 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMTM: Cross-Modal Token Modulation for Unsupervised Video Object Segmentation
Apr 16, 2026Recent advances in unsupervised video object segmentation have highlighted the potential of two-stream architectures that integrate appearance and motion cues. However, fully leveraging these complementary sources of information requires effectively modeling their interdependencies. In this paper, we introduce cross-modality token modulation, a novel approach designed to strengthen the interaction between appearance and motion cues. Our method establishes dense connections between tokens from each modality, enabling efficient intra-modal and inter-modal information propagation through relation transformer blocks. To improve learning efficiency, we incorporate a token masking strategy that addresses the limitations of relying solely on increased model complexity. Our approach achieves state-of-the-art performance across all public benchmarks, outperforming existing methods.
Seen-to-Scene: Keep the Seen, Generate the Unseen for Video Outpainting
Apr 16, 2026Video outpainting aims to expand the visible content of a video beyond the original frame boundaries while preserving spatial fidelity and temporal coherence across frames. Existing methods primarily rely on large-scale generative models, such as diffusion models. However, generationbased approaches suffer from implicit temporal modeling and limited spatial context. These limitations lead to intraframe and inter-frame inconsistencies, which become particularly pronounced in dynamic scenes and large outpainting scenarios. To overcome these challenges, we propose Seen-to-Scene, a novel framework that unifies propagationbased and generation-based paradigms for video outpainting. Specifically, Seen-to-Scene leverages flow-based propagation with a flow completion network pre-trained for video inpainting, which is fine-tuned in an end-to-end manner to bridge the domain gap and reconstruct coherent motion fields. To further improve the efficiency and reliability of propagation, we introduce a reference-guided latent propagation that effectively propagates source content across frames. Extensive experiments demonstrate that our method achieves superior temporal coherence and visual realism with efficient inference, surpassing even prior state-of-the-art methods that require input-specific adaptation.
Easy to Learn, Yet Hard to Forget: Towards Robust Unlearning Under Bias
Feb 25, 2026Machine unlearning, which enables a model to forget specific data, is crucial for ensuring data privacy and model reliability. However, its effectiveness can be severely undermined in real-world scenarios where models learn unintended biases from spurious correlations within the data. This paper investigates the unique challenges of unlearning from such biased models. We identify a novel phenomenon we term ``shortcut unlearning," where models exhibit an ``easy to learn, yet hard to forget" tendency. Specifically, models struggle to forget easily-learned, bias-aligned samples; instead of forgetting the class attribute, they unlearn the bias attribute, which can paradoxically improve accuracy on the class intended to be forgotten. To address this, we propose CUPID, a new unlearning framework inspired by the observation that samples with different biases exhibit distinct loss landscape sharpness. Our method first partitions the forget set into causal- and bias-approximated subsets based on sample sharpness, then disentangles model parameters into causal and bias pathways, and finally performs a targeted update by routing refined causal and bias gradients to their respective pathways. Extensive experiments on biased datasets including Waterbirds, BAR, and Biased NICO++ demonstrate that our method achieves state-of-the-art forgetting performance and effectively mitigates the shortcut unlearning problem.
AccuQuant: Simulating Multiple Denoising Steps for Quantizing Diffusion Models
Oct 23, 2025We present in this paper a novel post-training quantization (PTQ) method, dubbed AccuQuant, for diffusion models. We show analytically and empirically that quantization errors for diffusion models are accumulated over denoising steps in a sampling process. To alleviate the error accumulation problem, AccuQuant minimizes the discrepancies between outputs of a full-precision diffusion model and its quantized version within a couple of denoising steps. That is, it simulates multiple denoising steps of a diffusion sampling process explicitly for quantization, accounting the accumulated errors over multiple denoising steps, which is in contrast to previous approaches to imitating a training process of diffusion models, namely, minimizing the discrepancies independently for each step. We also present an efficient implementation technique for AccuQuant, together with a novel objective, which reduces a memory complexity significantly from $\mathcal{O}(n)$ to $\mathcal{O}(1)$, where $n$ is the number of denoising steps. We demonstrate the efficacy and efficiency of AccuQuant across various tasks and diffusion models on standard benchmarks.
Find First, Track Next: Decoupling Identification and Propagation in Referring Video Object Segmentation
Mar 05, 2025



Referring video object segmentation aims to segment and track a target object in a video using a natural language prompt. Existing methods typically fuse visual and textual features in a highly entangled manner, processing multi-modal information together to generate per-frame masks. However, this approach often struggles with ambiguous target identification, particularly in scenes with multiple similar objects, and fails to ensure consistent mask propagation across frames. To address these limitations, we introduce FindTrack, a novel decoupled framework that separates target identification from mask propagation. FindTrack first adaptively selects a key frame by balancing segmentation confidence and vision-text alignment, establishing a robust reference for the target object. This reference is then utilized by a dedicated propagation module to track and segment the object across the entire video. By decoupling these processes, FindTrack effectively reduces ambiguities in target association and enhances segmentation consistency. We demonstrate that FindTrack outperforms existing methods on public benchmarks.
Sparse-DeRF: Deblurred Neural Radiance Fields from Sparse View
Jul 09, 2024



Recent studies construct deblurred neural radiance fields (DeRF) using dozens of blurry images, which are not practical scenarios if only a limited number of blurry images are available. This paper focuses on constructing DeRF from sparse-view for more pragmatic real-world scenarios. As observed in our experiments, establishing DeRF from sparse views proves to be a more challenging problem due to the inherent complexity arising from the simultaneous optimization of blur kernels and NeRF from sparse view. Sparse-DeRF successfully regularizes the complicated joint optimization, presenting alleviated overfitting artifacts and enhanced quality on radiance fields. The regularization consists of three key components: Surface smoothness, helps the model accurately predict the scene structure utilizing unseen and additional hidden rays derived from the blur kernel based on statistical tendencies of real-world; Modulated gradient scaling, helps the model adjust the amount of the backpropagated gradient according to the arrangements of scene objects; Perceptual distillation improves the perceptual quality by overcoming the ill-posed multi-view inconsistency of image deblurring and distilling the pre-filtered information, compensating for the lack of clean information in blurry images. We demonstrate the effectiveness of the Sparse-DeRF with extensive quantitative and qualitative experimental results by training DeRF from 2-view, 4-view, and 6-view blurry images.
TSANET: Temporal and Scale Alignment for Unsupervised Video Object Segmentation
Mar 08, 2023



Unsupervised Video Object Segmentation (UVOS) refers to the challenging task of segmenting the prominent object in videos without manual guidance. In other words, the network detects the accurate region of the target object in a sequence of RGB frames without prior knowledge. In recent works, two approaches for UVOS have been discussed that can be divided into: appearance and appearance-motion based methods. Appearance based methods utilize the correlation information of inter-frames to capture target object that commonly appears in a sequence. However, these methods does not consider the motion of target object due to exploit the correlation information between randomly paired frames. Appearance-motion based methods, on the other hand, fuse the appearance features from RGB frames with the motion features from optical flow. Motion cue provides useful information since salient objects typically show distinctive motion in a sequence. However, these approaches have the limitation that the dependency on optical flow is dominant. In this paper, we propose a novel framework for UVOS that can address aforementioned limitations of two approaches in terms of both time and scale. Temporal Alignment Fusion aligns the saliency information of adjacent frames with the target frame to leverage the information of adjacent frames. Scale Alignment Decoder predicts the target object mask precisely by aggregating differently scaled feature maps via continuous mapping with implicit neural representation. We present experimental results on public benchmark datasets, DAVIS 2016 and FBMS, which demonstrate the effectiveness of our method. Furthermore, we outperform the state-of-the-art methods on DAVIS 2016.
Domain Alignment and Temporal Aggregation for Unsupervised Video Object Segmentation
Nov 22, 2022Unsupervised video object segmentation aims at detecting and segmenting the most salient object in videos. In recent times, two-stream approaches that collaboratively leverage appearance cues and motion cues have attracted extensive attention thanks to their powerful performance. However, there are two limitations faced by those methods: 1) the domain gap between appearance and motion information is not well considered; and 2) long-term temporal coherence within a video sequence is not exploited. To overcome these limitations, we propose a domain alignment module (DAM) and a temporal aggregation module (TAM). DAM resolves the domain gap between two modalities by forcing the values to be in the same range using a cross-correlation mechanism. TAM captures long-term coherence by extracting and leveraging global cues of a video. On public benchmark datasets, our proposed approach demonstrates its effectiveness, outperforming all existing methods by a substantial margin.
Unsupervised Video Object Segmentation via Prototype Memory Network
Sep 08, 2022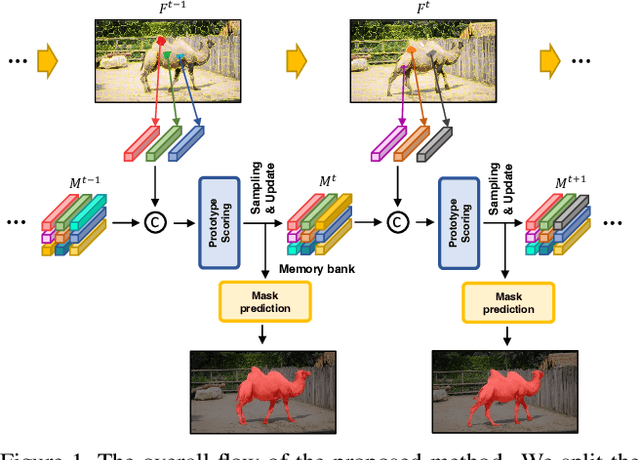
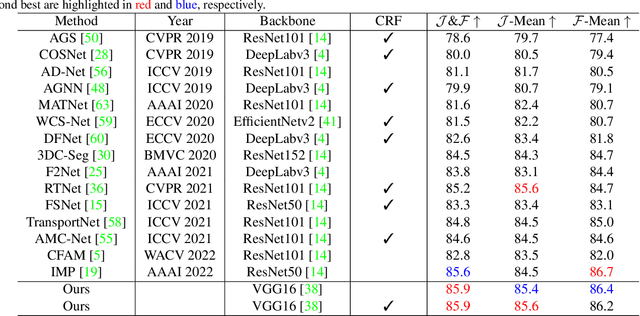

Unsupervised video object segmentation aims to segment a target object in the video without a ground truth mask in the initial frame. This challenging task requires extracting features for the most salient common objects within a video sequence. This difficulty can be solved by using motion information such as optical flow, but using only the information between adjacent frames results in poor connectivity between distant frames and poor performance. To solve this problem, we propose a novel prototype memory network architecture. The proposed model effectively extracts the RGB and motion information by extracting superpixel-based component prototypes from the input RGB images and optical flow maps. In addition, the model scores the usefulness of the component prototypes in each frame based on a self-learning algorithm and adaptively stores the most useful prototypes in memory and discards obsolete prototypes. We use the prototypes in the memory bank to predict the next query frames mask, which enhances the association between distant frames to help with accurate mask prediction. Our method is evaluated on three datasets, achieving state-of-the-art performance. We prove the effectiveness of the proposed model with various ablation studies.
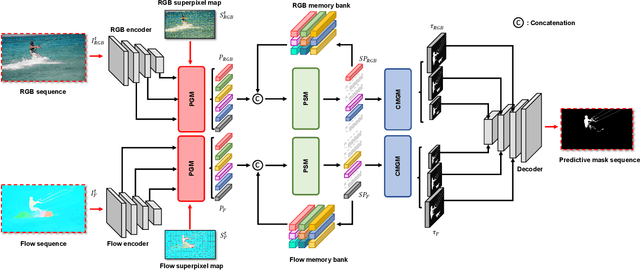
Treating Motion as Option to Reduce Motion Dependency in Unsupervised Video Object Segmentation
Sep 04, 2022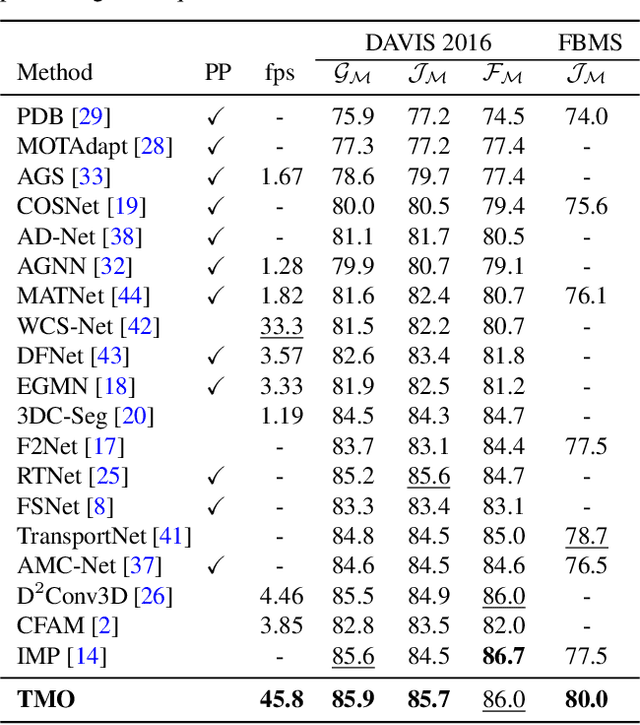
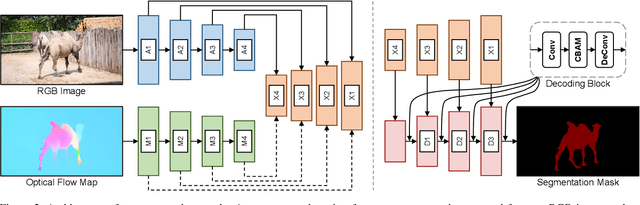
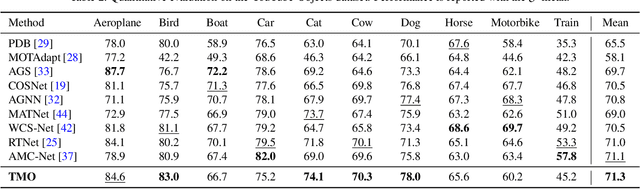

Unsupervised video object segmentation (VOS) aims to detect the most salient object in a video sequence at the pixel level. In unsupervised VOS, most state-of-the-art methods leverage motion cues obtained from optical flow maps in addition to appearance cues to exploit the property that salient objects usually have distinctive movements compared to the background. However, as they are overly dependent on motion cues, which may be unreliable in some cases, they cannot achieve stable prediction. To reduce this motion dependency of existing two-stream VOS methods, we propose a novel motion-as-option network that optionally utilizes motion cues. Additionally, to fully exploit the property of the proposed network that motion is not always required, we introduce a collaborative network learning strategy. On all the public benchmark datasets, our proposed network affords state-of-the-art performance with real-time inference speed.