 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Adversarial Distillation for Graph Neural Networks
Dec 28, 2021
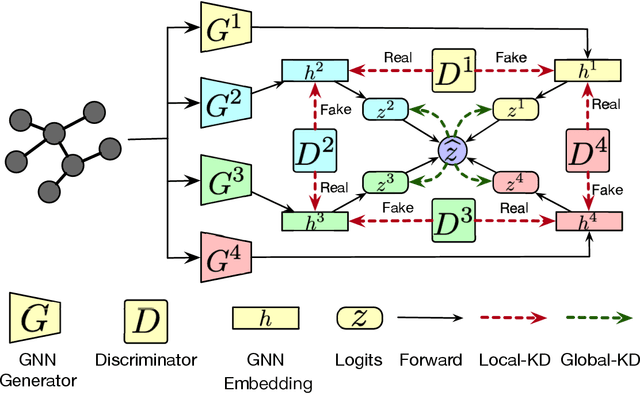
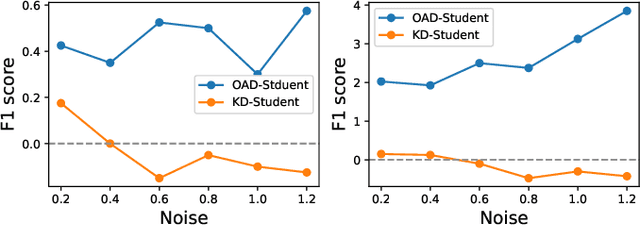
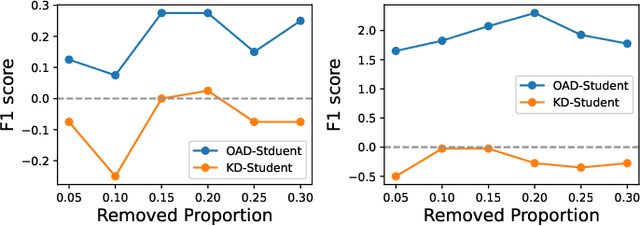

Knowledge distillation has recently become a popular technique to improve the model generalization ability on convolutional neural networks. However, its effect on graph neural networks is less than satisfactory since the graph topology and node attributes are likely to change in a dynamic way and in this case a static teacher model is insufficient in guiding student training. In this paper, we tackle this challenge by simultaneously training a group of graph neural networks in an online distillation fashion, where the group knowledge plays a role as a dynamic virtual teacher and the structure changes in graph neural networks are effectively captured. To improve the distillation performance, two types of knowledge are transferred among the students to enhance each other: local knowledge reflecting information in the graph topology and node attributes, and global knowledge reflecting the prediction over classes. We transfer the global knowledge with KL-divergence as the vanilla knowledge distillation does, while exploiting the complicated structure of the local knowledge with an efficient adversarial cyclic learning framework. Extensive experiments verified the effectiveness of our proposed online adversarial distillation approach.
A Modular Framework for Centrality and Clustering in Complex Networks
Nov 23, 2021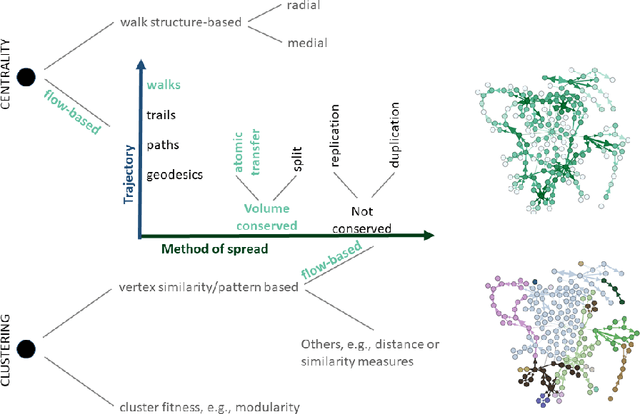

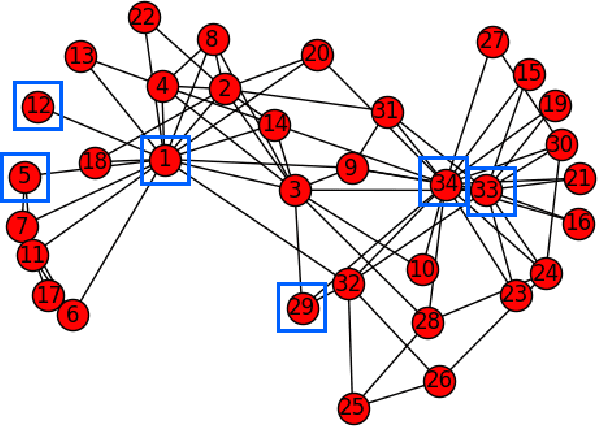
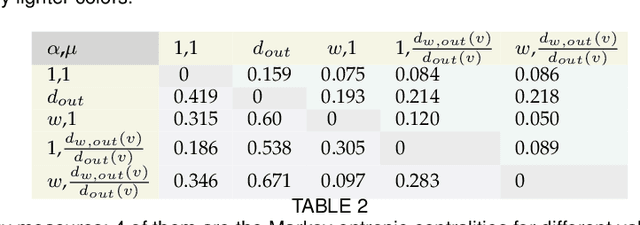
The structure of many complex networks includes edge directionality and weights on top of their topology. Network analysis that can seamlessly consider combination of these properties are desirable. In this paper, we study two important such network analysis techniques, namely, centrality and clustering. An information-flow based model is adopted for clustering, which itself builds upon an information theoretic measure for computing centrality. Our principal contributions include a generalized model of Markov entropic centrality with the flexibility to tune the importance of node degrees, edge weights and directions, with a closed-form asymptotic analysis. It leads to a novel two-stage graph clustering algorithm. The centrality analysis helps reason about the suitability of our approach to cluster a given graph, and determine `query' nodes, around which to explore local community structures, leading to an agglomerative clustering mechanism. The entropic centrality computations are amortized by our clustering algorithm, making it computationally efficient: compared to prior approaches using Markov entropic centrality for clustering, our experiments demonstrate multiple orders of magnitude of speed-up. Our clustering algorithm naturally inherits the flexibility to accommodate edge directionality, as well as different interpretations and interplay between edge weights and node degrees. Overall, this paper thus not only makes significant theoretical and conceptual contributions, but also translates the findings into artifacts of practical relevance, yielding new, effective and scalable centrality computations and graph clustering algorithms, whose efficacy has been validated through extensive benchmarking experiments.
Video Reconstruction from a Single Motion Blurred Image using Learned Dynamic Phase Coding
Dec 28, 2021

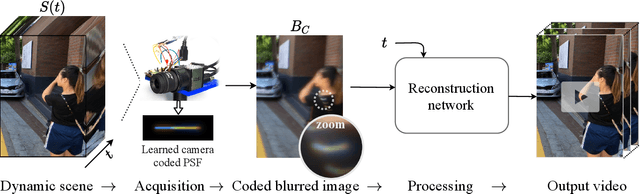
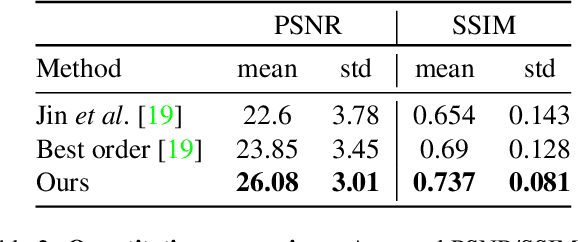
Video reconstruction from a single motion-blurred image is a challenging problem, which can enhance existing cameras' capabilities. Recently, several works addressed this task using conventional imaging and deep learning. Yet, such purely-digital methods are inherently limited, due to direction ambiguity and noise sensitivity. Some works proposed to address these limitations using non-conventional image sensors, however, such sensors are extremely rare and expensive. To circumvent these limitations with simpler means, we propose a hybrid optical-digital method for video reconstruction that requires only simple modifications to existing optical systems. We use a learned dynamic phase-coding in the lens aperture during the image acquisition to encode the motion trajectories, which serve as prior information for the video reconstruction process. The proposed computational camera generates a sharp frame burst of the scene at various frame rates from a single coded motion-blurred image, using an image-to-video convolutional neural network. We present advantages and improved performance compared to existing methods, using both simulations and a real-world camera prototype.
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
Dec 16, 2021
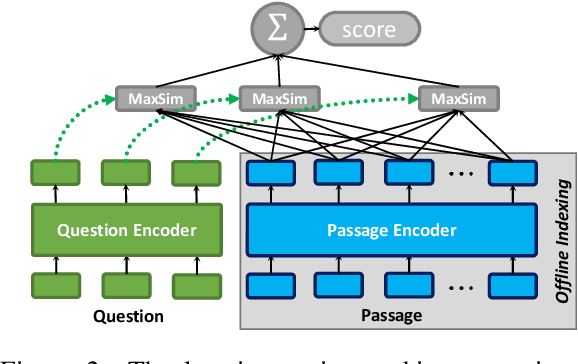
Neural information retrieval (IR) has greatly advanced search and other knowledge-intensive language tasks. While many neural IR methods encode queries and documents into single-vector representations, late interaction models produce multi-vector representations at the granularity of each token and decompose relevance modeling into scalable token-level computations. This decomposition has been shown to make late interaction more effective, but it inflates the space footprint of these models by an order of magnitude. In this work, we introduce ColBERTv2, a retriever that couples an aggressive residual compression mechanism with a denoised supervision strategy to simultaneously improve the quality and space footprint of late interaction. We evaluate ColBERTv2 across a wide range of benchmarks, establishing state-of-the-art quality within and outside the training domain while reducing the space footprint of late interaction models by 5--8$\times$.
SymbioLCD: Ensemble-Based Loop Closure Detection using CNN-Extracted Objects and Visual Bag-of-Words
Oct 21, 2021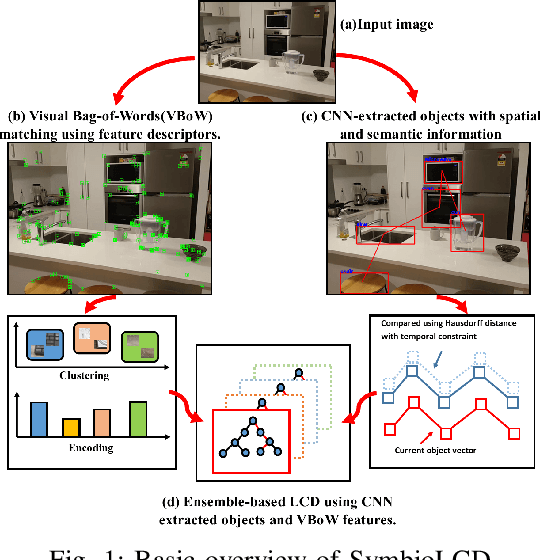
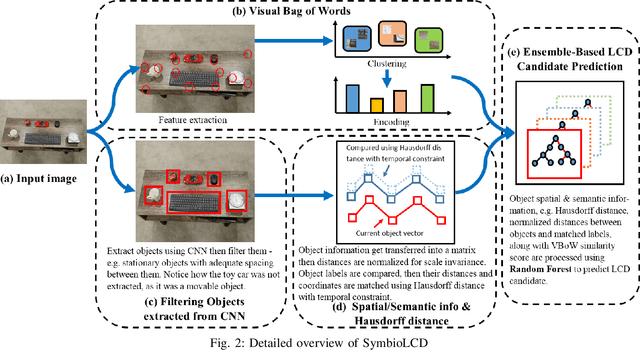

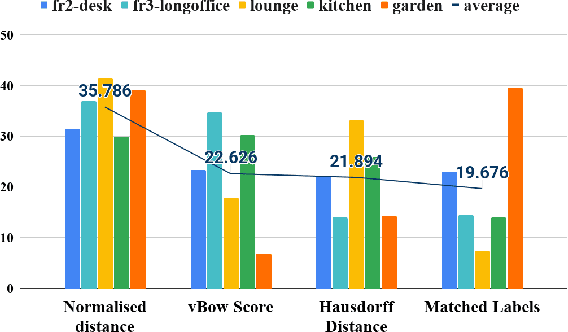
Loop closure detection is an essential tool of Simultaneous Localization and Mapping (SLAM) to minimize drift in its localization. Many state-of-the-art loop closure detection (LCD) algorithms use visual Bag-of-Words (vBoW), which is robust against partial occlusions in a scene but cannot perceive the semantics or spatial relationships between feature points. CNN object extraction can address those issues, by providing semantic labels and spatial relationships between objects in a scene. Previous work has mainly focused on replacing vBoW with CNN-derived features. In this paper, we propose SymbioLCD, a novel ensemble-based LCD that utilizes both CNN-extracted objects and vBoW features for LCD candidate prediction. When used in tandem, the added elements of object semantics and spatial-awareness create a more robust and symbiotic loop closure detection system. The proposed SymbioLCD uses scale-invariant spatial and semantic matching, Hausdorff distance with temporal constraints, and a Random Forest that utilizes combined information from both CNN-extracted objects and vBoW features for predicting accurate loop closure candidates. Evaluation of the proposed method shows it outperforms other Machine Learning (ML) algorithms - such as SVM, Decision Tree and Neural Network, and demonstrates that there is a strong symbiosis between CNN-extracted object information and vBoW features which assists accurate LCD candidate prediction. Furthermore, it is able to perceive loop closure candidates earlier than state-of-the-art SLAM algorithms, utilizing added spatial and semantic information from CNN-extracted objects.
Forgetting Outside the Box: Scrubbing Deep Networks of Information Accessible from Input-Output Observations
Mar 05, 2020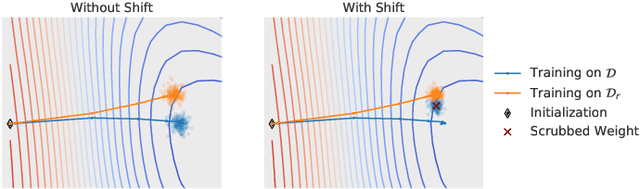
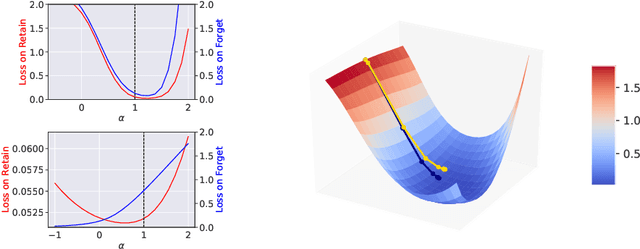
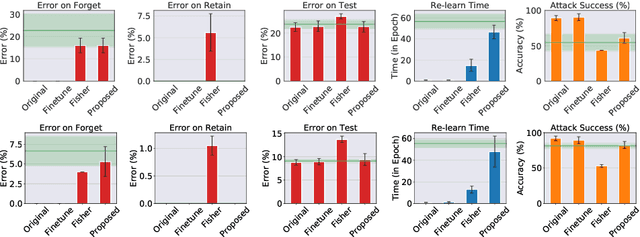
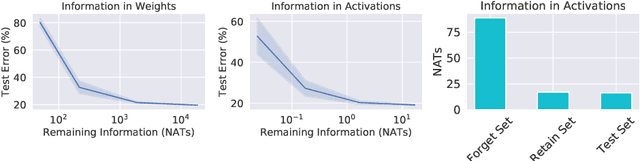
We describe a procedure for removing dependency on a cohort of training data from a trained deep network that improves upon and generalizes previous methods to different readout functions and can be extended to ensure forgetting in the activations of the network. We introduce a new bound on how much information can be extracted per query about the forgotten cohort from a black-box network for which only the input-output behavior is observed. The proposed forgetting procedure has a deterministic part derived from the differential equations of a linearized version of the model, and a stochastic part that ensures information destruction by adding noise tailored to the geometry of the loss landscape. We exploit the connections between the activation and weight dynamics of a DNN inspired by Neural Tangent Kernels to compute the information in the activations.
Value Function Factorisation with Hypergraph Convolution for Cooperative Multi-agent Reinforcement Learning
Dec 09, 2021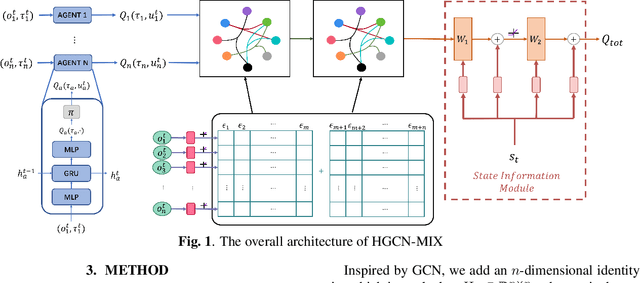
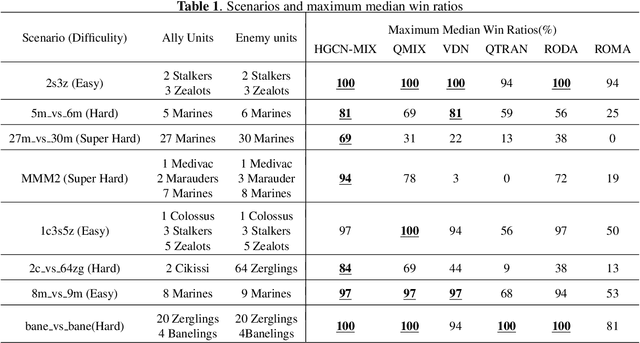
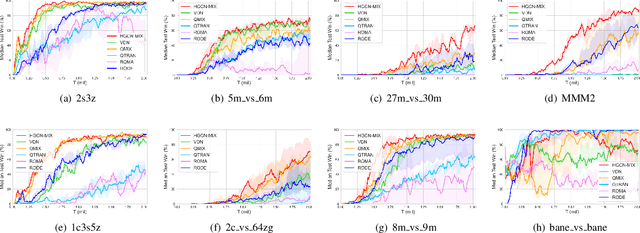
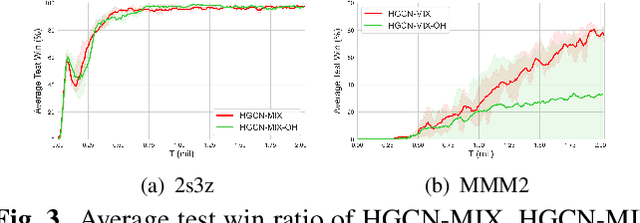
Cooperation between agents in a multi-agent system (MAS) has become a hot topic in recent years, and many algorithms based on centralized training with decentralized execution (CTDE), such as VDN and QMIX, have been proposed. However, these methods disregard the information hidden in the individual action values. In this paper, we propose HyperGraph CoNvolution MIX (HGCN-MIX), a method that combines hypergraph convolution with value decomposition. By treating action values as signals, HGCN-MIX aims to explore the relationship between these signals via a self-learning hypergraph. Experimental results present that HGCN-MIX matches or surpasses state-of-the-art techniques in the StarCraft II multi-agent challenge (SMAC) benchmark on various situations, notably those with a number of agents.
Learning Object-Centric Representations of Multi-Object Scenes from Multiple Views
Nov 13, 2021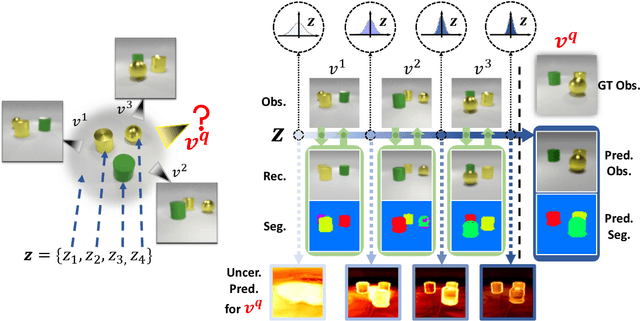
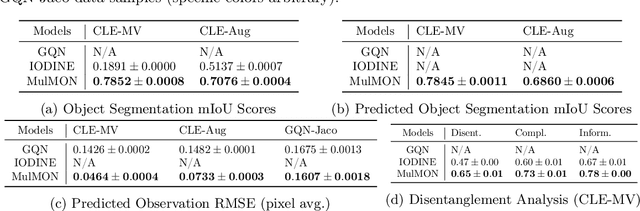
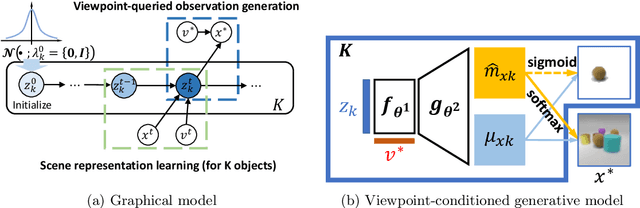

Learning object-centric representations of multi-object scenes is a promising approach towards machine intelligence, facilitating high-level reasoning and control from visual sensory data. However, current approaches for unsupervised object-centric scene representation are incapable of aggregating information from multiple observations of a scene. As a result, these "single-view" methods form their representations of a 3D scene based only on a single 2D observation (view). Naturally, this leads to several inaccuracies, with these methods falling victim to single-view spatial ambiguities. To address this, we propose The Multi-View and Multi-Object Network (MulMON) -- a method for learning accurate, object-centric representations of multi-object scenes by leveraging multiple views. In order to sidestep the main technical difficulty of the multi-object-multi-view scenario -- maintaining object correspondences across views -- MulMON iteratively updates the latent object representations for a scene over multiple views. To ensure that these iterative updates do indeed aggregate spatial information to form a complete 3D scene understanding, MulMON is asked to predict the appearance of the scene from novel viewpoints during training. Through experiments, we show that MulMON better-resolves spatial ambiguities than single-view methods -- learning more accurate and disentangled object representations -- and also achieves new functionality in predicting object segmentations for novel viewpoints.
Improving Supervised Phase Identification Through the Theory of Information Losses
Nov 04, 2019
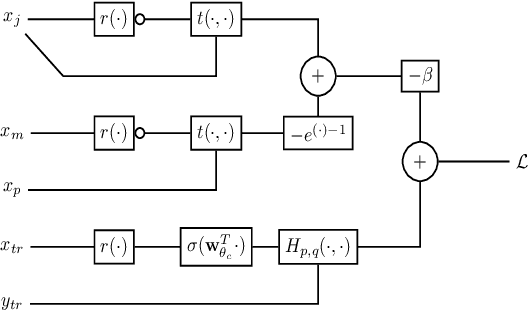
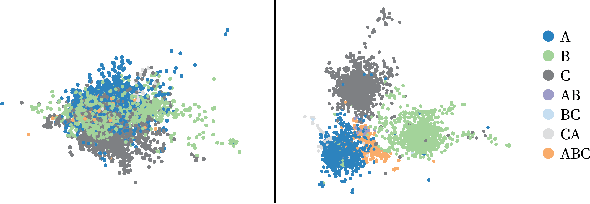
This paper considers the problem of Phase Identification in power distribution systems. In particular, it focuses on improving supervised learning accuracies by focusing on exploiting some of the problem's information theoretic properties. This focus, along with recent advances in Information Theoretic Machine Learning (ITML), helps us to create two new techniques. The first transforms a bound on information losses into a data selection technique. This is important because phase identification data labels are difficult to obtain in practice. The second interprets the properties of distribution systems in the terms of ITML. This allows us to obtain an improvement in the representation learned by any classifier applied to the problem. We tested these two techniques experimentally on real datasets and have found that they yield phenomenal performance in every case. In the most extreme case, they improve phase identification accuracy from $51.7\%$ to $97.3\%$. Furthermore, since many problems share the physical properties of phase identification exploited in this paper, the techniques can be applied to a wide range of similar problems.
Action-Centered Information Retrieval
Mar 23, 2019
Information Retrieval (IR) aims at retrieving documents that are most relevant to a query provided by a user. Traditional techniques rely mostly on syntactic methods. In some cases, however, links at a deeper semantic level must be considered. In this paper, we explore a type of IR task in which documents describe sequences of events, and queries are about the state of the world after such events. In this context, successfully matching documents and query requires considering the events' possibly implicit, uncertain effects and side-effects. We begin by analyzing the problem, then propose an action language based formalization, and finally automate the corresponding IR task using Answer Set Programming.