 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Anomaly Detection in 3D Brain MRI using Deep Learning with Multi-Task Brain Age Prediction
Jan 31, 2022
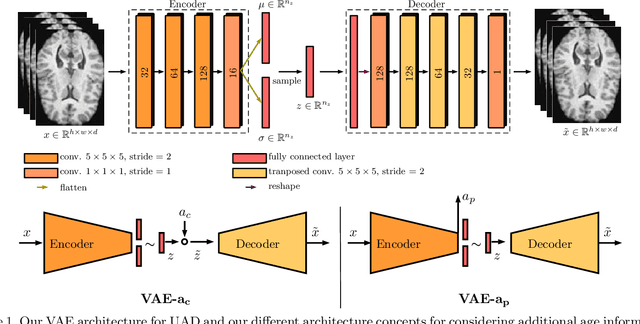

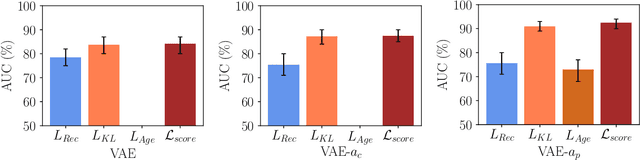
Lesion detection in brain Magnetic Resonance Images (MRIs) remains a challenging task. MRIs are typically read and interpreted by domain experts, which is a tedious and time-consuming process. Recently, unsupervised anomaly detection (UAD) in brain MRI with deep learning has shown promising results to provide a quick, initial assessment. So far, these methods only rely on the visual appearance of healthy brain anatomy for anomaly detection. Another biomarker for abnormal brain development is the deviation between the brain age and the chronological age, which is unexplored in combination with UAD. We propose deep learning for UAD in 3D brain MRI considering additional age information. We analyze the value of age information during training, as an additional anomaly score, and systematically study several architecture concepts. Based on our analysis, we propose a novel deep learning approach for UAD with multi-task age prediction. We use clinical T1-weighted MRIs of 1735 healthy subjects and the publicly available BraTs 2019 data set for our study. Our novel approach significantly improves UAD performance with an AUC of 92.60% compared to an AUC-score of 84.37% using previous approaches without age information.
Conditional Measurement Density Estimation in Sequential Monte Carlo via Normalizing Flow
Mar 16, 2022
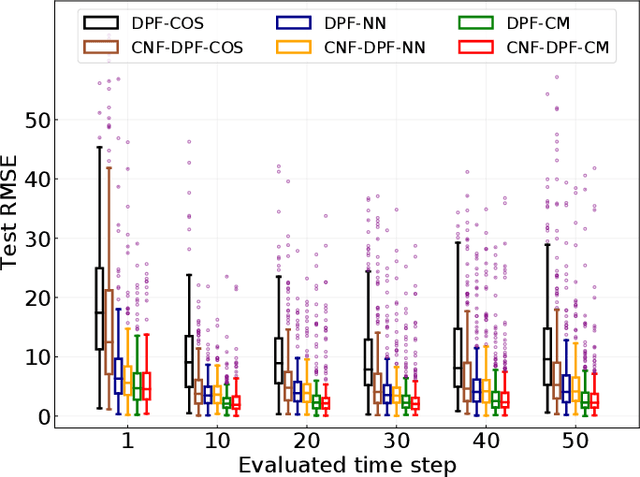
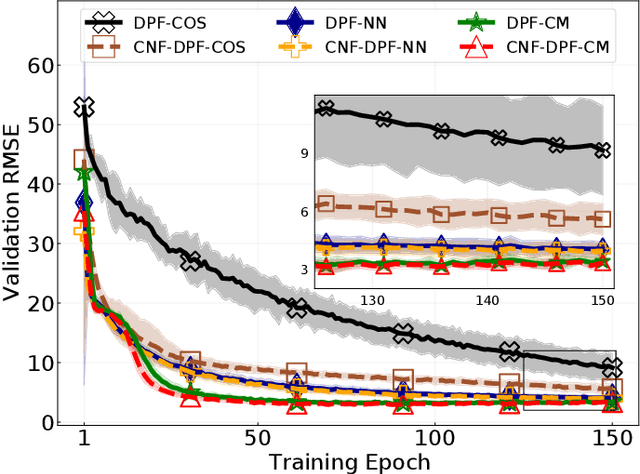
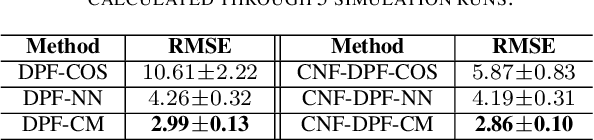
Tuning of measurement models is challenging in real-world applications of sequential Monte Carlo methods. Recent advances in differentiable particle filters have led to various efforts to learn measurement models through neural networks. But existing approaches in the differentiable particle filter framework do not admit valid probability densities in constructing measurement models, leading to incorrect quantification of the measurement uncertainty given state information. We propose to learn expressive and valid probability densities in measurement models through conditional normalizing flows, to capture the complex likelihood of measurements given states. We show that the proposed approach leads to improved estimation performance and faster training convergence in a visual tracking experiment.
S-R2F2U-Net: A single-stage model for teeth segmentation
Apr 06, 2022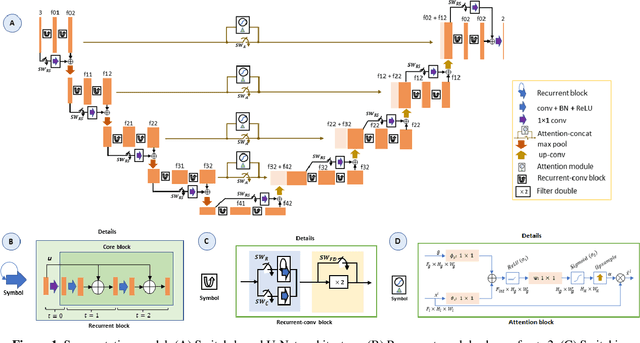
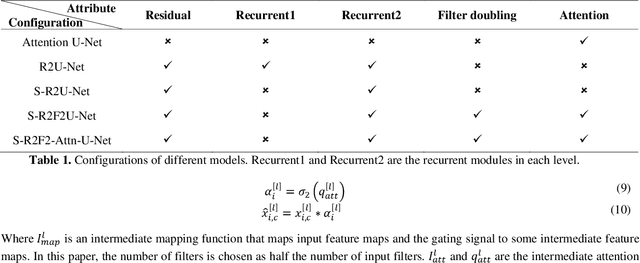
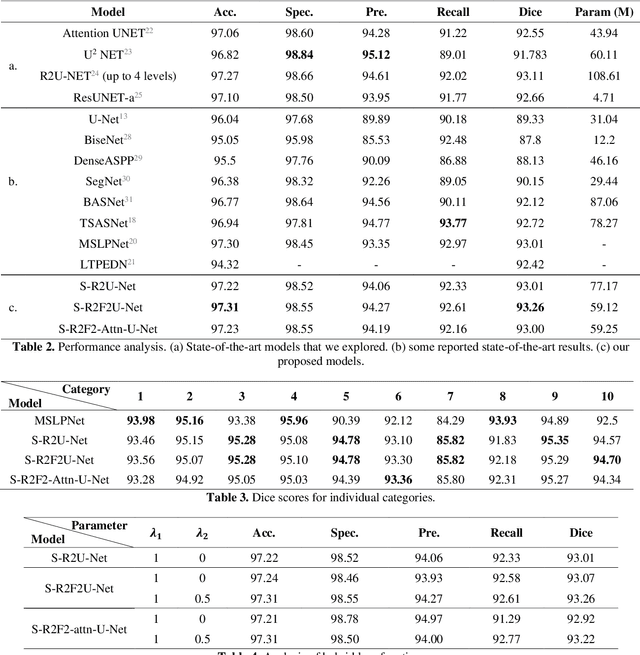
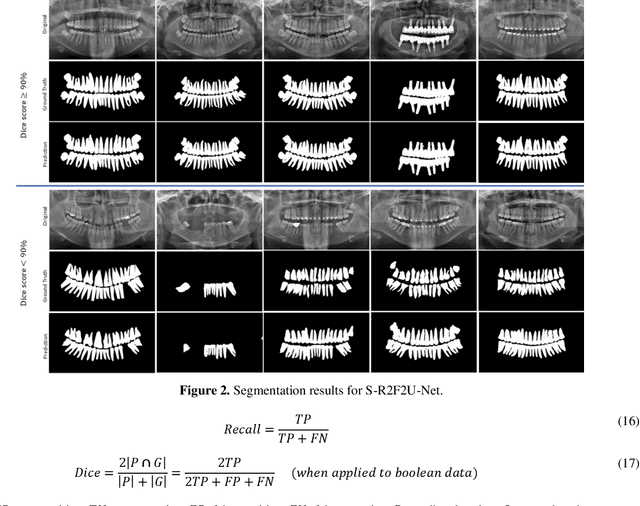
Precision tooth segmentation is crucial in the oral sector because it provides location information for orthodontic therapy, clinical diagnosis, and surgical treatments. In this paper, we investigate residual, recurrent, and attention networks to segment teeth from panoramic dental images. Based on our findings, we suggest three single-stage models: Single Recurrent R2U-Net (S-R2U-Net), Single Recurrent Filter Double R2U-Net (S-R2F2U-Net), and Single Recurrent Attention Enabled Filter Double (S-R2F2-Attn-U-Net). Particularly, S-R2F2U-Net outperforms state-of-the-art models in terms of accuracy and dice score. A hybrid loss function combining the cross-entropy loss and dice loss is used to train the model. In addition, it reduces around 45% of model parameters compared to the R2U-Net model. Models are trained and evaluated on a benchmark dataset containing 1500 dental panoramic X-ray images. S-R2F2U-Net achieves 97.31% of accuracy and 93.26% of dice score, showing superiority over the state-of-the-art methods. Codes are available at https://github.com/mrinal054/teethSeg_sr2f2u-net.git.
Differential Data-Aided Beam Training for RIS-Empowered Multi-Antenna Communications
Apr 27, 2022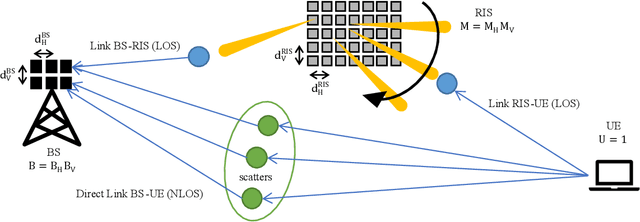
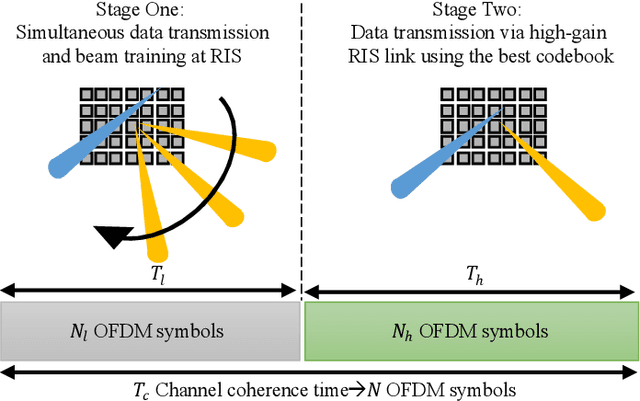
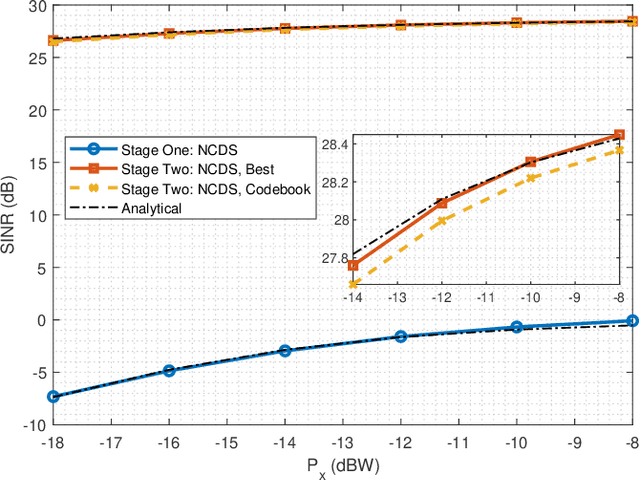
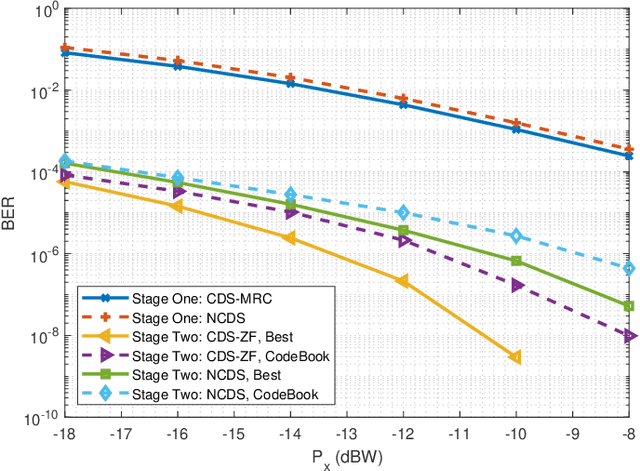
The Reconfigurable Intelligent Surface (RIS) constitutes one of the prominent technologies for the next generation of wireless communications. It is envisioned to enhance the signal coverage in cases when the direct link of the communication is weak. Recently, beam training based on codebook selection is proposed to obtain the optimized phase configuration of the RIS, and then, the data is transmitted and received by using the classical coherent demodulation scheme (CDS). This training approach is able to avoid the large overhead required by the channel sounding process, and it also circumvents complex optimization problems. However, the beam training still requires the transmission of some reference signals to test the different phase configurations of the codebook, which reduces the spectral efficiency. The best codeword is chosen according to the received energy of the reference signals. In this paper, the data transmission and reception based on non-CDS (NCDS) is proposed during the beam training process in order to increase the efficiency of the system, and at the same time, enable the energy measurement for the determination of the best beam for the RIS. After choosing the best codebook, NCDS is still more suitable to transmit information for high mobility scenarios as compared to the classical CDS. Analytical expressions for the Signal-to-Interference and Noise Ratio (SINR) for the non-coherent RIS-empowered system are presented. Moreover, a detailed comparison between the NCDS and CDS in terms of efficiency and complexity is also given. The extensive computer simulation results verify the accuracy of the presented analysis and showcase that the proposed system outperforms the existing solutions.
A Review-aware Graph Contrastive Learning Framework for Recommendation
Apr 27, 2022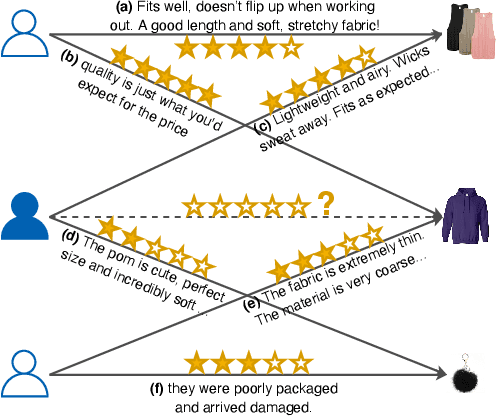
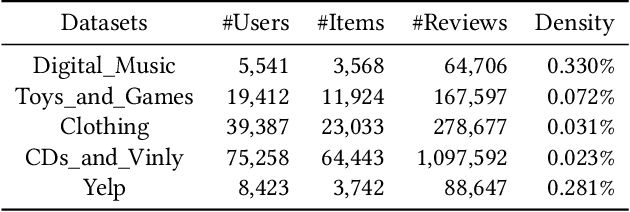
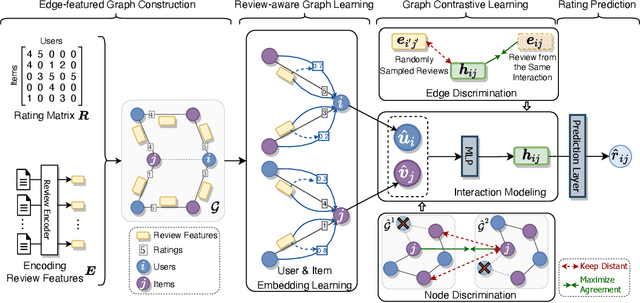
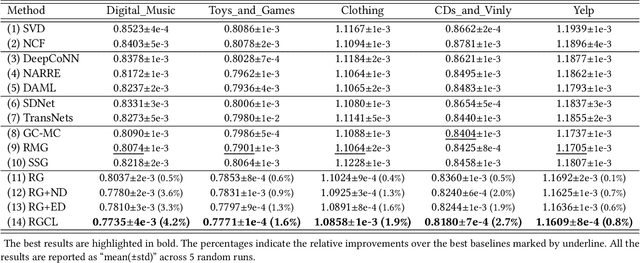
Most modern recommender systems predict users preferences with two components: user and item embedding learning, followed by the user-item interaction modeling. By utilizing the auxiliary review information accompanied with user ratings, many of the existing review-based recommendation models enriched user/item embedding learning ability with historical reviews or better modeled user-item interactions with the help of available user-item target reviews. Though significant progress has been made, we argue that current solutions for review-based recommendation suffer from two drawbacks. First, as review-based recommendation can be naturally formed as a user-item bipartite graph with edge features from corresponding user-item reviews, how to better exploit this unique graph structure for recommendation? Second, while most current models suffer from limited user behaviors, can we exploit the unique self-supervised signals in the review-aware graph to guide two recommendation components better? To this end, in this paper, we propose a novel Review-aware Graph Contrastive Learning (RGCL) framework for review-based recommendation. Specifically, we first construct a review-aware user-item graph with feature-enhanced edges from reviews, where each edge feature is composed of both the user-item rating and the corresponding review semantics. This graph with feature-enhanced edges can help attentively learn each neighbor node weight for user and item representation learning. After that, we design two additional contrastive learning tasks (i.e., Node Discrimination and Edge Discrimination) to provide self-supervised signals for the two components in recommendation process. Finally, extensive experiments over five benchmark datasets demonstrate the superiority of our proposed RGCL compared to the state-of-the-art baselines.
Facial Expression Recognition with Swin Transformer
Mar 25, 2022
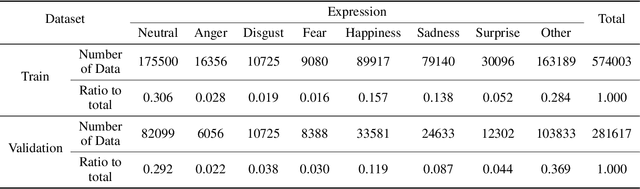

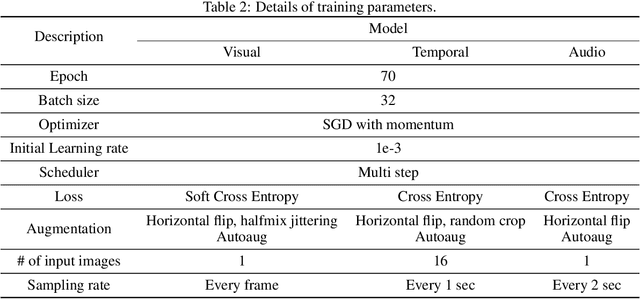
The task of recognizing human facial expressions plays a vital role in various human-related systems, including health care and medical fields. With the recent success of deep learning and the accessibility of a large amount of annotated data, facial expression recognition research has been mature enough to be utilized in real-world scenarios with audio-visual datasets. In this paper, we introduce Swin transformer-based facial expression approach for an in-the-wild audio-visual dataset of the Aff-Wild2 Expression dataset. Specifically, we employ a three-stream network (i.e., Visual stream, Temporal stream, and Audio stream) for the audio-visual videos to fuse the multi-modal information into facial expression recognition. Experimental results on the Aff-Wild2 dataset show the effectiveness of our proposed multi-modal approaches.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021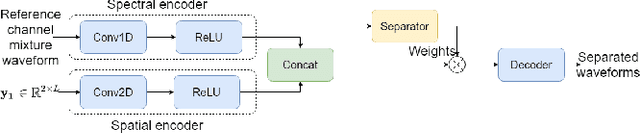
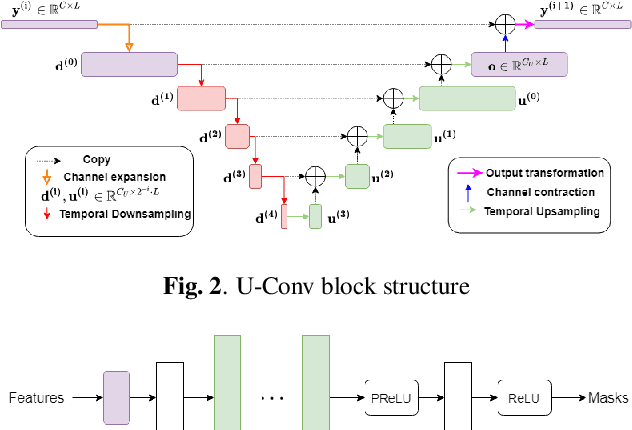
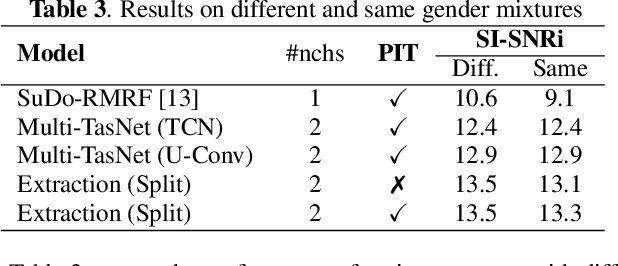

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
Apr 18, 2022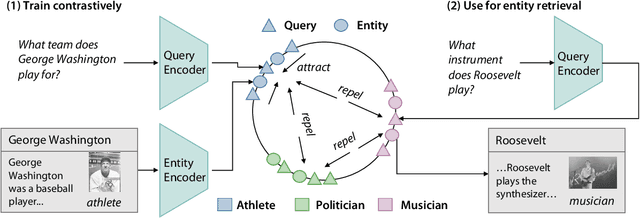
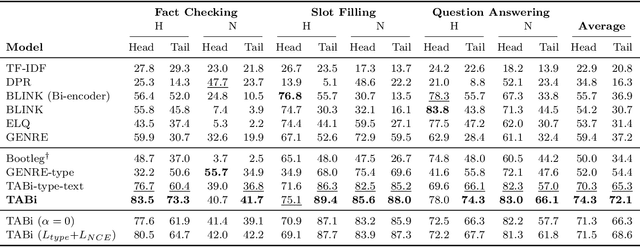

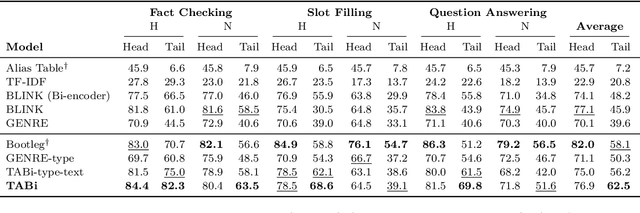
Entity retrieval--retrieving information about entity mentions in a query--is a key step in open-domain tasks, such as question answering or fact checking. However, state-of-the-art entity retrievers struggle to retrieve rare entities for ambiguous mentions due to biases towards popular entities. Incorporating knowledge graph types during training could help overcome popularity biases, but there are several challenges: (1) existing type-based retrieval methods require mention boundaries as input, but open-domain tasks run on unstructured text, (2) type-based methods should not compromise overall performance, and (3) type-based methods should be robust to noisy and missing types. In this work, we introduce TABi, a method to jointly train bi-encoders on knowledge graph types and unstructured text for entity retrieval for open-domain tasks. TABi leverages a type-enforced contrastive loss to encourage entities and queries of similar types to be close in the embedding space. TABi improves retrieval of rare entities on the Ambiguous Entity Retrieval (AmbER) sets, while maintaining strong overall retrieval performance on open-domain tasks in the KILT benchmark compared to state-of-the-art retrievers. TABi is also robust to incomplete type systems, improving rare entity retrieval over baselines with only 5% type coverage of the training dataset. We make our code publicly available at https://github.com/HazyResearch/tabi.
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Feb 16, 2022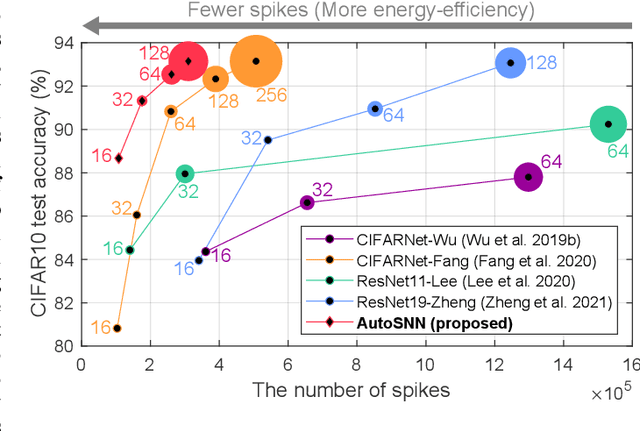
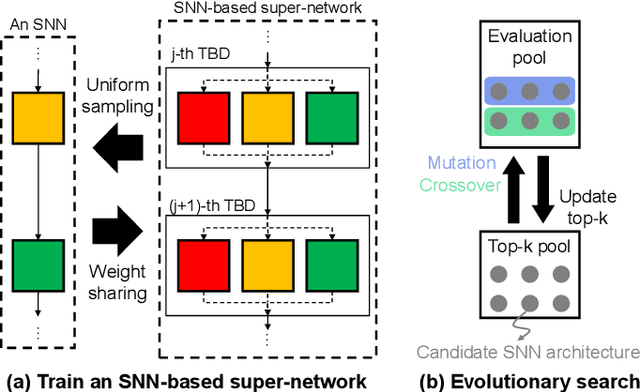
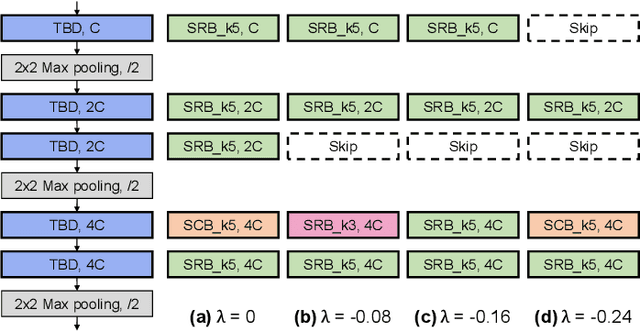
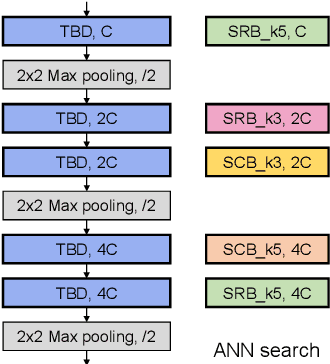
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
Global Readiness of Language Technology for Healthcare: What would it Take to Combat the Next Pandemic?
Apr 06, 2022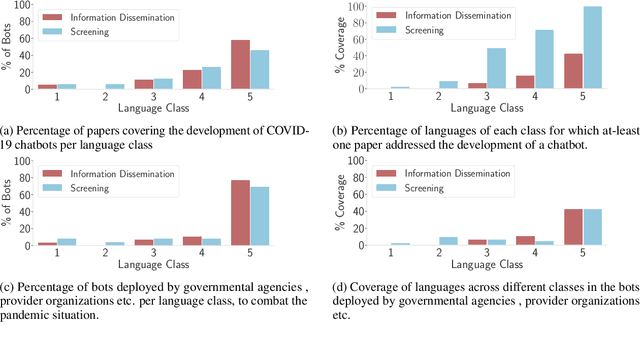
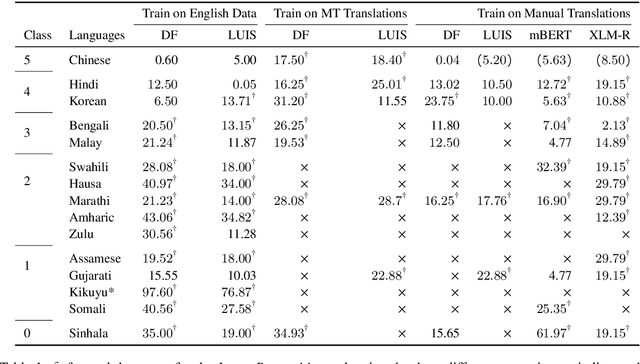
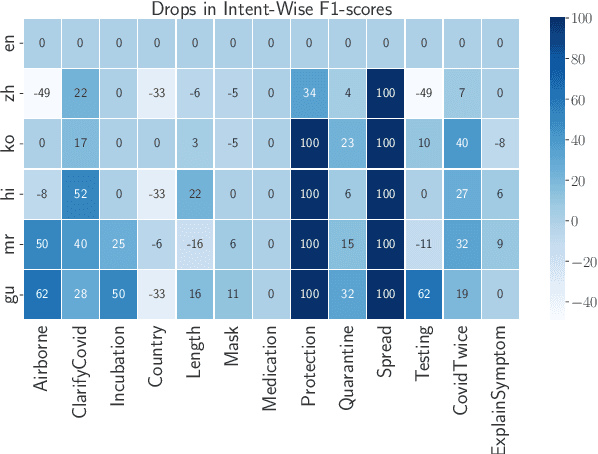

The COVID-19 pandemic has brought out both the best and worst of language technology (LT). On one hand, conversational agents for information dissemination and basic diagnosis have seen widespread use, and arguably, had an important role in combating the pandemic. On the other hand, it has also become clear that such technologies are readily available for a handful of languages, and the vast majority of the global south is completely bereft of these benefits. What is the state of LT, especially conversational agents, for healthcare across the world's languages? And, what would it take to ensure global readiness of LT before the next pandemic? In this paper, we try to answer these questions through survey of existing literature and resources, as well as through a rapid chatbot building exercise for 15 Asian and African languages with varying amount of resource-availability. The study confirms the pitiful state of LT even for languages with large speaker bases, such as Sinhala and Hausa, and identifies the gaps that could help us prioritize research and investment strategies in LT for healthcare.