 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Performance of Semantic Segmentation CycleGANs by Noise Injection into the Latent Segmentation Space
Jan 17, 2022
In recent years, semantic segmentation has taken benefit from various works in computer vision. Inspired by the very versatile CycleGAN architecture, we combine semantic segmentation with the concept of cycle consistency to enable a multitask training protocol. However, learning is largely prevented by the so-called steganography effect, which expresses itself as watermarks in the latent segmentation domain, making image reconstruction a too easy task. To combat this, we propose a noise injection, based either on quantization noise or on Gaussian noise addition to avoid this disadvantageous information flow in the cycle architecture. We find that noise injection significantly reduces the generation of watermarks and thus allows the recognition of highly relevant classes such as "traffic signs", which are hardly detected by the ERFNet baseline. We report mIoU and PSNR results on the Cityscapes dataset for semantic segmentation and image reconstruction, respectively. The proposed methodology allows to achieve an mIoU improvement on the Cityscapes validation set of 5.7% absolute over the same CycleGAN without noise injection, and still an absolute 4.9% over the ERFNet non-cyclic baseline.
TFW2V: An Enhanced Document Similarity Method for the Morphologically Rich Finnish Language
Dec 23, 2021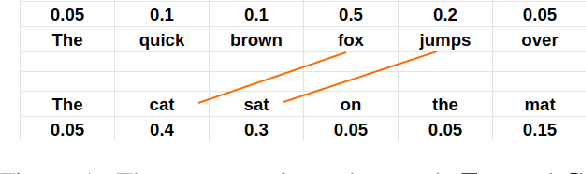
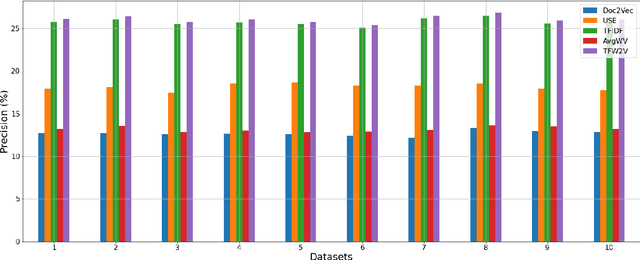
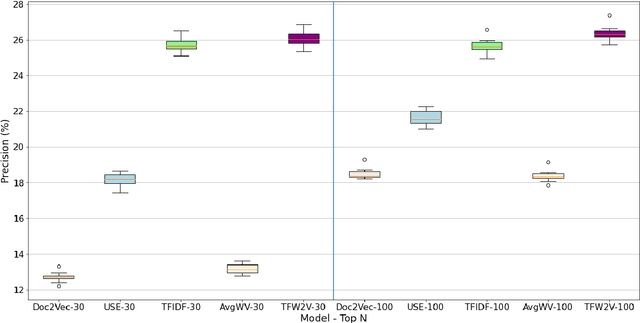
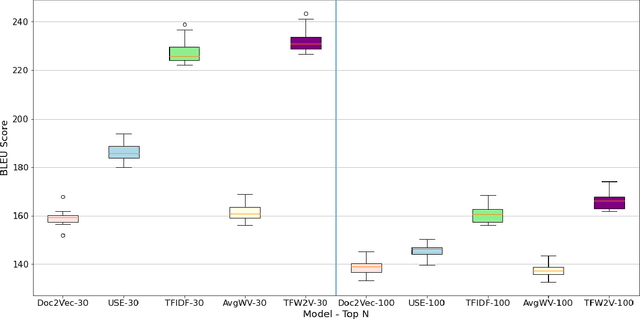
Measuring the semantic similarity of different texts has many important applications in Digital Humanities research such as information retrieval, document clustering and text summarization. The performance of different methods depends on the length of the text, the domain and the language. This study focuses on experimenting with some of the current approaches to Finnish, which is a morphologically rich language. At the same time, we propose a simple method, TFW2V, which shows high efficiency in handling both long text documents and limited amounts of data. Furthermore, we design an objective evaluation method which can be used as a framework for benchmarking text similarity approaches.
FCMNet: Full Communication Memory Net for Team-Level Cooperation in Multi-Agent Systems
Jan 31, 2022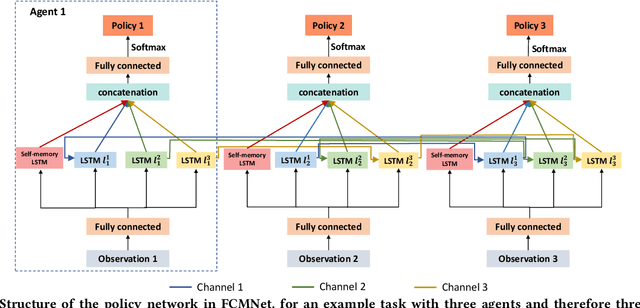


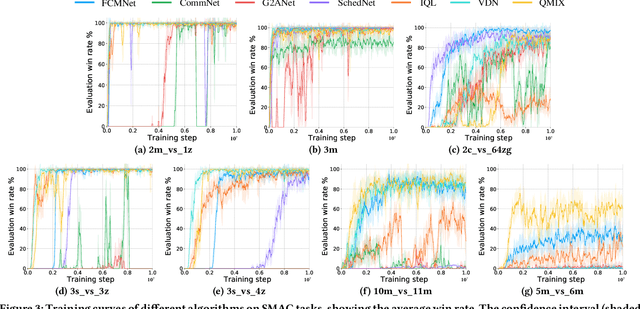
Decentralized cooperation in partially-observable multi-agent systems requires effective communications among agents. To support this effort, this work focuses on the class of problems where global communications are available but may be unreliable, thus precluding differentiable communication learning methods. We introduce FCMNet, a reinforcement learning based approach that allows agents to simultaneously learn a) an effective multi-hop communications protocol and b) a common, decentralized policy that enables team-level decision-making. Specifically, our proposed method utilizes the hidden states of multiple directional recurrent neural networks as communication messages among agents. Using a simple multi-hop topology, we endow each agent with the ability to receive information sequentially encoded by every other agent at each time step, leading to improved global cooperation. We demonstrate FCMNet on a challenging set of StarCraft II micromanagement tasks with shared rewards, as well as a collaborative multi-agent pathfinding task with individual rewards. There, our comparison results show that FCMNet outperforms state-of-the-art communication-based reinforcement learning methods in all StarCraft II micromanagement tasks, and value decomposition methods in certain tasks. We further investigate the robustness of FCMNet under realistic communication disturbances, such as random message loss or binarized messages (i.e., non-differentiable communication channels), to showcase FMCNet's potential applicability to robotic tasks under a variety of real-world conditions.
Infrastructure-enabled GPS Spoofing Detection and Correction
Feb 11, 2022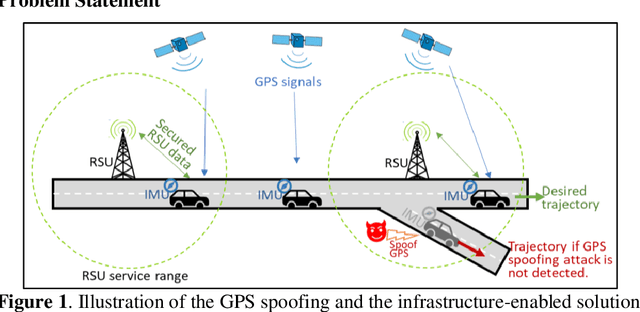
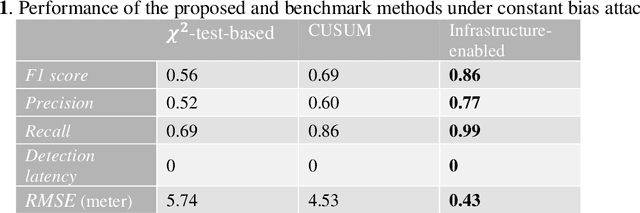
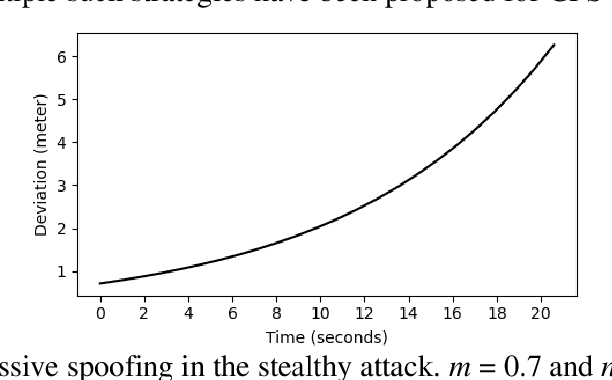
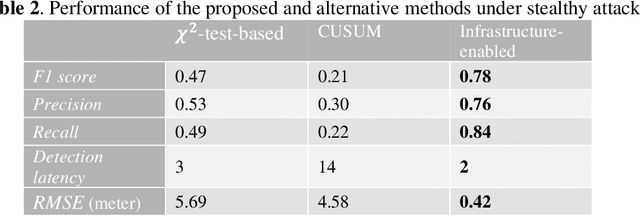
Accurate and robust localization is crucial for supporting high-level driving automation and safety. Modern localization solutions rely on various sensors, among which GPS has been and will continue to be essential. However, GPS can be vulnerable to malicious attacks and GPS spoofing has been identified as a high threat. GPS spoofing injects false information into true GPS measurements, aiming to deviate a vehicle from its true trajectory, endangering the safety of road users. With various types of vehicle-based sensors emerging, recent studies propose to detect GPS spoofing by fusing data from multiple sensors and identifying inconsistencies among them. Yet, these methods often require sophisticated algorithms and cannot handle stealthy or coordinated attacks targeting multiple sensors. With infrastructure becoming increasingly important in supporting emerging vehicle technologies and systems (e.g., automated vehicles), this study explores the potential of applying infrastructure data in defending against GPS spoofing. We propose an infrastructure-enabled method by deploying roadside infrastructure as an independent, secured data source. A real-time detector, based on the Isolation Forest, is constructed to detect GPS spoofing. Once spoofing is detected, GPS measurements are isolated, and the potentially compromised location estimator is corrected using the infrastructure data. The proposed method relies less on vehicular onboard data than existing solutions. Enabled by the secure infrastructure data, we can design a simpler yet more effective solution against GPS spoofing, compared with state-of-the-art defense methods. We test the proposed method using both simulation data and real-world GPS data, and show its effectiveness in defending various types of GPS spoofing attacks, including a type of stealthy attacks that are proposed to fail the production-grade autonomous driving systems.
Dynamical Audio-Visual Navigation: Catching Unheard Moving Sound Sources in Unmapped 3D Environments
Jan 12, 2022
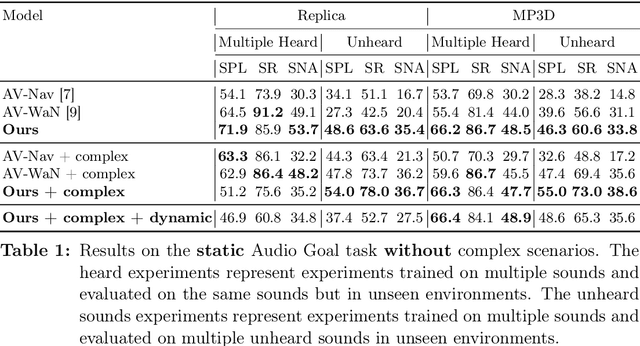
Recent work on audio-visual navigation targets a single static sound in noise-free audio environments and struggles to generalize to unheard sounds. We introduce the novel dynamic audio-visual navigation benchmark in which an embodied AI agent must catch a moving sound source in an unmapped environment in the presence of distractors and noisy sounds. We propose an end-to-end reinforcement learning approach that relies on a multi-modal architecture that fuses the spatial audio-visual information from a binaural audio signal and spatial occupancy maps to encode the features needed to learn a robust navigation policy for our new complex task settings. We demonstrate that our approach outperforms the current state-of-the-art with better generalization to unheard sounds and better robustness to noisy scenarios on the two challenging 3D scanned real-world datasets Replica and Matterport3D, for the static and dynamic audio-visual navigation benchmarks. Our novel benchmark will be made available at http://dav-nav.cs.uni-freiburg.de.
SwinUNet3D -- A Hierarchical Architecture for Deep Traffic Prediction using Shifted Window Transformers
Jan 17, 2022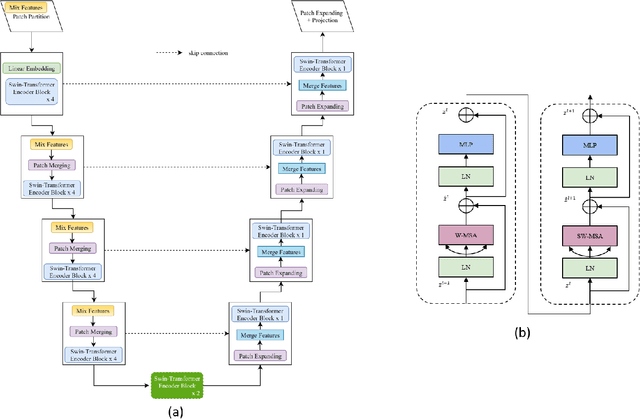
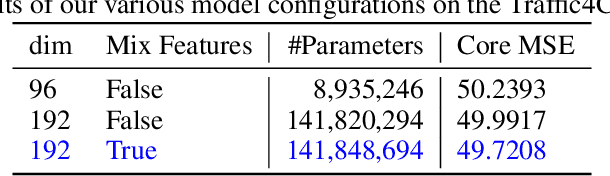

Traffic forecasting is an important element of mobility management, an important key that drives the logistics industry. Over the years, lots of work have been done in Traffic forecasting using time series as well as spatiotemporal dynamic forecasting. In this paper, we explore the use of vision transformer in a UNet setting. We completely remove all convolution-based building blocks in UNet, while using 3D shifted window transformer in both encoder and decoder branches. In addition, we experiment with the use of feature mixing just before patch encoding to control the inter-relationship of the feature while avoiding contraction of the depth dimension of our spatiotemporal input. The proposed network is tested on the data provided by Traffic Map Movie Forecasting Challenge 2021(Traffic4cast2021), held in the competition track of Neural Information Processing Systems (NeurIPS). Traffic4cast2021 task is to predict an hour (6 frames) of traffic conditions (volume and average speed)from one hour of given traffic state (12 frames averaged in 5 minutes time span). Source code is available online at https://github.com/bojesomo/Traffic4Cast2021-SwinUNet3D.
Content-aware Warping for View Synthesis
Jan 22, 2022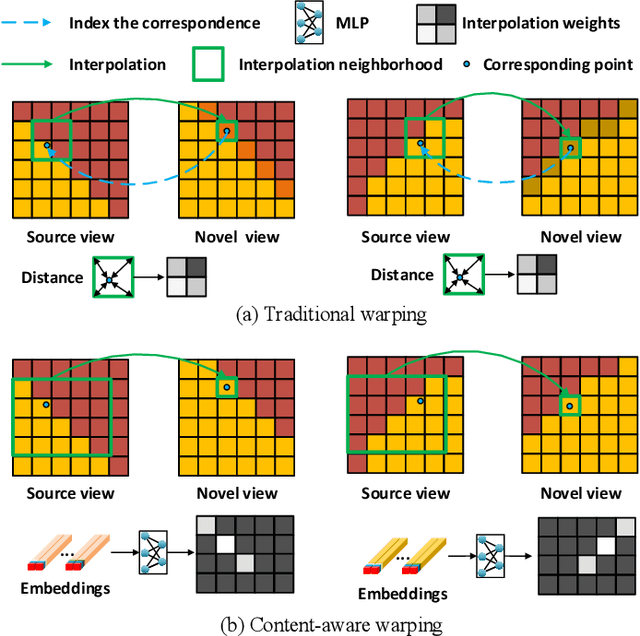
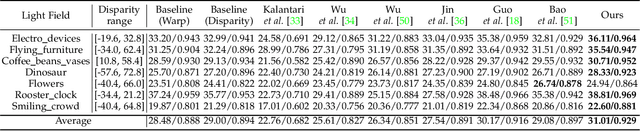
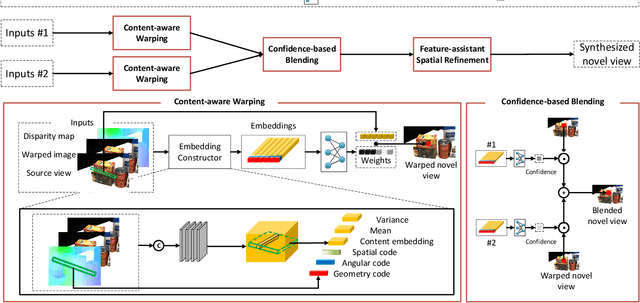

Existing image-based rendering methods usually adopt depth-based image warping operation to synthesize novel views. In this paper, we reason the essential limitations of the traditional warping operation to be the limited neighborhood and only distance-based interpolation weights. To this end, we propose content-aware warping, which adaptively learns the interpolation weights for pixels of a relatively large neighborhood from their contextual information via a lightweight neural network. Based on this learnable warping module, we propose a new end-to-end learning-based framework for novel view synthesis from two input source views, in which two additional modules, namely confidence-based blending and feature-assistant spatial refinement, are naturally proposed to handle the occlusion issue and capture the spatial correlation among pixels of the synthesized view, respectively. Besides, we also propose a weight-smoothness loss term to regularize the network. Experimental results on structured light field datasets with wide baselines and unstructured multi-view datasets show that the proposed method significantly outperforms state-of-the-art methods both quantitatively and visually. The source code will be publicly available at https://github.com/MantangGuo/CW4VS.
Multi-Pair Two-Way Massive MIMO DF Relaying Over Rician Fading Channels Under Imperfect CSI
Oct 28, 2021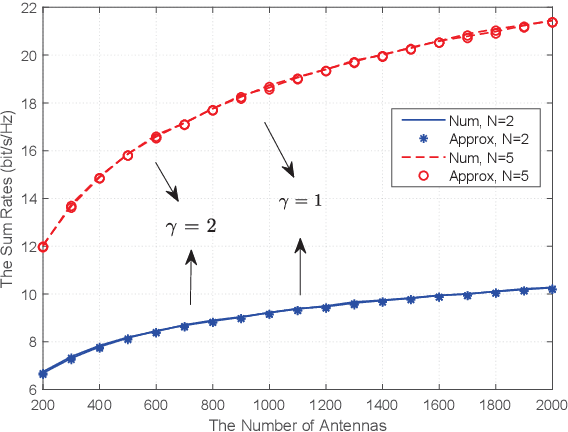
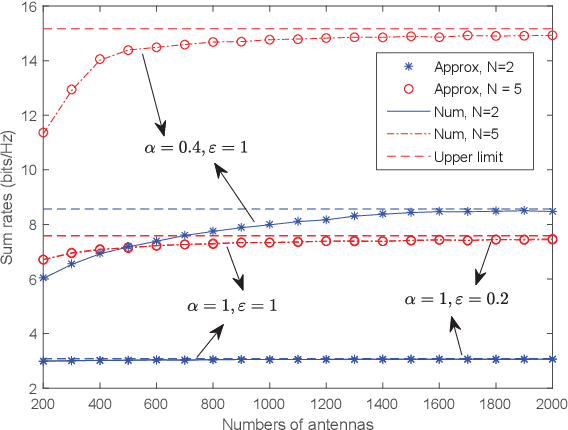

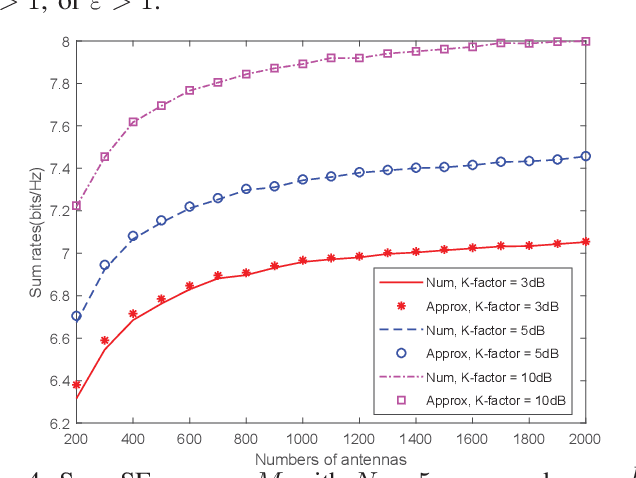
We investigate a multi-pair two-way decode-andforward relaying aided massive multiple-input multiple-output antenna system under Rician fading channels, in which multiple pairs of users exchange information through a relay station having multiple antennas. Imperfect channel state information is considered in the context of maximum-ratio processing. Closedform expressions are derived for approximating the sum spectral efficiency (SE) of the system. Moreover, we obtain the powerscaling laws at the users and the relay station to satisfy a certain SE requirement in three typical scenarios. Finally, simulations validate the accuracy of the derived results.
MHAttnSurv: Multi-Head Attention for Survival Prediction Using Whole-Slide Pathology Images
Oct 22, 2021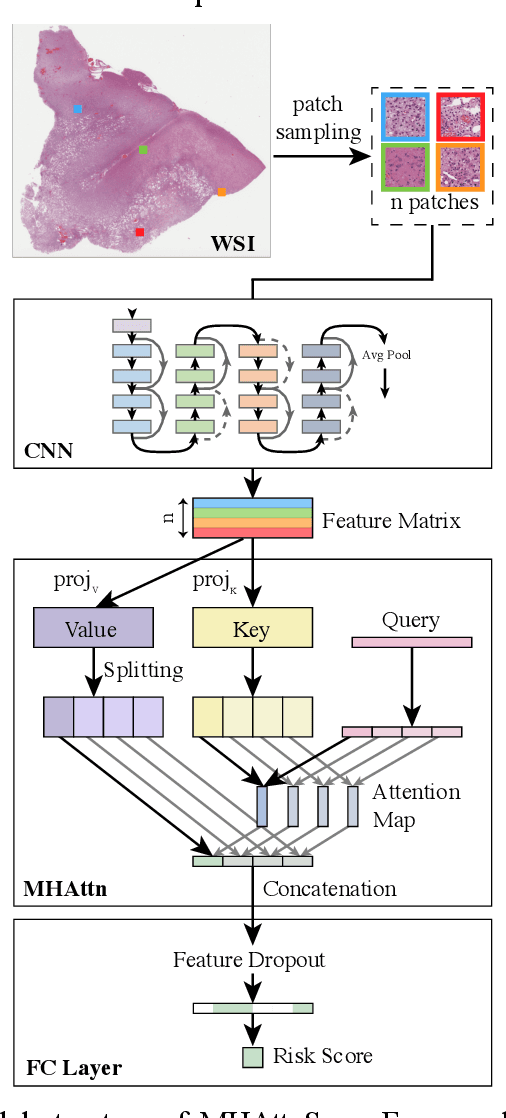
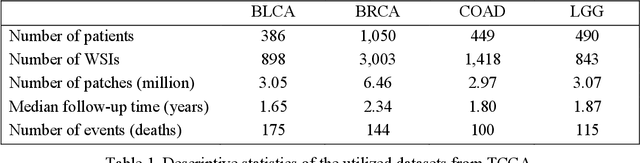
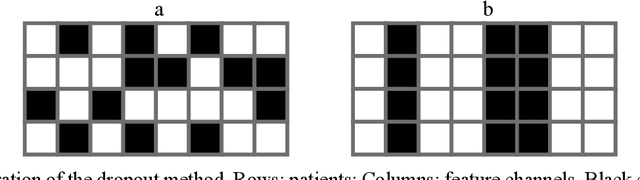
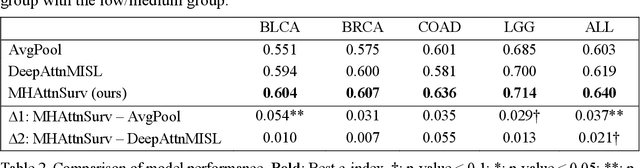
In pathology, whole-slide images (WSI) based survival prediction has attracted increasing interest. However, given the large size of WSIs and the lack of pathologist annotations, extracting the prognostic information from WSIs remains a challenging task. Previous studies have used multiple instance learning approaches to combine the information from multiple randomly sampled patches, but different visual patterns may contribute differently to prognosis prediction. In this study, we developed a multi-head attention approach to focus on various parts of a tumor slide, for more comprehensive information extraction from WSIs. We evaluated our approach on four cancer types from The Cancer Genome Atlas database. Our model achieved an average c-index of 0.640, outperforming two existing state-of-the-art approaches for WSI-based survival prediction, which have an average c-index of 0.603 and 0.619 on these datasets. Visualization of our attention maps reveals each attention head focuses synergistically on different morphological patterns.
Real-World Semantic Grasping Detection
Nov 20, 2021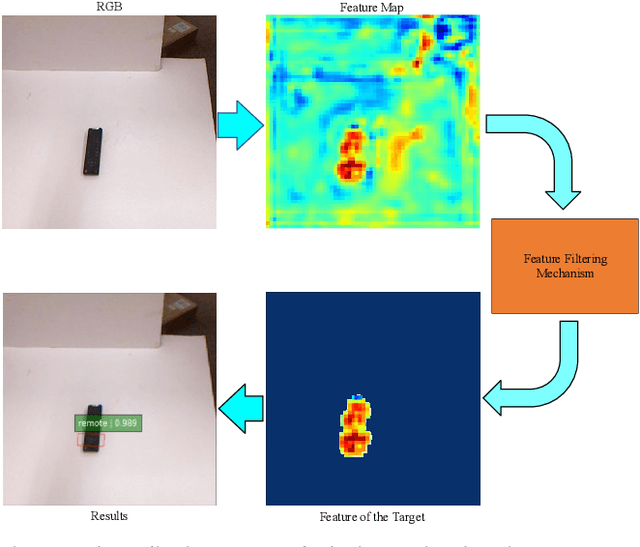
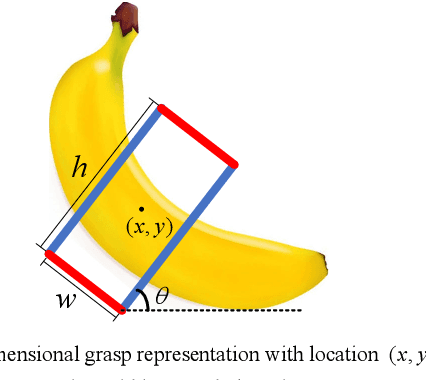
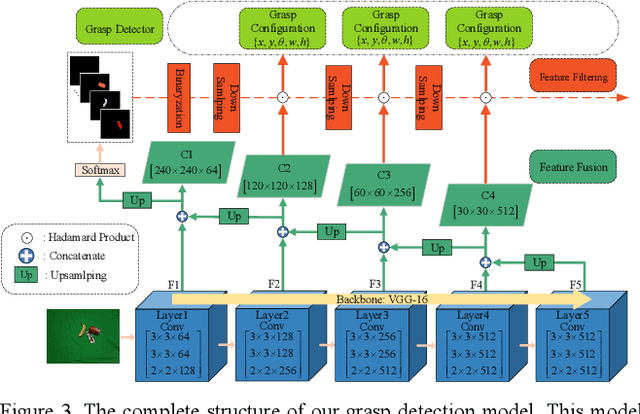

Reducing the scope of grasping detection according to the semantic information of the target is significant to improve the accuracy of the grasping detection model and expand its application. Researchers have been trying to combine these capabilities in an end-to-end network to grasp specific objects in a cluttered scene efficiently. In this paper, we propose an end-to-end semantic grasping detection model, which can accomplish both semantic recognition and grasping detection. And we also design a target feature filtering mechanism, which only maintains the features of a single object according to the semantic information for grasping detection. This method effectively reduces the background features that are weakly correlated to the target object, thus making the features more unique and guaranteeing the accuracy and efficiency of grasping detection. Experimental results show that the proposed method can achieve 98.38% accuracy in Cornell grasping dataset Furthermore, our results on different datasets or evaluation metrics show the domain adaptability of our method over the state-of-the-art.