 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 30, 2021
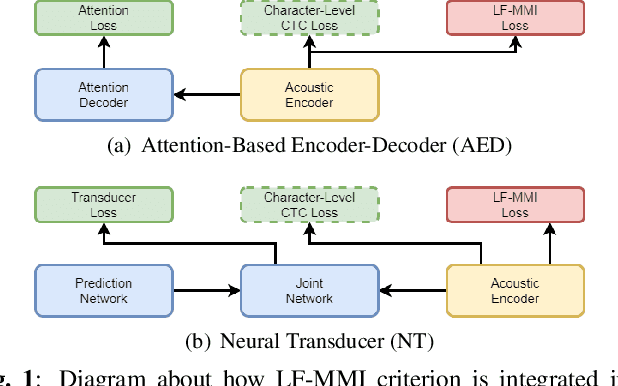
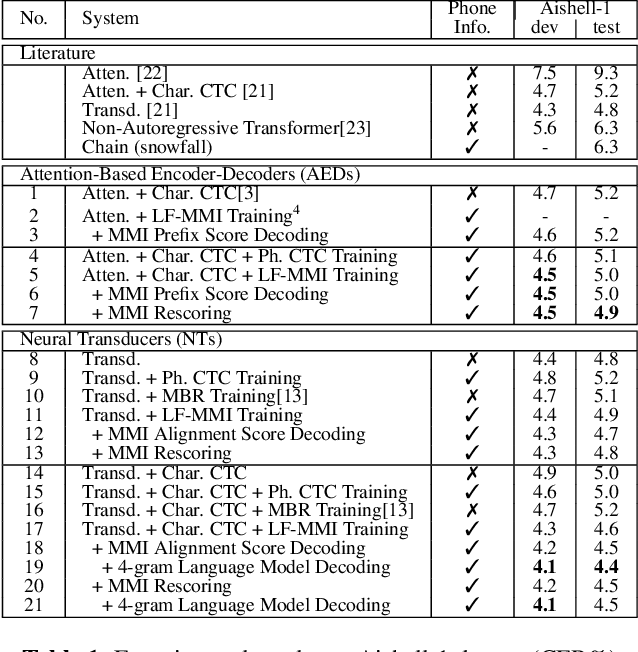
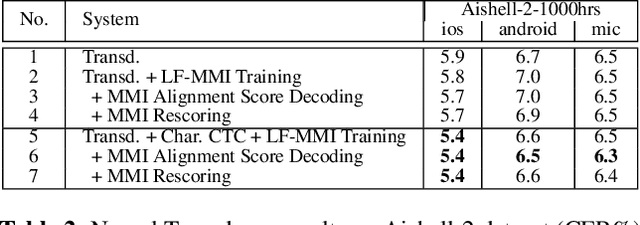
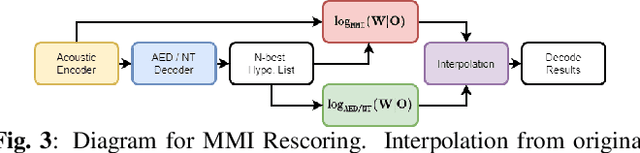
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Homoscatter: Towards efficient connectivity for ZigBee backscatter system
Nov 20, 2021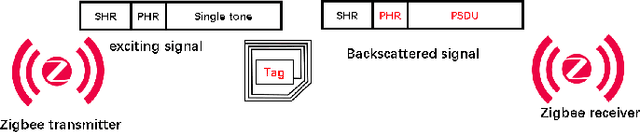
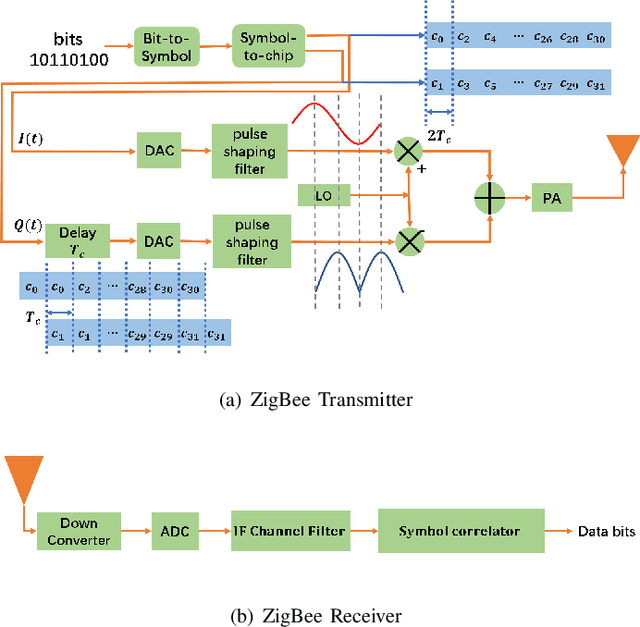
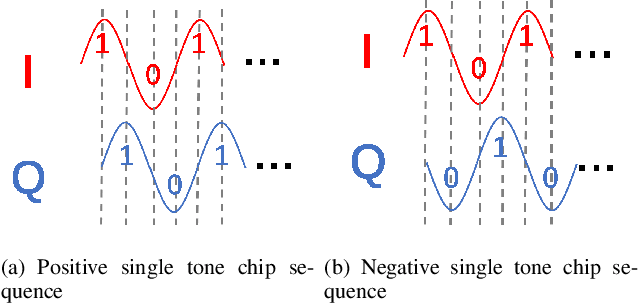
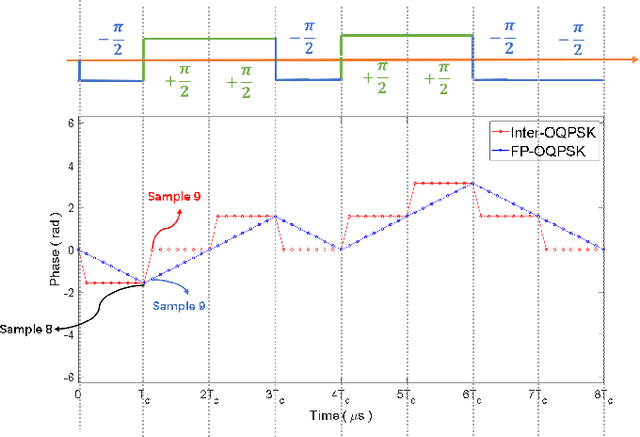
Recent advances in backscatter open a promising direction for ultra-low power communication. However, the state-of-art ZigBee backscatter system, Interscatter, has several drawbacks to deploy. Its backscatter tag and exciting source, Bluetooth, can hardly decode packets from other ZigBee nodes, which left Interscatter one-way communication. Besides, it adopts instantaneous phase change to modulate information, producing obvious sidelobes and interfering devices working on neighboring channels severely. To address the problems mentioned above, we introduce Homoscatter, a novel ZigBee backscatter system that adopts specific ZigBee devices to generate a single tone and leverages continuous phase change to modulate information, which eliminates spectral leakage. It also does codeword translation on the packet header of exciting packets, improving the utilization of ambient signal. The prototype of Homoscatter consists of a microchip radio, a backscatter tag, and a commodity receiver. The evaluations show that the occupied bandwidth of Homoscatter achieves 3x smaller than Interscatter. When the channel capacity is 17.5 kbps, the continuous phase change modulation achieves 13 kbps with the codeword translation on the excitation header. Based on the widely spread IoT devices, Homoscatter is a practical way to build an efficient connection between IoT devices.
Less is Less: When Are Snippets Insufficient for Human vs Machine Relevance Estimation?
Jan 21, 2022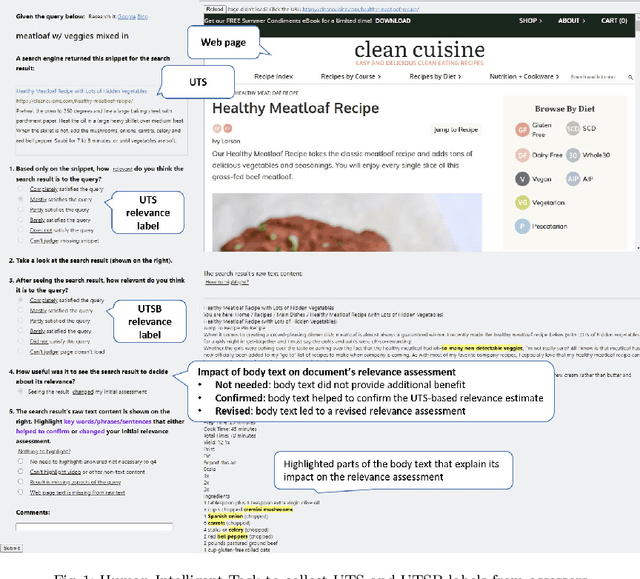

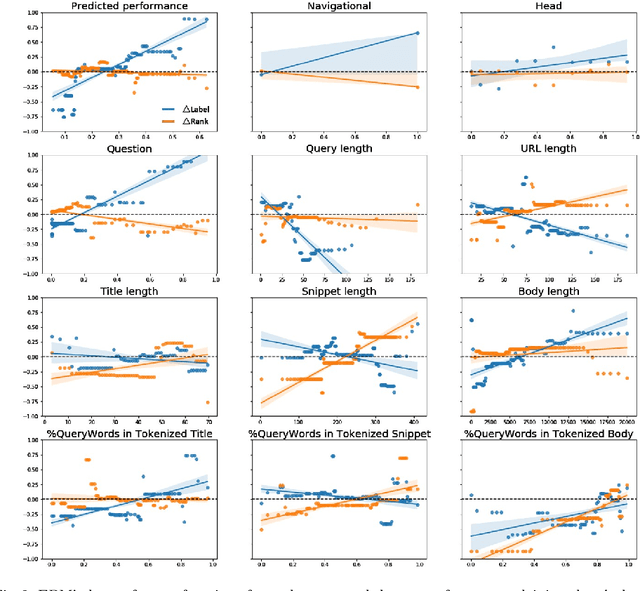

Traditional information retrieval (IR) ranking models process the full text of documents. Newer models based on Transformers, however, would incur a high computational cost when processing long texts, so typically use only snippets from the document instead. The model's input based on a document's URL, title, and snippet (UTS) is akin to the summaries that appear on a search engine results page (SERP) to help searchers decide which result to click. This raises questions about when such summaries are sufficient for relevance estimation by the ranking model or the human assessor, and whether humans and machines benefit from the document's full text in similar ways. To answer these questions, we study human and neural model based relevance assessments on 12k query-documents sampled from Bing's search logs. We compare changes in the relevance assessments when only the document summaries and when the full text is also exposed to assessors, studying a range of query and document properties, e.g., query type, snippet length. Our findings show that the full text is beneficial for humans and a BERT model for similar query and document types, e.g., tail, long queries. A closer look, however, reveals that humans and machines respond to the additional input in very different ways. Adding the full text can also hurt the ranker's performance, e.g., for navigational queries.
PreDisM: Pre-Disaster Modelling With CNN Ensembles for At-Risk Communities
Dec 26, 2021



The machine learning community has recently had increased interest in the climate and disaster damage domain due to a marked increased occurrences of natural hazards (e.g., hurricanes, forest fires, floods, earthquakes). However, not enough attention has been devoted to mitigating probable destruction from impending natural hazards. We explore this crucial space by predicting building-level damages on a before-the-fact basis that would allow state actors and non-governmental organizations to be best equipped with resource distribution to minimize or preempt losses. We introduce PreDisM that employs an ensemble of ResNets and fully connected layers over decision trees to capture image-level and meta-level information to accurately estimate weakness of man-made structures to disaster-occurrences. Our model performs well and is responsive to tuning across types of disasters and highlights the space of preemptive hazard damage modelling.
STJLA: A Multi-Context Aware Spatio-Temporal Joint Linear Attention Network for Traffic Forecasting
Dec 04, 2021
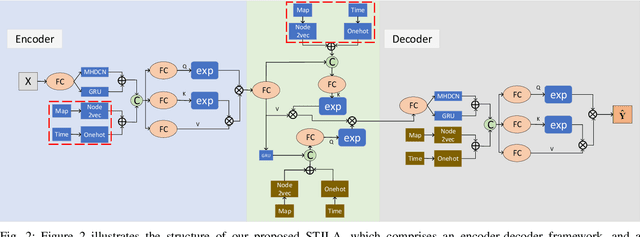
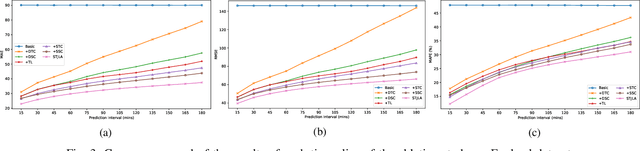
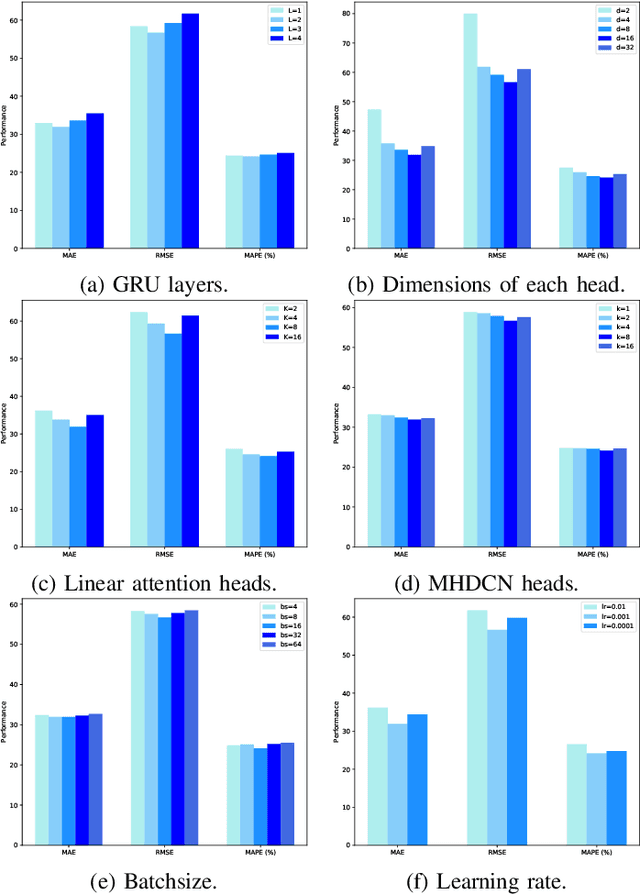
Traffic prediction has gradually attracted the attention of researchers because of the increase in traffic big data. Therefore, how to mine the complex spatio-temporal correlations in traffic data to predict traffic conditions more accurately become a difficult problem. Previous works combined graph convolution networks (GCNs) and self-attention mechanism with deep time series models (e.g. recurrent neural networks) to capture the spatio-temporal correlations separately, ignoring the relationships across time and space. Besides, GCNs are limited by over-smoothing issue and self-attention is limited by quadratic problem, result in GCNs lack global representation capabilities, and self-attention inefficiently capture the global spatial dependence. In this paper, we propose a novel deep learning model for traffic forecasting, named Multi-Context Aware Spatio-Temporal Joint Linear Attention (STJLA), which applies linear attention to the spatio-temporal joint graph to capture global dependence between all spatio-temporal nodes efficiently. More specifically, STJLA utilizes static structural context and dynamic semantic context to improve model performance. The static structure context based on node2vec and one-hot encoding enriches the spatio-temporal position information. Furthermore, the multi-head diffusion convolution network based dynamic spatial context enhances the local spatial perception ability, and the GRU based dynamic temporal context stabilizes sequence position information of the linear attention, respectively. Experiments on two real-world traffic datasets, England and PEMSD7, demonstrate that our STJLA can achieve up to 9.83% and 3.08% accuracy improvement in MAE measure over state-of-the-art baselines.
Constrained Wrapped Least Squares: A Tool for High Accuracy GNSS Attitude Determination
Dec 29, 2021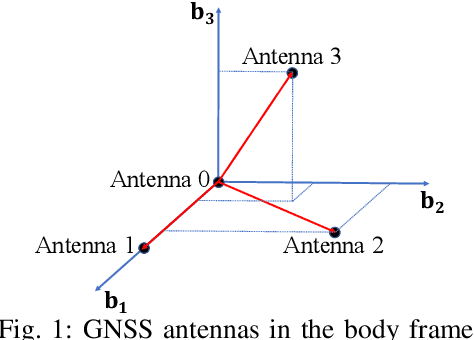
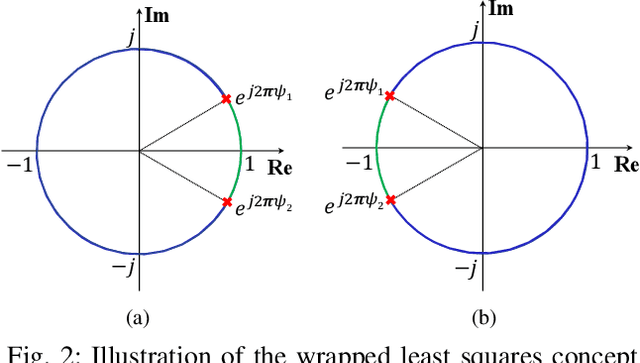
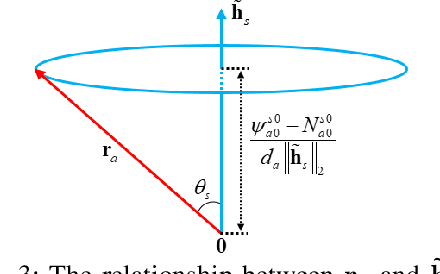
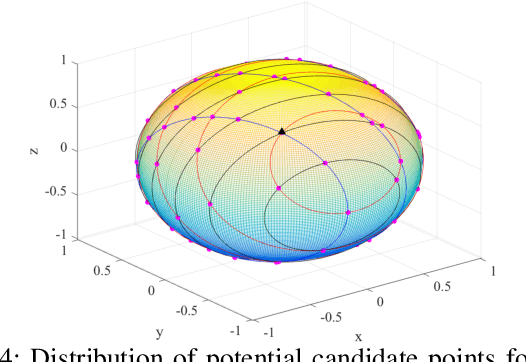
Attitude determination is a popular application of Global Navigation Satellite Systems (GNSS). Many methods have been developed to solve the attitude determination problem with different performance offerings. We develop a constrained wrapped least-squares (C-WLS) method for high-accuracy attitude determination. This approach is built on an optimization model that leverages prior information related to the antenna array and the integer nature of the carrier-phase ambiguities in an innovative way. The proposed approach adopts an efficient search strategy to estimate the vehicle's attitude parameters using ambiguous carrier-phase observations directly, without requiring prior carrier-phase ambiguity fixing. The performance of the proposed method is evaluated via simulations and experimentally utilizing data collected using multiple GNSS receivers. The simulation and experimental results demonstrate excellent performance, with the proposed method outperforming the ambiguity function method, the constrained LAMBDA and multivariate constrained LAMBDA methods, three prominent attitude determination algorithms.
Sparse Spatial Transformers for Few-Shot Learning
Sep 27, 2021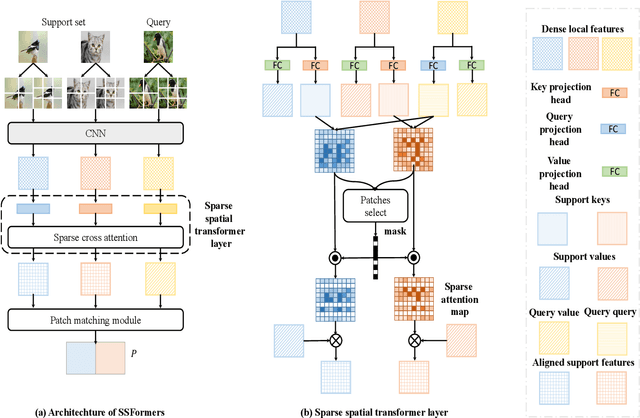
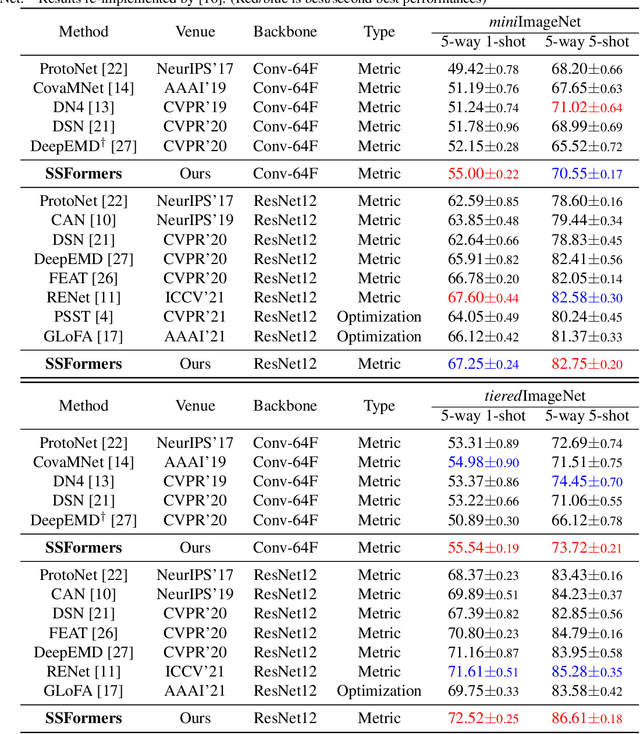


Learning from limited data is a challenging task since the scarcity of data leads to a poor generalization of the trained model. The classical global pooled representation is likely to lose useful local information. Recently, many few shot learning methods address this challenge by using deep descriptors and learning a pixel-level metric. However, using deep descriptors as feature representations may lose the contextual information of the image. And most of these methods deal with each class in the support set independently, which cannot sufficiently utilize discriminative information and task-specific embeddings. In this paper, we propose a novel Transformer based neural network architecture called Sparse Spatial Transformers (SSFormers), which can find task-relevant features and suppress task-irrelevant features. Specifically, we first divide each input image into several image patches of different sizes to obtain dense local features. These features retain contextual information while expressing local information. Then, a sparse spatial transformer layer is proposed to find spatial correspondence between the query image and the entire support set to select task-relevant image patches and suppress task-irrelevant image patches. Finally, we propose an image patch matching module to calculate the distance between dense local representations to determine which category the query image belongs to in the support set. Extensive experiments on popular few-shot learning benchmarks show that our method achieves the state-of-the-art performance. Our code is available at \url{https://github.com/chenhaoxing/SSFormers}.
Directional Message Passing on Molecular Graphs via Synthetic Coordinates
Nov 08, 2021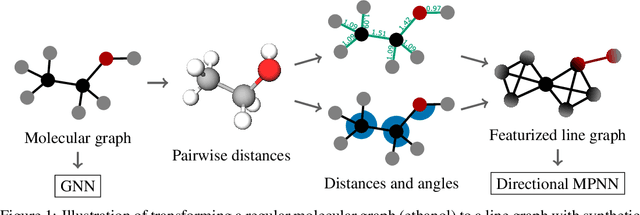


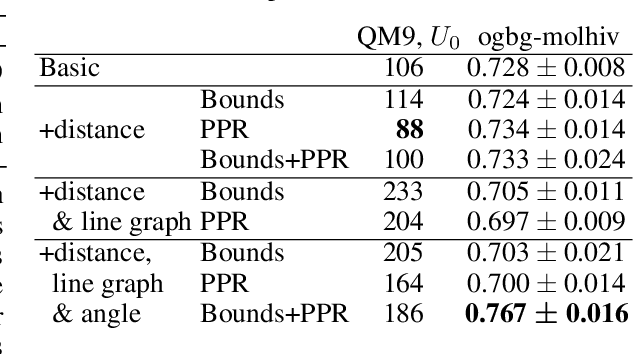
Graph neural networks that leverage coordinates via directional message passing have recently set the state of the art on multiple molecular property prediction tasks. However, they rely on atom position information that is often unavailable, and obtaining it is usually prohibitively expensive or even impossible. In this paper we propose synthetic coordinates that enable the use of advanced GNNs without requiring the true molecular configuration. We propose two distances as synthetic coordinates: Distance bounds that specify the rough range of molecular configurations, and graph-based distances using a symmetric variant of personalized PageRank. To leverage both distance and angular information we propose a method of transforming normal graph neural networks into directional MPNNs. We show that with this transformation we can reduce the error of a normal graph neural network by 55% on the ZINC benchmark. We furthermore set the state of the art on ZINC and coordinate-free QM9 by incorporating synthetic coordinates in the SMP and DimeNet++ models. Our implementation is available online.
AlphaFold Accelerates Artificial Intelligence Powered Drug Discovery: Efficient Discovery of a Novel Cyclin-dependent Kinase 20 (CDK20) Small Molecule Inhibitor
Jan 21, 2022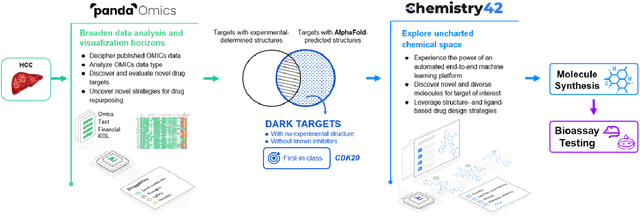

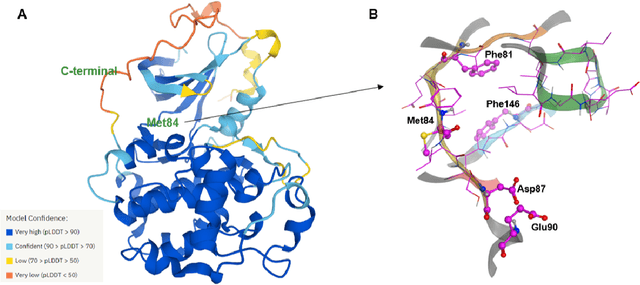
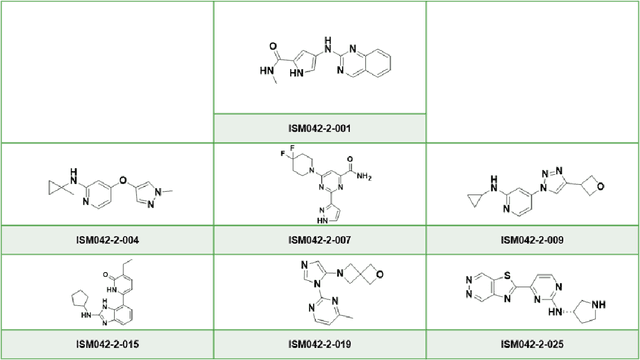
The AlphaFold computer program predicted protein structures for the whole human genome, which has been considered as a remarkable breakthrough both in artificial intelligence (AI) application and structural biology. Despite the varying confidence level, these predicted structures still could significantly contribute to the structure-based drug design of novel targets, especially the ones with no or limited structural information. In this work, we successfully applied AlphaFold in our end-to-end AI-powered drug discovery engines constituted of a biocomputational platform PandaOmics and a generative chemistry platform Chemistry42, to identify a first-in-class hit molecule of a novel target without an experimental structure starting from target selection towards hit identification in a cost- and time-efficient manner. PandaOmics provided the targets of interest and Chemistry42 generated the molecules based on the AlphaFold predicted structure, and the selected molecules were synthesized and tested in biological assays. Through this approach, we identified a small molecule hit compound for CDK20 with a Kd value of 8.9 +/- 1.6 uM (n = 4) within 30 days from target selection and after only synthesizing 7 compounds. To the best of our knowledge, this is the first reported small molecule targeting CDK20 and more importantly, this work is the first demonstration of AlphaFold application in the hit identification process in early drug discovery.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022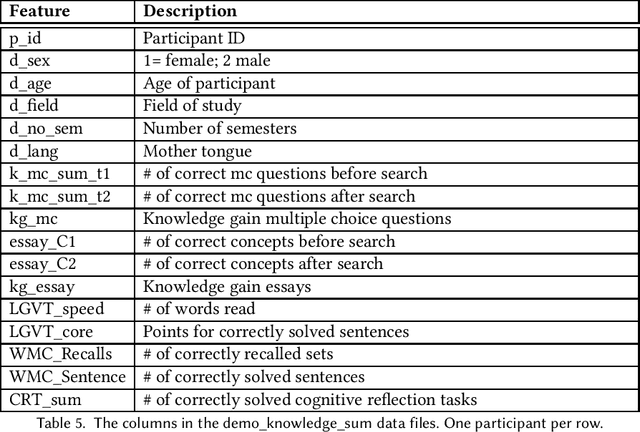
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.