 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GISNet: Graph-Based Information Sharing Network For Vehicle Trajectory Prediction
Mar 22, 2020
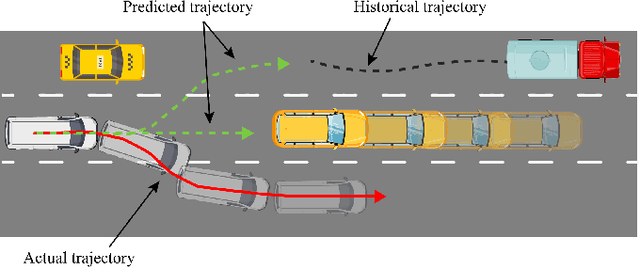
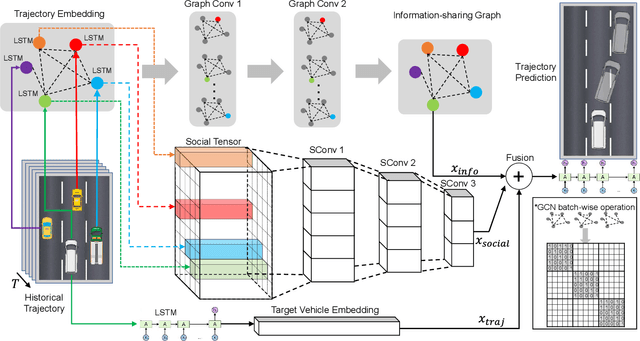
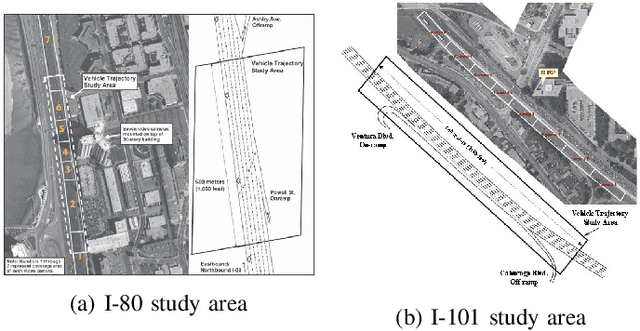
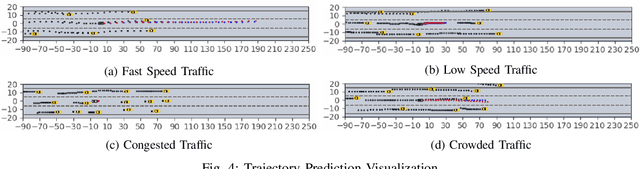
The trajectory prediction is a critical and challenging problem in the design of an autonomous driving system. Many AI-oriented companies, such as Google Waymo, Uber and DiDi, are investigating more accurate vehicle trajectory prediction algorithms. However, the prediction performance is governed by lots of entangled factors, such as the stochastic behaviors of surrounding vehicles, historical information of self-trajectory, and relative positions of neighbors, etc. In this paper, we propose a novel graph-based information sharing network (GISNet) that allows the information sharing between the target vehicle and its surrounding vehicles. Meanwhile, the model encodes the historical trajectory information of all the vehicles in the scene. Experiments are carried out on the public NGSIM US-101 and I-80 Dataset and the prediction performance is measured by the Root Mean Square Error (RMSE). The quantitative and qualitative experimental results show that our model significantly improves the trajectory prediction accuracy, by up to 50.00%, compared to existing models.
Augmented Business Process Management Systems: A Research Manifesto
Feb 03, 2022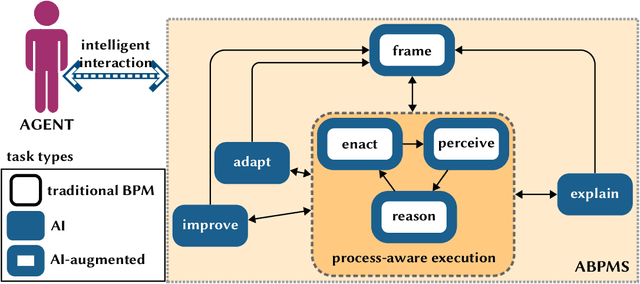
Augmented Business Process Management Systems (ABPMSs) are an emerging class of process-aware information systems that draws upon trustworthy AI technology. An ABPMS enhances the execution of business processes with the aim of making these processes more adaptable, proactive, explainable, and context-sensitive. This manifesto presents a vision for ABPMSs and discusses research challenges that need to be surmounted to realize this vision. To this end, we define the concept of ABPMS, we outline the lifecycle of processes within an ABPMS, we discuss core characteristics of an ABPMS, and we derive a set of challenges to realize systems with these characteristics.
TANDEM: Learning Joint Exploration and Decision Making with Tactile Sensors
Mar 01, 2022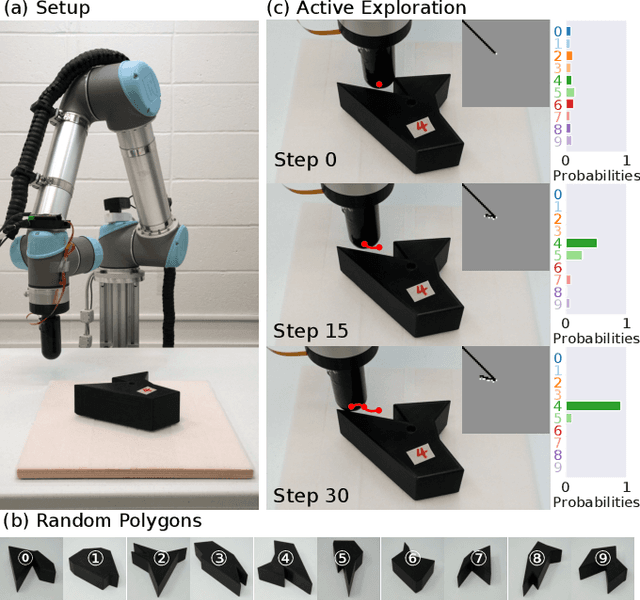
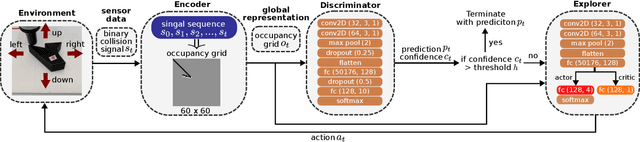
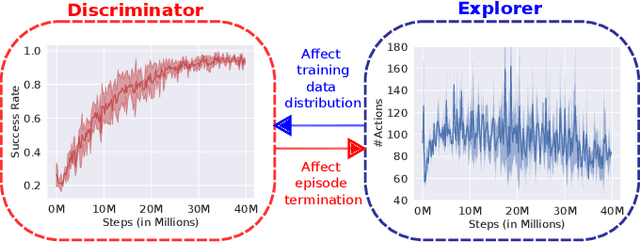
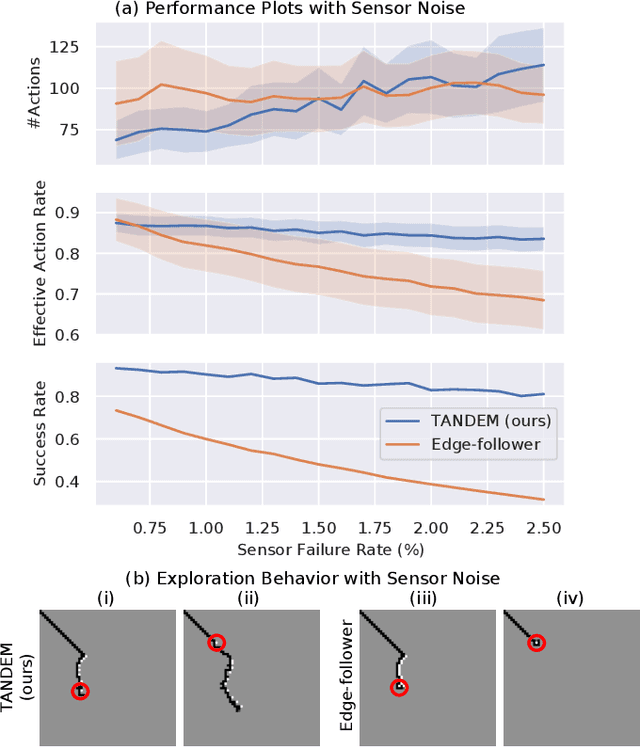
Inspired by the human ability to perform complex manipulation in the complete absence of vision (like retrieving an object from a pocket), the robotic manipulation field is motivated to develop new methods for tactile-based object interaction. However, tactile sensing presents the challenge of being an active sensing modality: a touch sensor provides sparse, local data, and must be used in conjunction with effective exploration strategies in order to collect information. In this work, we focus on the process of guiding tactile exploration, and its interplay with task-related decision making. We propose TANDEM (TActile exploration aNd DEcision Making), an architecture to learn efficient exploration strategies in conjunction with decision making. Our approach is based on separate but co-trained modules for exploration and discrimination. We demonstrate this method on a tactile object recognition task, where a robot equipped with a touch sensor must explore and identify an object from a known set based on tactile feedback alone. TANDEM achieves higher accuracy with fewer actions than alternative methods and is also shown to be more robust to sensor noise.
Convolutional Neural Network Modelling for MODIS Land Surface Temperature Super-Resolution
Feb 22, 2022
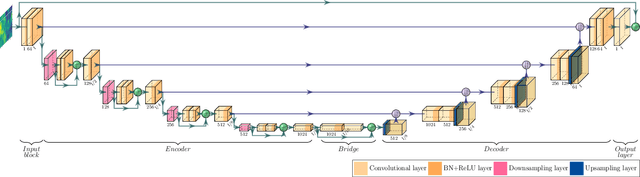
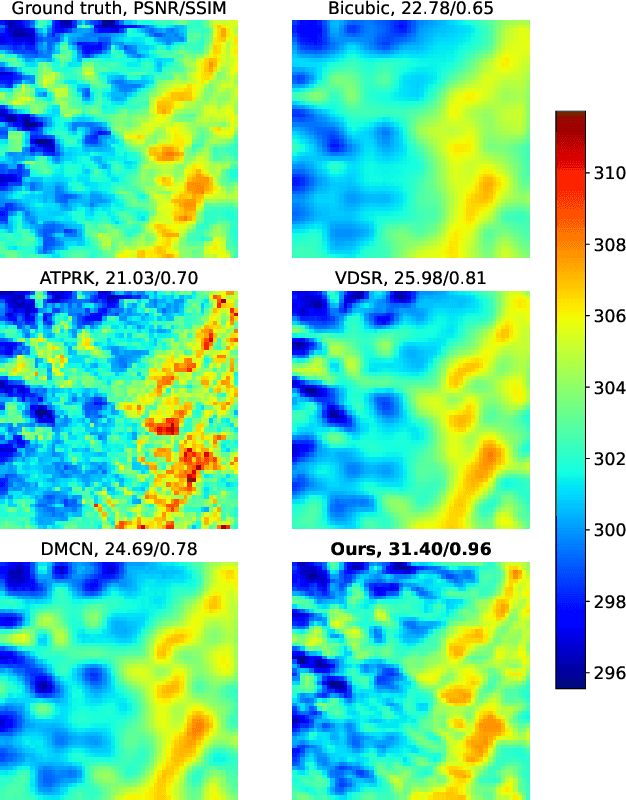
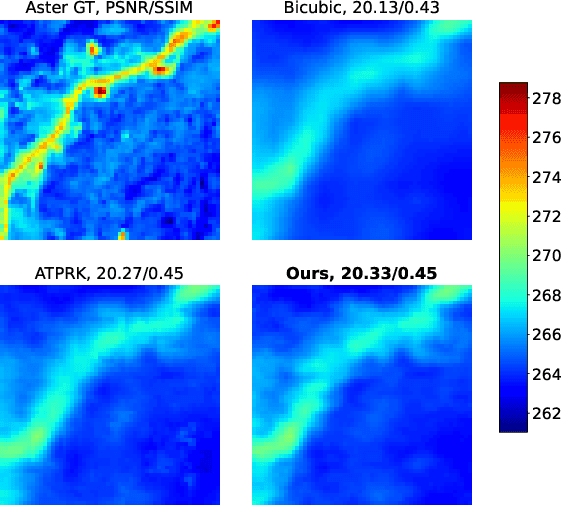
Nowadays, thermal infrared satellite remote sensors enable to extract very interesting information at large scale, in particular Land Surface Temperature (LST). However such data are limited in spatial and/or temporal resolutions which prevents from an analysis at fine scales. For example, MODIS satellite provides daily acquisitions with 1Km spatial resolutions which is not sufficient to deal with highly heterogeneous environments as agricultural parcels. Therefore, image super-resolution is a crucial task to better exploit MODIS LSTs. This issue is tackled in this paper. We introduce a deep learning-based algorithm, named Multi-residual U-Net, for super-resolution of MODIS LST single-images. Our proposed network is a modified version of U-Net architecture, which aims at super-resolving the input LST image from 1Km to 250m per pixel. The results show that our Multi-residual U-Net outperforms other state-of-the-art methods.
Prediction-Guided Distillation for Dense Object Detection
Mar 10, 2022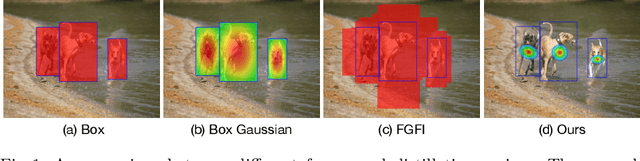
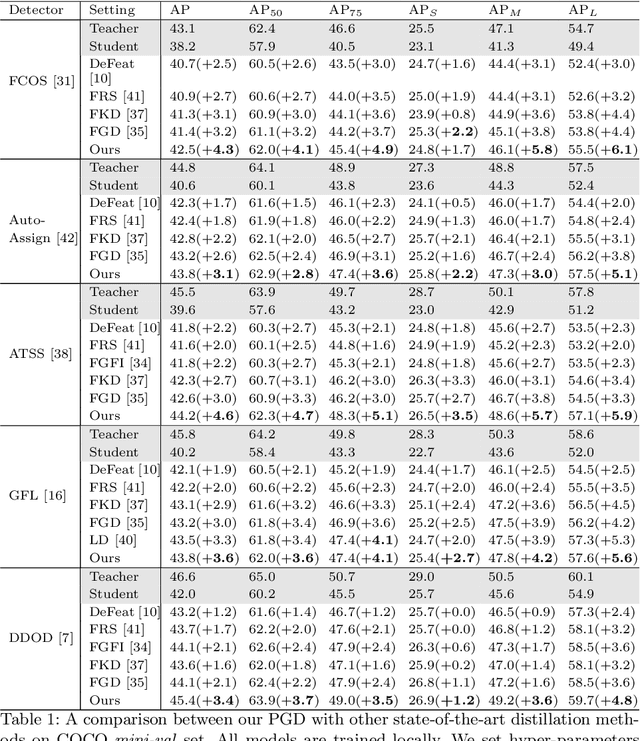

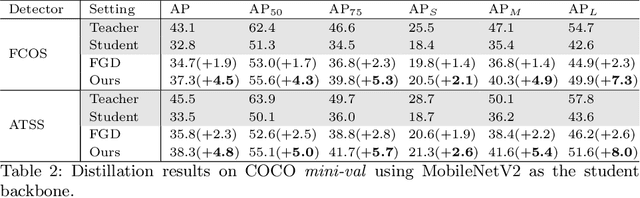
Real-world object detection models should be cheap and accurate. Knowledge distillation (KD) can boost the accuracy of a small, cheap detection model by leveraging useful information from a larger teacher model. However, a key challenge is identifying the most informative features produced by the teacher for distillation. In this work, we show that only a very small fraction of features within a ground-truth bounding box are responsible for a teacher's high detection performance. Based on this, we propose Prediction-Guided Distillation (PGD), which focuses distillation on these key predictive regions of the teacher and yields considerable gains in performance over many existing KD baselines. In addition, we propose an adaptive weighting scheme over the key regions to smooth out their influence and achieve even better performance. Our proposed approach outperforms current state-of-the-art KD baselines on a variety of advanced one-stage detection architectures. Specifically, on the COCO dataset, our method achieves between +3.1% and +4.6% AP improvement using ResNet-101 and ResNet-50 as the teacher and student backbones, respectively. On the CrowdHuman dataset, we achieve +3.2% and +2.0% improvements in MR and AP, also using these backbones. Our code is available at https://github.com/ChenhongyiYang/PGD.
Single microphone speaker extraction using unified time-frequency Siamese-Unet
Mar 06, 2022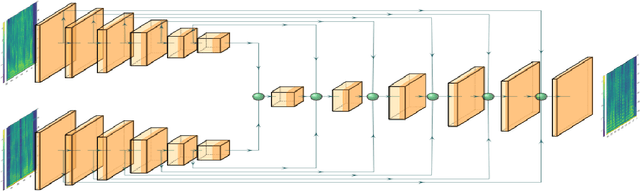
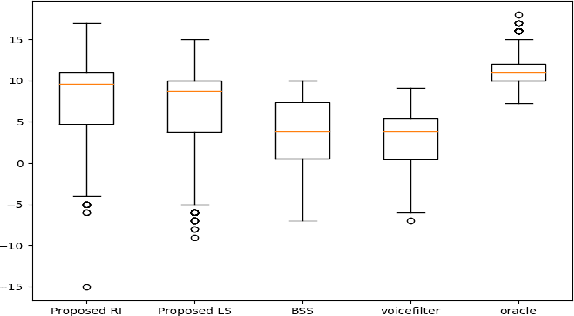
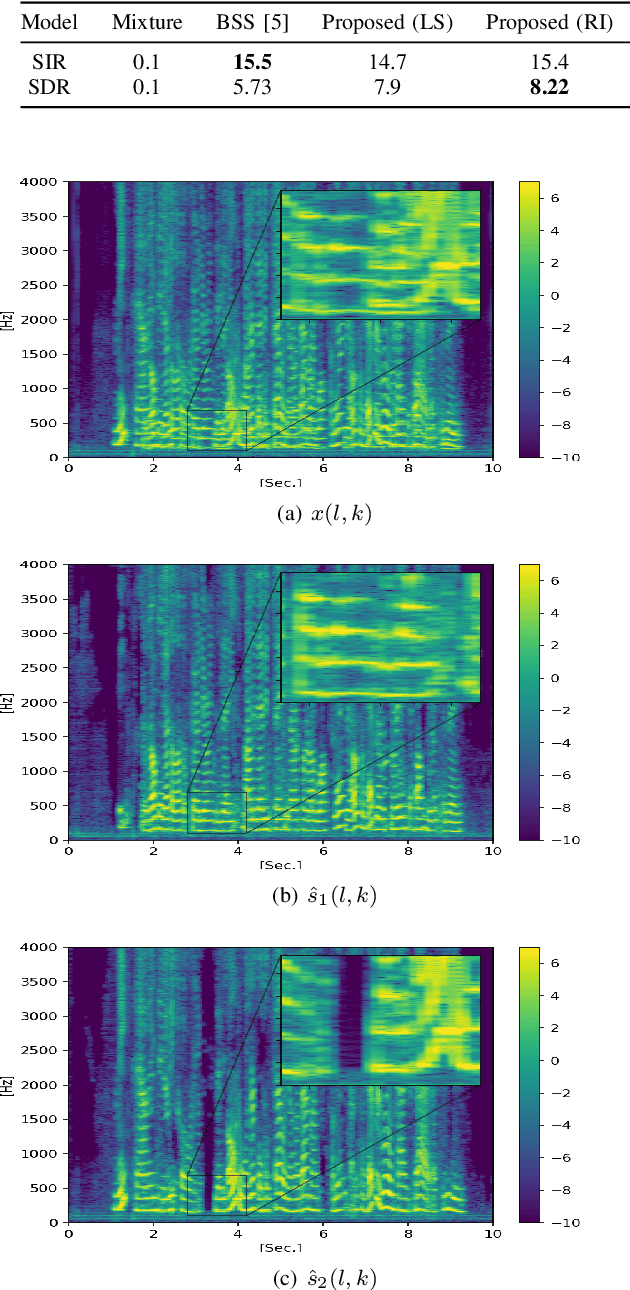

In this paper we present a unified time-frequency method for speaker extraction in clean and noisy conditions. Given a mixed signal, along with a reference signal, the common approaches for extracting the desired speaker are either applied in the time-domain or in the frequency-domain. In our approach, we propose a Siamese-Unet architecture that uses both representations. The Siamese encoders are applied in the frequency-domain to infer the embedding of the noisy and reference spectra, respectively. The concatenated representations are then fed into the decoder to estimate the real and imaginary components of the desired speaker, which are then inverse-transformed to the time-domain. The model is trained with the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) loss to exploit the time-domain information. The time-domain loss is also regularized with frequency-domain loss to preserve the speech patterns. Experimental results demonstrate that the unified approach is not only very easy to train, but also provides superior results as compared with state-of-the-art (SOTA) Blind Source Separation (BSS) methods, as well as commonly used speaker extraction approach.
Human and Machine Action Prediction Independent of Object Information
Apr 22, 2020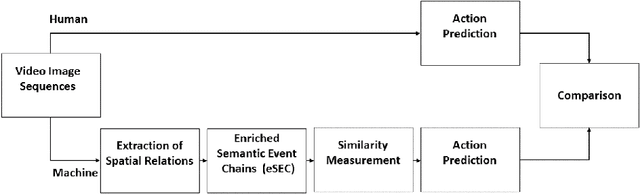
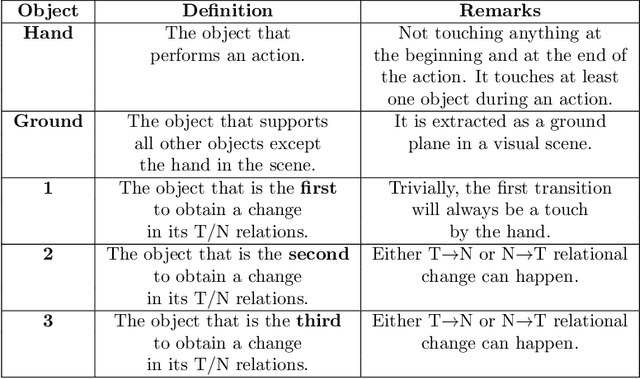

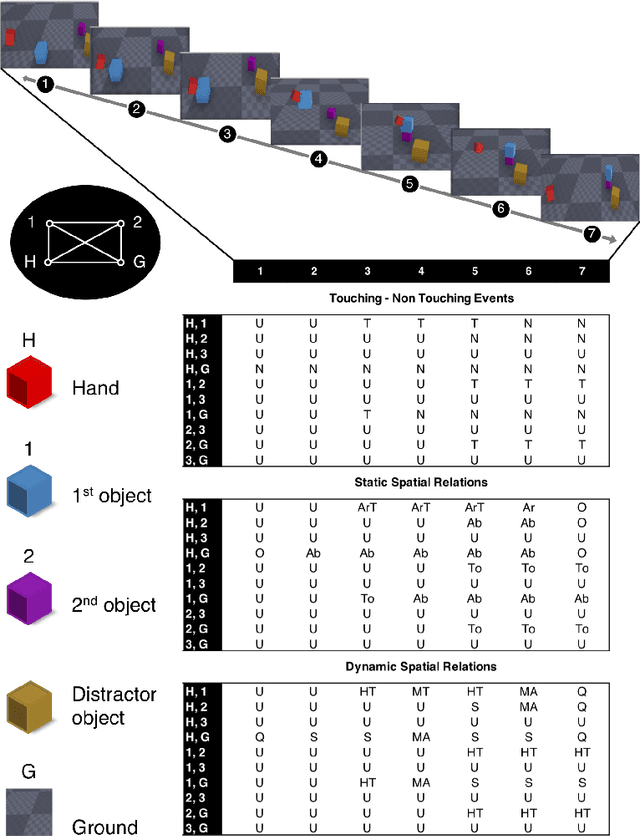
Predicting other people's action is key to successful social interactions, enabling us to adjust our own behavior to the consequence of the others' future actions. Studies on action recognition have focused on the importance of individual visual features of objects involved in an action and its context. Humans, however, recognize actions on unknown objects or even when objects are imagined (pantomime). Other cues must thus compensate the lack of recognizable visual object features. Here, we focus on the role of inter-object relations that change during an action. We designed a virtual reality setup and tested recognition speed for 10 different manipulation actions on 50 subjects. All objects were abstracted by emulated cubes so the actions could not be inferred using object information. Instead, subjects had to rely only on the information that comes from the changes in the spatial relations that occur between those cubes. In spite of these constraints, our results show the subjects were able to predict actions in, on average, less than 64% of the action's duration. We employed a computational model -an enriched Semantic Event Chain (eSEC)- incorporating the information of spatial relations, specifically (a) objects' touching/untouching, (b) static spatial relations between objects and (c) dynamic spatial relations between objects. Trained on the same actions as those observed by subjects, the model successfully predicted actions even better than humans. Information theoretical analysis shows that eSECs optimally use individual cues, whereas humans presumably mostly rely on a mixed-cue strategy, which takes longer until recognition. Providing a better cognitive basis of action recognition may, on one hand improve our understanding of related human pathologies and, on the other hand, also help to build robots for conflict-free human-robot cooperation. Our results open new avenues here.
RGB-Depth Fusion GAN for Indoor Depth Completion
Mar 21, 2022
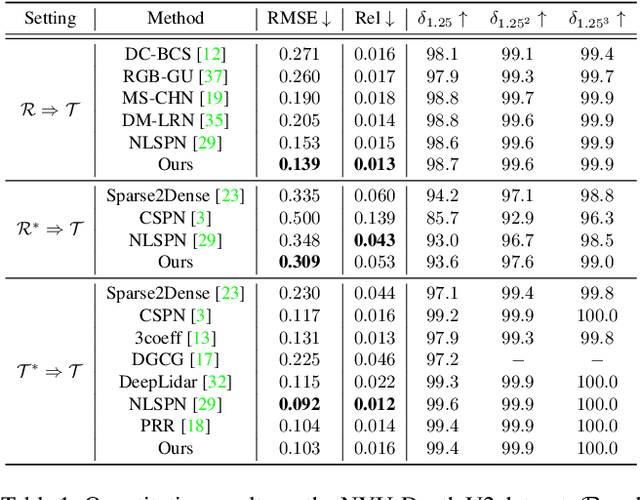
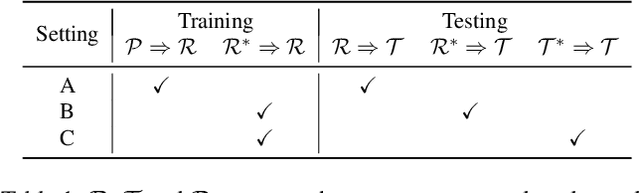
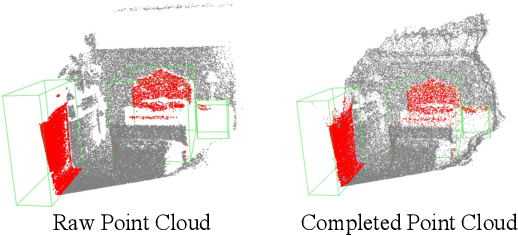
The raw depth image captured by the indoor depth sensor usually has an extensive range of missing depth values due to inherent limitations such as the inability to perceive transparent objects and limited distance range. The incomplete depth map burdens many downstream vision tasks, and a rising number of depth completion methods have been proposed to alleviate this issue. While most existing methods can generate accurate dense depth maps from sparse and uniformly sampled depth maps, they are not suitable for complementing the large contiguous regions of missing depth values, which is common and critical. In this paper, we design a novel two-branch end-to-end fusion network, which takes a pair of RGB and incomplete depth images as input to predict a dense and completed depth map. The first branch employs an encoder-decoder structure to regress the local dense depth values from the raw depth map, with the help of local guidance information extracted from the RGB image. In the other branch, we propose an RGB-depth fusion GAN to transfer the RGB image to the fine-grained textured depth map. We adopt adaptive fusion modules named W-AdaIN to propagate the features across the two branches, and we append a confidence fusion head to fuse the two outputs of the branches for the final depth map. Extensive experiments on NYU-Depth V2 and SUN RGB-D demonstrate that our proposed method clearly improves the depth completion performance, especially in a more realistic setting of indoor environments with the help of the pseudo depth map.
Overcoming Oversmoothness in Graph Convolutional Networks via Hybrid Scattering Networks
Jan 22, 2022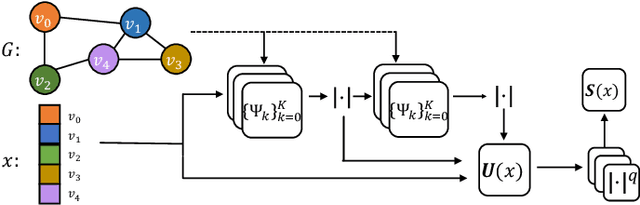
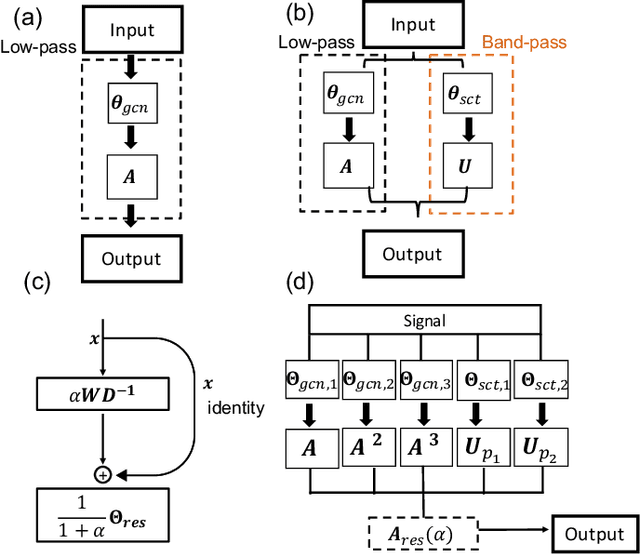
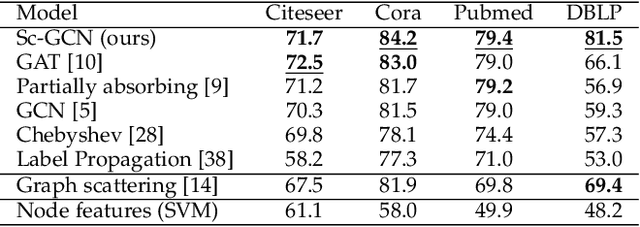
Geometric deep learning (GDL) has made great strides towards generalizing the design of structure-aware neural network architectures from traditional domains to non-Euclidean ones, such as graphs. This gave rise to graph neural network (GNN) models that can be applied to graph-structured datasets arising, for example, in social networks, biochemistry, and material science. Graph convolutional networks (GCNs) in particular, inspired by their Euclidean counterparts, have been successful in processing graph data by extracting structure-aware features. However, current GNN models (and GCNs in particular) are known to be constrained by various phenomena that limit their expressive power and ability to generalize to more complex graph datasets. Most models essentially rely on low-pass filtering of graph signals via local averaging operations, thus leading to oversmoothing. Here, we propose a hybrid GNN framework that combines traditional GCN filters with band-pass filters defined via the geometric scattering transform. We further introduce an attention framework that allows the model to locally attend over the combined information from different GNN filters at the node level. Our theoretical results establish the complementary benefits of the scattering filters to leverage structural information from the graph, while our experiments show the benefits of our method on various learning tasks.
A Self-Tuning Impedance-based Interaction Planner for Robotic Haptic Exploration
Mar 10, 2022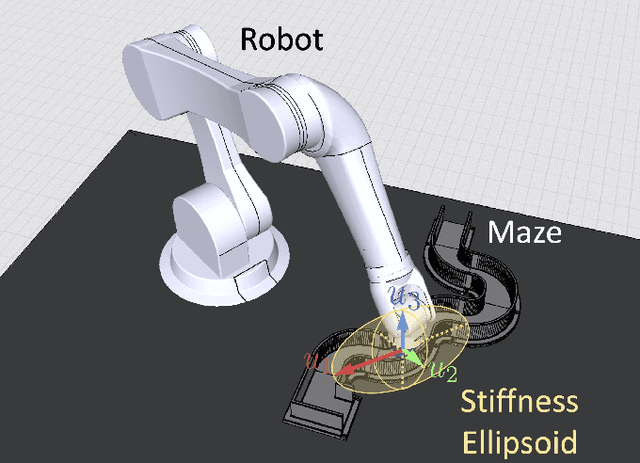
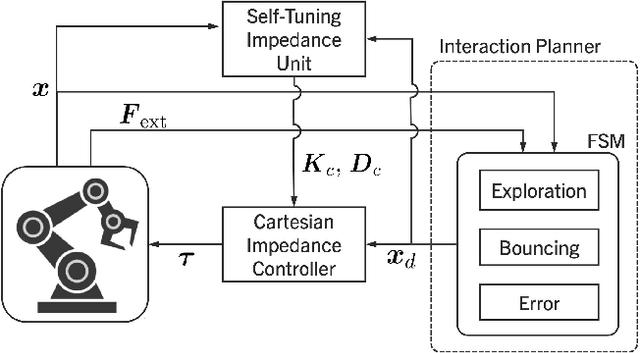


This paper presents a novel interaction planning method that exploits impedance tuning techniques in response to environmental uncertainties and unpredictable conditions using haptic information only. The proposed algorithm plans the robot's trajectory based on the haptic interaction with the environment and adapts planning strategies as needed. Two approaches are considered: Exploration and Bouncing strategies. The Exploration strategy takes the actual motion of the robot into account in planning, while the Bouncing strategy exploits the forces and the motion vector of the robot. Moreover, self-tuning impedance is performed according to the planned trajectory to ensure stable contact and low contact forces. In order to show the performance of the proposed methodology, two experiments with a torque-controller robotic arm are carried out. The first considers a maze exploration without obstacles, whereas the second includes obstacles. The proposed method performance is analyzed and compared against previously proposed solutions in both cases. Experimental results demonstrate that: i) the robot can successfully plan its trajectory autonomously in the most feasible direction according to the interaction with the environment, and ii) a stable interaction with an unknown environment despite the uncertainties is achieved. Finally, a scalability demonstration is carried out to show the potential of the proposed method under multiple scenarios.