 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Nov 19, 2021
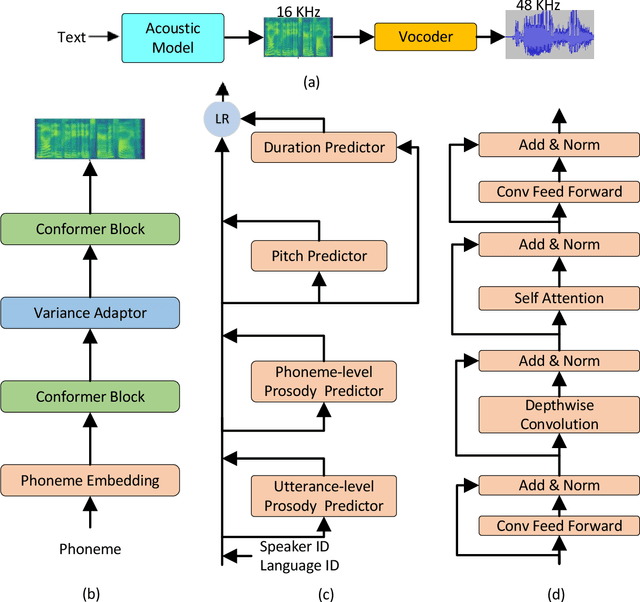
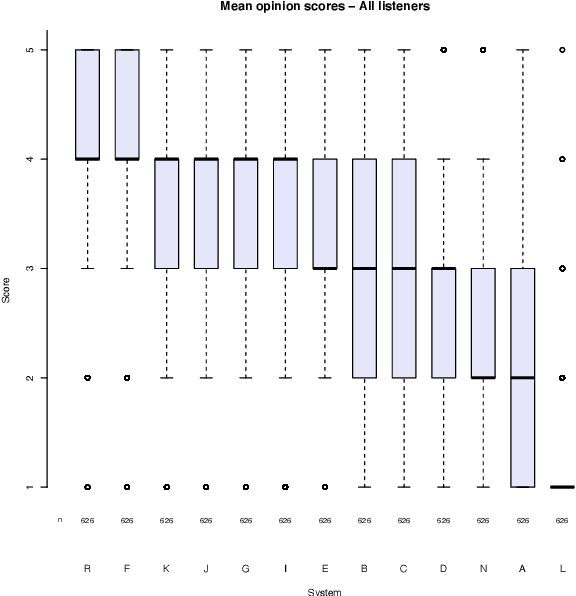
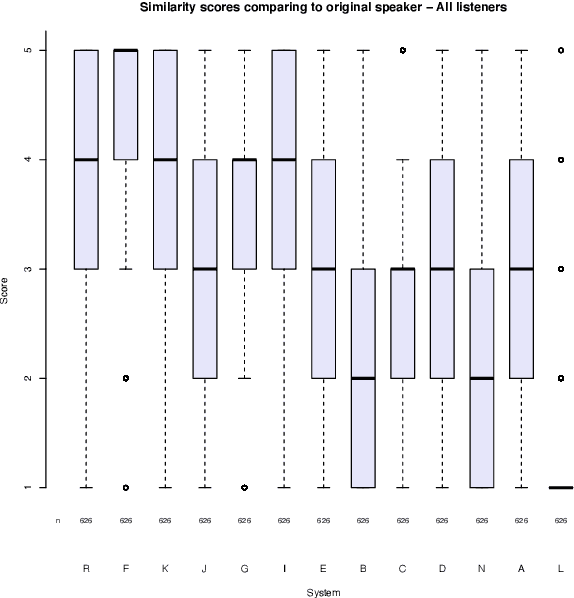
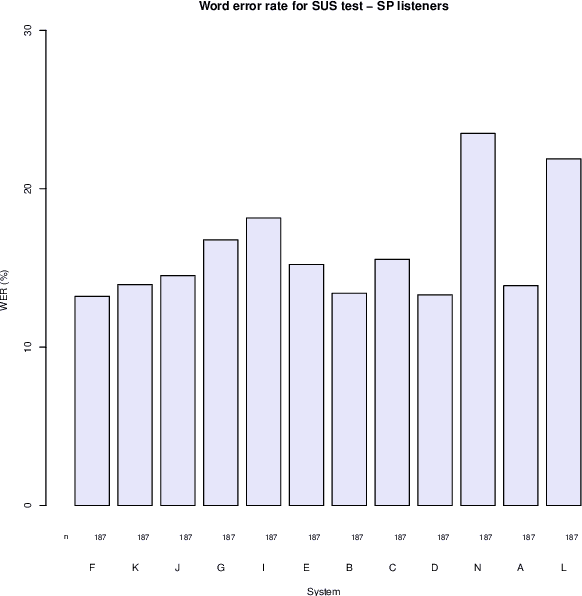
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system
A Temporal Knowledge Graph Completion Method Based on Balanced Timestamp Distribution
Aug 30, 2021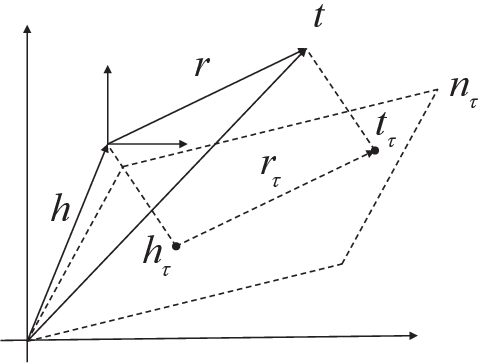


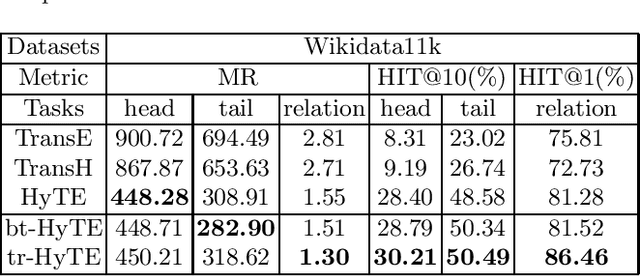
Completion through the embedding representation of the knowledge graph (KGE) has been a research hotspot in recent years. Realistic knowledge graphs are mostly related to time, while most of the existing KGE algorithms ignore the time information. A few existing methods directly or indirectly encode the time information, ignoring the balance of timestamp distribution, which greatly limits the performance of temporal knowledge graph completion (KGC). In this paper, a temporal KGC method is proposed based on the direct encoding time information framework, and a given time slice is treated as the finest granularity for balanced timestamp distribution. A large number of experiments on temporal knowledge graph datasets extracted from the real world demonstrate the effectiveness of our method.
Learning Agent State Online with Recurrent Generate-and-Test
Dec 30, 2021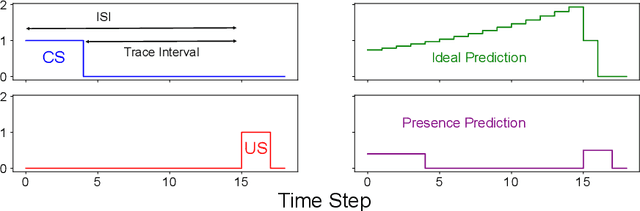
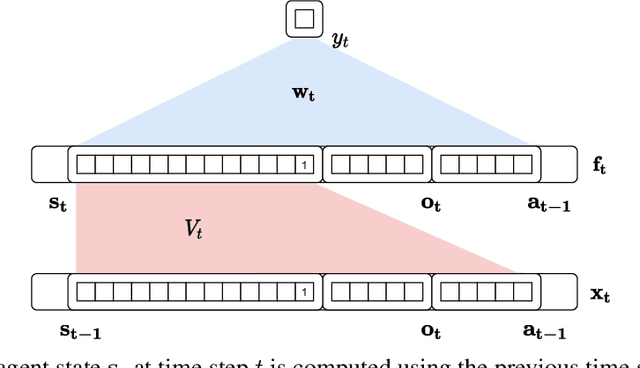
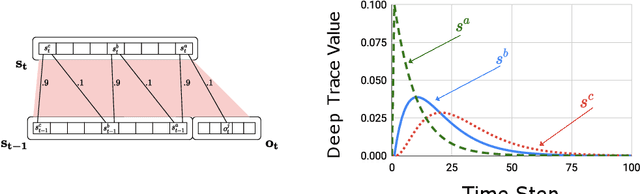
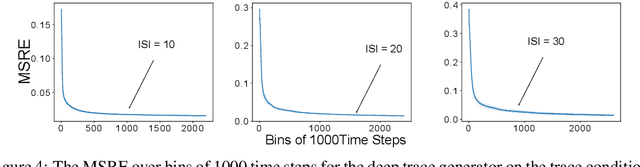
Learning continually and online from a continuous stream of data is challenging, especially for a reinforcement learning agent with sequential data. When the environment only provides observations giving partial information about the state of the environment, the agent must learn the agent state based on the data stream of experience. We refer to the state learned directly from the data stream of experience as the agent state. Recurrent neural networks can learn the agent state, but the training methods are computationally expensive and sensitive to the hyper-parameters, making them unideal for online learning. This work introduces methods based on the generate-and-test approach to learn the agent state. A generate-and-test algorithm searches for state features by generating features and testing their usefulness. In this process, features useful for the agent's performance on the task are preserved, and the least useful features get replaced with newly generated features. We study the effectiveness of our methods on two online multi-step prediction problems. The first problem, trace conditioning, focuses on the agent's ability to remember a cue for a prediction multiple steps into the future. In the second problem, trace patterning, the agent needs to learn patterns in the observation signals and remember them for future predictions. We show that our proposed methods can effectively learn the agent state online and produce accurate predictions.
The SOFC-Exp Corpus and Neural Approaches to Information Extraction in the Materials Science Domain
Jun 04, 2020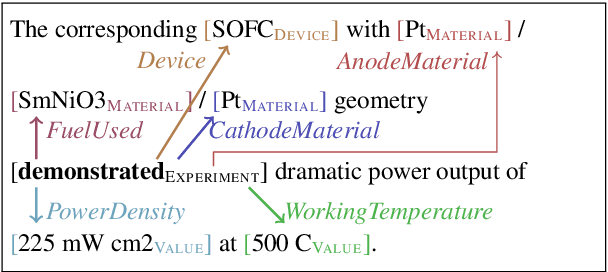
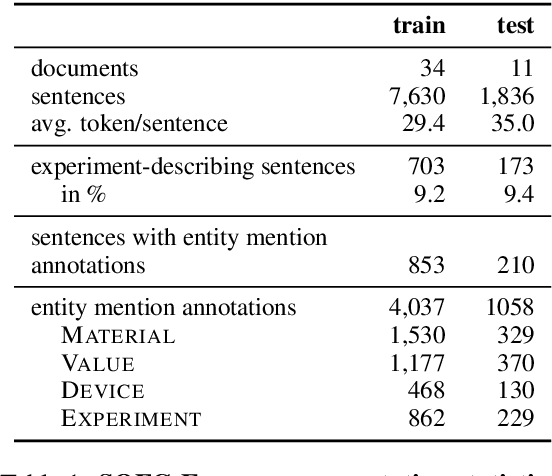
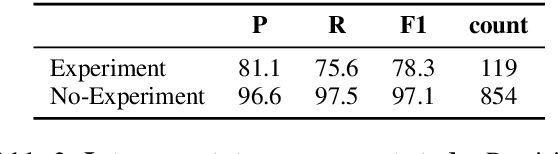
This paper presents a new challenging information extraction task in the domain of materials science. We develop an annotation scheme for marking information on experiments related to solid oxide fuel cells in scientific publications, such as involved materials and measurement conditions. With this paper, we publish our annotation guidelines, as well as our SOFC-Exp corpus consisting of 45 open-access scholarly articles annotated by domain experts. A corpus and an inter-annotator agreement study demonstrate the complexity of the suggested named entity recognition and slot filling tasks as well as high annotation quality. We also present strong neural-network based models for a variety of tasks that can be addressed on the basis of our new data set. On all tasks, using BERT embeddings leads to large performance gains, but with increasing task complexity, adding a recurrent neural network on top seems beneficial. Our models will serve as competitive baselines in future work, and analysis of their performance highlights difficult cases when modeling the data and suggests promising research directions.
Interpreting deep urban sound classification using Layer-wise Relevance Propagation
Nov 19, 2021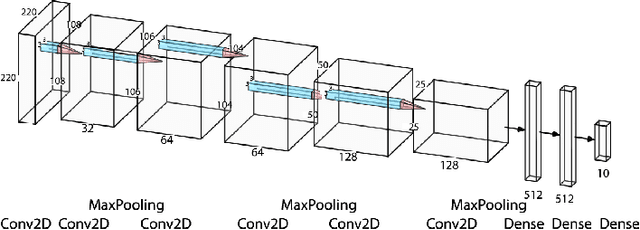
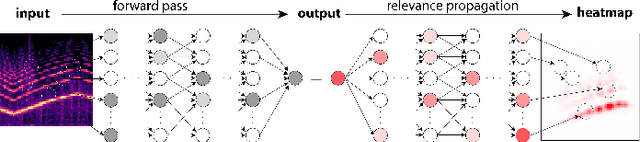
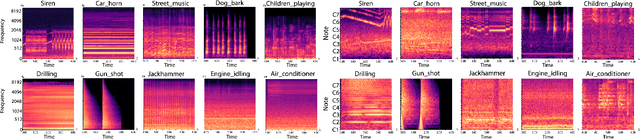
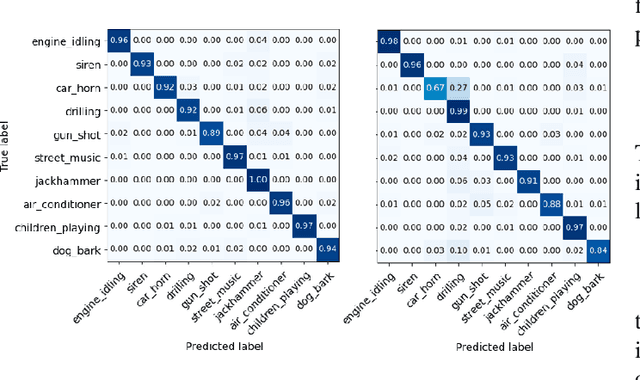
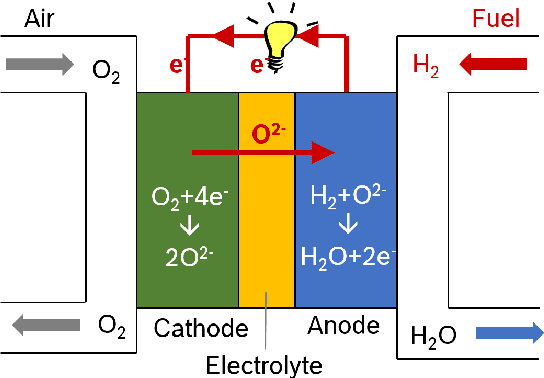
After constructing a deep neural network for urban sound classification, this work focuses on the sensitive application of assisting drivers suffering from hearing loss. As such, clear etiology justifying and interpreting model predictions comprise a strong requirement. To this end, we used two different representations of audio signals, i.e. Mel and constant-Q spectrograms, while the decisions made by the deep neural network are explained via layer-wise relevance propagation. At the same time, frequency content assigned with high relevance in both feature sets, indicates extremely discriminative information characterizing the present classification task. Overall, we present an explainable AI framework for understanding deep urban sound classification.
Distribution Knowledge Embedding for Graph Pooling
Sep 29, 2021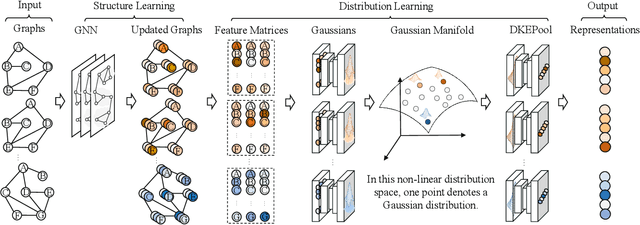
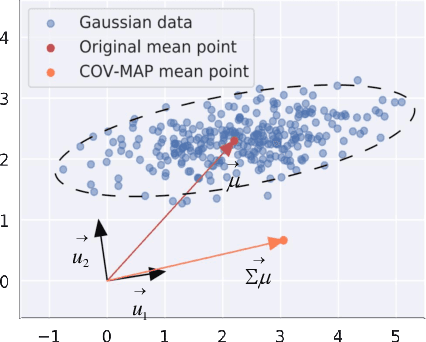
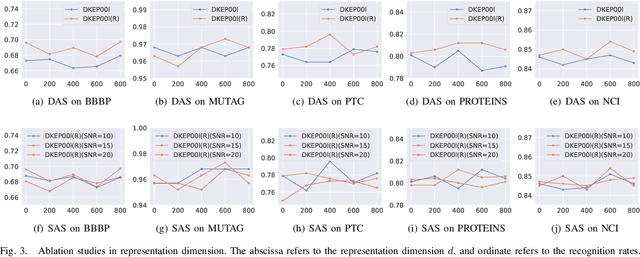
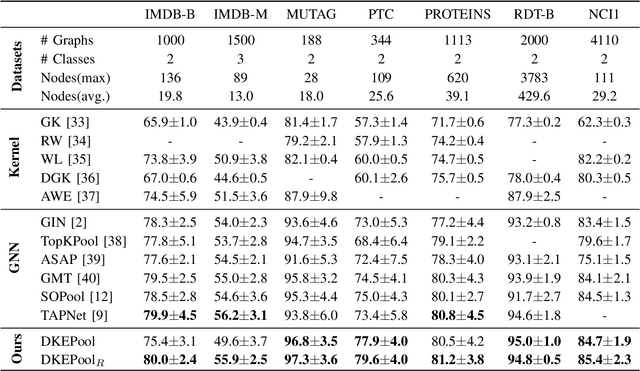
Graph-level representation learning is the pivotal step for downstream tasks that operate on the whole graph. The most common approach to this problem heretofore is graph pooling, where node features are typically averaged or summed to obtain the graph representations. However, pooling operations like averaging or summing inevitably cause massive information missing, which may severely downgrade the final performance. In this paper, we argue what is crucial to graph-level downstream tasks includes not only the topological structure but also the distribution from which nodes are sampled. Therefore, powered by existing Graph Neural Networks (GNN), we propose a new plug-and-play pooling module, termed as Distribution Knowledge Embedding (DKEPool), where graphs are rephrased as distributions on top of GNNs and the pooling goal is to summarize the entire distribution information instead of retaining a certain feature vector by simple predefined pooling operations. A DKEPool network de facto disassembles representation learning into two stages, structure learning and distribution learning. Structure learning follows a recursive neighborhood aggregation scheme to update node features where structure information is obtained. Distribution learning, on the other hand, omits node interconnections and focuses more on the distribution depicted by all the nodes. Extensive experiments demonstrate that the proposed DKEPool significantly and consistently outperforms the state-of-the-art methods.
Damage Estimation and Localization from Sparse Aerial Imagery
Nov 05, 2021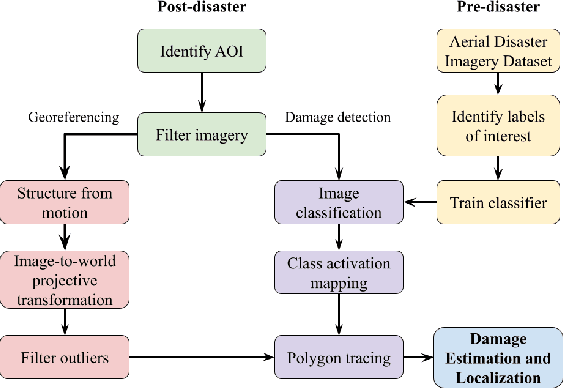

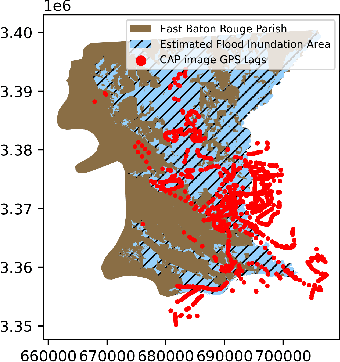
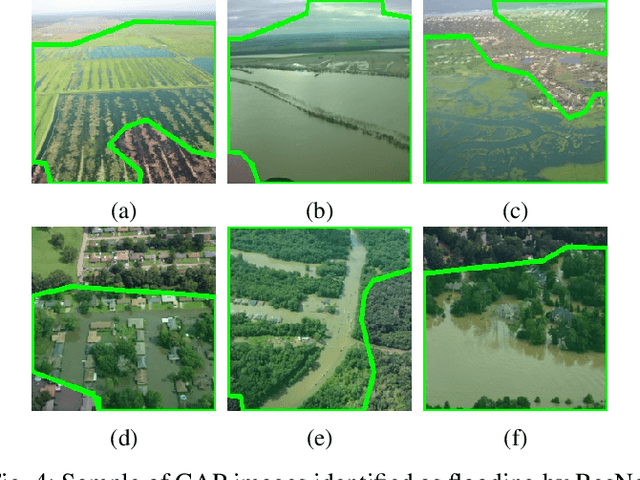
Aerial images provide important situational awareness for responding to natural disasters such as hurricanes. They are well-suited for providing information for damage estimation and localization (DEL); i.e., characterizing the type and spatial extent of damage following a disaster. Despite recent advances in sensing and unmanned aerial systems technology, much of post-disaster aerial imagery is still taken by handheld DSLR cameras from small, manned, fixed-wing aircraft. However, these handheld cameras lack IMU information, and images are taken opportunistically post-event by operators. As such, DEL from such imagery is still a highly manual and time-consuming process. We propose an approach to both detect damage in aerial images and localize it in world coordinates, with specific focus on detecting and localizing flooding. The approach is based on using structure from motion to relate image coordinates to world coordinates via a projective transformation, using class activation mapping to detect the extent of damage in an image, and applying the projective transformation to localize damage in world coordinates. We evaluate the performance of our approach on post-event data from the 2016 Louisiana floods, and find that our approach achieves a precision of 88%. Given this high precision using limited data, we argue that this approach is currently viable for fast and effective DEL from handheld aerial imagery for disaster response.
CLUE: Contextualised Unified Explainable Learning of User Engagement in Video Lectures
Jan 14, 2022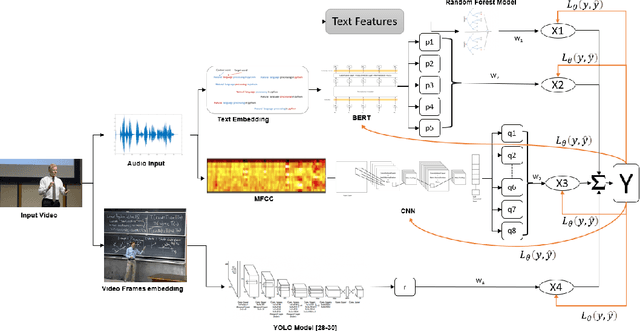
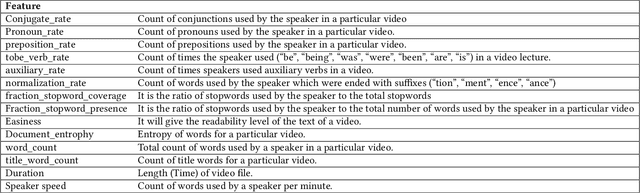
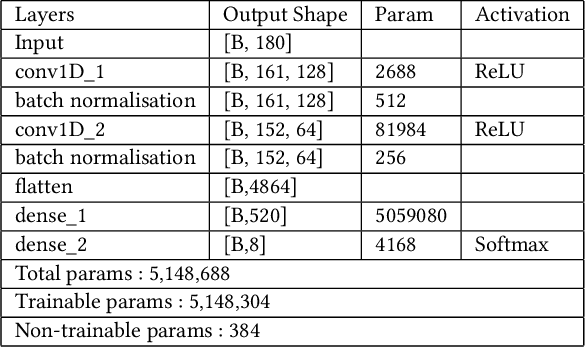
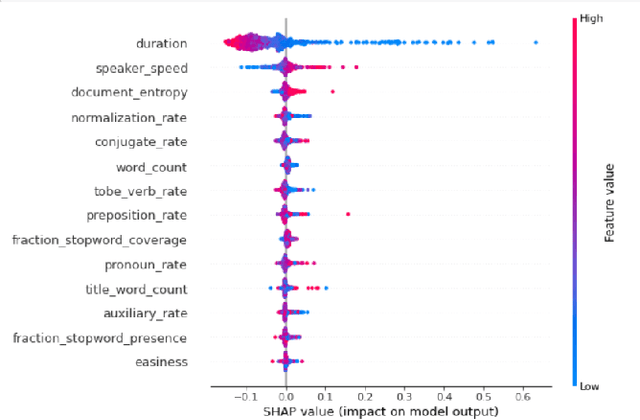
Predicting contextualised engagement in videos is a long-standing problem that has been popularly attempted by exploiting the number of views or the associated likes using different computational methods. The recent decade has seen a boom in online learning resources, and during the pandemic, there has been an exponential rise of online teaching videos without much quality control. The quality of the content could be improved if the creators could get constructive feedback on their content. Employing an army of domain expert volunteers to provide feedback on the videos might not scale. As a result, there has been a steep rise in developing computational methods to predict a user engagement score that is indicative of some form of possible user engagement, i.e., to what level a user would tend to engage with the content. A drawback in current methods is that they model various features separately, in a cascaded approach, that is prone to error propagation. Besides, most of them do not provide crucial explanations on how the creator could improve their content. In this paper, we have proposed a new unified model, CLUE for the educational domain, which learns from the features extracted from freely available public online teaching videos and provides explainable feedback on the video along with a user engagement score. Given the complexity of the task, our unified framework employs different pre-trained models working together as an ensemble of classifiers. Our model exploits various multi-modal features to model the complexity of language, context agnostic information, textual emotion of the delivered content, animation, speaker's pitch and speech emotions. Under a transfer learning setup, the overall model, in the unified space, is fine-tuned for downstream applications.
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
Jun 25, 2019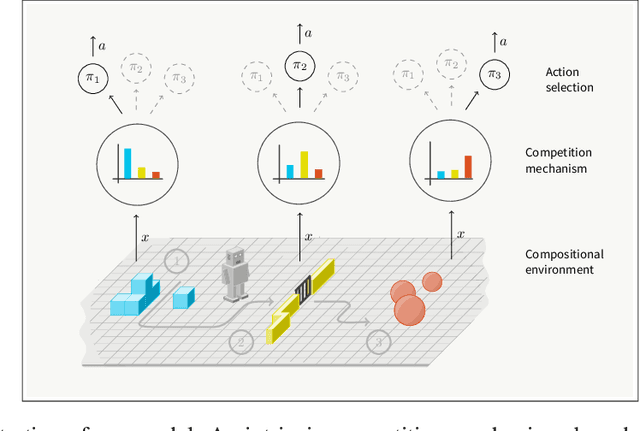

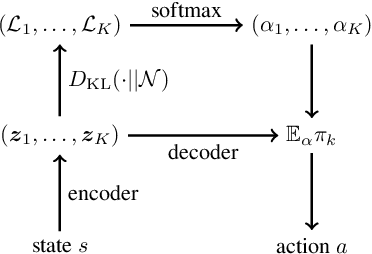
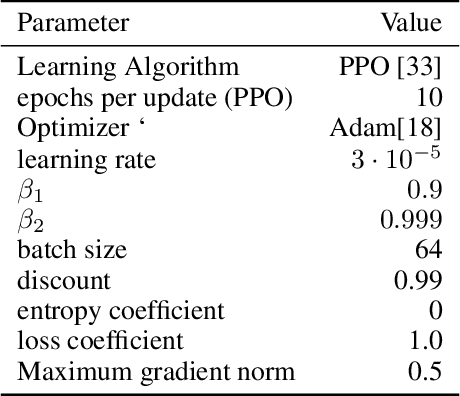
Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.
Couplformer:Rethinking Vision Transformer with Coupling Attention Map
Dec 10, 2021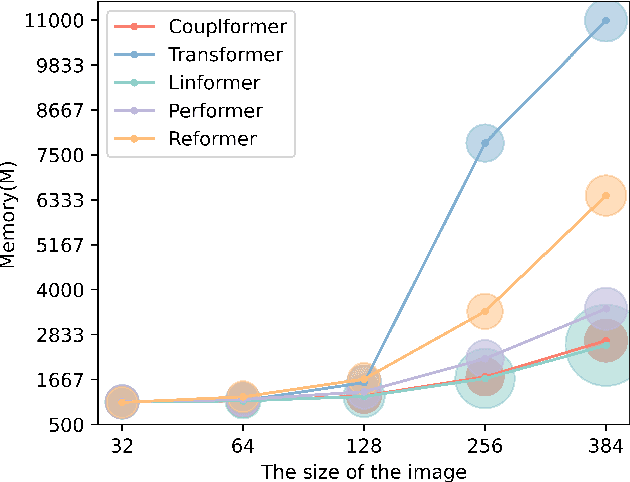

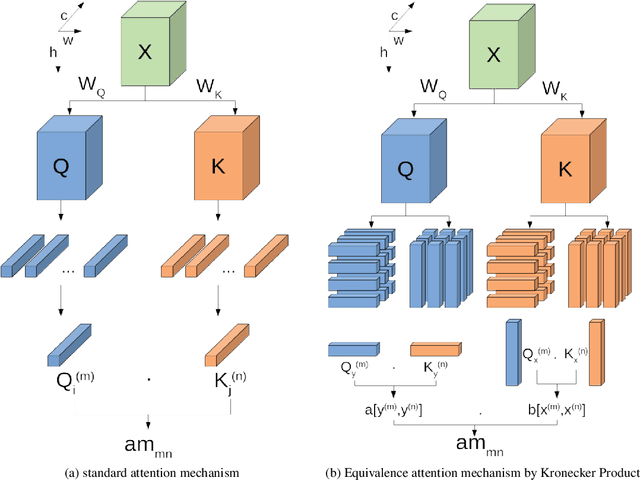
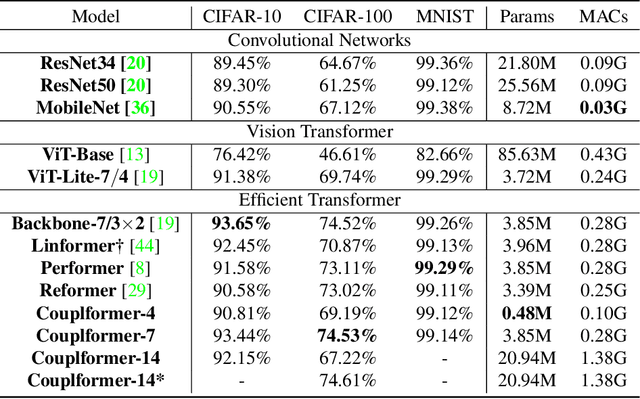
With the development of the self-attention mechanism, the Transformer model has demonstrated its outstanding performance in the computer vision domain. However, the massive computation brought from the full attention mechanism became a heavy burden for memory consumption. Sequentially, the limitation of memory reduces the possibility of improving the Transformer model. To remedy this problem, we propose a novel memory economy attention mechanism named Couplformer, which decouples the attention map into two sub-matrices and generates the alignment scores from spatial information. A series of different scale image classification tasks are applied to evaluate the effectiveness of our model. The result of experiments shows that on the ImageNet-1k classification task, the Couplformer can significantly decrease 28% memory consumption compared with regular Transformer while accessing sufficient accuracy requirements and outperforming 0.92% on Top-1 accuracy while occupying the same memory footprint. As a result, the Couplformer can serve as an efficient backbone in visual tasks, and provide a novel perspective on the attention mechanism for researchers.