 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Memory Design in SAM-Based Visual Object Tracking
Dec 27, 2025\noindent Memory has become the central mechanism enabling robust visual object tracking in modern segmentation-based frameworks. Recent methods built upon Segment Anything Model 2 (SAM2) have demonstrated strong performance by refining how past observations are stored and reused. However, existing approaches address memory limitations in a method-specific manner, leaving the broader design principles of memory in SAM-based tracking poorly understood. Moreover, it remains unclear how these memory mechanisms transfer to stronger, next-generation foundation models such as Segment Anything Model 3 (SAM3). In this work, we present a systematic memory-centric study of SAM-based visual object tracking. We first analyze representative SAM2-based trackers and show that most methods primarily differ in how short-term memory frames are selected, while sharing a common object-centric representation. Building on this insight, we faithfully reimplement these memory mechanisms within the SAM3 framework and conduct large-scale evaluations across ten diverse benchmarks, enabling a controlled analysis of memory design independent of backbone strength. Guided by our empirical findings, we propose a unified hybrid memory framework that explicitly decomposes memory into short-term appearance memory and long-term distractor-resolving memory. This decomposition enables the integration of existing memory policies in a modular and principled manner. Extensive experiments demonstrate that the proposed framework consistently improves robustness under long-term occlusion, complex motion, and distractor-heavy scenarios on both SAM2 and SAM3 backbones. Code is available at: https://github.com/HamadYA/SAM3_Tracking_Zoo. \textbf{This is a preprint. Some results are being finalized and may be updated in a future revision.}
Cytoplasmic Strings Analysis in Human Embryo Time-Lapse Videos using Deep Learning Framework
Dec 10, 2025Infertility is a major global health issue, and while in-vitro fertilization has improved treatment outcomes, embryo selection remains a critical bottleneck. Time-lapse imaging enables continuous, non-invasive monitoring of embryo development, yet most automated assessment methods rely solely on conventional morphokinetic features and overlook emerging biomarkers. Cytoplasmic Strings, thin filamentous structures connecting the inner cell mass and trophectoderm in expanded blastocysts, have been associated with faster blastocyst formation, higher blastocyst grades, and improved viability. However, CS assessment currently depends on manual visual inspection, which is labor-intensive, subjective, and severely affected by detection and subtle visual appearance. In this work, we present, to the best of our knowledge, the first computational framework for CS analysis in human IVF embryos. We first design a human-in-the-loop annotation pipeline to curate a biologically validated CS dataset from TLI videos, comprising 13,568 frames with highly sparse CS-positive instances. Building on this dataset, we propose a two-stage deep learning framework that (i) classifies CS presence at the frame level and (ii) localizes CS regions in positive cases. To address severe imbalance and feature uncertainty, we introduce the Novel Uncertainty-aware Contractive Embedding (NUCE) loss, which couples confidence-aware reweighting with an embedding contraction term to form compact, well-separated class clusters. NUCE consistently improves F1-score across five transformer backbones, while RF-DETR-based localization achieves state-of-the-art (SOTA) detection performance for thin, low-contrast CS structures. The source code will be made publicly available at: https://github.com/HamadYA/CS_Detection.
A Novel Transformer Network with Shifted Window Cross-Attention for Spatiotemporal Weather Forecasting
Aug 02, 2022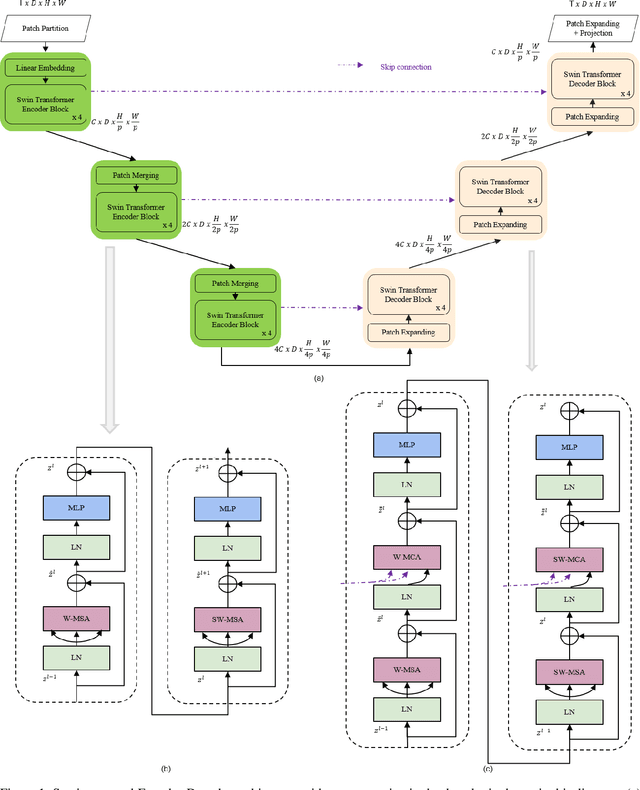

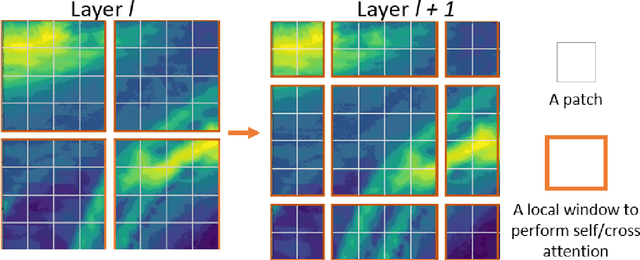

Earth Observatory is a growing research area that can capitalize on the powers of AI for short time forecasting, a Now-casting scenario. In this work, we tackle the challenge of weather forecasting using a video transformer network. Vision transformer architectures have been explored in various applications, with major constraints being the computational complexity of Attention and the data hungry training. To address these issues, we propose the use of Video Swin-Transformer, coupled with a dedicated augmentation scheme. Moreover, we employ gradual spatial reduction on the encoder side and cross-attention on the decoder. The proposed approach is tested on the Weather4Cast2021 weather forecasting challenge data, which requires the prediction of 8 hours ahead future frames (4 per hour) from an hourly weather product sequence. The dataset was normalized to 0-1 to facilitate using the evaluation metrics across different datasets. The model results in an MSE score of 0.4750 when provided with training data, and 0.4420 during transfer learning without using training data, respectively.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022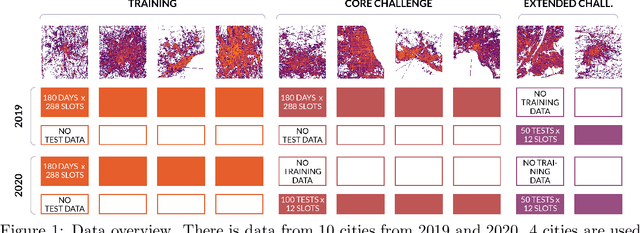
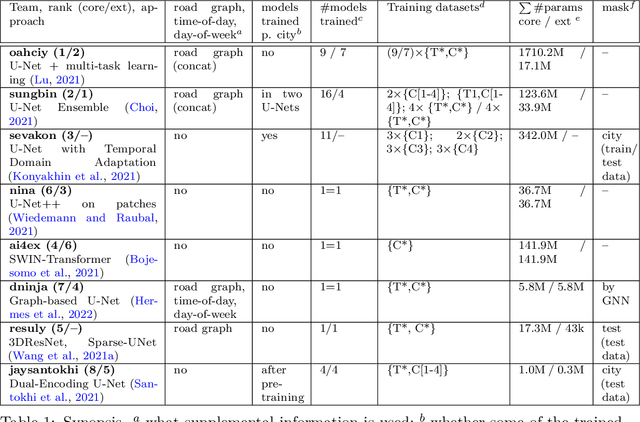
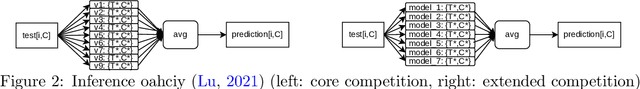
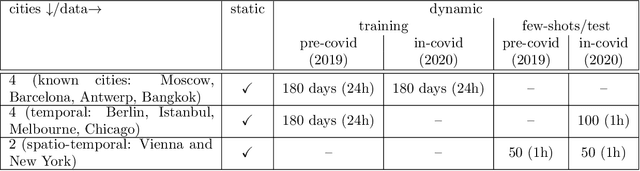
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
SwinUNet3D -- A Hierarchical Architecture for Deep Traffic Prediction using Shifted Window Transformers
Jan 17, 2022


Traffic forecasting is an important element of mobility management, an important key that drives the logistics industry. Over the years, lots of work have been done in Traffic forecasting using time series as well as spatiotemporal dynamic forecasting. In this paper, we explore the use of vision transformer in a UNet setting. We completely remove all convolution-based building blocks in UNet, while using 3D shifted window transformer in both encoder and decoder branches. In addition, we experiment with the use of feature mixing just before patch encoding to control the inter-relationship of the feature while avoiding contraction of the depth dimension of our spatiotemporal input. The proposed network is tested on the data provided by Traffic Map Movie Forecasting Challenge 2021(Traffic4cast2021), held in the competition track of Neural Information Processing Systems (NeurIPS). Traffic4cast2021 task is to predict an hour (6 frames) of traffic conditions (volume and average speed)from one hour of given traffic state (12 frames averaged in 5 minutes time span). Source code is available online at https://github.com/bojesomo/Traffic4Cast2021-SwinUNet3D.
Traffic flow prediction using Deep Sedenion Networks
Dec 11, 2020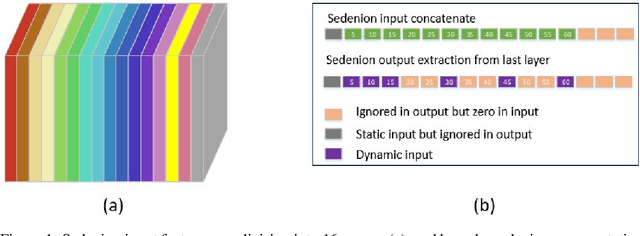
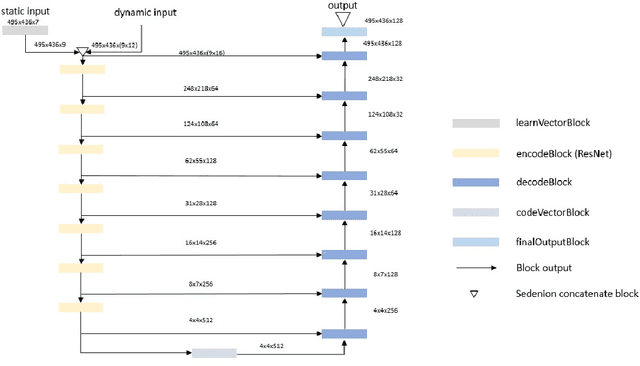
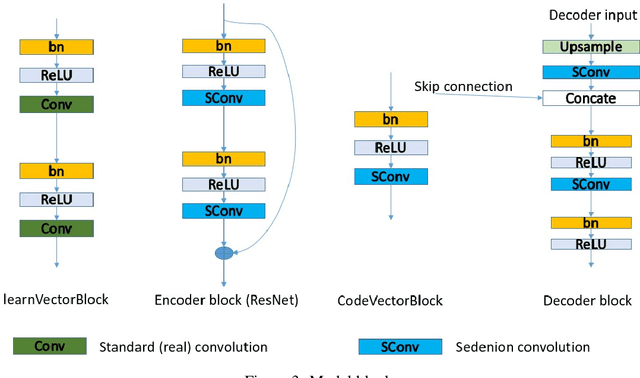

In this paper, we present our solution to the Traffic4cast2020 traffic prediction challenge. In this competition, participants are to predict future traffic parameters (speed and volume) in three different cities: Berlin, Istanbul and Moscow. The information provided includes nine channels where the first eight represent the speed and volume for four different direction of traffic (NE, NW, SE and SW), while the last channel is used to indicate presence of traffic incidents. The expected output should have the first 8 channels of the input at six future timing intervals (5, 10, 15, 30, 45, and 60min), while a one hour duration of past traffic data, in 5mins intervals, are provided as input. We solve the problem using a novel sedenion U-Net neural network. Sedenion networks provide the means for efficient encoding of correlated multimodal datasets. We use 12 of the 15 sedenion imaginary parts for the dynamic inputs and the real sedenion component is used for the static input. The sedenion output of the network is used to represent the multimodal traffic predictions. Proposed system achieved a validation MSE of 1.33e-3 and a test MSE of 1.31e-3.