 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition
Apr 10, 2022
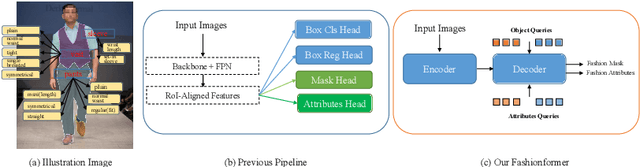
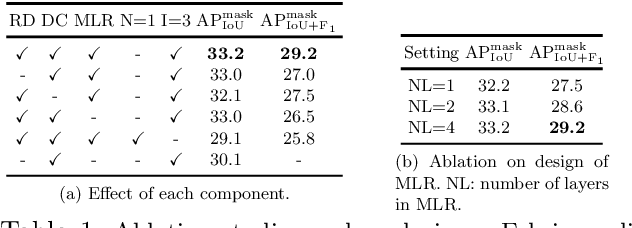
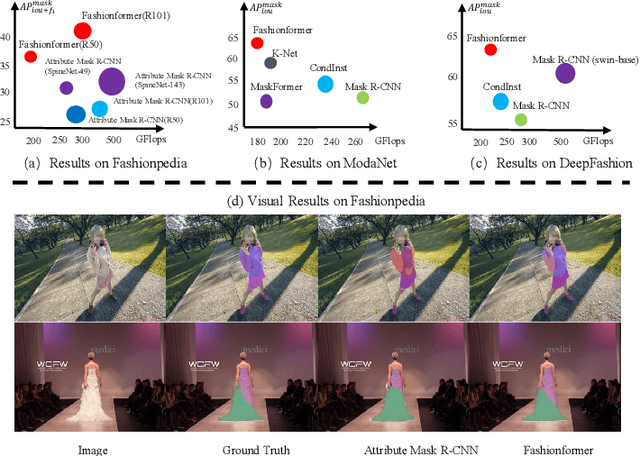
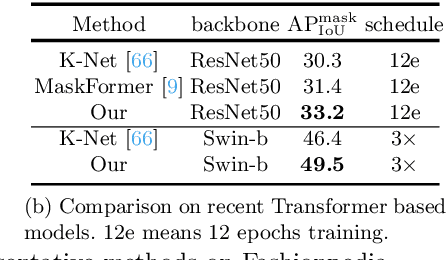
Human fashion understanding is one important computer vision task since it has the comprehensive information that can be used for real-world applications. In this work, we focus on joint human fashion segmentation and attribute recognition. Contrary to the previous works that separately model each task as a multi-head prediction problem, our insight is to bridge these two tasks with one unified model via vision transformer modeling to benefit each task. In particular, we introduce the object query for segmentation and the attribute query for attribute prediction. Both queries and their corresponding features can be linked via mask prediction. Then we adopt a two-stream query learning framework to learn the decoupled query representations. For attribute stream, we design a novel Multi-Layer Rendering module to explore more fine-grained features. The decoder design shares the same spirits with DETR, thus we name the proposed method Fahsionformer. Extensive experiments on three human fashion datasets including Fashionpedia, ModaNet and Deepfashion illustrate the effectiveness of our approach. In particular, our method with the same backbone achieve relative 10% improvements than previous works in case of \textit{a joint metric ( AP$^{\text{mask}}_{\text{IoU+F}_1}$) for both segmentation and attribute recognition}. To the best of our knowledge, we are the first unified end-to-end vision transformer framework for human fashion analysis. We hope this simple yet effective method can serve as a new flexible baseline for fashion analysis. Code will be available at https://github.com/xushilin1/FashionFormer.
Target Detection within Nonhomogeneous Clutter via Total Bregman Divergence-Based Matrix Information Geometry Detectors
Dec 27, 2020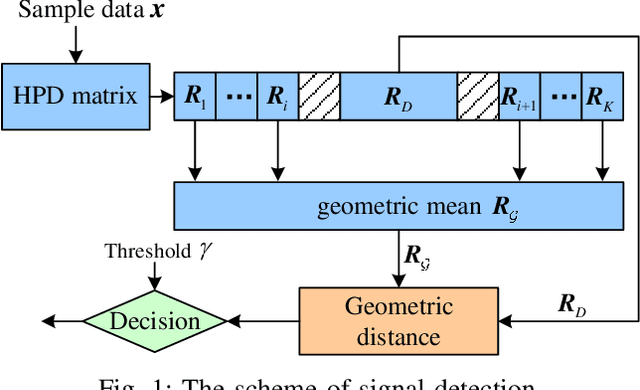
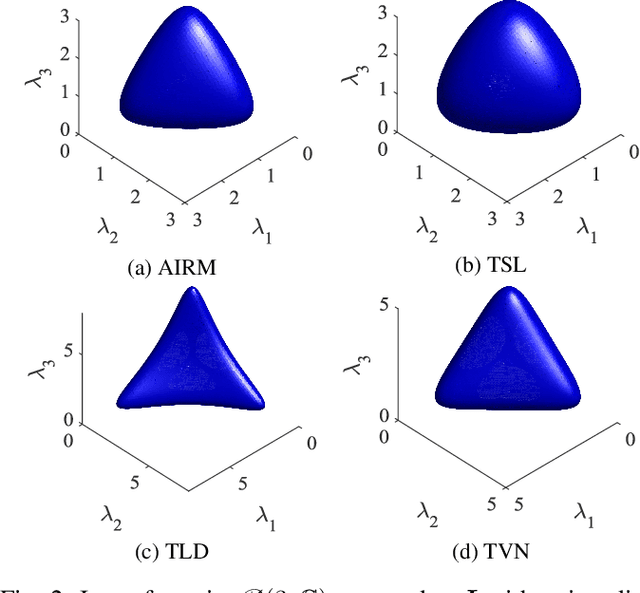
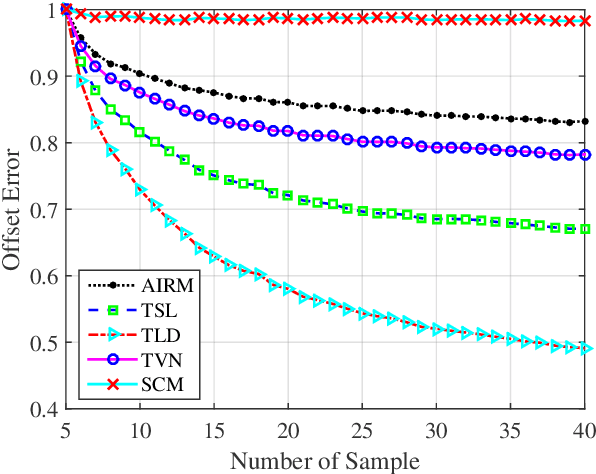
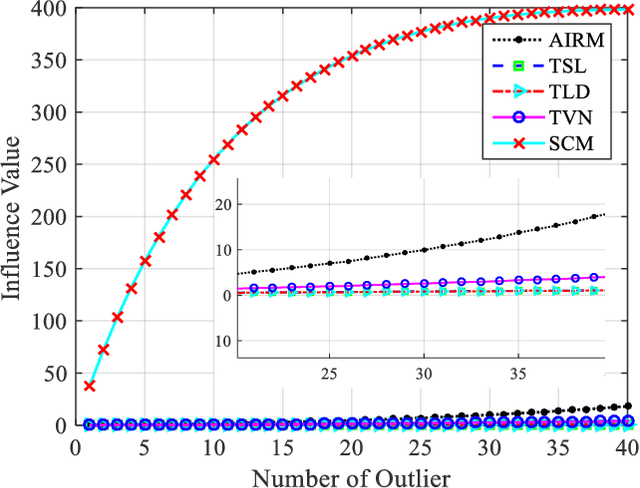
Information divergences are commonly used to measure the dissimilarity of two elements on a statistical manifold. Differentiable manifolds endowed with different divergences may possess different geometric properties, which can result in totally different performances in many practical applications. In this paper, we propose a total Bregman divergence-based matrix information geometry (TBD-MIG) detector and apply it to detect targets emerged into nonhomogeneous clutter. In particular, each sample data is assumed to be modeled as a Hermitian positive-definite (HPD) matrix and the clutter covariance matrix is estimated by the TBD mean of a set of secondary HPD matrices. We then reformulate the problem of signal detection as discriminating two points on the HPD matrix manifold. Three TBD-MIG detectors, referred to as the total square loss, the total log-determinant and the total von Neumann MIG detectors, are proposed, and they can achieve great performances due to their power of discrimination and robustness to interferences. Simulations show the advantage of the proposed TBD-MIG detectors in comparison with the geometric detector using an affine invariant Riemannian metric as well as the adaptive matched filter in nonhomogeneous clutter.
Why adversarial training can hurt robust accuracy
Mar 03, 2022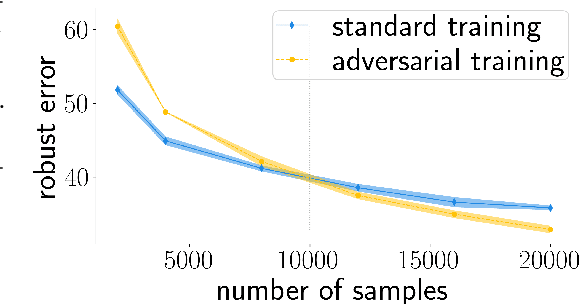
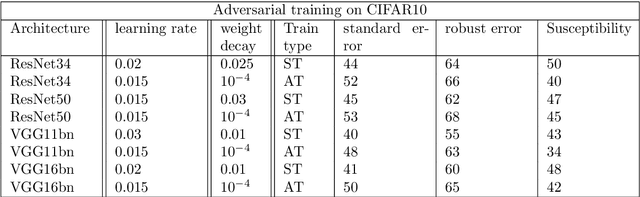

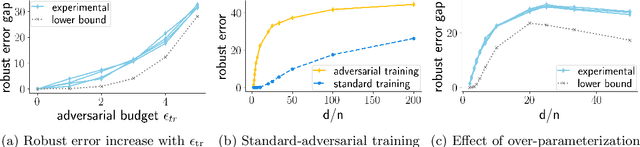
Machine learning classifiers with high test accuracy often perform poorly under adversarial attacks. It is commonly believed that adversarial training alleviates this issue. In this paper, we demonstrate that, surprisingly, the opposite may be true -- Even though adversarial training helps when enough data is available, it may hurt robust generalization in the small sample size regime. We first prove this phenomenon for a high-dimensional linear classification setting with noiseless observations. Our proof provides explanatory insights that may also transfer to feature learning models. Further, we observe in experiments on standard image datasets that the same behavior occurs for perceptible attacks that effectively reduce class information such as mask attacks and object corruptions.
On Recoverability of Graph Neural Network Representations
Jan 30, 2022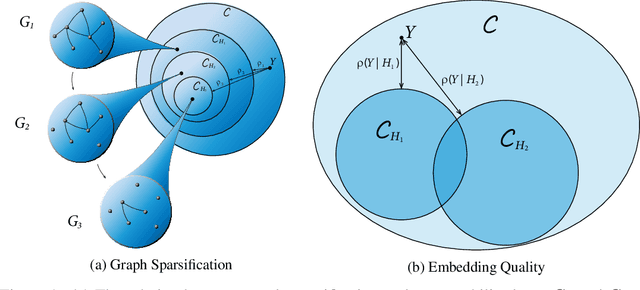
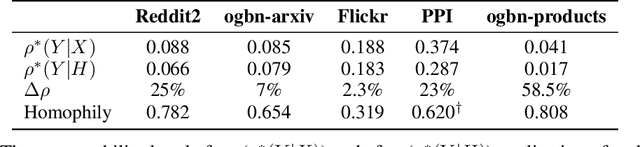
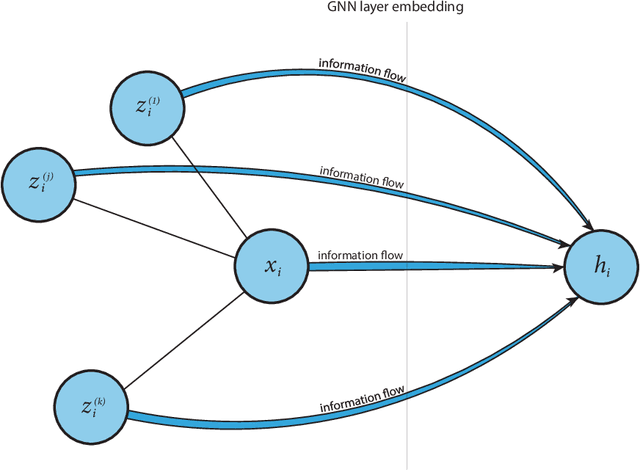

Despite their growing popularity, graph neural networks (GNNs) still have multiple unsolved problems, including finding more expressive aggregation methods, propagation of information to distant nodes, and training on large-scale graphs. Understanding and solving such problems require developing analytic tools and techniques. In this work, we propose the notion of recoverability, which is tightly related to information aggregation in GNNs, and based on this concept, develop the method for GNN embedding analysis. We define recoverability theoretically and propose a method for its efficient empirical estimation. We demonstrate, through extensive experimental results on various datasets and different GNN architectures, that estimated recoverability correlates with aggregation method expressivity and graph sparsification quality. Therefore, we believe that the proposed method could provide an essential tool for understanding the roots of the aforementioned problems, and potentially lead to a GNN design that overcomes them. The code to reproduce our experiments is available at https://github.com/Anonymous1252022/Recoverability
Covariate-informed Representation Learning with Samplewise Optimal Identifiable Variational Autoencoders
Feb 09, 2022
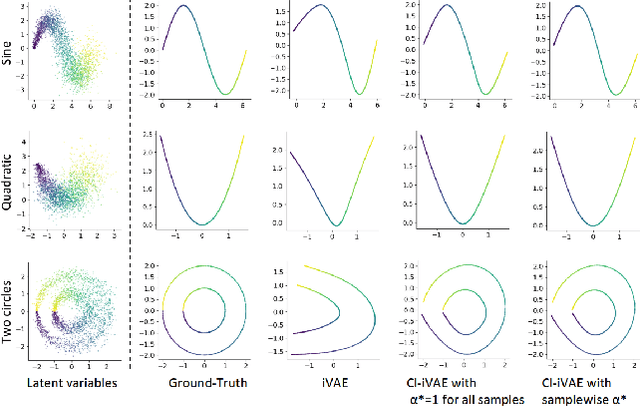
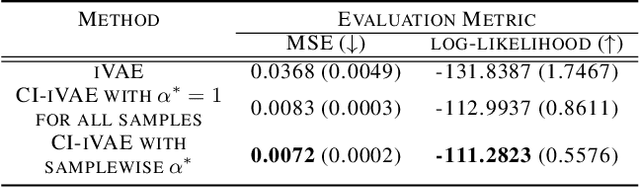
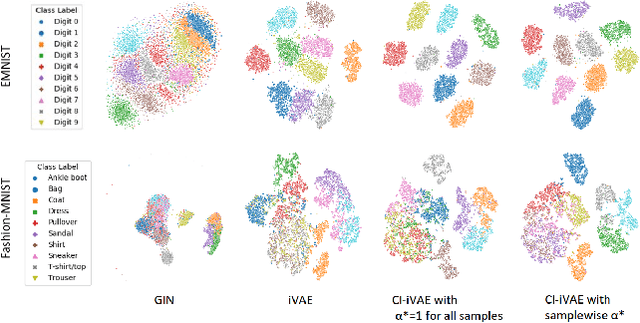
Recently proposed identifiable variational autoencoder (iVAE, Khemakhem et al. (2020)) framework provides a promising approach for learning latent independent components of the data. Although the identifiability is appealing, the objective function of iVAE does not enforce the inverse relation between encoders and decoders. Without the inverse relation, representations from the encoder in iVAE may not reconstruct observations,i.e., representations lose information in observations. To overcome this limitation, we develop a new approach, covariate-informed identifiable VAE (CI-iVAE). Different from previous iVAE implementations, our method critically leverages the posterior distribution of latent variables conditioned only on observations. In doing so, the objective function enforces the inverse relation, and learned representation contains more information of observations. Furthermore, CI-iVAE extends the original iVAE objective function to a larger class and finds the optimal one among them, thus providing a better fit to the data. Theoretically, our method has tighter evidence lower bounds (ELBOs) than the original iVAE. We demonstrate that our approach can more reliably learn features of various synthetic datasets, two benchmark image datasets (EMNIST and Fashion MNIST), and a large-scale brain imaging dataset for adolescent mental health research.
Exploring Human Mobility for Multi-Pattern Passenger Prediction: A Graph Learning Framework
Feb 17, 2022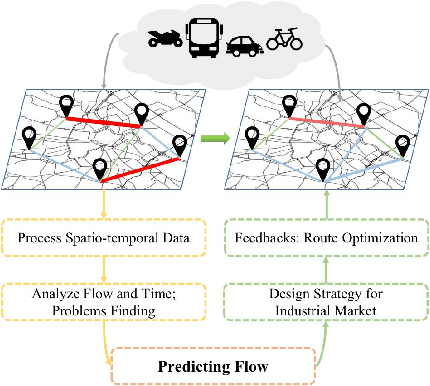
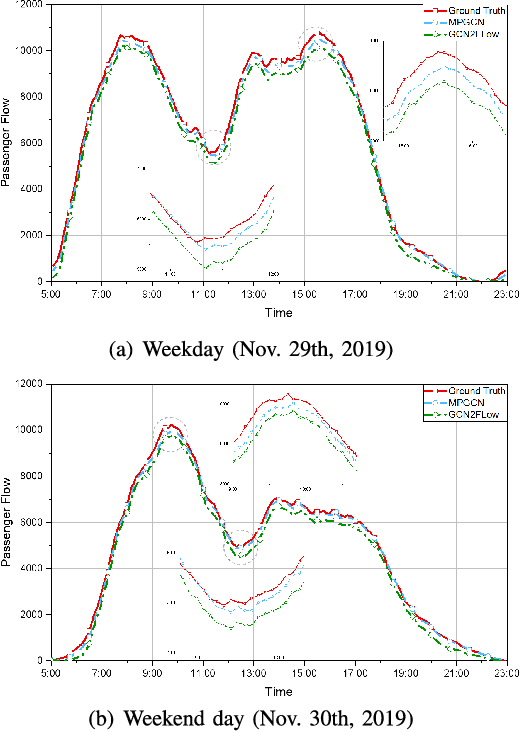
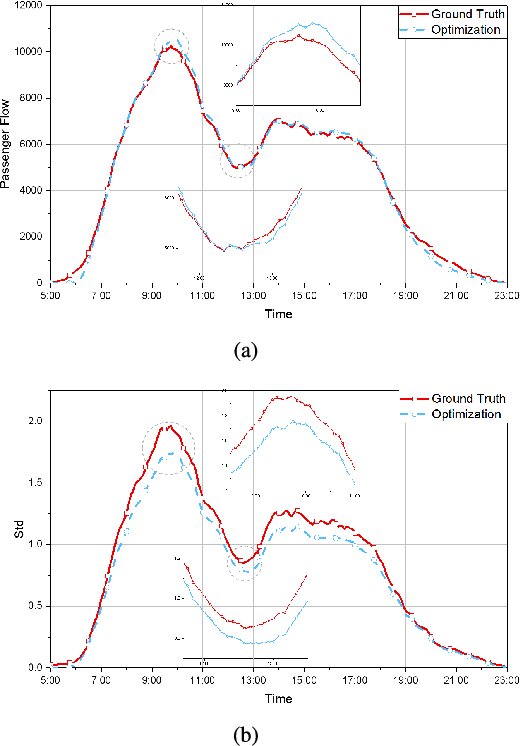

Traffic flow prediction is an integral part of an intelligent transportation system and thus fundamental for various traffic-related applications. Buses are an indispensable way of moving for urban residents with fixed routes and schedules, which leads to latent travel regularity. However, human mobility patterns, specifically the complex relationships between bus passengers, are deeply hidden in this fixed mobility mode. Although many models exist to predict traffic flow, human mobility patterns have not been well explored in this regard. To reduce this research gap and learn human mobility knowledge from this fixed travel behaviors, we propose a multi-pattern passenger flow prediction framework, MPGCN, based on Graph Convolutional Network (GCN). Firstly, we construct a novel sharing-stop network to model relationships between passengers based on bus record data. Then, we employ GCN to extract features from the graph by learning useful topology information and introduce a deep clustering method to recognize mobility patterns hidden in bus passengers. Furthermore, to fully utilize Spatio-temporal information, we propose GCN2Flow to predict passenger flow based on various mobility patterns. To the best of our knowledge, this paper is the first work to adopt a multipattern approach to predict the bus passenger flow from graph learning. We design a case study for optimizing routes. Extensive experiments upon a real-world bus dataset demonstrate that MPGCN has potential efficacy in passenger flow prediction and route optimization.
Robust Reputation Independence in Ranking Systems for Multiple Sensitive Attributes
Mar 30, 2022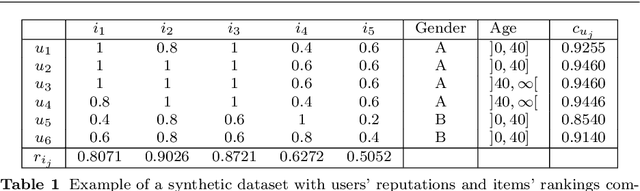

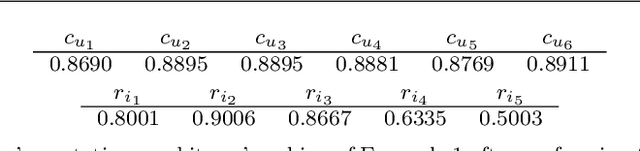
Ranking systems have an unprecedented influence on how and what information people access, and their impact on our society is being analyzed from different perspectives, such as users' discrimination. A notable example is represented by reputation-based ranking systems, a class of systems that rely on users' reputation to generate a non-personalized item-ranking, proved to be biased against certain demographic classes. To safeguard that a given sensitive user's attribute does not systematically affect the reputation of that user, prior work has operationalized a reputation independence constraint on this class of systems. In this paper, we uncover that guaranteeing reputation independence for a single sensitive attribute is not enough. When mitigating biases based on one sensitive attribute (e.g., gender), the final ranking might still be biased against certain demographic groups formed based on another attribute (e.g., age). Hence, we propose a novel approach to introduce reputation independence for multiple sensitive attributes simultaneously. We then analyze the extent to which our approach impacts on discrimination and other important properties of the ranking system, such as its quality and robustness against attacks. Experiments on two real-world datasets show that our approach leads to less biased rankings with respect to multiple users' sensitive attributes, without affecting the system's quality and robustness.
Context Enhanced Short Text Matching using Clickthrough Data
Mar 03, 2022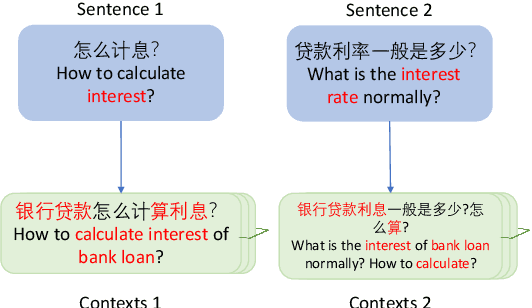
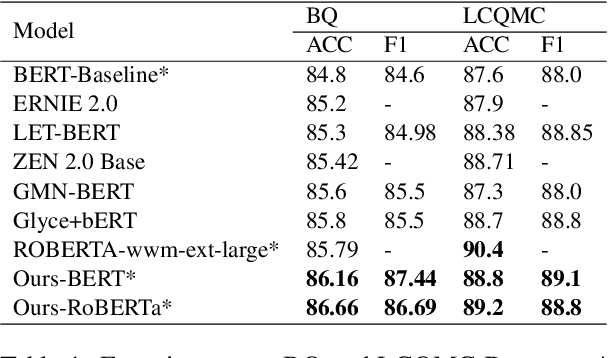
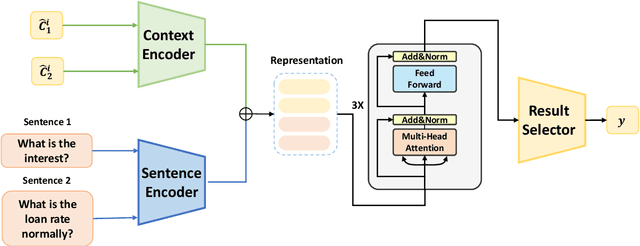
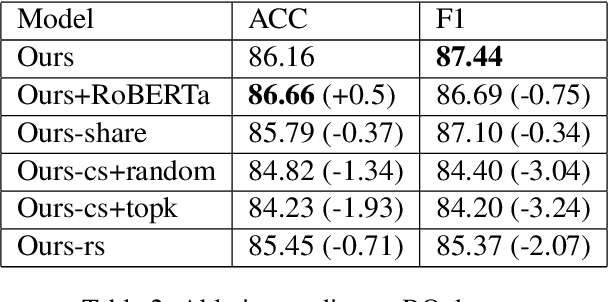
The short text matching task employs a model to determine whether two short texts have the same semantic meaning or intent. Existing short text matching models usually rely on the content of short texts which are lack information or missing some key clues. Therefore, the short texts need external knowledge to complete their semantic meaning. To address this issue, we propose a new short text matching framework for introducing external knowledge to enhance the short text contextual representation. In detail, we apply a self-attention mechanism to enrich short text representation with external contexts. Experiments on two Chinese datasets and one English dataset demonstrate that our framework outperforms the state-of-the-art short text matching models.
Network state Estimation using Raw Video Analysis: vQoS-GAN based non-intrusive Deep Learning Approach
Mar 22, 2022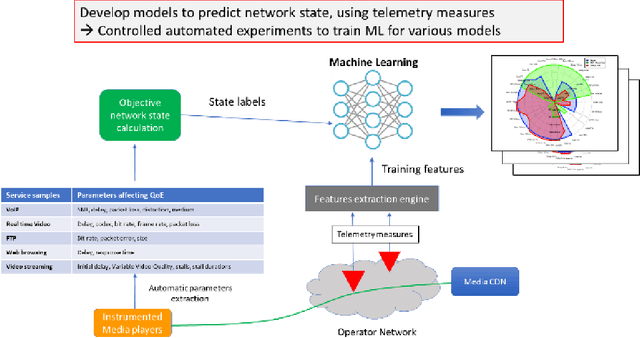

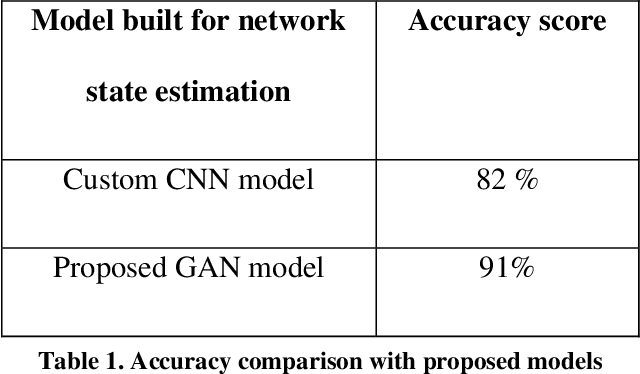

Content based providers transmits real time complex signal such as video data from one region to another. During this transmission process, the signals usually end up distorted or degraded where the actual information present in the video is lost. This normally happens in the streaming video services applications. Hence there is a need to know the level of degradation that happened in the receiver side. This video degradation can be estimated by network state parameters like data rate and packet loss values. Our proposed solution vQoS GAN (video Quality of Service Generative Adversarial Network) can estimate the network state parameters from the degraded received video data using a deep learning approach of semi supervised generative adversarial network algorithm. A robust and unique design of deep learning network model has been trained with the video data along with data rate and packet loss class labels and achieves over 95 percent of training accuracy. The proposed semi supervised generative adversarial network can additionally reconstruct the degraded video data to its original form for a better end user experience.
HOP: History-and-Order Aware Pre-training for Vision-and-Language Navigation
Mar 22, 2022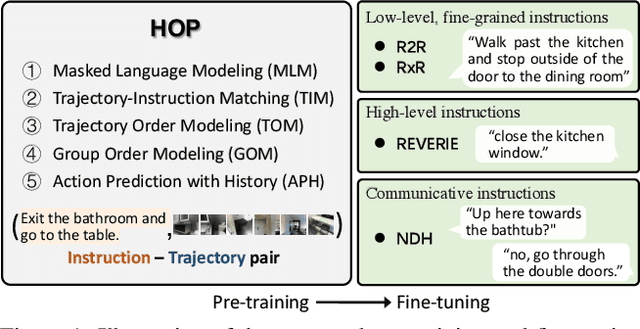
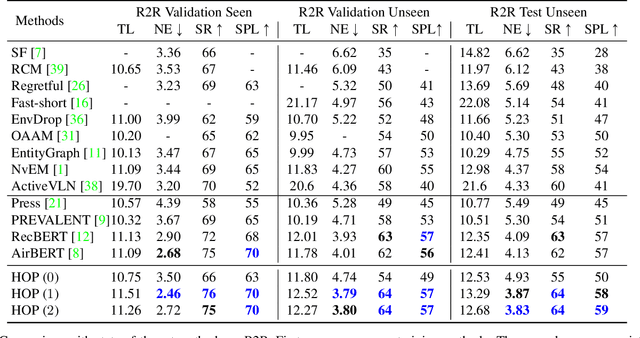
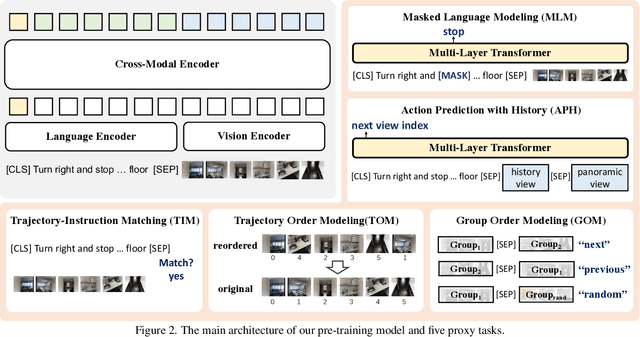
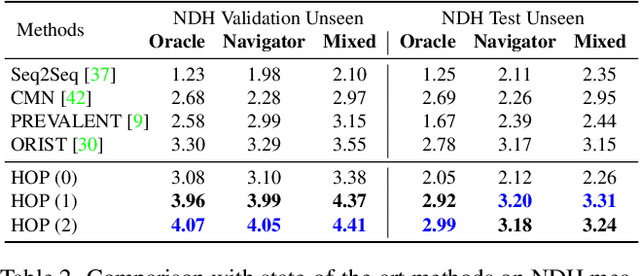
Pre-training has been adopted in a few of recent works for Vision-and-Language Navigation (VLN). However, previous pre-training methods for VLN either lack the ability to predict future actions or ignore the trajectory contexts, which are essential for a greedy navigation process. In this work, to promote the learning of spatio-temporal visual-textual correspondence as well as the agent's capability of decision making, we propose a novel history-and-order aware pre-training paradigm (HOP) with VLN-specific objectives that exploit the past observations and support future action prediction. Specifically, in addition to the commonly used Masked Language Modeling (MLM) and Trajectory-Instruction Matching (TIM), we design two proxy tasks to model temporal order information: Trajectory Order Modeling (TOM) and Group Order Modeling (GOM). Moreover, our navigation action prediction is also enhanced by introducing the task of Action Prediction with History (APH), which takes into account the history visual perceptions. Extensive experimental results on four downstream VLN tasks (R2R, REVERIE, NDH, RxR) demonstrate the effectiveness of our proposed method compared against several state-of-the-art agents.