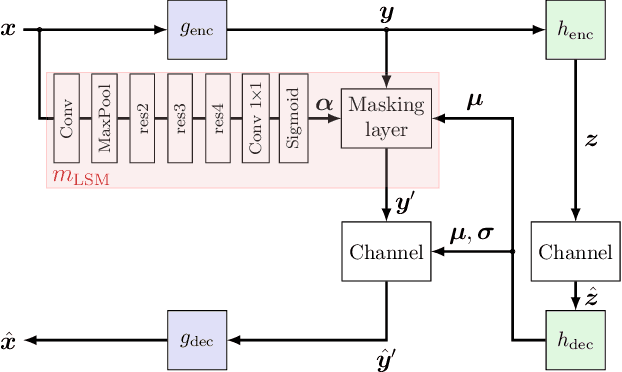
Today, many image coding scenarios do not have a human as final intended user, but rather a machine fulfilling computer vision tasks on the decoded image. Thereby, the primary goal is not to keep visual quality but maintain the task accuracy of the machine for a given bitrate. Due to the tremendous progress of deep neural networks setting benchmarking results, mostly neural networks are employed to solve the analysis tasks at the decoder side. Moreover, neural networks have also found their way into the field of image compression recently. These two developments allow for an end-to-end training of the neural compression network for an analysis network as information sink. Therefore, we first roll out such a training with a task-specific loss to enhance the coding performance of neural compression networks. Compared to the standard VVC, 41.4 % of bitrate are saved by this method for Mask R-CNN as analysis network on the uncompressed Cityscapes dataset. As a main contribution, we propose LSMnet, a network that runs in parallel to the encoder network and masks out elements of the latent space that are presumably not required for the analysis network. By this approach, additional 27.3 % of bitrate are saved compared to the basic neural compression network optimized with the task loss. In addition, we propose a feature-based loss, which allows for a training without annotated data. We provide extensive analyses on the Cityscapes dataset including cross-evaluation with different analysis networks and present exemplary visual results.
"Just Drive": Colour Bias Mitigation for Semantic Segmentation in the Context of Urban Driving
Dec 02, 2021
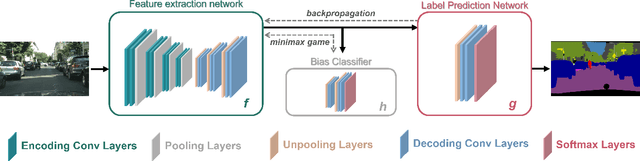
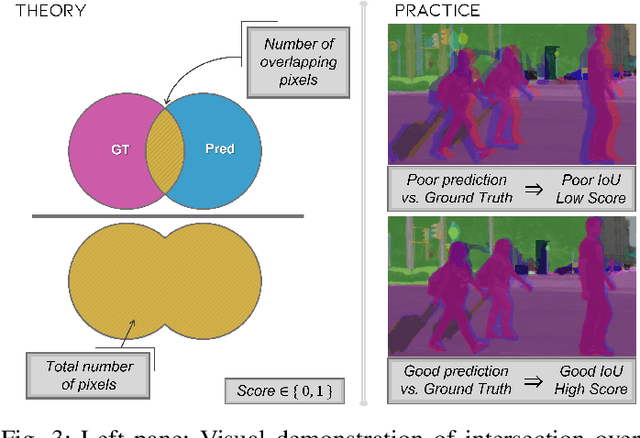
Biases can filter into AI technology without our knowledge. Oftentimes, seminal deep learning networks champion increased accuracy above all else. In this paper, we attempt to alleviate biases encountered by semantic segmentation models in urban driving scenes, via an iteratively trained unlearning algorithm. Convolutional neural networks have been shown to rely on colour and texture rather than geometry. This raises issues when safety-critical applications, such as self-driving cars, encounter images with covariate shift at test time - induced by variations such as lighting changes or seasonality. Conceptual proof of bias unlearning has been shown on simple datasets such as MNIST. However, the strategy has never been applied to the safety-critical domain of pixel-wise semantic segmentation of highly variable training data - such as urban scenes. Trained models for both the baseline and bias unlearning scheme have been tested for performance on colour-manipulated validation sets showing a disparity of up to 85.50% in mIoU from the original RGB images - confirming segmentation networks strongly depend on the colour information in the training data to make their classification. The bias unlearning scheme shows improvements of handling this covariate shift of up to 61% in the best observed case - and performs consistently better at classifying the "human" and "vehicle" classes compared to the baseline model.
A Review on Communication Protocols for Autonomous Unmanned Aerial Vehicles for Inspection Application
Nov 12, 2021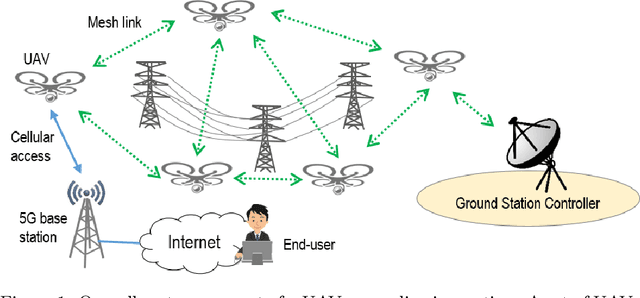
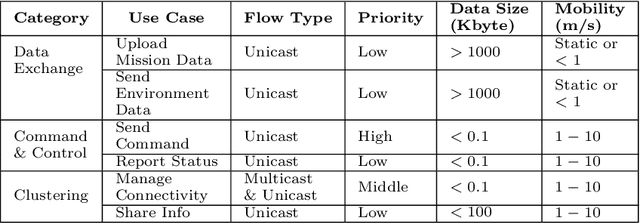
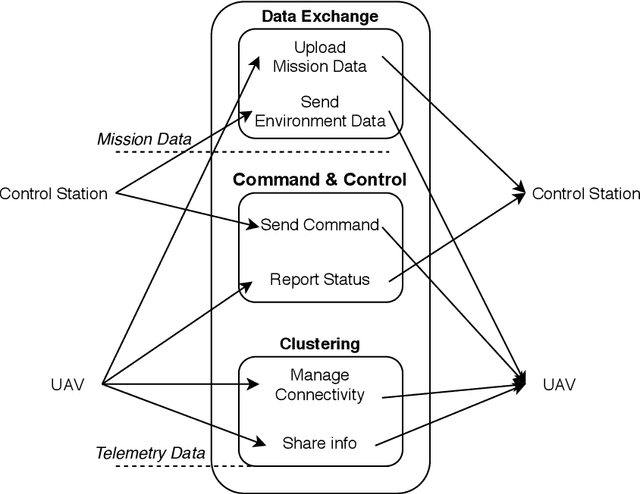
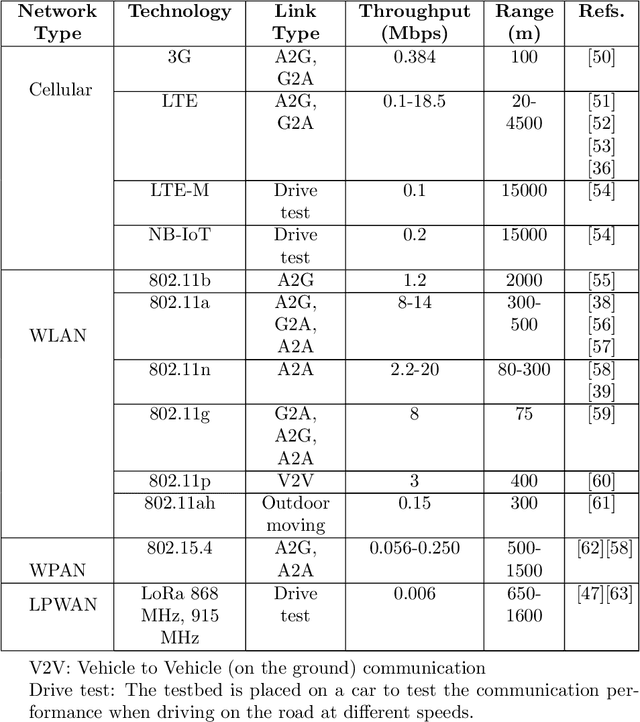
The communication system is a critical part of the system design for the autonomous UAV. It has to address different considerations, including efficiency, reliability and mobility of the UAV. In addition, a multi-UAV system requires a communication system to assist information sharing, task allocation and collaboration in a team of UAVs. In this paper, we review communication solutions for supporting a team of UAVs while considering an application in the power line inspection industry. We provide a review of candidate wireless communication technologies {for supporting communication in UAV applications. Performance measurements and UAV-related channel modeling of those candidate technologies are reviewed. A discussion of current technologies for building UAV mesh networks is presented. We then analyze the structure, interface and performance of robotic communication middleware, ROS and ROS2. Based on our review, the features and dependencies of candidate solutions in each layer of the communication system are presented.
Bayesian AirComp with Sign-Alignment Precoding for Wireless Federated Learning
Sep 14, 2021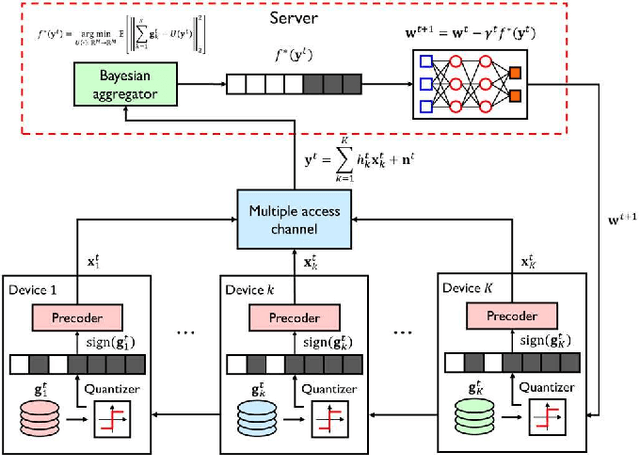
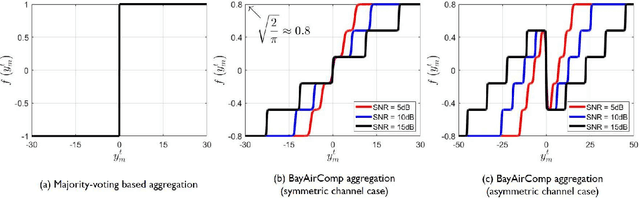
In this paper, we consider the problem of wireless federated learning based on sign stochastic gradient descent (signSGD) algorithm via a multiple access channel. When sending locally computed gradient's sign information, each mobile device requires to apply precoding to circumvent wireless fading effects. In practice, however, acquiring perfect knowledge of channel state information (CSI) at all mobile devices is infeasible. In this paper, we present a simple yet effective precoding method with limited channel knowledge, called sign-alignment precoding. The idea of sign-alignment precoding is to protect sign-flipping errors from wireless fadings. Under the Gaussian prior assumption on the local gradients, we also derive the mean squared error (MSE)-optimal aggregation function called Bayesian over-the-air computation (BayAirComp). Our key finding is that one-bit precoding with BayAirComp aggregation can provide a better learning performance than the existing precoding method even using perfect CSI with AirComp aggregation.
LHRM: A LBS based Heterogeneous Relations Model for User Cold Start Recommendation in Online Travel Platform
Aug 05, 2021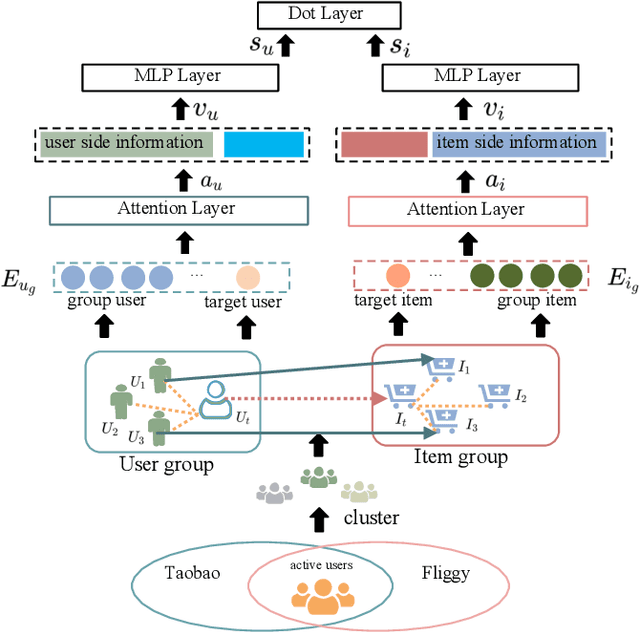
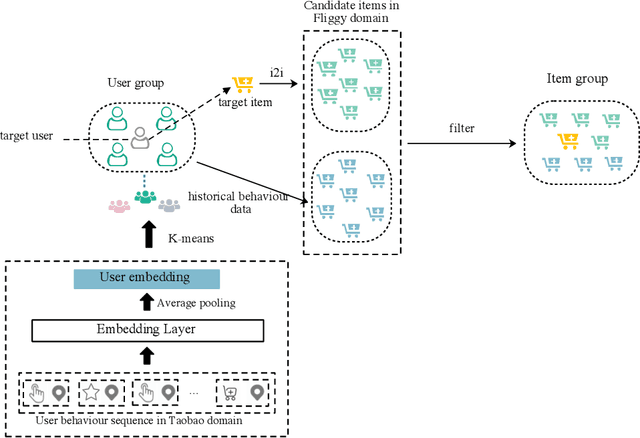
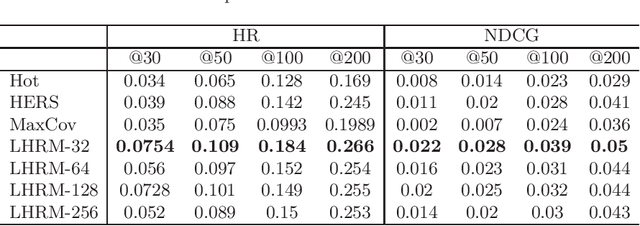
Most current recommender systems used the historical behaviour data of user to predict user' preference. However, it is difficult to recommend items to new users accurately. To alleviate this problem, existing user cold start methods either apply deep learning to build a cross-domain recommender system or map user attributes into the space of user behaviour. These methods are more challenging when applied to online travel platform (e.g., Fliggy), because it is hard to find a cross-domain that user has similar behaviour with travel scenarios and the Location Based Services (LBS) information of users have not been paid sufficient attention. In this work, we propose a LBS-based Heterogeneous Relations Model (LHRM) for user cold start recommendation, which utilizes user's LBS information and behaviour information in related domains and user's behaviour information in travel platforms (e.g., Fliggy) to construct the heterogeneous relations between users and items. Moreover, an attention-based multi-layer perceptron is applied to extract latent factors of users and items. Through this way, LHRM has better generalization performance than existing methods. Experimental results on real data from Fliggy's offline log illustrate the effectiveness of LHRM.
A Nature-Inspired Feature Selection Approach based on Hypercomplex Information
Jan 14, 2021
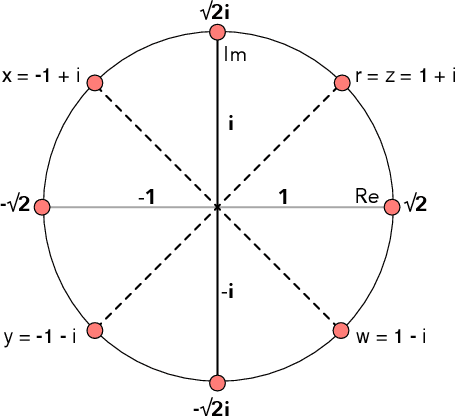

Feature selection for a given model can be transformed into an optimization task. The essential idea behind it is to find the most suitable subset of features according to some criterion. Nature-inspired optimization can mitigate this problem by producing compelling yet straightforward solutions when dealing with complicated fitness functions. Additionally, new mathematical representations, such as quaternions and octonions, are being used to handle higher-dimensional spaces. In this context, we are introducing a meta-heuristic optimization framework in a hypercomplex-based feature selection, where hypercomplex numbers are mapped to real-valued solutions and then transferred onto a boolean hypercube by a sigmoid function. The intended hypercomplex feature selection is tested for several meta-heuristic algorithms and hypercomplex representations, achieving results comparable to some state-of-the-art approaches. The good results achieved by the proposed approach make it a promising tool amongst feature selection research.
* 17 pages, 7 figures
Deep-Learning Based Linear Precoding for MIMO Channels with Finite-Alphabet Signaling
Nov 05, 2021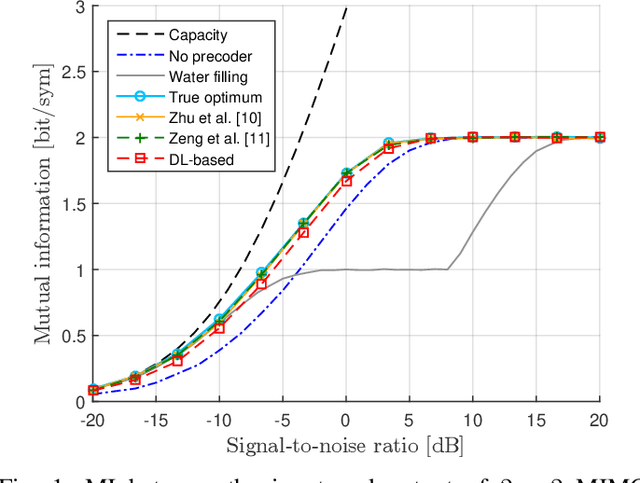

This paper studies the problem of linear precoding for multiple-input multiple-output (MIMO) communication channels employing finite-alphabet signaling. Existing solutions typically suffer from high computational complexity due to costly computations of the constellation-constrained mutual information. In contrast to existing works, this paper takes a different path of tackling the MIMO precoding problem. Namely, a data-driven approach, based on deep learning, is proposed. In the offline training phase, a deep neural network learns the optimal solution on a set of MIMO channel matrices. This allows the reduction of the computational complexity of the precoder optimization in the online inference phase. Numerical results demonstrate the efficiency of the proposed solution vis-\`a-vis existing precoding algorithms in terms of significantly reduced complexity and close-to-optimal performance.
* Published in Physical Communication, 4 pages, 1 figure, 1 table