 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegulating Group Exposure for Item Providers in Recommendation
Apr 24, 2022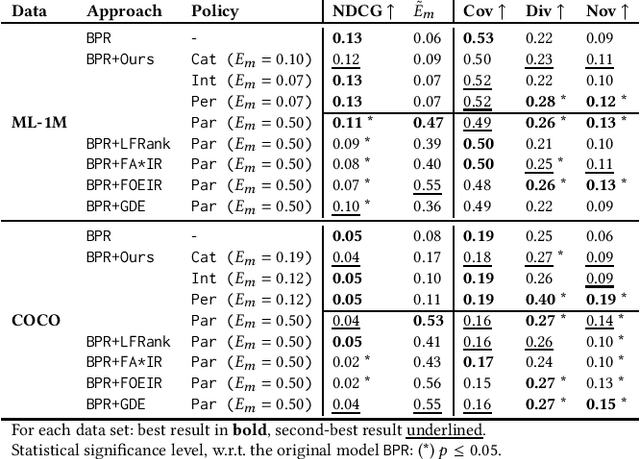
Engaging all content providers, including newcomers or minority demographic groups, is crucial for online platforms to keep growing and working. Hence, while building recommendation services, the interests of those providers should be valued. In this paper, we consider providers as grouped based on a common characteristic in settings in which certain provider groups have low representation of items in the catalog and, thus, in the user interactions. Then, we envision a scenario wherein platform owners seek to control the degree of exposure to such groups in the recommendation process. To support this scenario, we rely on disparate exposure measures that characterize the gap between the share of recommendations given to groups and the target level of exposure pursued by the platform owners. We then propose a re-ranking procedure that ensures desired levels of exposure are met. Experiments show that, while supporting certain groups of providers by rendering them with the target exposure, beyond-accuracy objectives experience significant gains with negligible impact in recommendation utility.
Robust Reputation Independence in Ranking Systems for Multiple Sensitive Attributes
Mar 30, 2022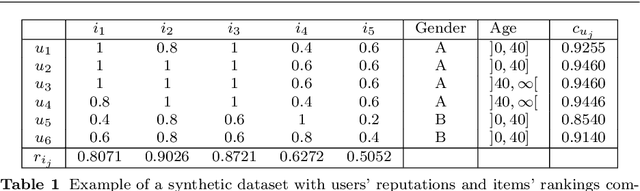

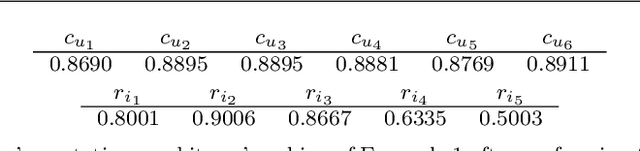
Ranking systems have an unprecedented influence on how and what information people access, and their impact on our society is being analyzed from different perspectives, such as users' discrimination. A notable example is represented by reputation-based ranking systems, a class of systems that rely on users' reputation to generate a non-personalized item-ranking, proved to be biased against certain demographic classes. To safeguard that a given sensitive user's attribute does not systematically affect the reputation of that user, prior work has operationalized a reputation independence constraint on this class of systems. In this paper, we uncover that guaranteeing reputation independence for a single sensitive attribute is not enough. When mitigating biases based on one sensitive attribute (e.g., gender), the final ranking might still be biased against certain demographic groups formed based on another attribute (e.g., age). Hence, we propose a novel approach to introduce reputation independence for multiple sensitive attributes simultaneously. We then analyze the extent to which our approach impacts on discrimination and other important properties of the ranking system, such as its quality and robustness against attacks. Experiments on two real-world datasets show that our approach leads to less biased rankings with respect to multiple users' sensitive attributes, without affecting the system's quality and robustness.
A Robust Reputation-based Group Ranking System and its Resistance to Bribery
Apr 17, 2020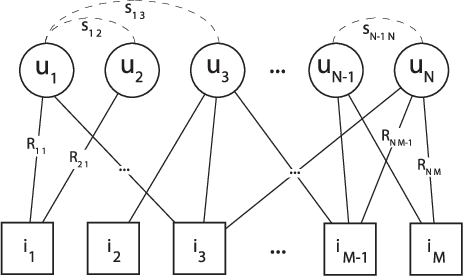
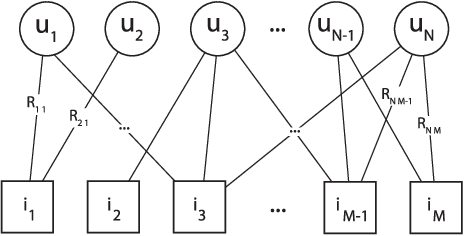
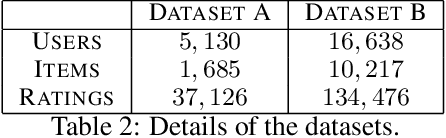
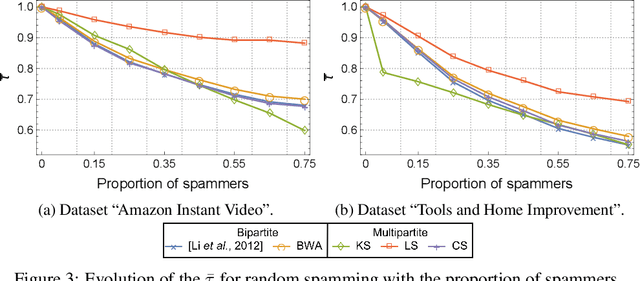
The spread of online reviews and opinions and its growing influence on people's behavior and decisions, boosted the interest to extract meaningful information from this data deluge. Hence, crowdsourced ratings of products and services gained a critical role in business and governments. Current state-of-the-art solutions rank the items with an average of the ratings expressed for an item, with a consequent lack of personalization for the users, and the exposure to attacks and spamming/spurious users. Using these ratings to group users with similar preferences might be useful to present users with items that reflect their preferences and overcome those vulnerabilities. In this paper, we propose a new reputation-based ranking system, utilizing multipartite rating subnetworks, which clusters users by their similarities using three measures, two of them based on Kolmogorov complexity. We also study its resistance to bribery and how to design optimal bribing strategies. Our system is novel in that it reflects the diversity of preferences by (possibly) assigning distinct rankings to the same item, for different groups of users. We prove the convergence and efficiency of the system. By testing it on synthetic and real data, we see that it copes better with spamming/spurious users, being more robust to attacks than state-of-the-art approaches. Also, by clustering users, the effect of bribery in the proposed multipartite ranking system is dimmed, comparing to the bipartite case.