 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BayGo: Joint Bayesian Learning and Information-Aware Graph Optimization
Nov 09, 2020
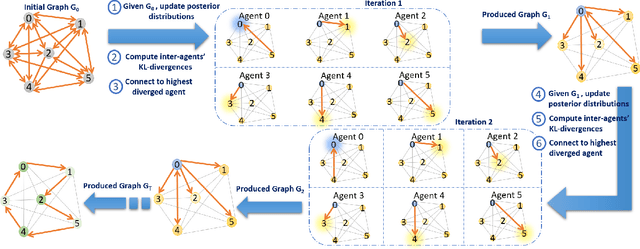
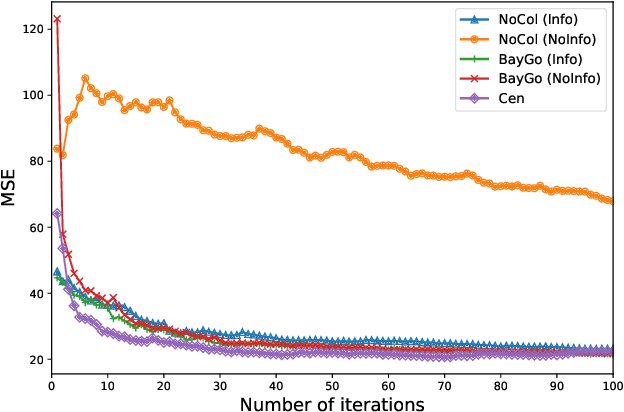
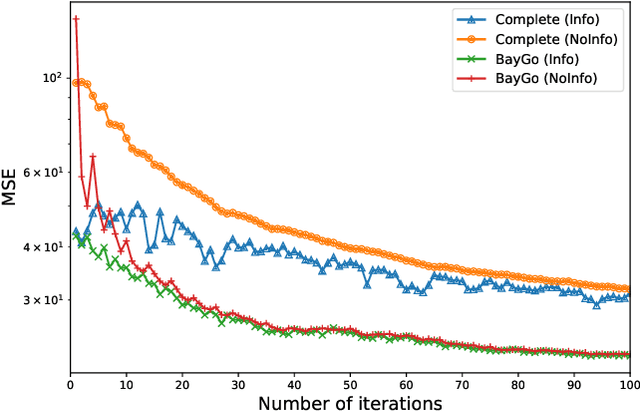
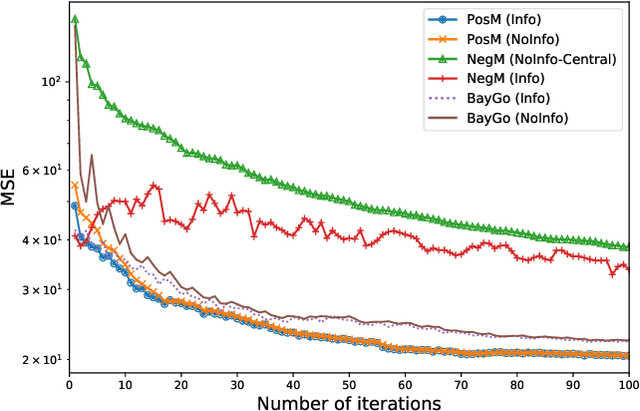
This article deals with the problem of distributed machine learning, in which agents update their models based on their local datasets, and aggregate the updated models collaboratively and in a fully decentralized manner. In this paper, we tackle the problem of information heterogeneity arising in multi-agent networks where the placement of informative agents plays a crucial role in the learning dynamics. Specifically, we propose BayGo, a novel fully decentralized joint Bayesian learning and graph optimization framework with proven fast convergence over a sparse graph. Under our framework, agents are able to learn and communicate with the most informative agent to their own learning. Unlike prior works, our framework assumes no prior knowledge of the data distribution across agents nor does it assume any knowledge of the true parameter of the system. The proposed alternating minimization based framework ensures global connectivity in a fully decentralized way while minimizing the number of communication links. We theoretically show that by optimizing the proposed objective function, the estimation error of the posterior probability distribution decreases exponentially at each iteration. Via extensive simulations, we show that our framework achieves faster convergence and higher accuracy compared to fully-connected and star topology graphs.
Towards Micro-video Thumbnail Selection via a Multi-label Visual-semantic Embedding Model
Feb 07, 2022The thumbnail, as the first sight of a micro-video, plays a pivotal role in attracting users to click and watch. While in the real scenario, the more the thumbnails satisfy the users, the more likely the micro-videos will be clicked. In this paper, we aim to select the thumbnail of a given micro-video that meets most users` interests. Towards this end, we present a multi-label visual-semantic embedding model to estimate the similarity between the pair of each frame and the popular topics that users are interested in. In this model, the visual and textual information is embedded into a shared semantic space, whereby the similarity can be measured directly, even the unseen words. Moreover, to compare the frame to all words from the popular topics, we devise an attention embedding space associated with the semantic-attention projection. With the help of these two embedding spaces, the popularity score of a frame, which is defined by the sum of similarity scores over the corresponding visual information and popular topic pairs, is achieved. Ultimately, we fuse the visual representation score and the popularity score of each frame to select the attractive thumbnail for the given micro-video. Extensive experiments conducted on a real-world dataset have well-verified that our model significantly outperforms several state-of-the-art baselines.
RestoreFormer: High-Quality Blind Face Restoration From Undegraded Key-Value Pairs
Jan 17, 2022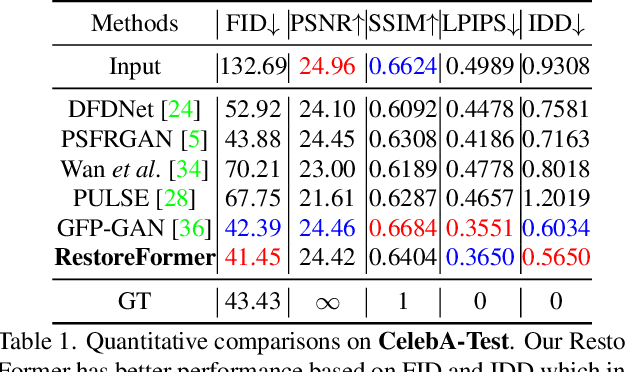
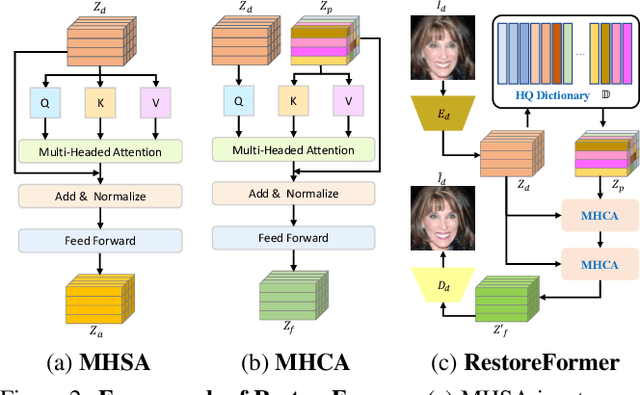
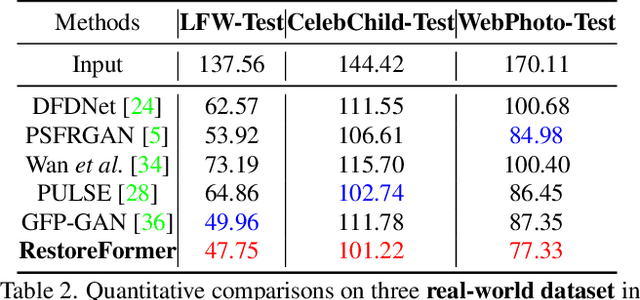
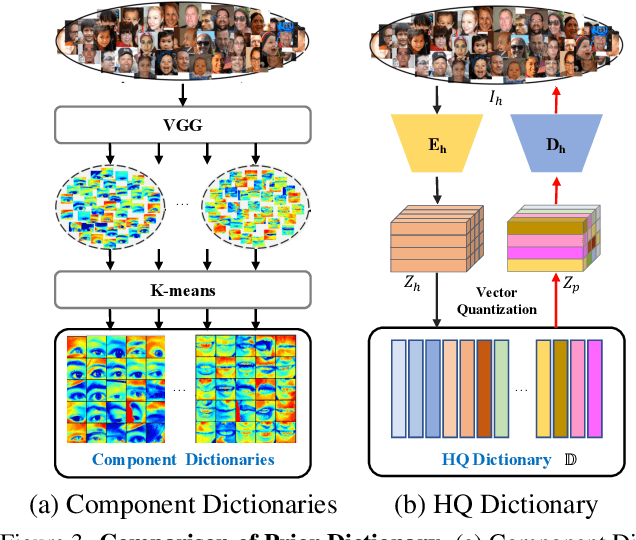
Blind face restoration is to recover a high-quality face image from unknown degradations. As face image contains abundant contextual information, we propose a method, RestoreFormer, which explores fully-spatial attentions to model contextual information and surpasses existing works that use local operators. RestoreFormer has several benefits compared to prior arts. First, unlike the conventional multi-head self-attention in previous Vision Transformers (ViTs), RestoreFormer incorporates a multi-head cross-attention layer to learn fully-spatial interactions between corrupted queries and high-quality key-value pairs. Second, the key-value pairs in ResotreFormer are sampled from a reconstruction-oriented high-quality dictionary, whose elements are rich in high-quality facial features specifically aimed for face reconstruction, leading to superior restoration results. Third, RestoreFormer outperforms advanced state-of-the-art methods on one synthetic dataset and three real-world datasets, as well as produces images with better visual quality.
Towards Group Robustness in the presence of Partial Group Labels
Jan 10, 2022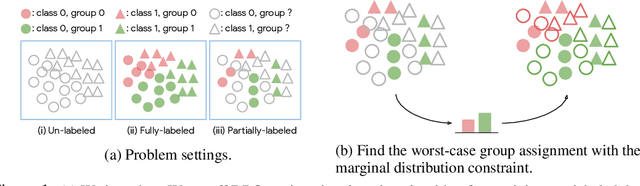

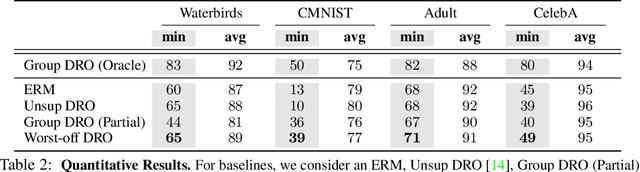
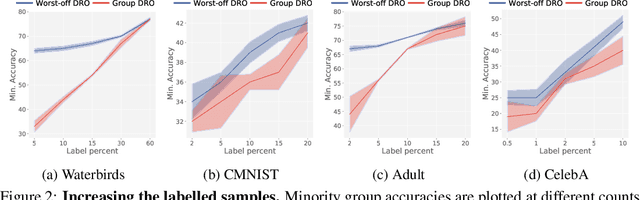
Learning invariant representations is an important requirement when training machine learning models that are driven by spurious correlations in the datasets. These spurious correlations, between input samples and the target labels, wrongly direct the neural network predictions resulting in poor performance on certain groups, especially the minority groups. Robust training against these spurious correlations requires the knowledge of group membership for every sample. Such a requirement is impractical in situations where the data labeling efforts for minority or rare groups are significantly laborious or where the individuals comprising the dataset choose to conceal sensitive information. On the other hand, the presence of such data collection efforts results in datasets that contain partially labeled group information. Recent works have tackled the fully unsupervised scenario where no labels for groups are available. Thus, we aim to fill the missing gap in the literature by tackling a more realistic setting that can leverage partially available sensitive or group information during training. First, we construct a constraint set and derive a high probability bound for the group assignment to belong to the set. Second, we propose an algorithm that optimizes for the worst-off group assignments from the constraint set. Through experiments on image and tabular datasets, we show improvements in the minority group's performance while preserving overall aggregate accuracy across groups.
Improving Adversarial Transferability with Spatial Momentum
Mar 25, 2022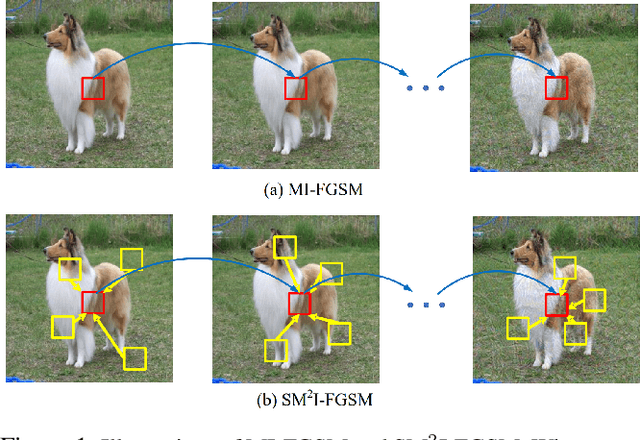
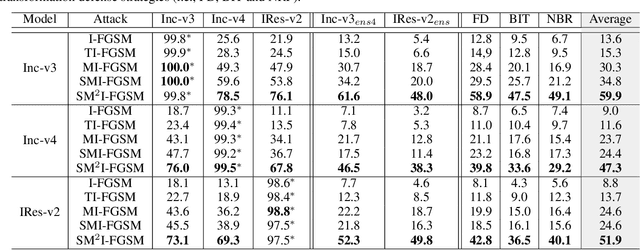
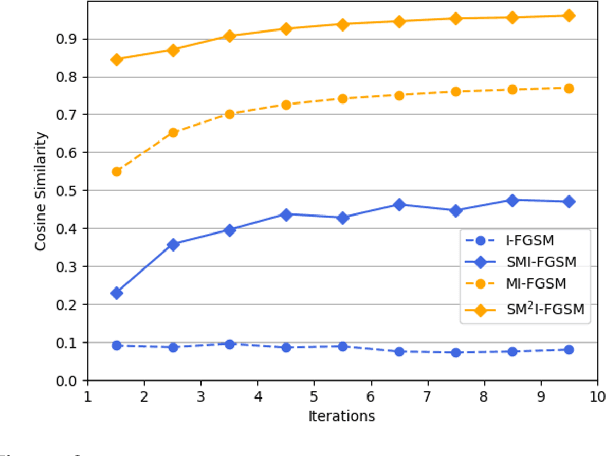
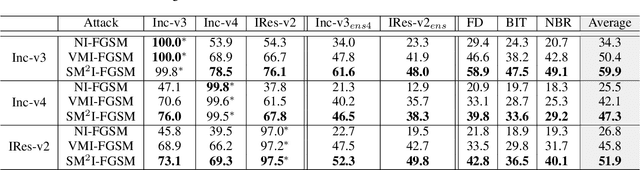
Deep Neural Networks (DNN) are vulnerable to adversarial examples. Although many adversarial attack methods achieve satisfactory attack success rates under the white-box setting, they usually show poor transferability when attacking other DNN models. Momentum-based attack (MI-FGSM) is one effective method to improve transferability. It integrates the momentum term into the iterative process, which can stabilize the update directions by adding the gradients' temporal correlation for each pixel. We argue that only this temporal momentum is not enough, the gradients from the spatial domain within an image, i.e. gradients from the context pixels centered on the target pixel are also important to the stabilization. For that, in this paper, we propose a novel method named Spatial Momentum Iterative FGSM Attack (SMI-FGSM), which introduces the mechanism of momentum accumulation from temporal domain to spatial domain by considering the context gradient information from different regions within the image. SMI-FGSM is then integrated with MI-FGSM to simultaneously stabilize the gradients' update direction from both the temporal and spatial domain. The final method is called SM$^2$I-FGSM. Extensive experiments are conducted on the ImageNet dataset and results show that SM$^2$I-FGSM indeed further enhances the transferability. It achieves the best transferability success rate for multiple mainstream undefended and defended models, which outperforms the state-of-the-art methods by a large margin.
An End-to-End Approach for Seam Carving Detection using Deep Neural Networks
Mar 05, 2022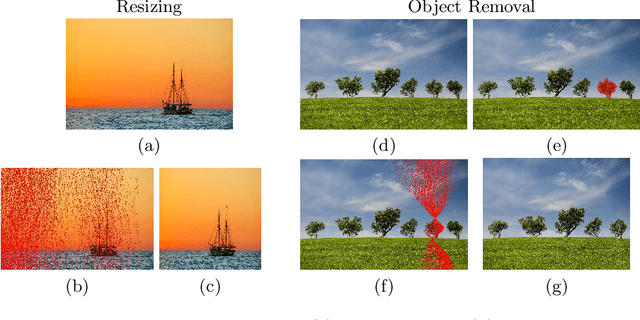
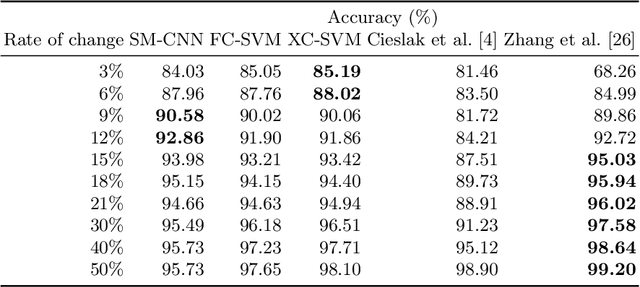
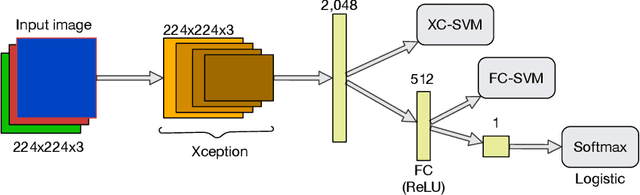
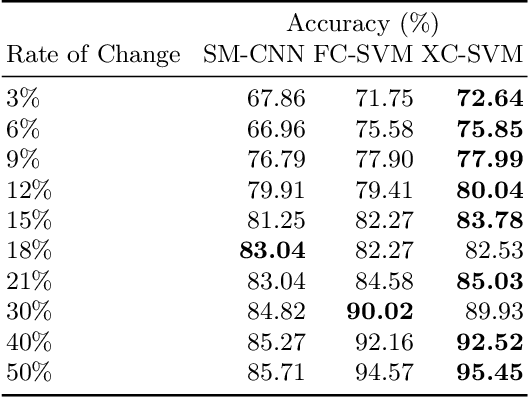
Seam carving is a computational method capable of resizing images for both reduction and expansion based on its content, instead of the image geometry. Although the technique is mostly employed to deal with redundant information, i.e., regions composed of pixels with similar intensity, it can also be used for tampering images by inserting or removing relevant objects. Therefore, detecting such a process is of extreme importance regarding the image security domain. However, recognizing seam-carved images does not represent a straightforward task even for human eyes, and robust computation tools capable of identifying such alterations are very desirable. In this paper, we propose an end-to-end approach to cope with the problem of automatic seam carving detection that can obtain state-of-the-art results. Experiments conducted over public and private datasets with several tampering configurations evidence the suitability of the proposed model.
Multilingual Detection of Personal Employment Status on Twitter
Mar 17, 2022
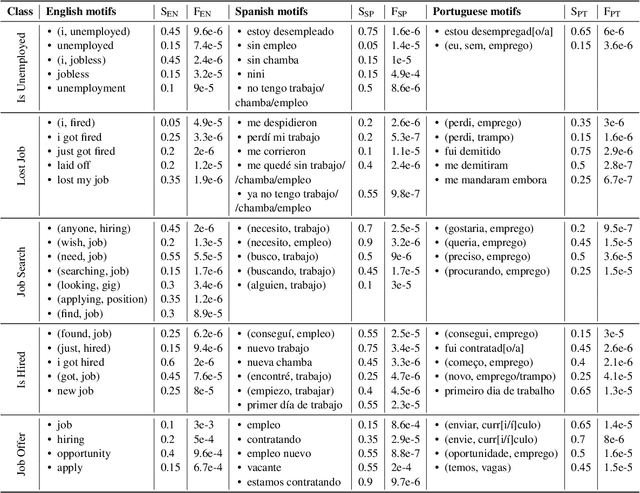
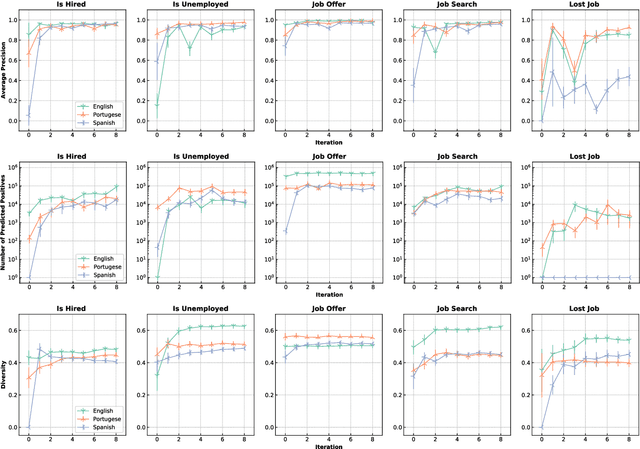

Detecting disclosures of individuals' employment status on social media can provide valuable information to match job seekers with suitable vacancies, offer social protection, or measure labor market flows. However, identifying such personal disclosures is a challenging task due to their rarity in a sea of social media content and the variety of linguistic forms used to describe them. Here, we examine three Active Learning (AL) strategies in real-world settings of extreme class imbalance, and identify five types of disclosures about individuals' employment status (e.g. job loss) in three languages using BERT-based classification models. Our findings show that, even under extreme imbalance settings, a small number of AL iterations is sufficient to obtain large and significant gains in precision, recall, and diversity of results compared to a supervised baseline with the same number of labels. We also find that no AL strategy consistently outperforms the rest. Qualitative analysis suggests that AL helps focus the attention mechanism of BERT on core terms and adjust the boundaries of semantic expansion, highlighting the importance of interpretable models to provide greater control and visibility into this dynamic learning process.
ECMG: Exemplar-based Commit Message Generation
Mar 05, 2022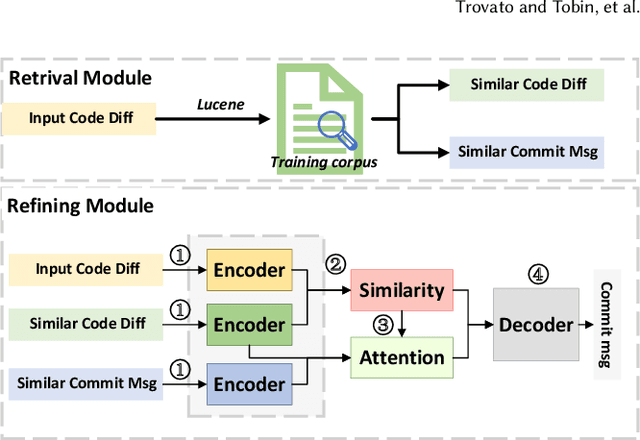

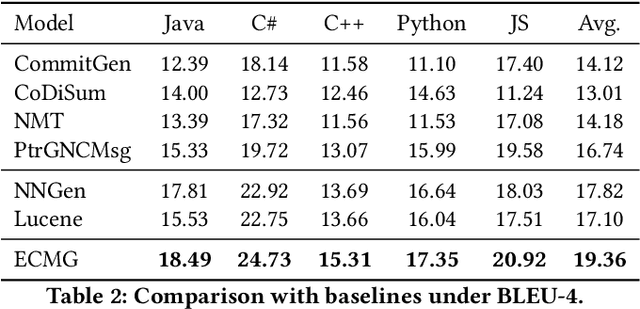
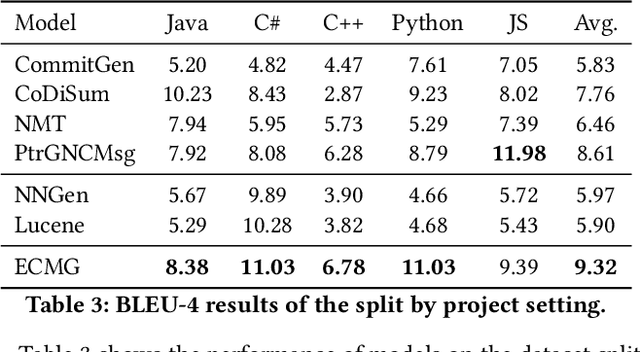
Commit messages concisely describe the content of code diffs (i.e., code changes) and the intent behind them. Recently, many approaches have been proposed to generate commit messages automatically. The information retrieval-based methods reuse the commit messages of similar code diffs, while the neural-based methods learn the semantic connection between code diffs and commit messages. However, the reused commit messages might not accurately describe the content/intent of code diffs and neural-based methods tend to generate high-frequent and repetitive tokens in the corpus. In this paper, we combine the advantages of the two technical routes and propose a novel exemplar-based neural commit message generation model, which treats the similar commit message as an exemplar and leverages it to guide the neural network model to generate an accurate commit message. We perform extensive experiments and the results confirm the effectiveness of our model.
An Unsupervised Sentence Embedding Method byMutual Information Maximization
Sep 25, 2020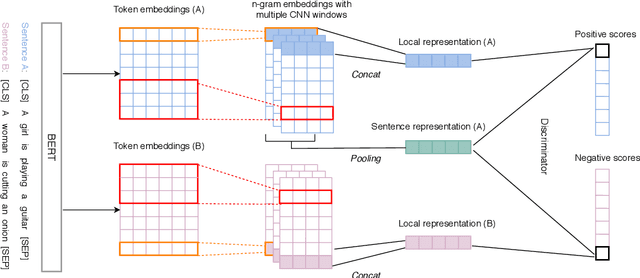
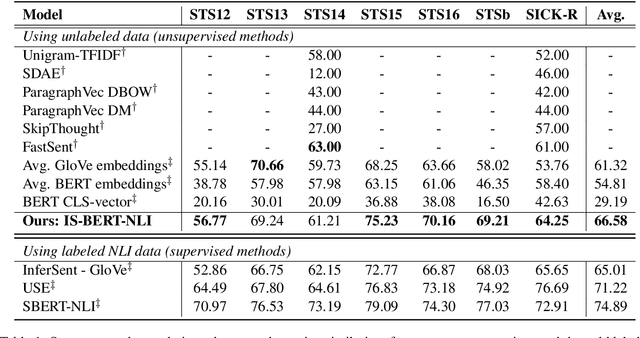
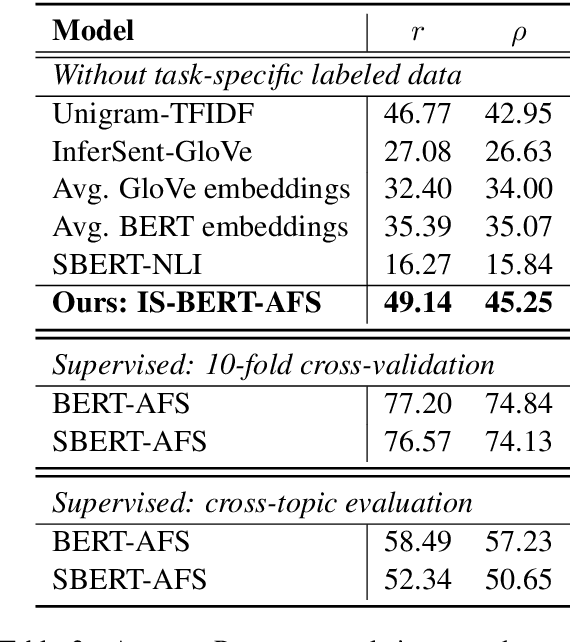
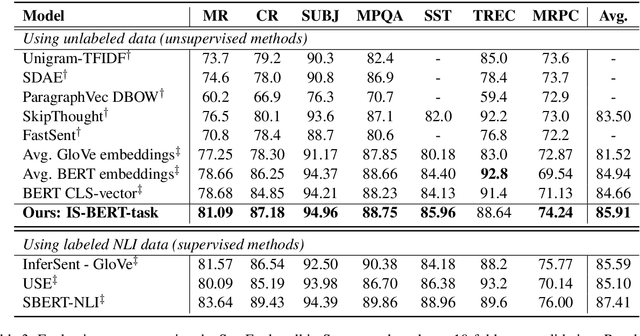
BERT is inefficient for sentence-pair tasks such as clustering or semantic search as it needs to evaluate combinatorially many sentence pairs which is very time-consuming. Sentence BERT (SBERT) attempted to solve this challenge by learning semantically meaningful representations of single sentences, such that similarity comparison can be easily accessed. However, SBERT is trained on corpus with high-quality labeled sentence pairs, which limits its application to tasks where labeled data is extremely scarce. In this paper, we propose a lightweight extension on top of BERT and a novel self-supervised learning objective based on mutual information maximization strategies to derive meaningful sentence embeddings in an unsupervised manner. Unlike SBERT, our method is not restricted by the availability of labeled data, such that it can be applied on different domain-specific corpus. Experimental results show that the proposed method significantly outperforms other unsupervised sentence embedding baselines on common semantic textual similarity (STS) tasks and downstream supervised tasks. It also outperforms SBERT in a setting where in-domain labeled data is not available, and achieves performance competitive with supervised methods on various tasks.
ros2_tracing: Multipurpose Low-Overhead Framework for Real-Time Tracing of ROS 2
Jan 02, 2022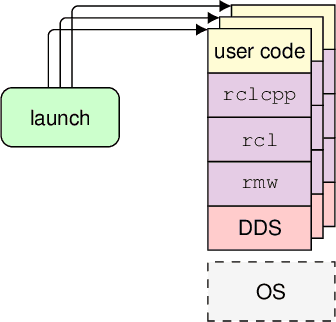
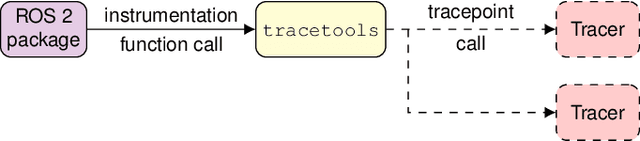
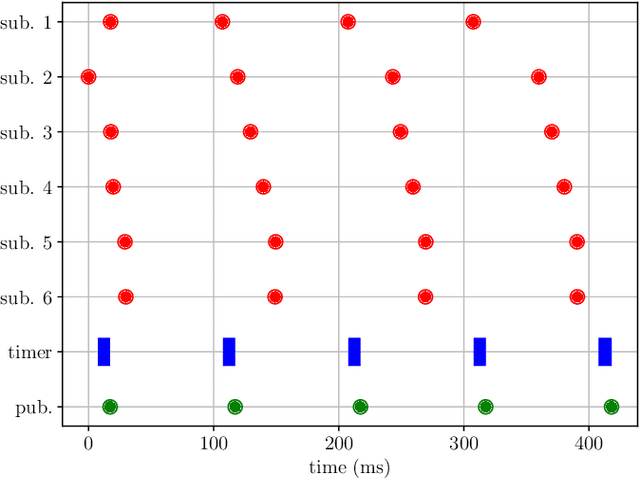
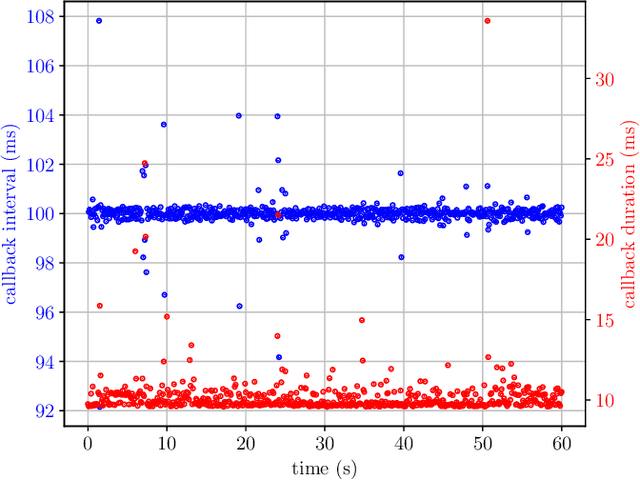
Testing and debugging have become major obstacles for robot software development, because of high system complexity and dynamic environments. Standard, middleware-based data recording does not provide sufficient information on internal computation and performance bottlenecks. Other existing methods also target very specific problems and thus cannot be used for multipurpose analysis. Moreover, they are not suitable for real-time applications. In this paper, we present ros2_tracing, a collection of flexible tracing tools and multipurpose instrumentation for ROS 2. It allows collecting runtime execution information on real-time distributed systems, using the low-overhead LTTng tracer. Tools also integrate tracing into the invaluable ROS 2 orchestration system and other usability tools. A message latency experiment shows that the end-to-end message latency overhead, when enabling all ROS 2 instrumentation, is below 0.0055 ms, which we believe is suitable for production real-time systems. ROS 2 execution information obtained using ros2_tracing can be combined with trace data from the operating system, enabling a wider range of precise analyses, that help understand an application execution, to find the cause of performance bottlenecks and other issues. The source code is available at: https://gitlab.com/ros-tracing/ros2_tracing.