 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBye Bye Perspective API: Lessons for Measurement Infrastructure in NLP, CSS and LLM Evaluation
Apr 28, 2026The closure of Perspective API at the end of 2026 discards what has functioned as the de facto standard for automated toxicity measurement in NLP, CSS, and LLM evaluation research. We document the structural dependence that the communities built on this single proprietary tool and discuss how this dependence caused epistemic problems that have affected - and will likely continue to affect - collective research efforts. Perspective's model was periodically updated without versioning or disclosure, its annotation structure reflected a single corporate operationalisation of a contested concept, and its scores were used simultaneously as an evaluation target and an evaluation standard. Its closure leaves behind non-updatable benchmarks, irreproducible results, and ultimately a field at risk of perpetuating these issues by turning to closed-source LLMs. We use Perspective's announced termination as an opportunity to call for an independent, valid, adaptable, and reproducible toxicity and hate speech measurement infrastructure, with the technical and governance requirements outlined in this paper.
The Enforcement and Feasibility of Hate Speech Moderation on Twitter
Apr 14, 2026Online hate speech is associated with substantial social harms, yet it remains unclear how consistently platforms enforce hate speech policies or whether enforcement is feasible at scale. We address these questions through a global audit of hate speech moderation on Twitter (now X). Using a complete 24-hour snapshot of public tweets, we construct representative samples comprising 540,000 tweets annotated for hate speech by trained annotators across eight major languages. Five months after posting, 80% of hateful tweets remain online, including explicitly violent hate speech. Such tweets are no more likely to be removed than non-hateful tweets, with neither severity nor visibility increasing the likelihood of removal. We then examine whether these enforcement gaps reflect technical limits of large-scale moderation systems. While fully automated detection systems cannot reliably identify hate speech without generating large numbers of false positives, they effectively prioritize likely violations for human review. Simulations of a human-AI moderation pipeline indicate that substantially reducing user exposure to hate speech is economically feasible at a cost below existing regulatory penalties. These results suggest that the persistence of online hate cannot be explained by technical constraints alone but also reflects institutional choices in the allocation of moderation resources.
Demographic Probing of Large Language Models Lacks Construct Validity
Jan 26, 2026Demographic probing is widely used to study how large language models (LLMs) adapt their behavior to signaled demographic attributes. This approach typically uses a single demographic cue in isolation (e.g., a name or dialect) as a signal for group membership, implicitly assuming strong construct validity: that such cues are interchangeable operationalizations of the same underlying, demographically conditioned behavior. We test this assumption in realistic advice-seeking interactions, focusing on race and gender in a U.S. context. We find that cues intended to represent the same demographic group induce only partially overlapping changes in model behavior, while differentiation between groups within a given cue is weak and uneven. Consequently, estimated disparities are unstable, with both magnitude and direction varying across cues. We further show that these inconsistencies partly arise from variation in how strongly cues encode demographic attributes and from linguistic confounders that independently shape model behavior. Together, our findings suggest that demographic probing lacks construct validity: it does not yield a single, stable characterization of how LLMs condition on demographic information, which may reflect a misspecified or fragmented construct. We conclude by recommending the use of multiple, ecologically valid cues and explicit control of confounders to support more defensible claims about demographic effects in LLMs.
When Claims Evolve: Evaluating and Enhancing the Robustness of Embedding Models Against Misinformation Edits
Mar 05, 2025



Online misinformation remains a critical challenge, and fact-checkers increasingly rely on embedding-based methods to retrieve relevant fact-checks. Yet, when debunked claims reappear in edited forms, the performance of these methods is unclear. In this work, we introduce a taxonomy of six common real-world misinformation edits and propose a perturbation framework that generates valid, natural claim variations. Our multi-stage retrieval evaluation reveals that standard embedding models struggle with user-introduced edits, while LLM-distilled embeddings offer improved robustness at a higher computational cost. Although a strong reranker helps mitigate some issues, it cannot fully compensate for first-stage retrieval gaps. Addressing these retrieval gaps, our train- and inference-time mitigation approaches enhance in-domain robustness by up to 17 percentage points and boost out-of-domain generalization by 10 percentage points over baseline models. Overall, our findings provide practical improvements to claim-matching systems, enabling more reliable fact-checking of evolving misinformation.
HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter
Nov 23, 2024



To tackle the global challenge of online hate speech, a large body of research has developed detection models to flag hate speech in the sea of online content. Yet, due to systematic biases in evaluation datasets, detection performance in real-world settings remains unclear, let alone across geographies. To address this issue, we introduce HateDay, the first global hate speech dataset representative of social media settings, randomly sampled from all tweets posted on September 21, 2022 for eight languages and four English-speaking countries. Using HateDay, we show how the prevalence and composition of hate speech varies across languages and countries. We also find that evaluation on academic hate speech datasets overestimates real-world detection performance, which we find is very low, especially for non-European languages. We identify several factors explaining poor performance, including models' inability to distinguish between hate and offensive speech, and the misalignment between academic target focus and real-world target prevalence. We finally argue that such low performance renders hate speech moderation with public detection models unfeasible, even in a human-in-the-loop setting which we find is prohibitively costly. Overall, we emphasize the need to evaluate future detection models from academia and platforms in real-world settings to address this global challenge.
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Apr 27, 2024



Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by language. This hides potential cultural biases, as one language may be spoken in different countries home to different cultures. In this work, we evaluate cultural bias in HS datasets by leveraging two interrelated cultural proxies: language and geography. We conduct a systematic survey of HS datasets in eight languages and confirm past findings on their English-language bias, but also show that this bias has been steadily decreasing in the past few years. For three geographically-widespread languages -- English, Arabic and Spanish -- we then leverage geographical metadata from tweets to approximate geo-cultural contexts by pairing language and country information. We find that HS datasets for these languages exhibit a strong geo-cultural bias, largely overrepresenting a handful of countries (e.g., US and UK for English) relative to their prominence in both the broader social media population and the general population speaking these languages. Based on these findings, we formulate recommendations for the creation of future HS datasets.
NaijaHate: Evaluating Hate Speech Detection on Nigerian Twitter Using Representative Data
Mar 28, 2024



To address the global issue of hateful content proliferating in online platforms, hate speech detection (HSD) models are typically developed on datasets collected in the United States, thereby failing to generalize to English dialects from the Majority World. Furthermore, HSD models are often evaluated on curated samples, raising concerns about overestimating model performance in real-world settings. In this work, we introduce NaijaHate, the first dataset annotated for HSD which contains a representative sample of Nigerian tweets. We demonstrate that HSD evaluated on biased datasets traditionally used in the literature largely overestimates real-world performance on representative data. We also propose NaijaXLM-T, a pretrained model tailored to the Nigerian Twitter context, and establish the key role played by domain-adaptive pretraining and finetuning in maximizing HSD performance. Finally, we show that in this context, a human-in-the-loop approach to content moderation where humans review 1% of Nigerian tweets flagged as hateful would enable to moderate 60% of all hateful content. Taken together, these results pave the way towards robust HSD systems and a better protection of social media users from hateful content in low-resource settings.
Casteist but Not Racist? Quantifying Disparities in Large Language Model Bias between India and the West
Sep 15, 2023

Large Language Models (LLMs), now used daily by millions of users, can encode societal biases, exposing their users to representational harms. A large body of scholarship on LLM bias exists but it predominantly adopts a Western-centric frame and attends comparatively less to bias levels and potential harms in the Global South. In this paper, we quantify stereotypical bias in popular LLMs according to an Indian-centric frame and compare bias levels between the Indian and Western contexts. To do this, we develop a novel dataset which we call Indian-BhED (Indian Bias Evaluation Dataset), containing stereotypical and anti-stereotypical examples for caste and religion contexts. We find that the majority of LLMs tested are strongly biased towards stereotypes in the Indian context, especially as compared to the Western context. We finally investigate Instruction Prompting as a simple intervention to mitigate such bias and find that it significantly reduces both stereotypical and anti-stereotypical biases in the majority of cases for GPT-3.5. The findings of this work highlight the need for including more diverse voices when evaluating LLMs.
Multilingual Detection of Personal Employment Status on Twitter
Mar 17, 2022
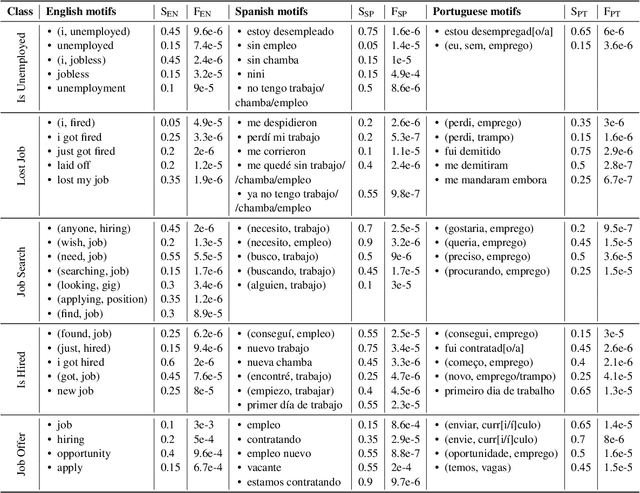
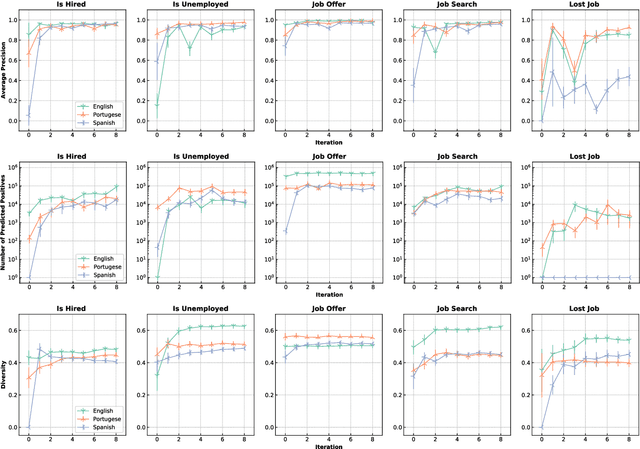

Detecting disclosures of individuals' employment status on social media can provide valuable information to match job seekers with suitable vacancies, offer social protection, or measure labor market flows. However, identifying such personal disclosures is a challenging task due to their rarity in a sea of social media content and the variety of linguistic forms used to describe them. Here, we examine three Active Learning (AL) strategies in real-world settings of extreme class imbalance, and identify five types of disclosures about individuals' employment status (e.g. job loss) in three languages using BERT-based classification models. Our findings show that, even under extreme imbalance settings, a small number of AL iterations is sufficient to obtain large and significant gains in precision, recall, and diversity of results compared to a supervised baseline with the same number of labels. We also find that no AL strategy consistently outperforms the rest. Qualitative analysis suggests that AL helps focus the attention mechanism of BERT on core terms and adjust the boundaries of semantic expansion, highlighting the importance of interpretable models to provide greater control and visibility into this dynamic learning process.