 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic-guided Image Virtual Attribute Learning for Noisy Multi-label Chest X-ray Classification
Mar 03, 2022
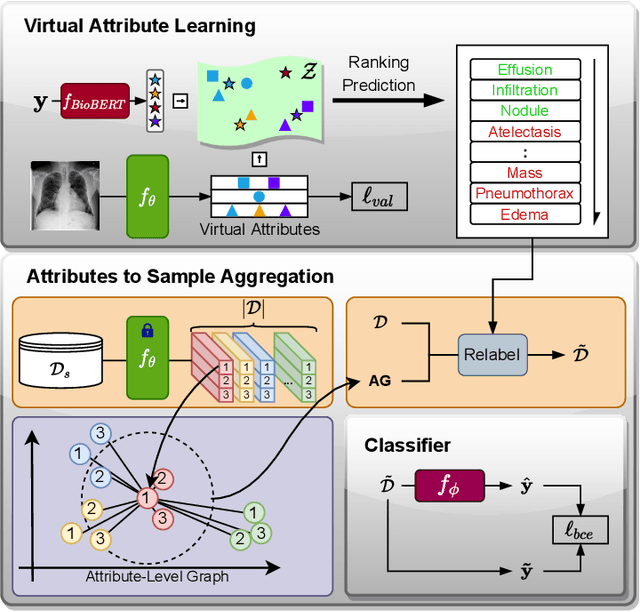
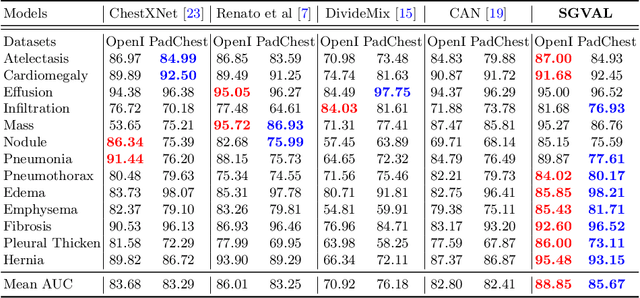
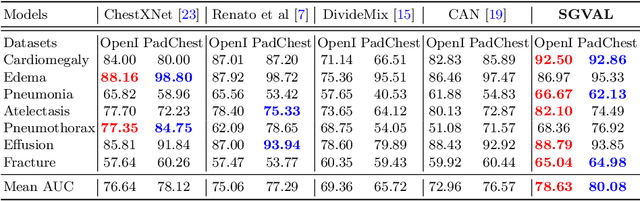
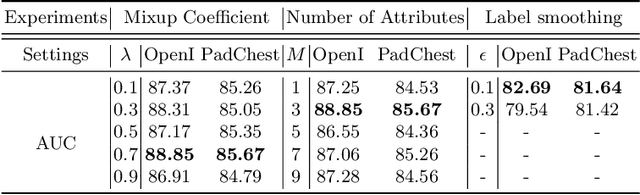
Deep learning methods have shown outstanding classification accuracy in medical image analysis problems, which is largely attributed to the availability of large datasets manually annotated with clean labels. However, such manual annotation can be expensive to obtain for large datasets, so we may rely on machine-generated noisy labels. Many Chest X-ray (CXR) classifiers are modelled from datasets with machine-generated labels, but their training procedure is in general not robust to the presence of noisy-label samples and can overfit those samples to produce sub-optimal solutions. Furthermore, CXR datasets are mostly multi-label, so current noisy-label learning methods designed for multi-class problems cannot be easily adapted. To address such noisy multi-label CXR learning problem, we propose a new learning method based on estimating image virtual attributes using semantic information from the label to assist in the identification and correction of noisy multi-labels from training samples. Our experiments on diverse noisy multi-label training sets and clean testing sets show that our model has state-of-the-art accuracy and robustness across all datasets.
Learning-Driven Lossy Image Compression; A Comprehensive Survey
Jan 23, 2022
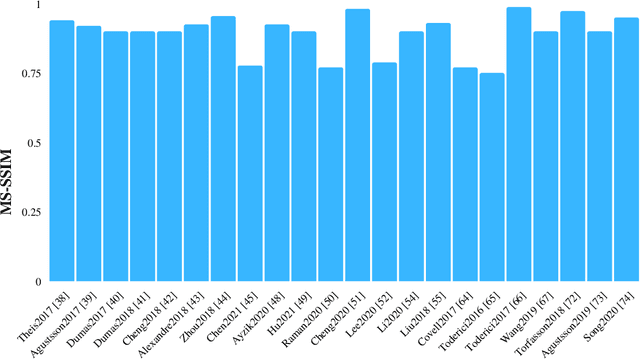
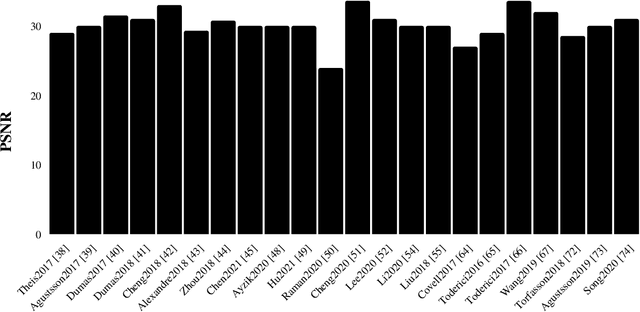
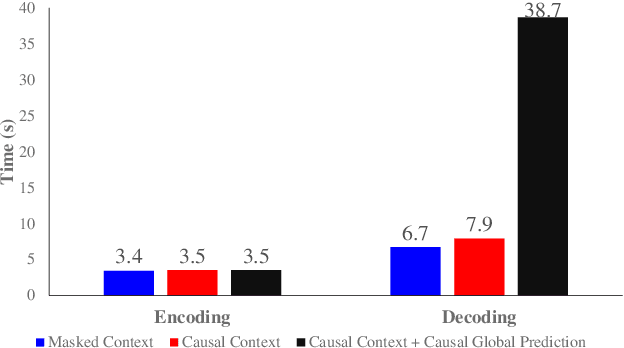
In the realm of image processing and computer vision (CV), machine learning (ML) architectures are widely applied. Convolutional neural networks (CNNs) solve a wide range of image processing issues and can solve image compression problem. Compression of images is necessary due to bandwidth and memory constraints. Helpful, redundant, and irrelevant information are three different forms of information found in images. This paper aims to survey recent techniques utilizing mostly lossy image compression using ML architectures including different auto-encoders (AEs) such as convolutional auto-encoders (CAEs), variational auto-encoders (VAEs), and AEs with hyper-prior models, recurrent neural networks (RNNs), CNNs, generative adversarial networks (GANs), principal component analysis (PCA) and fuzzy means clustering. We divide all of the algorithms into several groups based on architecture. We cover still image compression in this survey. Various discoveries for the researchers are emphasized and possible future directions for researchers. The open research problems such as out of memory (OOM), striped region distortion (SRD), aliasing, and compatibility of the frameworks with central processing unit (CPU) and graphics processing unit (GPU) simultaneously are explained. The majority of the publications in the compression domain surveyed are from the previous five years and use a variety of approaches.
D-HAN: Dynamic News Recommendation with Hierarchical Attention Network
Dec 19, 2021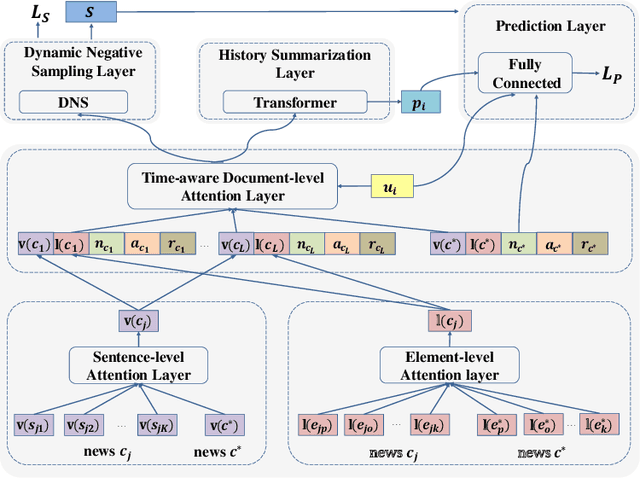
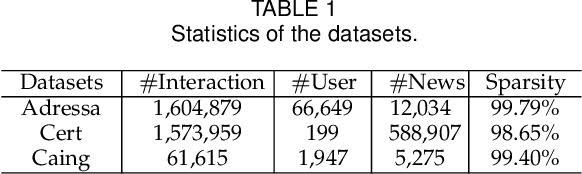
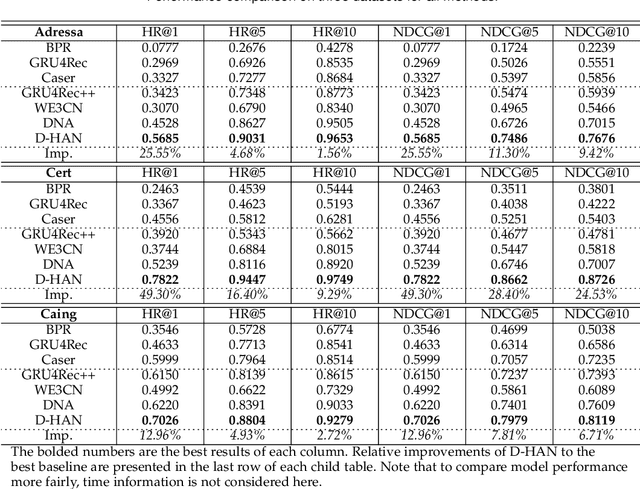
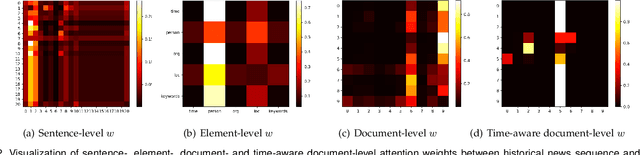
News recommendation is an effective information dissemination solution in modern society. While recent years have witnessed many promising news recommendation models, they mostly capture the user-news interactions on the document-level in a static manner. However, in real-world scenarios, the news can be quite complex and diverse, blindly squeezing all the contents into an embedding vector can be less effective in extracting information compatible with the personalized preference of the users. In addition, user preferences in the news recommendation scenario can be highly dynamic, and a tailored dynamic mechanism should be designed for better recommendation performance. In this paper, we propose a novel dynamic news recommender model. For better understanding the news content, we leverage the attention mechanism to represent the news from the sentence-, element- and document-levels, respectively. For capturing users' dynamic preferences, the continuous time information is seamlessly incorporated into the computing of the attention weights. More specifically, we design a hierarchical attention network, where the lower layer learns the importance of different sentences and elements, and the upper layer captures the correlations between the previously interacted and the target news. To comprehensively model the dynamic characters, we firstly enhance the traditional attention mechanism by incorporating both absolute and relative time information, and then we propose a dynamic negative sampling method to optimize the users' implicit feedback. We conduct extensive experiments based on three real-world datasets to demonstrate our model's effectiveness. Our source code and pre-trained representations are available at https://github.com/lshowway/D-HAN.
Unsupervised Domain Adaptation with Contrastive Learning for OCT Segmentation
Mar 07, 2022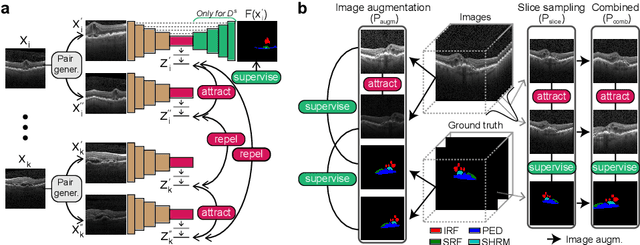
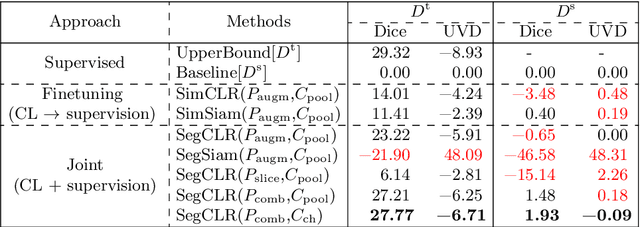

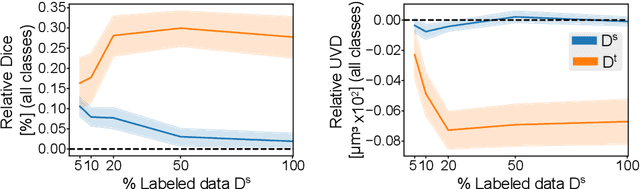
Accurate segmentation of retinal fluids in 3D Optical Coherence Tomography images is key for diagnosis and personalized treatment of eye diseases. While deep learning has been successful at this task, trained supervised models often fail for images that do not resemble labeled examples, e.g. for images acquired using different devices. We hereby propose a novel semi-supervised learning framework for segmentation of volumetric images from new unlabeled domains. We jointly use supervised and contrastive learning, also introducing a contrastive pairing scheme that leverages similarity between nearby slices in 3D. In addition, we propose channel-wise aggregation as an alternative to conventional spatial-pooling aggregation for contrastive feature map projection. We evaluate our methods for domain adaptation from a (labeled) source domain to an (unlabeled) target domain, each containing images acquired with different acquisition devices. In the target domain, our method achieves a Dice coefficient 13.8% higher than SimCLR (a state-of-the-art contrastive framework), and leads to results comparable to an upper bound with supervised training in that domain. In the source domain, our model also improves the results by 5.4% Dice, by successfully leveraging information from many unlabeled images.
Multi-Level Contrastive Learning for Cross-Lingual Alignment
Feb 26, 2022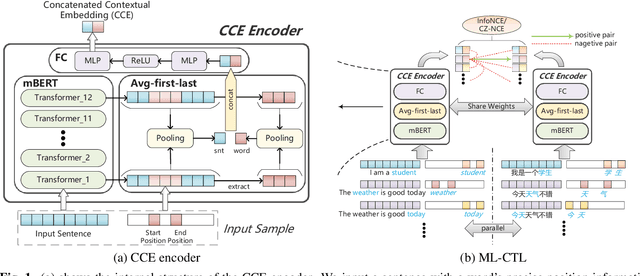
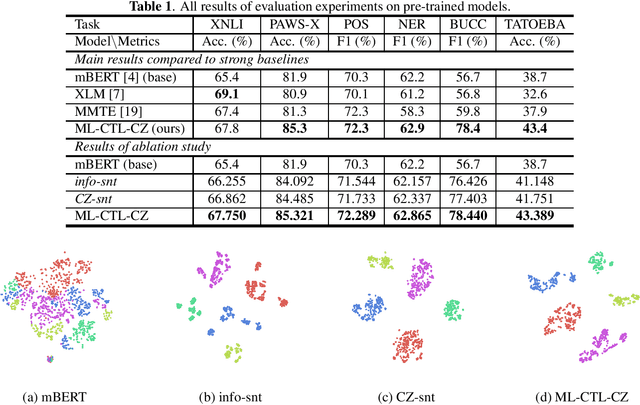
Cross-language pre-trained models such as multilingual BERT (mBERT) have achieved significant performance in various cross-lingual downstream NLP tasks. This paper proposes a multi-level contrastive learning (ML-CTL) framework to further improve the cross-lingual ability of pre-trained models. The proposed method uses translated parallel data to encourage the model to generate similar semantic embeddings for different languages. However, unlike the sentence-level alignment used in most previous studies, in this paper, we explicitly integrate the word-level information of each pair of parallel sentences into contrastive learning. Moreover, cross-zero noise contrastive estimation (CZ-NCE) loss is proposed to alleviate the impact of the floating-point error in the training process with a small batch size. The proposed method significantly improves the cross-lingual transfer ability of our basic model (mBERT) and outperforms on multiple zero-shot cross-lingual downstream tasks compared to the same-size models in the Xtreme benchmark.
Shift-Robust Node Classification via Graph Adversarial Clustering
Mar 07, 2022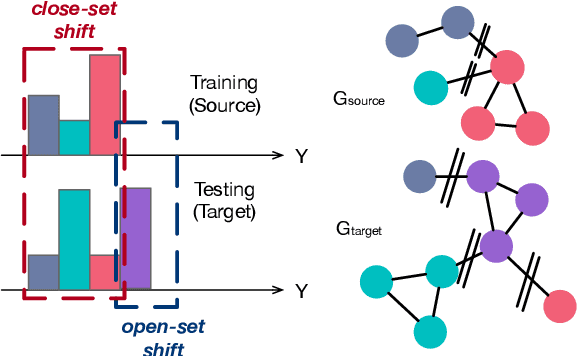
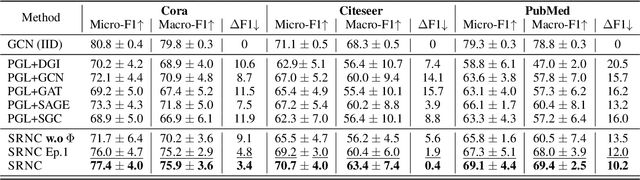
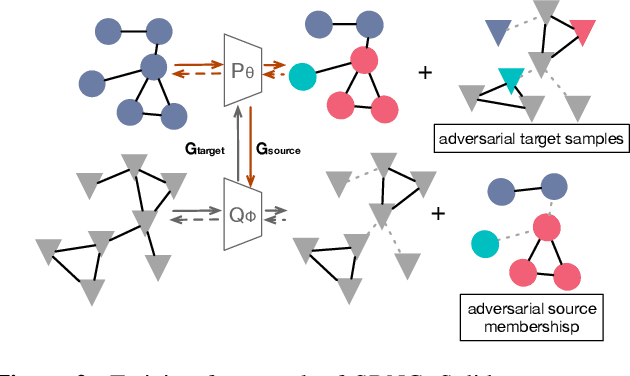
Graph Neural Networks (GNNs) are de facto node classification models in graph structured data. However, during testing-time, these algorithms assume no data shift, i.e., $\Pr_\text{train}(X,Y) = \Pr_\text{test}(X,Y)$. Domain adaption methods can be adopted for data shift, yet most of them are designed to only encourage similar feature distribution between source and target data. Conditional shift on classes can still affect such adaption. Fortunately, graph yields graph homophily across different data distributions. In response, we propose Shift-Robust Node Classification (SRNC) to address these limitations. We introduce an unsupervised cluster GNN on target graph to group the similar nodes by graph homophily. An adversarial loss with label information on source graph is used upon clustering objective. Then a shift-robust classifier is optimized on training graph and adversarial samples on target graph, which are generated by cluster GNN. We conduct experiments on both open-set shift and representation-shift, which demonstrates the superior accuracy of SRNC on generalizing to test graph with data shift. SRNC is consistently better than previous SoTA domain adaption algorithm on graph that progressively use model predictions on target graph for training.
Unlabeled Data Help: Minimax Analysis and Adversarial Robustness
Feb 14, 2022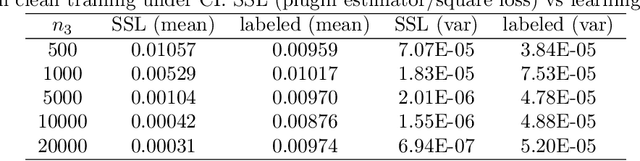
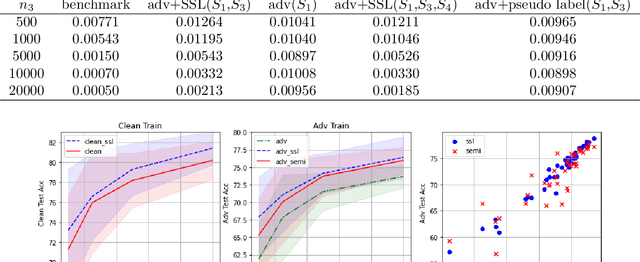

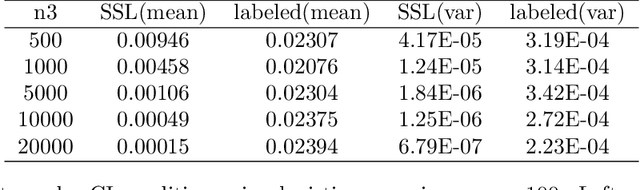
The recent proposed self-supervised learning (SSL) approaches successfully demonstrate the great potential of supplementing learning algorithms with additional unlabeled data. However, it is still unclear whether the existing SSL algorithms can fully utilize the information of both labelled and unlabeled data. This paper gives an affirmative answer for the reconstruction-based SSL algorithm \citep{lee2020predicting} under several statistical models. While existing literature only focuses on establishing the upper bound of the convergence rate, we provide a rigorous minimax analysis, and successfully justify the rate-optimality of the reconstruction-based SSL algorithm under different data generation models. Furthermore, we incorporate the reconstruction-based SSL into the existing adversarial training algorithms and show that learning from unlabeled data helps improve the robustness.
A Dynamic Mode Decomposition Approach for Decentralized Spectral Clustering of Graphs
Feb 26, 2022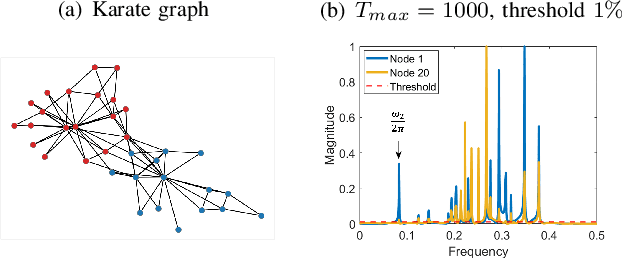
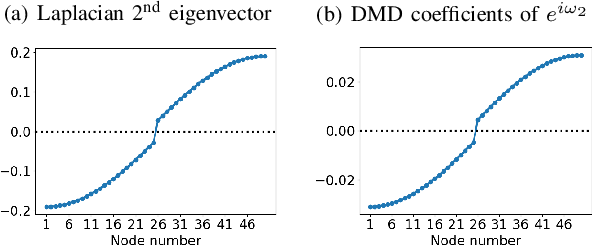
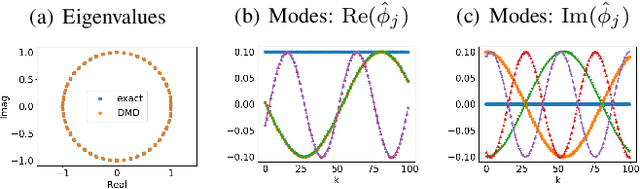
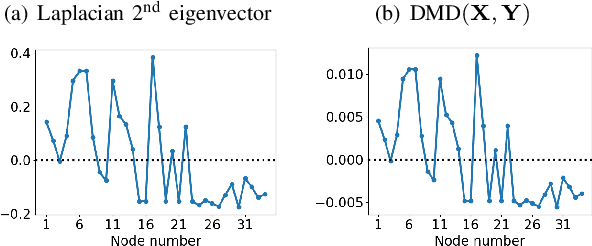
We propose a novel robust decentralized graph clustering algorithm that is provably equivalent to the popular spectral clustering approach. Our proposed method uses the existing wave equation clustering algorithm that is based on propagating waves through the graph. However, instead of using a fast Fourier transform (FFT) computation at every node, our proposed approach exploits the Koopman operator framework. Specifically, we show that propagating waves in the graph followed by a local dynamic mode decomposition (DMD) computation at every node is capable of retrieving the eigenvalues and the local eigenvector components of the graph Laplacian, thereby providing local cluster assignments for all nodes. We demonstrate that the DMD computation is more robust than the existing FFT based approach and requires 20 times fewer steps of the wave equation to accurately recover the clustering information and reduces the relative error by orders of magnitude. We demonstrate the decentralized approach on a range of graph clustering problems.
Integrating Temporal Information to Spatial Information in a Neural Circuit
Mar 01, 2019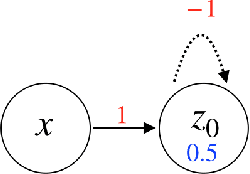
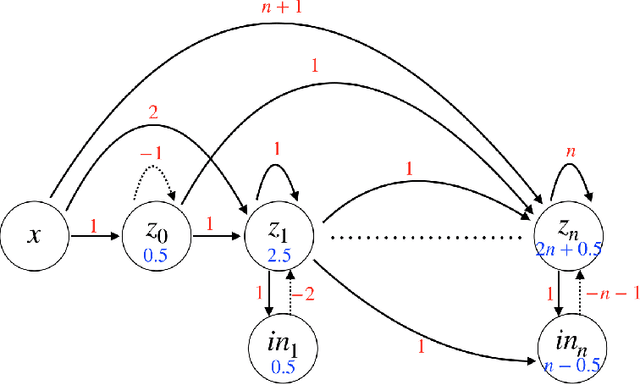
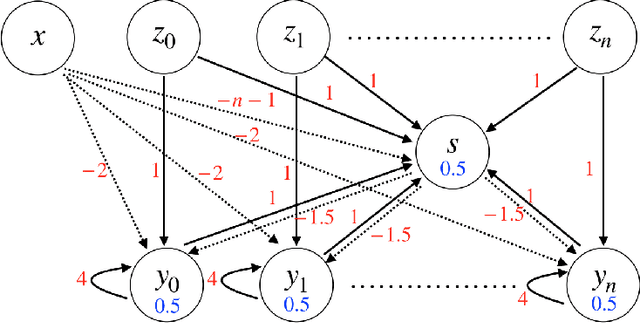
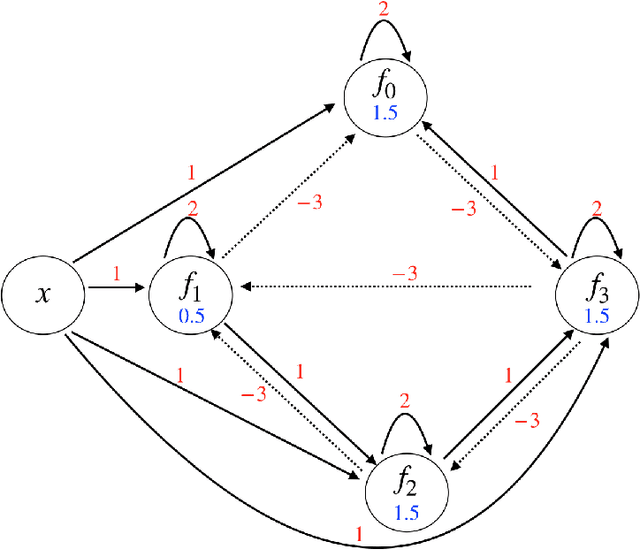
In this paper, we consider a network of spiking neurons with a deterministic synchronous firing rule at discrete time. We propose three problems -- "first consecutive spikes counting", "total spikes counting" and "$k$-spikes temporal to spatial encoding" -- to model how brains extract temporal information into spatial information from different neural codings. For a max input length $T$, we design three networks that solve these three problems with matching lower bounds in both time $O(T)$ and number of neurons $O(\log T)$ in all three questions.
Firefly: Supporting Drone Localization With Visible Light Communication
Dec 13, 2021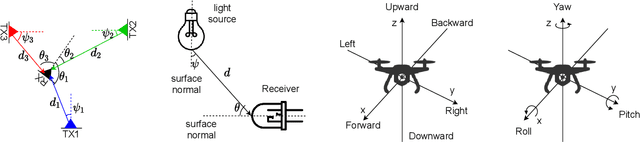

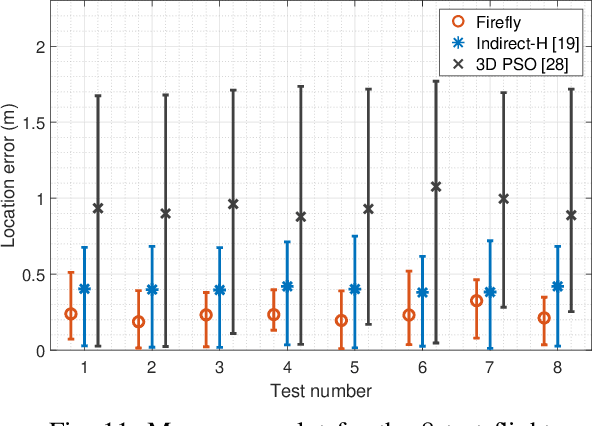
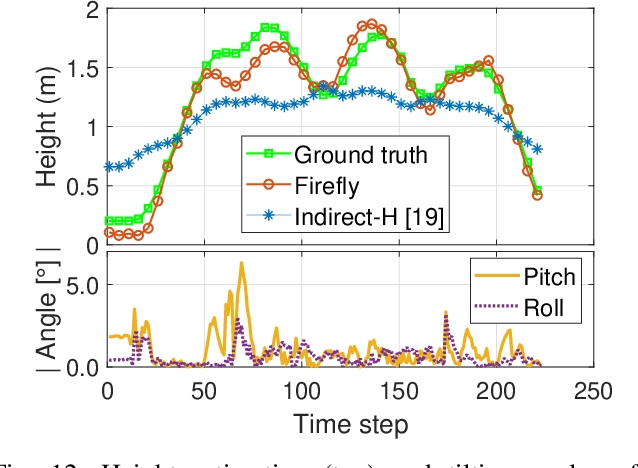
Drones are not fully trusted yet. Their reliance on radios and cameras for navigation raises safety and privacy concerns. These systems can fail, causing accidents, or be misused for unauthorized recordings. Considering recent regulations allowing commercial drones to operate only at night, we propose a radically new approach where drones obtain navigation information from artificial lighting. In our system, standard light bulbs modulate their intensity to send beacons and drones decode this information with a simple photodiode. This optical information is combined with the inertial and altitude sensors in the drones to provide localization without the need for radios, GPS or cameras. Our framework is the first to provide 3D drone localization with light and we evaluate it with a testbed consisting of four light beacons and a mini-drone. We show that, our approach allows to locate the drone within a few decimeters of the actual position and compared to state-of-the-art positioning methods, reduces the localization error by 42%.