 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Causal Effects from Natural Language Queries using Structured Representations
May 28, 2026Randomized controlled trials are a cornerstone of medicine and the social sciences as they enable reliable estimates of causal effects. However, they are costly and time-consuming to conduct, motivating interest in predicting causal effects from existing experimental evidence. Recent advances in large language models (LLMs) have demonstrated strong performance on knowledge-intensive tasks, raising the question of whether these models can be used for forecasting causal effect sizes. To investigate this, we introduce Query2Effect, a new large-scale benchmark consisting of more than 72,000 natural language questions aligned with experiment descriptions, created to simulate realistic information-seeking scenarios by varying query specificity along dimensions of implicitness, abstraction, and ambiguity. We then propose a two-step framework that first generates a synthetic structured representation of a query before predicting effect size using a supervised encoder model. Experiments show that finetuning plays a crucial role in improving prediction performance, with absolute error reducing by -27% up to -71% compared to prompted out-of-the-box LLMs, and that our two-step framework is beneficial for out-of-domain generalization, highlighting the benefits of separating semantic interpretation from numerical effect estimation.
Evaluating Deduplication Techniques for Economic Research Paper Titles with a Focus on Semantic Similarity using NLP and LLMs
Oct 02, 2024This study investigates efficient deduplication techniques for a large NLP dataset of economic research paper titles. We explore various pairing methods alongside established distance measures (Levenshtein distance, cosine similarity) and a sBERT model for semantic evaluation. Our findings suggest a potentially low prevalence of duplicates based on the observed semantic similarity across different methods. Further exploration with a human-annotated ground truth set is completed for a more conclusive assessment. The result supports findings from the NLP, LLM based distance metrics.
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Apr 27, 2024



Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by language. This hides potential cultural biases, as one language may be spoken in different countries home to different cultures. In this work, we evaluate cultural bias in HS datasets by leveraging two interrelated cultural proxies: language and geography. We conduct a systematic survey of HS datasets in eight languages and confirm past findings on their English-language bias, but also show that this bias has been steadily decreasing in the past few years. For three geographically-widespread languages -- English, Arabic and Spanish -- we then leverage geographical metadata from tweets to approximate geo-cultural contexts by pairing language and country information. We find that HS datasets for these languages exhibit a strong geo-cultural bias, largely overrepresenting a handful of countries (e.g., US and UK for English) relative to their prominence in both the broader social media population and the general population speaking these languages. Based on these findings, we formulate recommendations for the creation of future HS datasets.
NaijaHate: Evaluating Hate Speech Detection on Nigerian Twitter Using Representative Data
Mar 28, 2024



To address the global issue of hateful content proliferating in online platforms, hate speech detection (HSD) models are typically developed on datasets collected in the United States, thereby failing to generalize to English dialects from the Majority World. Furthermore, HSD models are often evaluated on curated samples, raising concerns about overestimating model performance in real-world settings. In this work, we introduce NaijaHate, the first dataset annotated for HSD which contains a representative sample of Nigerian tweets. We demonstrate that HSD evaluated on biased datasets traditionally used in the literature largely overestimates real-world performance on representative data. We also propose NaijaXLM-T, a pretrained model tailored to the Nigerian Twitter context, and establish the key role played by domain-adaptive pretraining and finetuning in maximizing HSD performance. Finally, we show that in this context, a human-in-the-loop approach to content moderation where humans review 1% of Nigerian tweets flagged as hateful would enable to moderate 60% of all hateful content. Taken together, these results pave the way towards robust HSD systems and a better protection of social media users from hateful content in low-resource settings.
Multilingual Detection of Personal Employment Status on Twitter
Mar 17, 2022
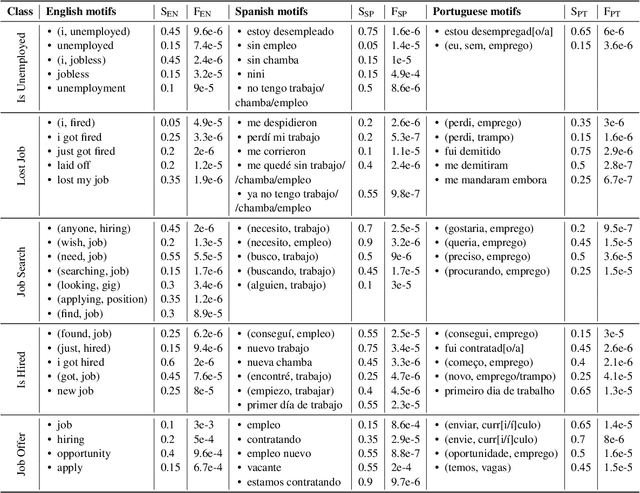
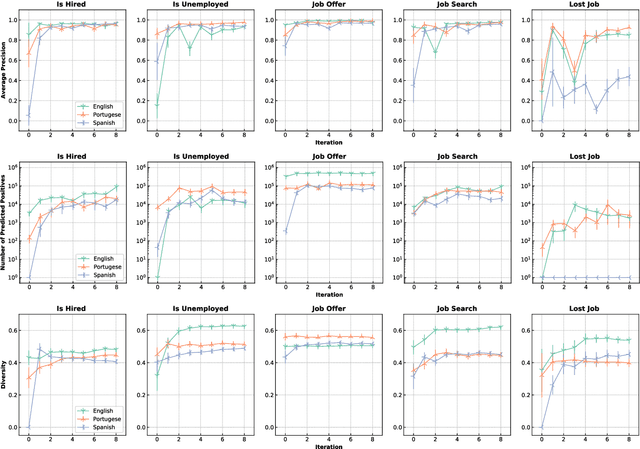

Detecting disclosures of individuals' employment status on social media can provide valuable information to match job seekers with suitable vacancies, offer social protection, or measure labor market flows. However, identifying such personal disclosures is a challenging task due to their rarity in a sea of social media content and the variety of linguistic forms used to describe them. Here, we examine three Active Learning (AL) strategies in real-world settings of extreme class imbalance, and identify five types of disclosures about individuals' employment status (e.g. job loss) in three languages using BERT-based classification models. Our findings show that, even under extreme imbalance settings, a small number of AL iterations is sufficient to obtain large and significant gains in precision, recall, and diversity of results compared to a supervised baseline with the same number of labels. We also find that no AL strategy consistently outperforms the rest. Qualitative analysis suggests that AL helps focus the attention mechanism of BERT on core terms and adjust the boundaries of semantic expansion, highlighting the importance of interpretable models to provide greater control and visibility into this dynamic learning process.