 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Verification for Zero-Shot Vision
Nov 14, 2025We propose a training-free, binary verification workflow for zero-shot vision with off-the-shelf VLMs. It comprises two steps: (i) quantization, which turns the open-ended query into a multiple-choice question (MCQ) with a small, explicit list of unambiguous candidates; and (ii) binarization, which asks one True/False question per candidate and resolves deterministically: if exactly one is True, select it; otherwise, revert to an MCQ over the remaining plausible candidates. We evaluate the workflow on referring expression grounding (REC), spatial reasoning (Spatial-Map, Spatial-Grid, Spatial-Maze), and BLINK-Jigsaw. Relative to answering open-ended queries directly, quantization to MCQ yields large gains, and True/False binarization provides a consistent additional boost. Across all tasks, the same workflow produces significant improvements, indicating generality. Our theory formalizes how open-ended vision queries can be quantized to MCQs and further binarized into True/False verifications, establishing a hardness ladder. A simple analysis explains why Boolean resolution boosts accuracy. Together, these components yield a simple and unified workflow that emphasizes inference-time design over task-specific training. It offers a practical, drop-in path to stronger zero-shot vision with today's VLMs.
LADI v2: Multi-label Dataset and Classifiers for Low-Altitude Disaster Imagery
Jun 04, 2024



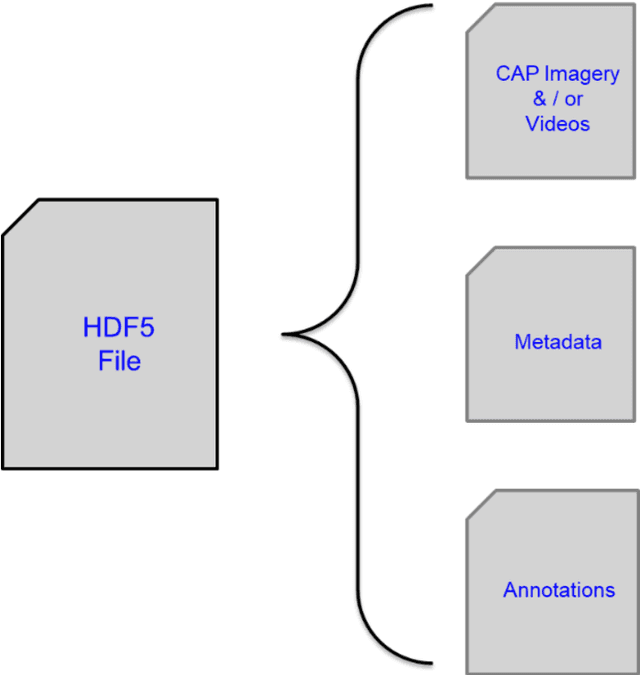
ML-based computer vision models are promising tools for supporting emergency management operations following natural disasters. Arial photographs taken from small manned and unmanned aircraft can be available soon after a disaster and provide valuable information from multiple perspectives for situational awareness and damage assessment applications. However, emergency managers often face challenges finding the most relevant photos among the tens of thousands that may be taken after an incident. While ML-based solutions could enable more effective use of aerial photographs, there is still a lack of training data for imagery of this type from multiple perspectives and for multiple hazard types. To address this, we present the LADI v2 (Low Altitude Disaster Imagery version 2) dataset, a curated set of about 10,000 disaster images captured in the United States by the Civil Air Patrol (CAP) in response to federally-declared emergencies (2015-2023) and annotated for multi-label classification by trained CAP volunteers. We also provide two pretrained baseline classifiers and compare their performance to state-of-the-art vision-language models in multi-label classification. The data and code are released publicly to support the development of computer vision models for emergency management research and applications.
An overview on the evaluated video retrieval tasks at TRECVID 2022
Jun 22, 2023



The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, tasks-based evaluation supported by metrology. Over the last twenty-one years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2022 planned for the following six tasks: Ad-hoc video search, Video to text captioning, Disaster scene description and indexing, Activity in extended videos, deep video understanding, and movie summarization. In total, 35 teams from various research organizations worldwide signed up to join the evaluation campaign this year. This paper introduces the tasks, datasets used, evaluation frameworks and metrics, as well as a high-level results overview.
Damage Estimation and Localization from Sparse Aerial Imagery
Nov 10, 2021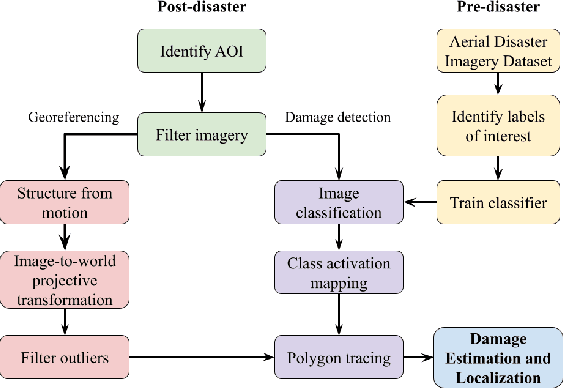

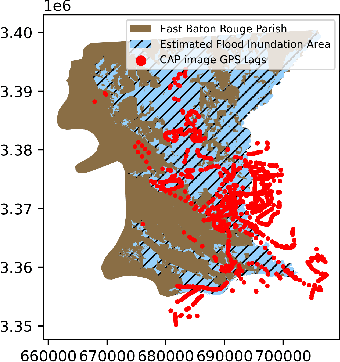
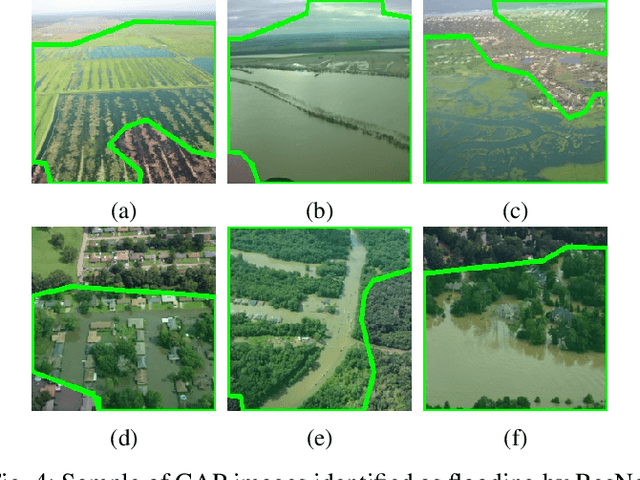
Aerial images provide important situational awareness for responding to natural disasters such as hurricanes. They are well-suited for providing information for damage estimation and localization (DEL); i.e., characterizing the type and spatial extent of damage following a disaster. Despite recent advances in sensing and unmanned aerial systems technology, much of post-disaster aerial imagery is still taken by handheld DSLR cameras from small, manned, fixed-wing aircraft. However, these handheld cameras lack IMU information, and images are taken opportunistically post-event by operators. As such, DEL from such imagery is still a highly manual and time-consuming process. We propose an approach to both detect damage in aerial images and localize it in world coordinates, with specific focus on detecting and localizing flooding. The approach is based on using structure from motion to relate image coordinates to world coordinates via a projective transformation, using class activation mapping to detect the extent of damage in an image, and applying the projective transformation to localize damage in world coordinates. We evaluate the performance of our approach on post-event data from the 2016 Louisiana floods, and find that our approach achieves a precision of 88%. Given this high precision using limited data, we argue that this approach is currently viable for fast and effective DEL from handheld aerial imagery for disaster response.
TRECVID 2020: A comprehensive campaign for evaluating video retrieval tasks across multiple application domains
Apr 27, 2021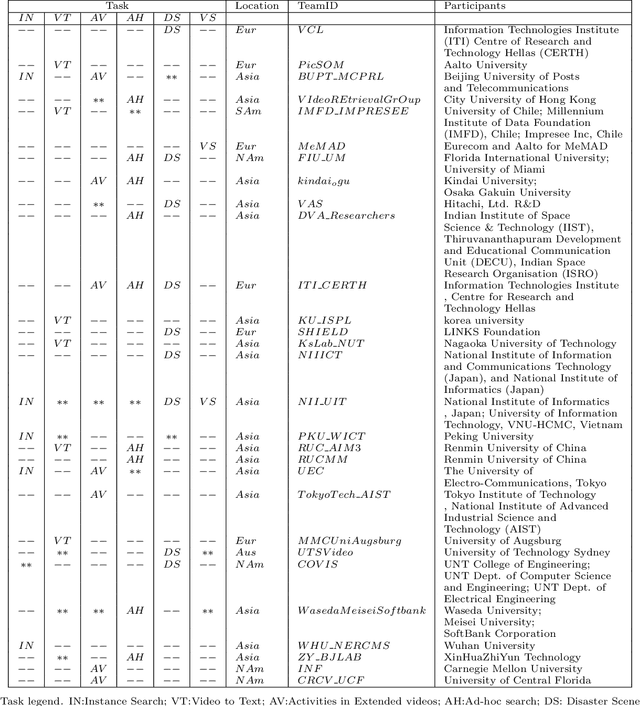

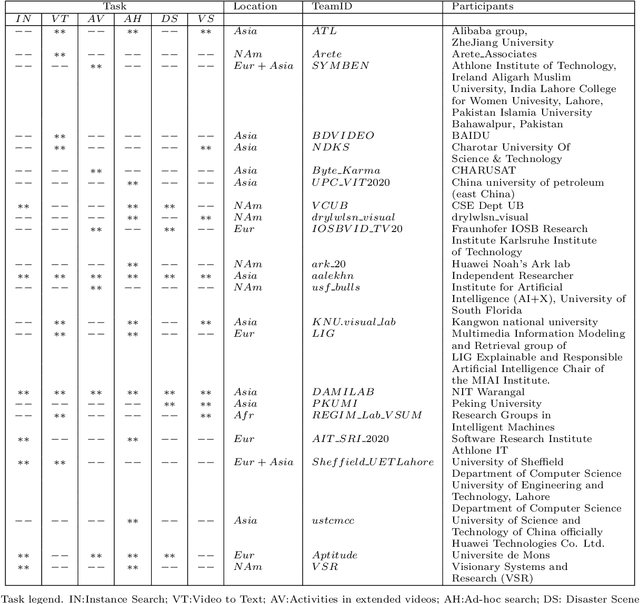
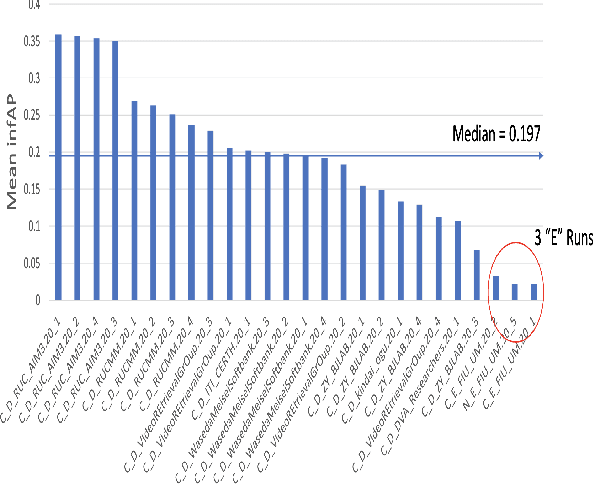
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last twenty years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2020 represented a continuation of four tasks and the addition of two new tasks. In total, 29 teams from various research organizations worldwide completed one or more of the following six tasks: 1. Ad-hoc Video Search (AVS), 2. Instance Search (INS), 3. Disaster Scene Description and Indexing (DSDI), 4. Video to Text Description (VTT), 5. Activities in Extended Video (ActEV), 6. Video Summarization (VSUM). This paper is an introduction to the evaluation framework, tasks, data, and measures used in the evaluation campaign.
Large Scale Organization and Inference of an Imagery Dataset for Public Safety
Aug 16, 2019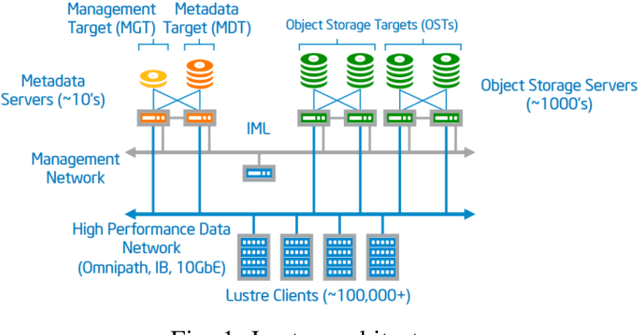

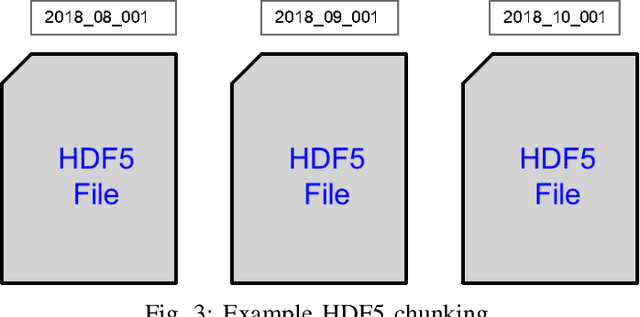
Video applications and analytics are routinely projected as a stressing and significant service of the Nationwide Public Safety Broadband Network. As part of a NIST PSCR funded effort, the New Jersey Office of Homeland Security and Preparedness and MIT Lincoln Laboratory have been developing a computer vision dataset of operational and representative public safety scenarios. The scale and scope of this dataset necessitates a hierarchical organization approach for efficient compute and storage. We overview architectural considerations using the Lincoln Laboratory Supercomputing Cluster as a test architecture. We then describe how we intelligently organized the dataset across LLSC and evaluated it with large scale imagery inference across terabytes of data.
Semantic Analysis of Traffic Camera Data: Topic Signal Extraction and Anomalous Event Detection
May 17, 2019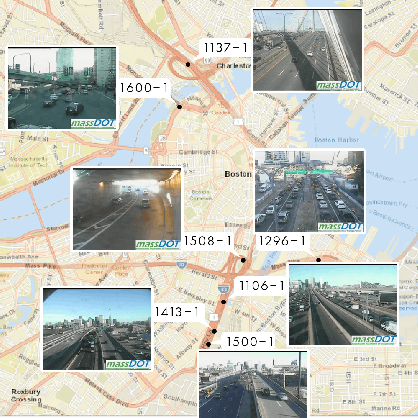
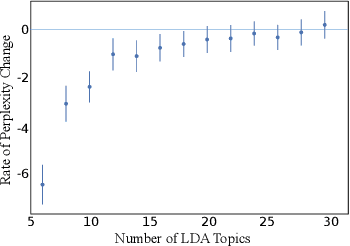

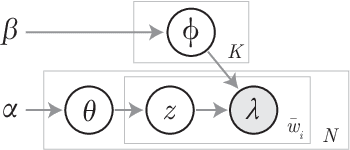
Traffic Management Centers (TMCs) routinely use traffic cameras to provide situational awareness regarding traffic, road, and weather conditions. Camera footage is quite useful for a variety of diagnostic purposes; yet, most footage is kept for only a few days, if at all. This is largely due to the fact that currently, identification of notable footage is done via manual review by human operators---a laborious and inefficient process. In this article, we propose a semantics-oriented approach to analyzing sequential image data, and demonstrate its application for automatic detection of real-world, anomalous events in weather and traffic conditions. Our approach constructs semantic vector representations of image contents from textual labels which can be easily obtained from off-the-shelf, pretrained image labeling software. These semantic label vectors are used to construct semantic topic signals---time series representations of physical processes---using the Latent Dirichlet Allocation (LDA) topic model. By detecting anomalies in the topic signals, we identify notable footage corresponding to winter storms and anomalous traffic congestion. In validation against real-world events, anomaly detection using semantic topic signals significantly outperforms detection using any individual label signal.
Semantic Topic Analysis of Traffic Camera Images
Sep 27, 2018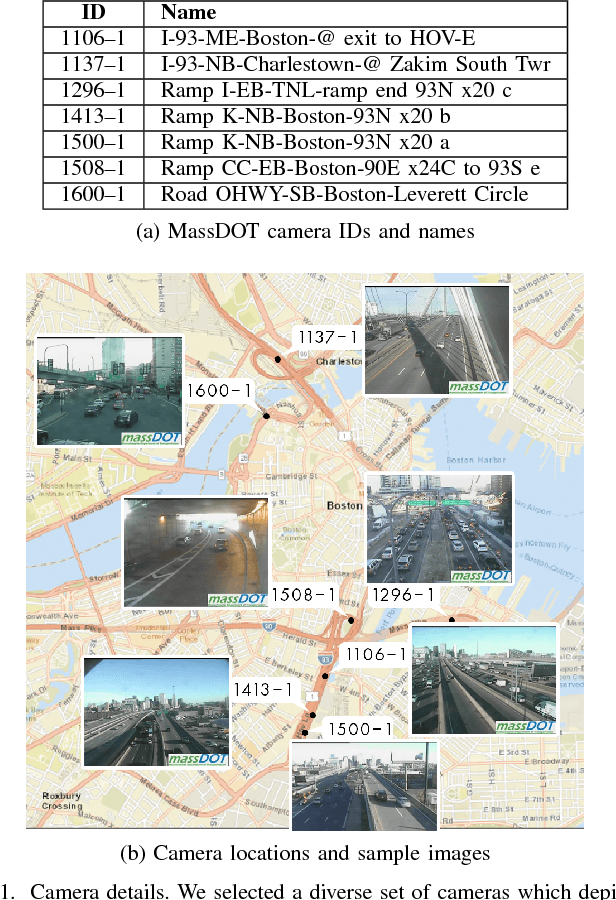
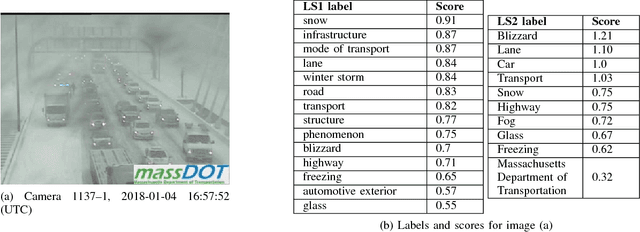
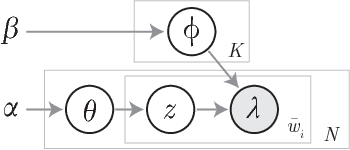
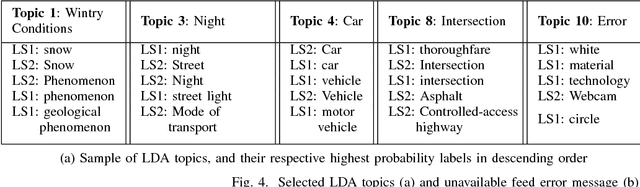
Traffic cameras are commonly deployed monitoring components in road infrastructure networks, providing operators visual information about conditions at critical points in the network. However, human observers are often limited in their ability to process simultaneous information sources. Recent advancements in computer vision, driven by deep learning methods, have enabled general object recognition, unlocking opportunities for camera-based sensing beyond the existing human observer paradigm. In this paper, we present a Natural Language Processing (NLP)-inspired approach, entitled Bag-of-Label-Words (BoLW), for analyzing image data sets using exclusively textual labels. The BoLW model represents the data in a conventional matrix form, enabling data compression and decomposition techniques, while preserving semantic interpretability. We apply the Latent Dirichlet Allocation (LDA) topic model to decompose the label data into a small number of semantic topics. To illustrate our approach, we use freeway camera images collected from the Boston area between December 2017-January 2018. We analyze the cameras' sensitivity to weather events; identify temporal traffic patterns; and analyze the impact of infrequent events, such as the winter holidays and the "bomb cyclone" winter storm. This study demonstrates the flexibility of our approach, which allows us to analyze weather events and freeway traffic using only traffic camera image labels.