 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
When Accuracy Meets Privacy: Two-Stage Federated Transfer Learning Framework in Classification of Medical Images on Limited Data: A COVID-19 Case Study
Mar 24, 2022
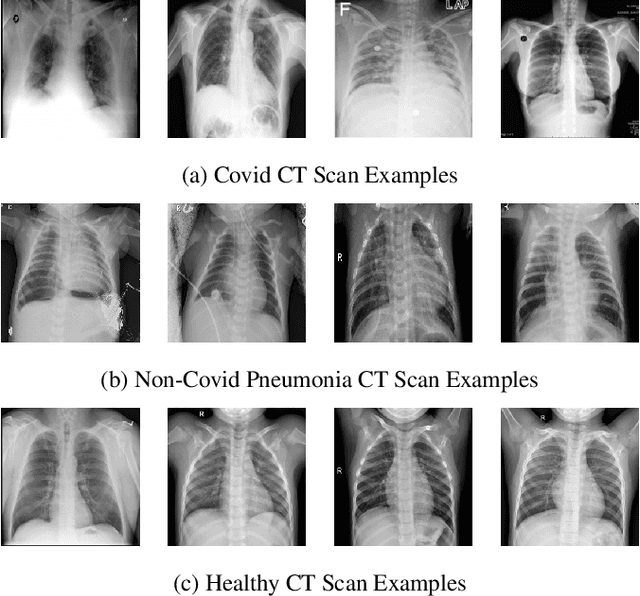
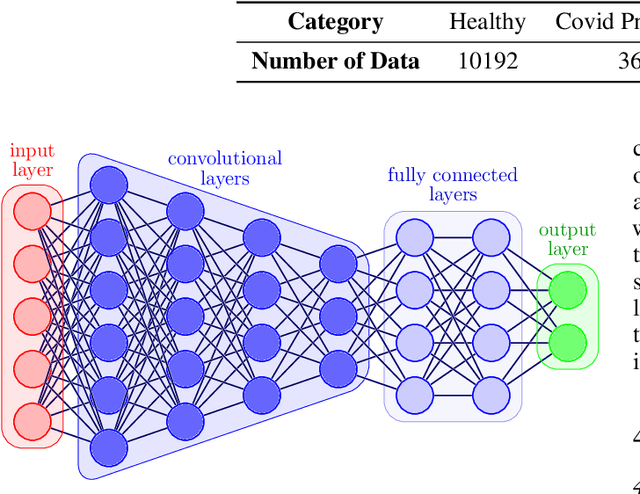
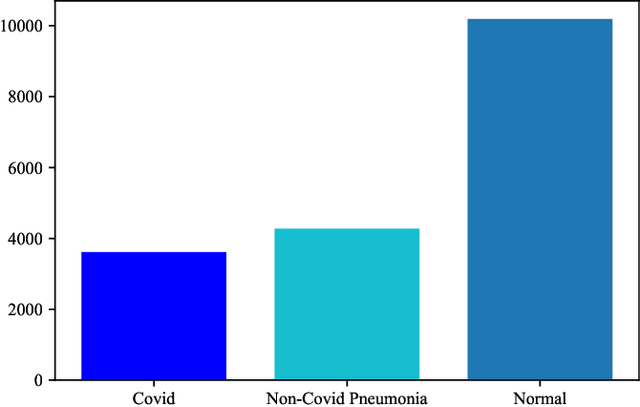

COVID-19 pandemic has spread rapidly and caused a shortage of global medical resources. The efficiency of COVID-19 diagnosis has become highly significant. As deep learning and convolutional neural network (CNN) has been widely utilized and been verified in analyzing medical images, it has become a powerful tool for computer-assisted diagnosis. However, there are two most significant challenges in medical image classification with the help of deep learning and neural networks, one of them is the difficulty of acquiring enough samples, which may lead to model overfitting. Privacy concerns mainly bring the other challenge since medical-related records are often deemed patients' private information and protected by laws such as GDPR and HIPPA. Federated learning can ensure the model training is decentralized on different devices and no data is shared among them, which guarantees privacy. However, with data located on different devices, the accessible data of each device could be limited. Since transfer learning has been verified in dealing with limited data with good performance, therefore, in this paper, We made a trial to implement federated learning and transfer learning techniques using CNNs to classify COVID-19 using lung CT scans. We also explored the impact of dataset distribution at the client-side in federated learning and the number of training epochs a model is trained. Finally, we obtained very high performance with federated learning, demonstrating our success in leveraging accuracy and privacy.
Signal Quality Assessment of Photoplethysmogram Signals using Quantum Pattern Recognition and lightweight CNN Architecture
Feb 01, 2022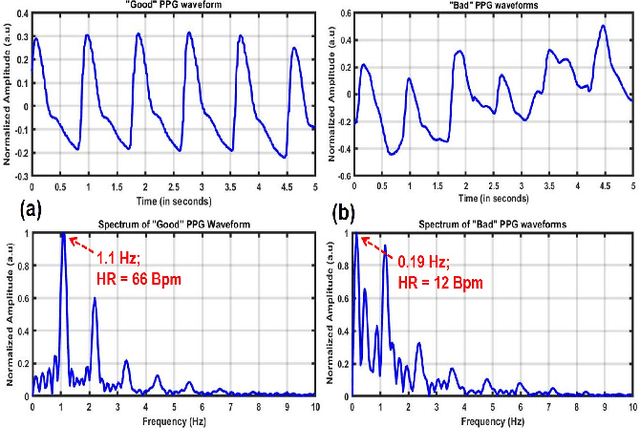
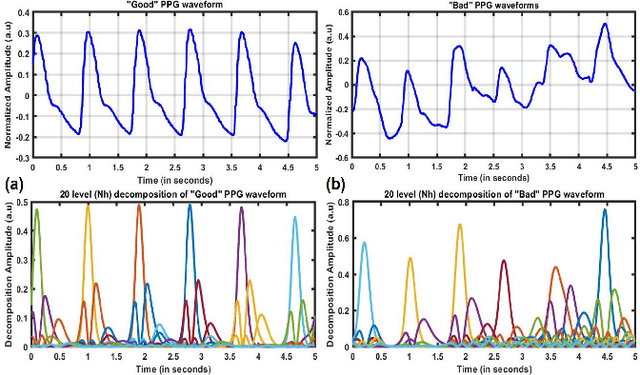
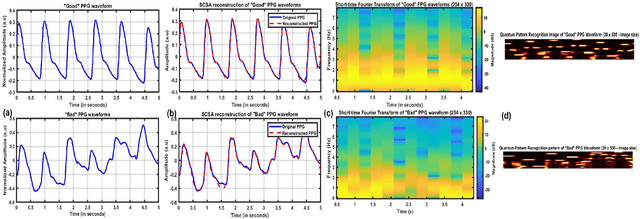
Photoplethysmography (PPG) signal comprises physiological information related to cardiorespiratory health. However, while recording, these PPG signals are easily corrupted by motion artifacts and body movements, leading to noise enriched, poor quality signals. Therefore ensuring high-quality signals is necessary to extract cardiorespiratory information accurately. Although there exists several rule-based and Machine-Learning (ML) - based approaches for PPG signal quality estimation, those algorithms' efficacy is questionable. Thus, this work proposes a lightweight CNN architecture for signal quality assessment employing a novel Quantum pattern recognition (QPR) technique. The proposed algorithm is validated on manually annotated data obtained from the University of Queensland database. A total of 28366, 5s signal segments are preprocessed and transformed into image files of 20 x 500 pixels. The image files are treated as an input to the 2D CNN architecture. The developed model classifies the PPG signal as `good' or `bad' with an accuracy of 98.3% with 99.3% sensitivity, 94.5% specificity and 98.9% F1-score. Finally, the performance of the proposed framework is validated against the noisy `Welltory app' collected PPG database. Even in a noisy environment, the proposed architecture proved its competence. Experimental analysis concludes that a slim architecture along with a novel Spatio-temporal pattern recognition technique improve the system's performance. Hence, the proposed approach can be useful to classify good and bad PPG signals for a resource-constrained wearable implementation.
Low-Complexity Beamforming Design for IRS-Aided NOMA Communication System with Imperfect CSI
Mar 16, 2022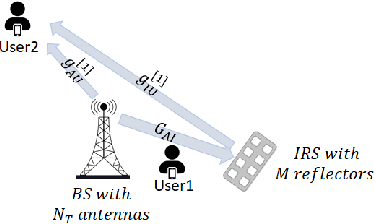
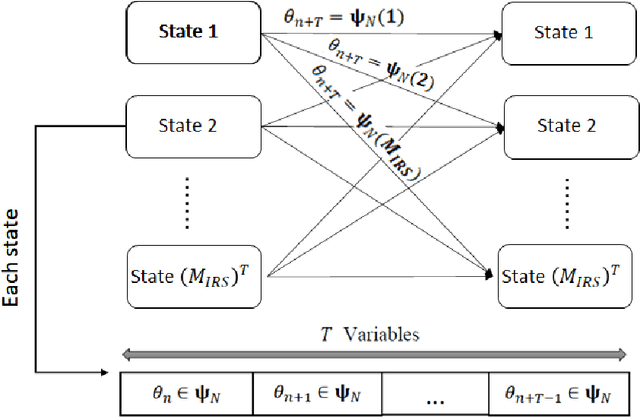
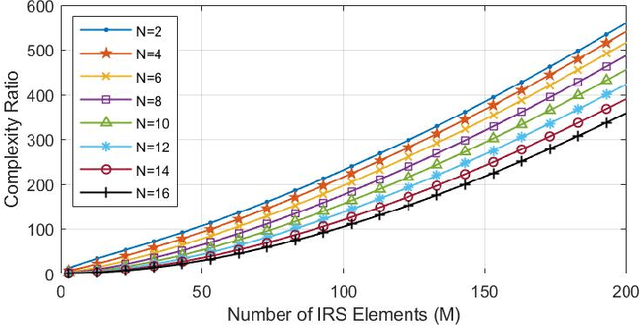
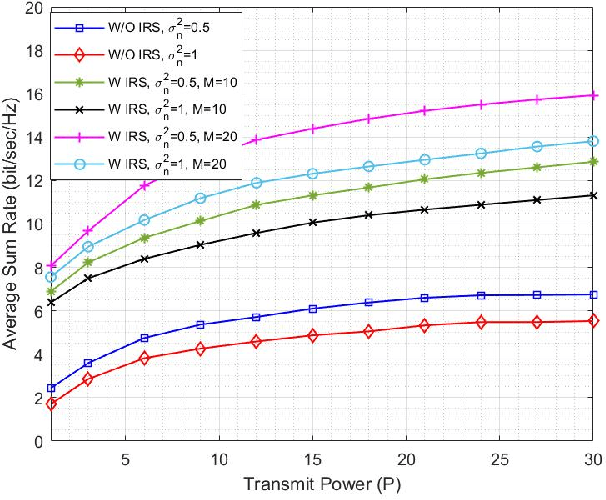
Intelligent reflecting surface (IRS) as a promising technology rendering high throughput in future communication systems is compatible with various communication techniques such as non-orthogonal multiple-access (NOMA). In this paper, the downlink transmission of IRS-assisted NOMA communication is considered while undergoing imperfect channel state information (CSI). Consequently, a robust IRS-aided NOMA design is proposed by solving the sum-rate maximization problem to jointly find the optimal beamforming vectors for the access point and the passive reflection matrix for the IRS, using the penalty dual decomposition (PDD) scheme. This problem can be solved through an iterative algorithm, with closed-form solutions in each step, and it is shown to have very close performance to its upper bound obtained from perfect CSI scenario. We also present a trellis-based method for optimal discrete phase shift selection of IRS which is shown to outperform the conventional quantization method. Our results show that the proposed algorithms, for both continuous and discrete IRS, have very low computational complexity compared to other schemes in the literature. Furthermore, we conduct a performance comparison from achievable sum-rate standpoint between IRS-aided NOMA and IRS-aided orthogonal multiple access (OMA), which demonstrates superiority of NOMA compared to OMA in case of a tolerated channel uncertainty.
Player of Games
Dec 06, 2021

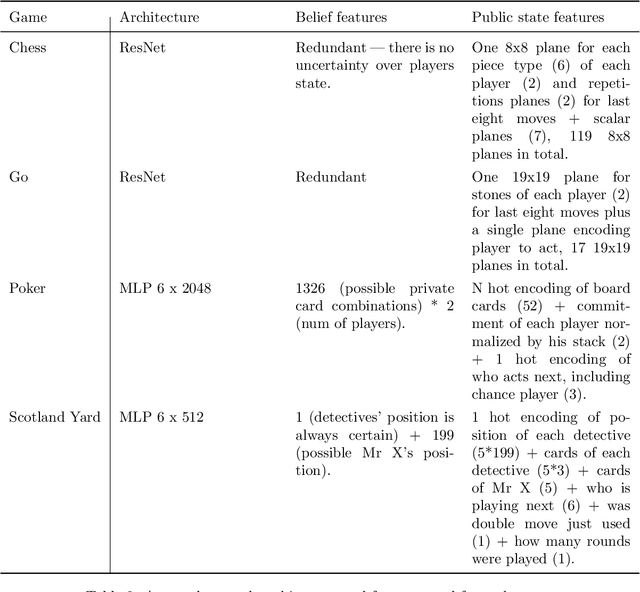
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Improving Disentangled Text Representation Learning with Information-Theoretic Guidance
Jun 06, 2020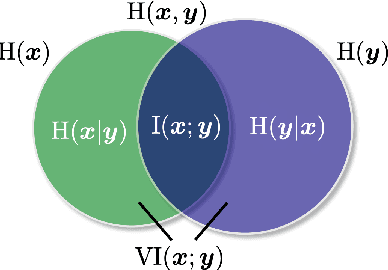
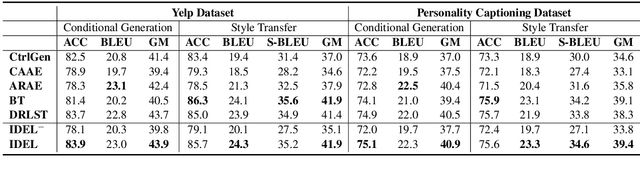
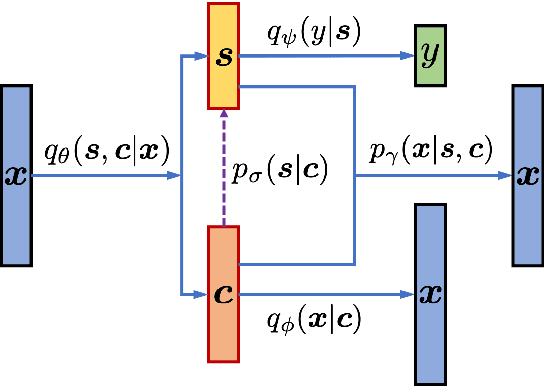
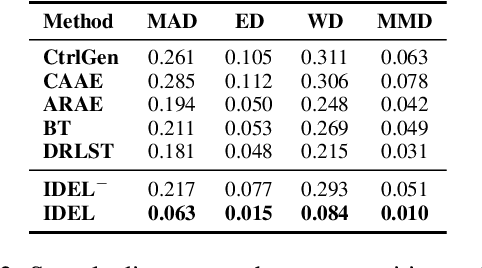
Learning disentangled representations of natural language is essential for many NLP tasks, e.g., conditional text generation, style transfer, personalized dialogue systems, etc. Similar problems have been studied extensively for other forms of data, such as images and videos. However, the discrete nature of natural language makes the disentangling of textual representations more challenging (e.g., the manipulation over the data space cannot be easily achieved). Inspired by information theory, we propose a novel method that effectively manifests disentangled representations of text, without any supervision on semantics. A new mutual information upper bound is derived and leveraged to measure dependence between style and content. By minimizing this upper bound, the proposed method induces style and content embeddings into two independent low-dimensional spaces. Experiments on both conditional text generation and text-style transfer demonstrate the high quality of our disentangled representation in terms of content and style preservation.
When did you become so smart, oh wise one?! Sarcasm Explanation in Multi-modal Multi-party Dialogues
Mar 12, 2022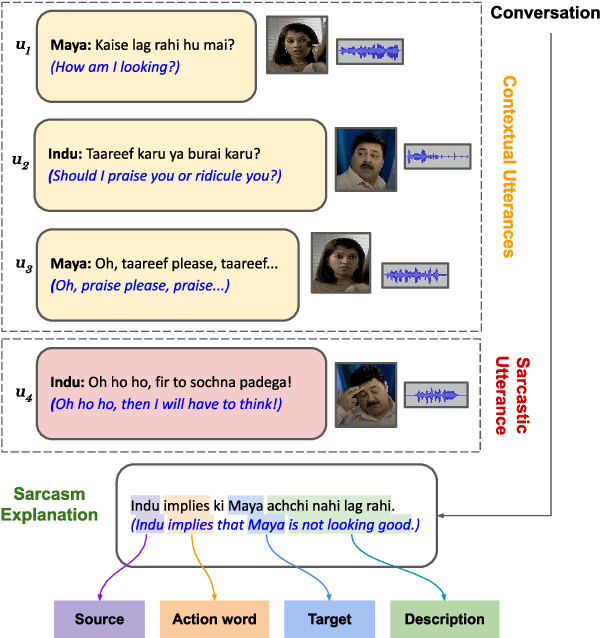
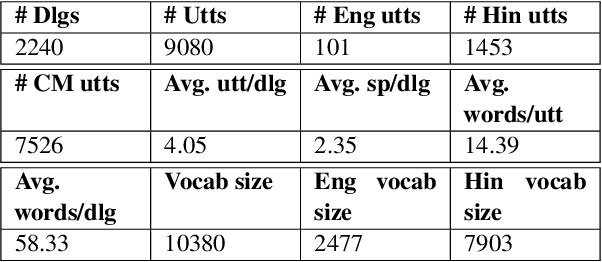
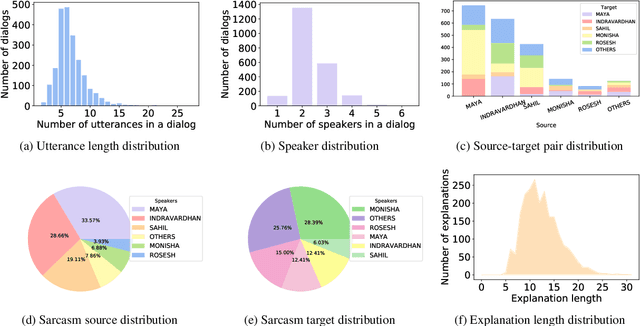
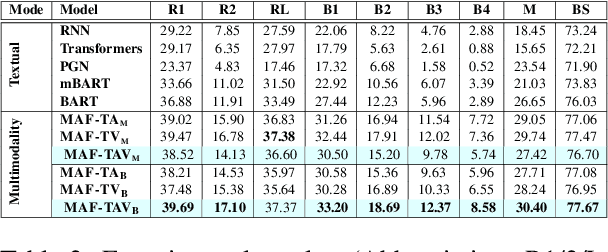
Indirect speech such as sarcasm achieves a constellation of discourse goals in human communication. While the indirectness of figurative language warrants speakers to achieve certain pragmatic goals, it is challenging for AI agents to comprehend such idiosyncrasies of human communication. Though sarcasm identification has been a well-explored topic in dialogue analysis, for conversational systems to truly grasp a conversation's innate meaning and generate appropriate responses, simply detecting sarcasm is not enough; it is vital to explain its underlying sarcastic connotation to capture its true essence. In this work, we study the discourse structure of sarcastic conversations and propose a novel task - Sarcasm Explanation in Dialogue (SED). Set in a multimodal and code-mixed setting, the task aims to generate natural language explanations of satirical conversations. To this end, we curate WITS, a new dataset to support our task. We propose MAF (Modality Aware Fusion), a multimodal context-aware attention and global information fusion module to capture multimodality and use it to benchmark WITS. The proposed attention module surpasses the traditional multimodal fusion baselines and reports the best performance on almost all metrics. Lastly, we carry out detailed analyses both quantitatively and qualitatively.
Multi-Modality Distillation via Learning the teacher's modality-level Gram Matrix
Dec 21, 2021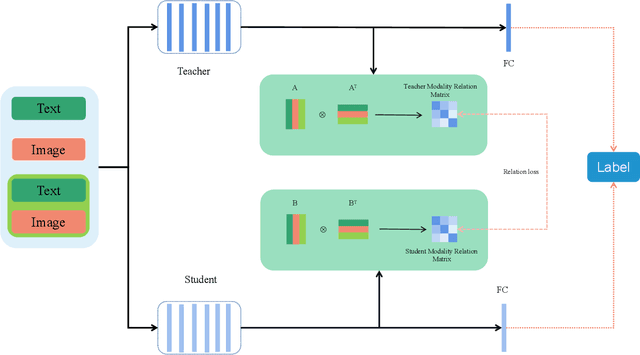
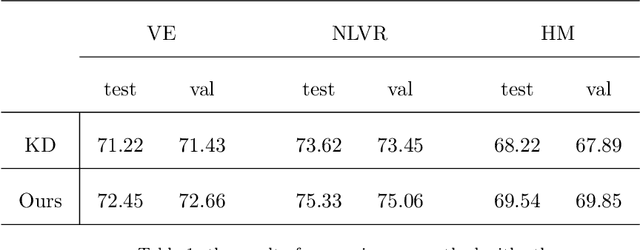
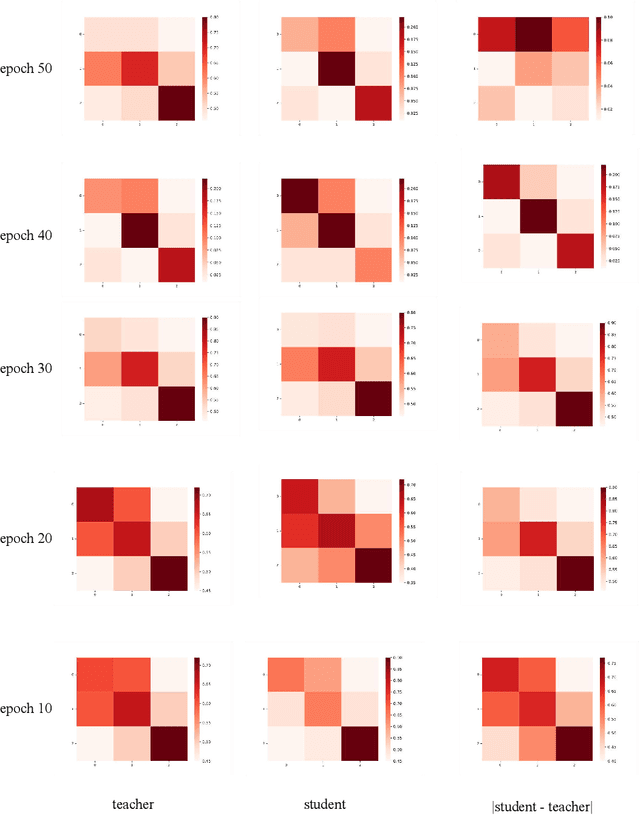
In the context of multi-modality knowledge distillation research, the existing methods was mainly focus on the problem of only learning teacher final output. Thus, there are still deep differences between the teacher network and the student network. It is necessary to force the student network to learn the modality relationship information of the teacher network. To effectively exploit transfering knowledge from teachers to students, a novel modality relation distillation paradigm by modeling the relationship information among different modality are adopted, that is learning the teacher modality-level Gram Matrix.
Using Statistical Models to Detect Occupancy in Buildings through Monitoring VOC, CO$_2$, and other Environmental Factors
Mar 07, 2022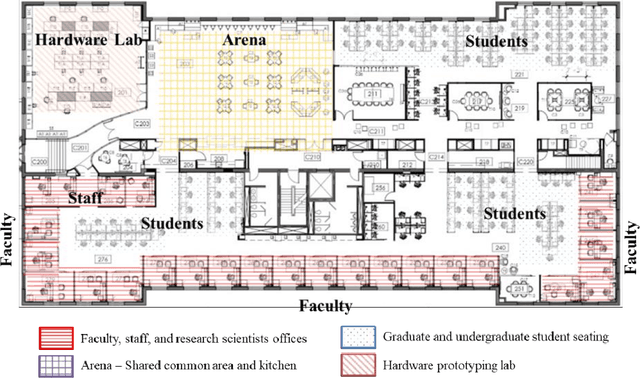
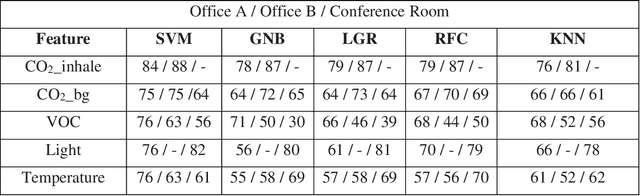
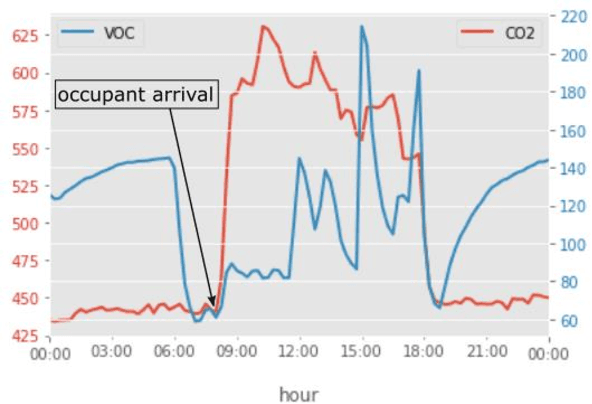
Dynamic models of occupancy patterns have shown to be effective in optimizing building-systems operations. Previous research has relied on CO$_2$ sensors and vision-based techniques to determine occupancy patterns. Vision-based techniques provide highly accurate information; however, they are very intrusive. Therefore, motion or CO$_2$ sensors are more widely adopted worldwide. Volatile Organic Compounds (VOCs) are another pollutant originating from the occupants. However, a limited number of studies have evaluated the impact of occupants on the VOC level. In this paper, continuous measurements of CO$_2$, VOC, light, temperature, and humidity were recorded in a 17,000 sqft open office space for around four months. Using different statistical models (e.g., SVM, K-Nearest Neighbors, and Random Forest) we evaluated which combination of environmental factors provides more accurate insights on occupant presence. Our preliminary results indicate that VOC is a good indicator of occupancy detection in some cases. It is also concluded that proper feature selection and developing appropriate global occupancy detection models can reduce the cost and energy of data collection without a significant impact on accuracy.
Knowledge Extraction in Low-Resource Scenarios: Survey and Perspective
Feb 16, 2022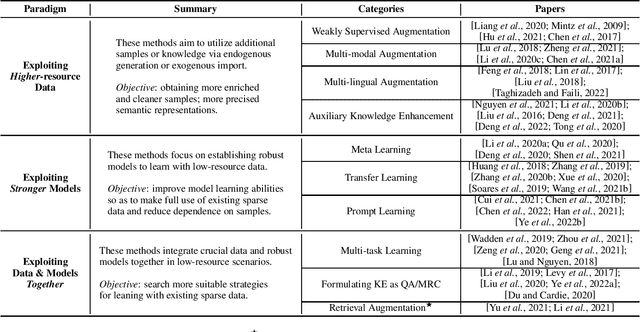
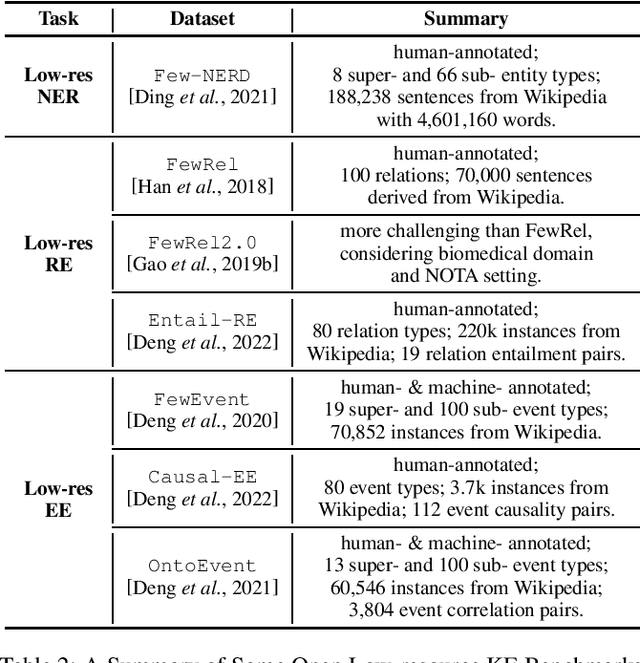
Knowledge Extraction (KE) which aims to extract structural information from unstructured texts often suffers from data scarcity and emerging unseen types, i.e., low-resource scenarios. Many neural approaches on low-resource KE have been widely investigated and achieved impressive performance. In this paper, we present a literature review towards KE in low-resource scenarios, and systematically categorize existing works into three paradigms: (1) exploiting higher-resource data, (2) exploiting stronger models, and (3) exploiting data and models together. In addition, we describe promising applications and outline some potential directions for future research. We hope that our survey can help both the academic and industrial community to better understand this field, inspire more ideas and boost broader applications.
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observations
Dec 08, 2021
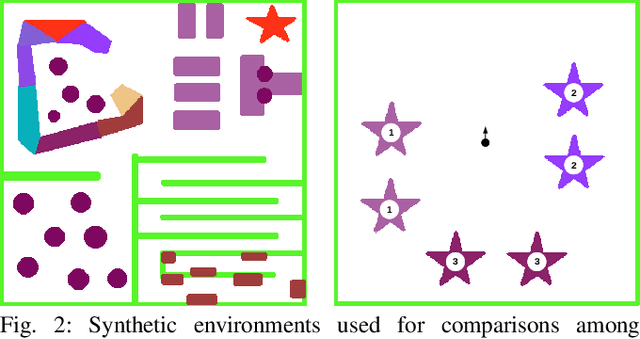
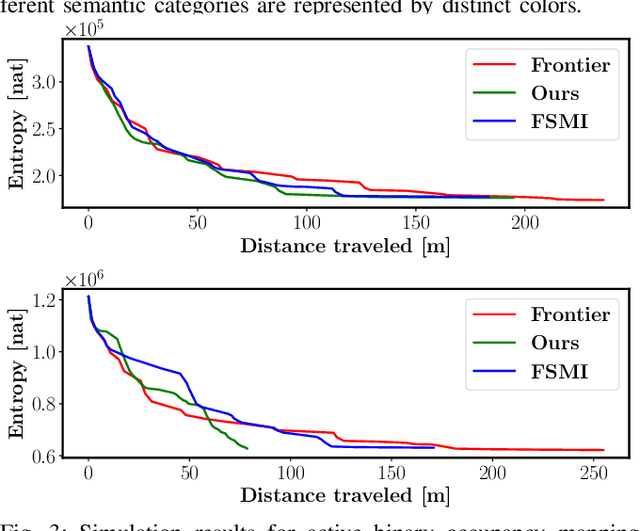
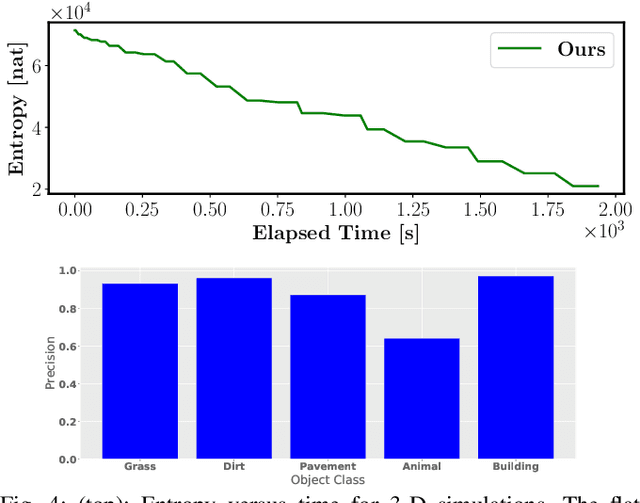
The demand for robot exploration in unstructured and unknown environments has recently grown substantially thanks to the host of inexpensive sensing and edge-computing solutions. In order to come closer to full autonomy, robots need to process the measurement stream in real-time, which calls for efficient exploration strategies. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. In this work we propose a Bayesian multi-class mapping algorithm utilizing range-category measurements, as well as a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. Furthermore, we develop a compressed representation of 3-D environments with semantic labels based on OcTree data structure, where each voxel maintains a categorical distribution over object classes. The proposed 3-D representation facilitates fast computation of Shannon mutual information between the semantic Octomap and the measurements using Run-Length Encoding (RLE) of range-category observation rays. We compare our method against frontier-based and FSMI exploration and apply it in a variety of simulated and real-world experiments.