 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Focus of Attention Improves Information Transfer in Visual Features
Jun 16, 2020

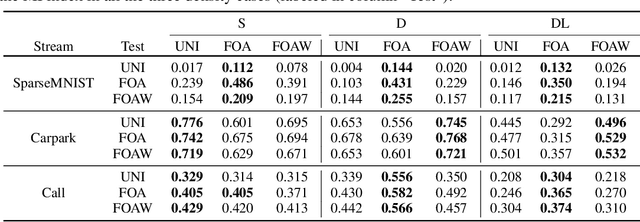

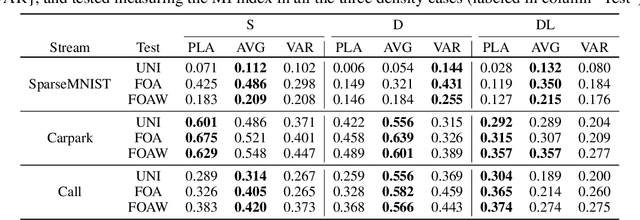
Unsupervised learning from continuous visual streams is a challenging problem that cannot be naturally and efficiently managed in the classic batch-mode setting of computation. The information stream must be carefully processed accordingly to an appropriate spatio-temporal distribution of the visual data, while most approaches of learning commonly assume uniform probability density. In this paper we focus on unsupervised learning for transferring visual information in a truly online setting by using a computational model that is inspired to the principle of least action in physics. The maximization of the mutual information is carried out by a temporal process which yields online estimation of the entropy terms. The model, which is based on second-order differential equations, maximizes the information transfer from the input to a discrete space of symbols related to the visual features of the input, whose computation is supported by hidden neurons. In order to better structure the input probability distribution, we use a human-like focus of attention model that, coherently with the information maximization model, is also based on second-order differential equations. We provide experimental results to support the theory by showing that the spatio-temporal filtering induced by the focus of attention allows the system to globally transfer more information from the input stream over the focused areas and, in some contexts, over the whole frames with respect to the unfiltered case that yields uniform probability distributions.
TASTEset -- Recipe Dataset and Food Entities Recognition Benchmark
Apr 16, 2022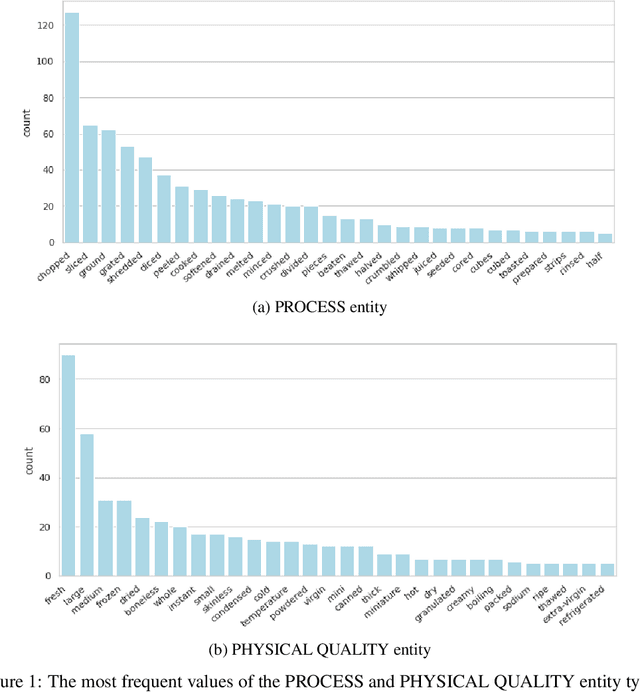
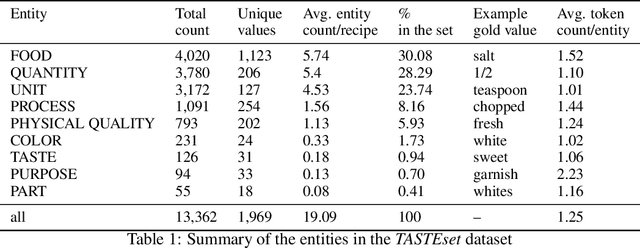
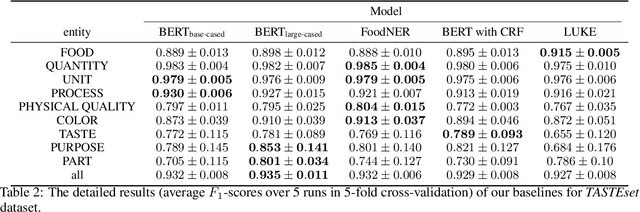
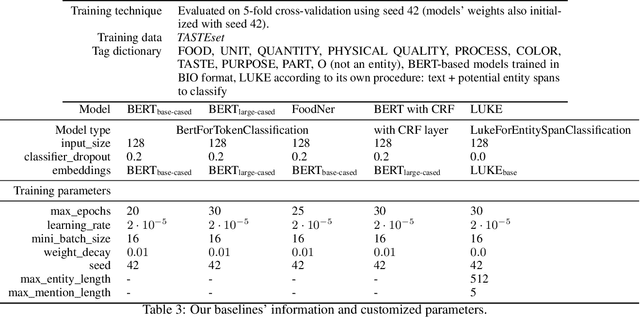
Food Computing is currently a fast-growing field of research. Natural language processing (NLP) is also increasingly essential in this field, especially for recognising food entities. However, there are still only a few well-defined tasks that serve as benchmarks for solutions in this area. We introduce a new dataset -- called \textit{TASTEset} -- to bridge this gap. In this dataset, Named Entity Recognition (NER) models are expected to find or infer various types of entities helpful in processing recipes, e.g.~food products, quantities and their units, names of cooking processes, physical quality of ingredients, their purpose, taste. The dataset consists of 700 recipes with more than 13,000 entities to extract. We provide a few state-of-the-art baselines of named entity recognition models, which show that our dataset poses a solid challenge to existing models. The best model achieved, on average, 0.95 $F_1$ score, depending on the entity type -- from 0.781 to 0.982. We share the dataset and the task to encourage progress on more in-depth and complex information extraction from recipes.
Active Visual Information Gathering for Vision-Language Navigation
Jul 23, 2020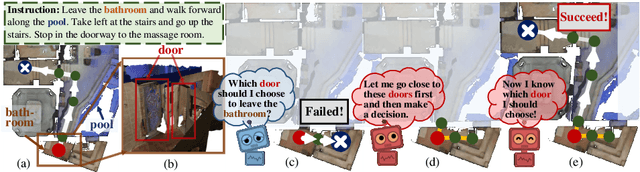
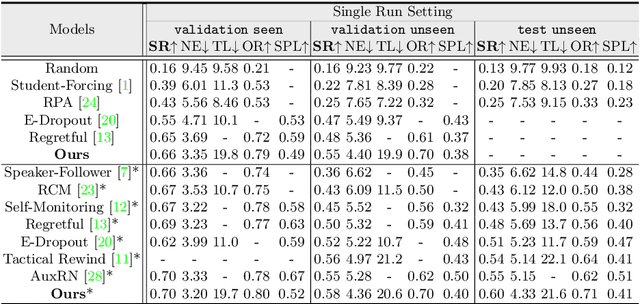
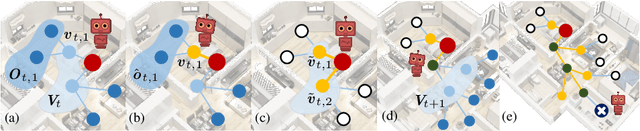
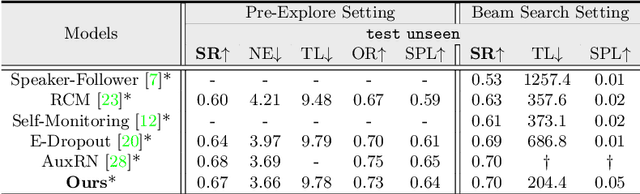
Vision-language navigation (VLN) is the task of entailing an agent to carry out navigational instructions inside photo-realistic environments. One of the key challenges in VLN is how to conduct a robust navigation by mitigating the uncertainty caused by ambiguous instructions and insufficient observation of the environment. Agents trained by current approaches typically suffer from this and would consequently struggle to avoid random and inefficient actions at every step. In contrast, when humans face such a challenge, they can still maintain robust navigation by actively exploring the surroundings to gather more information and thus make more confident navigation decisions. This work draws inspiration from human navigation behavior and endows an agent with an active information gathering ability for a more intelligent vision-language navigation policy. To achieve this, we propose an end-to-end framework for learning an exploration policy that decides i) when and where to explore, ii) what information is worth gathering during exploration, and iii) how to adjust the navigation decision after the exploration. The experimental results show promising exploration strategies emerged from training, which leads to significant boost in navigation performance. On the R2R challenge leaderboard, our agent gets promising results all three VLN settings, i.e., single run, pre-exploration, and beam search.
Effectively Using Long and Short Sessions for Multi-Session-based Recommendations
May 09, 2022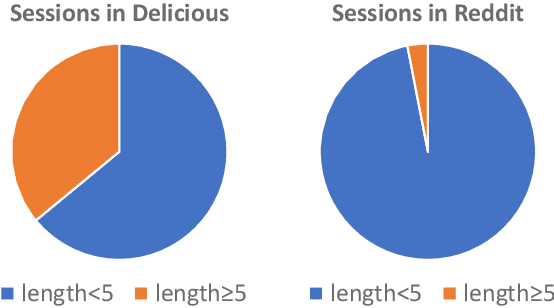
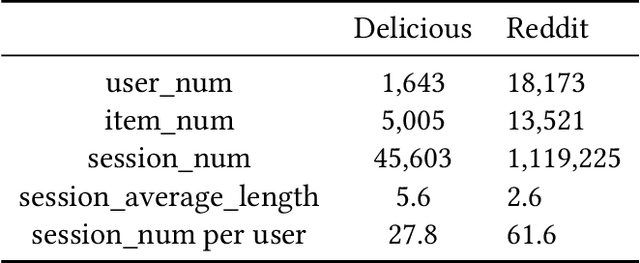
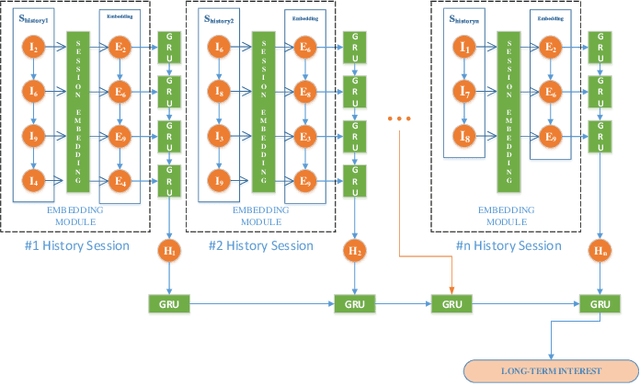
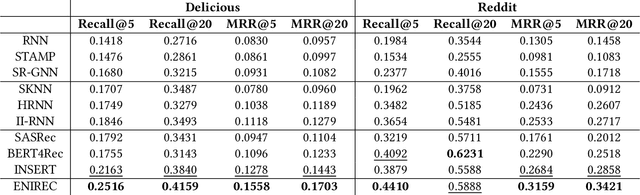
It is not accurate to make recommendations only based one single current session. Therefore, multi-session-based recommendation(MSBR) is a solution for the problem. Compared with the previous MSBR models, we have made three improvements in this paper. First, the previous work choose to use all the history sessions of the user and/or of his similar users. When the user's current interest changes greatly from the past, most of these sessions can only have negative impacts. Therefore, we select a large number of randomly chosen sessions from the dataset as candidate sessions to avoid over depending on history data. Then we only choose to use the most similar sessions to get the most useful information while reduce the noise caused by dissimilar sessions. Second, in real-world datasets, short sessions account for a large proportion. The RNN often used in previous work is not suitable to process short sessions, because RNN only focuses on the sequential relationship, which we find is not the only relationship between items in short sessions. So, we designed a more suitable method named GAFE based on attention to process short sessions. Third, Although there are few long sessions, they can not be ignored. Not like previous models, which simply process long sessions in the same way as short sessions, we propose LSIS, which can split the interest of long sessions, to make better use of long sessions. Finally, to help recommendations, we also have considered users' long-term interests captured by a multi-layer GRU. Considering the four points above, we built the model ENIREC. Experiments on two real-world datasets show that the comprehensive performance of ENIREC is better than other existing models.
VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
Oct 07, 2020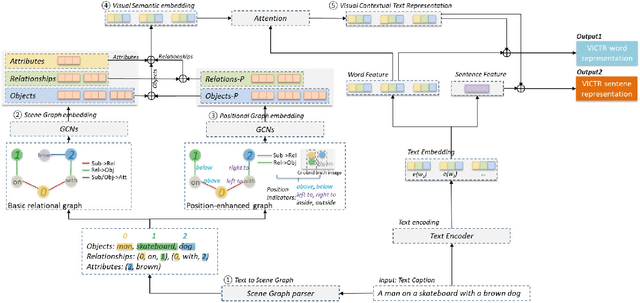
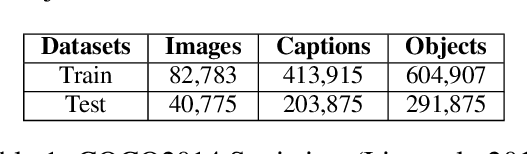
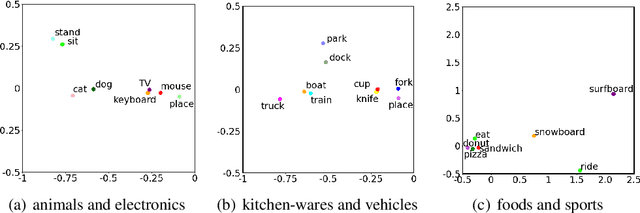
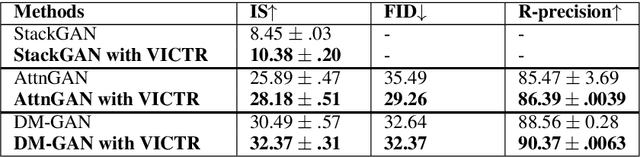
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mar 22, 2022
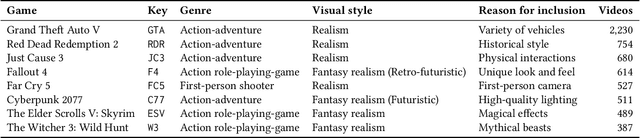

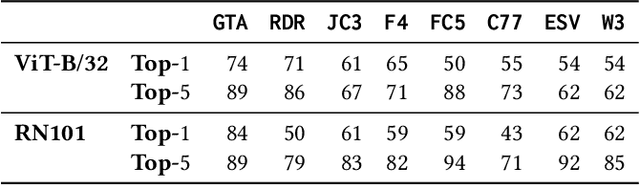
Gameplay videos contain rich information about how players interact with the game and how the game responds. Sharing gameplay videos on social media platforms, such as Reddit, has become a common practice for many players. Often, players will share gameplay videos that showcase video game bugs. Such gameplay videos are software artifacts that can be utilized for game testing, as they provide insight for bug analysis. Although large repositories of gameplay videos exist, parsing and mining them in an effective and structured fashion has still remained a big challenge. In this paper, we propose a search method that accepts any English text query as input to retrieve relevant videos from large repositories of gameplay videos. Our approach does not rely on any external information (such as video metadata); it works solely based on the content of the video. By leveraging the zero-shot transfer capabilities of the Contrastive Language-Image Pre-Training (CLIP) model, our approach does not require any data labeling or training. To evaluate our approach, we present the $\texttt{GamePhysics}$ dataset consisting of 26,954 videos from 1,873 games, that were collected from the GamePhysics section on the Reddit website. Our approach shows promising results in our extensive analysis of simple queries, compound queries, and bug queries, indicating that our approach is useful for object and event detection in gameplay videos. An example application of our approach is as a gameplay video search engine to aid in reproducing video game bugs. Please visit the following link for the code and the data: https://asgaardlab.github.io/CLIPxGamePhysics/
Quality Metric Guided Portrait Line Drawing Generation from Unpaired Training Data
Feb 08, 2022
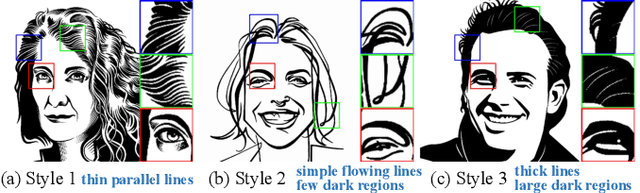
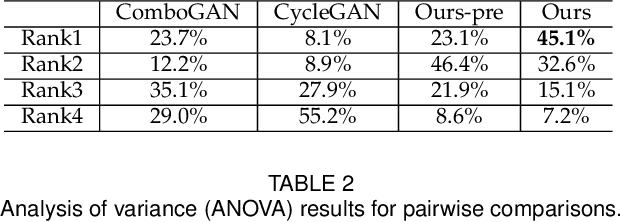

Face portrait line drawing is a unique style of art which is highly abstract and expressive. However, due to its high semantic constraints, many existing methods learn to generate portrait drawings using paired training data, which is costly and time-consuming to obtain. In this paper, we propose a novel method to automatically transform face photos to portrait drawings using unpaired training data with two new features; i.e., our method can (1) learn to generate high quality portrait drawings in multiple styles using a single network and (2) generate portrait drawings in a "new style" unseen in the training data. To achieve these benefits, we (1) propose a novel quality metric for portrait drawings which is learned from human perception, and (2) introduce a quality loss to guide the network toward generating better looking portrait drawings. We observe that existing unpaired translation methods such as CycleGAN tend to embed invisible reconstruction information indiscriminately in the whole drawings due to significant information imbalance between the photo and portrait drawing domains, which leads to important facial features missing. To address this problem, we propose a novel asymmetric cycle mapping that enforces the reconstruction information to be visible and only embedded in the selected facial regions. Along with localized discriminators for important facial regions, our method well preserves all important facial features in the generated drawings. Generator dissection further explains that our model learns to incorporate face semantic information during drawing generation. Extensive experiments including a user study show that our model outperforms state-of-the-art methods.
Traffic Context Aware Data Augmentation for Rare Object Detection in Autonomous Driving
May 01, 2022
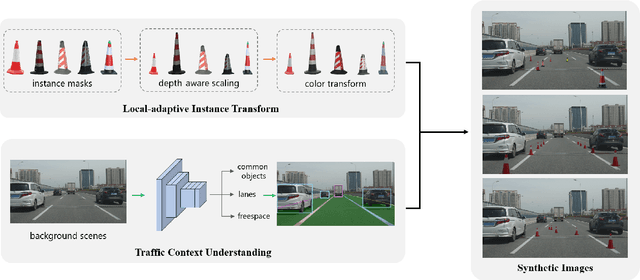


Detection of rare objects (e.g., traffic cones, traffic barrels and traffic warning triangles) is an important perception task to improve the safety of autonomous driving. Training of such models typically requires a large number of annotated data which is expensive and time consuming to obtain. To address the above problem, an emerging approach is to apply data augmentation to automatically generate cost-free training samples. In this work, we propose a systematic study on simple Copy-Paste data augmentation for rare object detection in autonomous driving. Specifically, local adaptive instance-level image transformation is introduced to generate realistic rare object masks from source domain to the target domain. Moreover, traffic scene context is utilized to guide the placement of masks of rare objects. To this end, our data augmentation generates training data with high quality and realistic characteristics by leveraging both local and global consistency. In addition, we build a new dataset named NM10k consisting 10k training images, 4k validation images and the corresponding labels with a diverse range of scenarios in autonomous driving. Experiments on NM10k show that our method achieves promising results on rare object detection. We also present a thorough study to illustrate the effectiveness of our local-adaptive and global constraints based Copy-Paste data augmentation for rare object detection. The data, development kit and more information of NM10k dataset are available online at: \url{https://nullmax-vision.github.io}.
2D LiDAR and Camera Fusion Using Motion Cues for Indoor Layout Estimation
Apr 24, 2022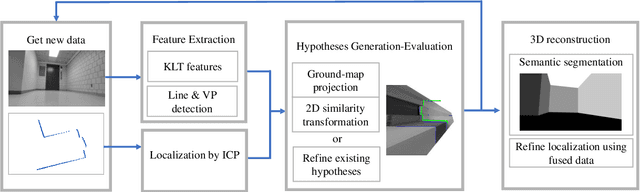
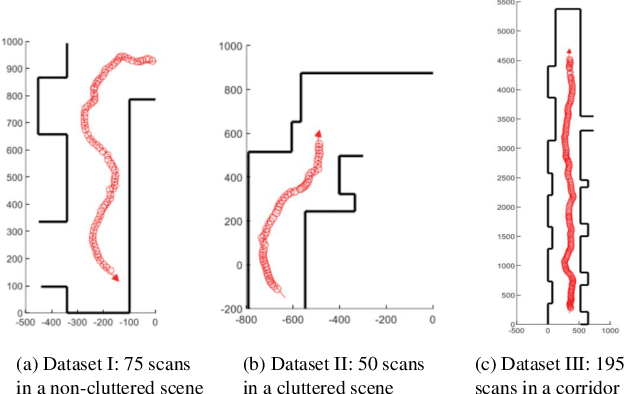


This paper presents a novel indoor layout estimation system based on the fusion of 2D LiDAR and intensity camera data. A ground robot explores an indoor space with a single floor and vertical walls, and collects a sequence of intensity images and 2D LiDAR datasets. The LiDAR provides accurate depth information, while the camera captures high-resolution data for semantic interpretation. The alignment of sensor outputs and image segmentation are computed jointly by aligning LiDAR points, as samples of the room contour, to ground-wall boundaries in the images. The alignment problem is decoupled into a top-down view projection and a 2D similarity transformation estimation, which can be solved according to the vertical vanishing point and motion of two sensors. The recursive random sample consensus algorithm is implemented to generate, evaluate and optimize multiple hypotheses with the sequential measurements. The system allows jointly analyzing the geometric interpretation from different sensors without offline calibration. The ambiguity in images for ground-wall boundary extraction is removed with the assistance of LiDAR observations, which improves the accuracy of semantic segmentation. The localization and mapping is refined using the fused data, which enables the system to work reliably in scenes with low texture or low geometric features.
LSTM-Based Distributed Conditional Generative Adversarial Network For Data-Driven 5G-Enabled Maritime UAV Communications
May 09, 2022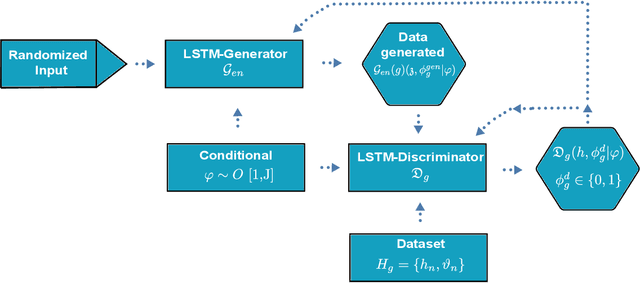
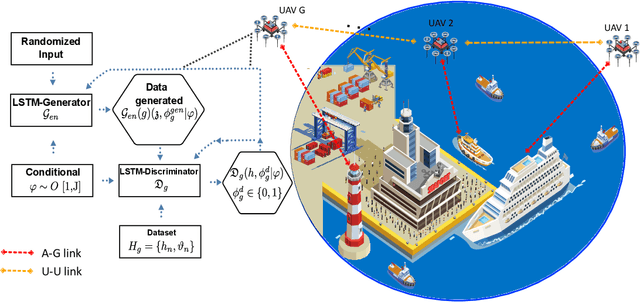
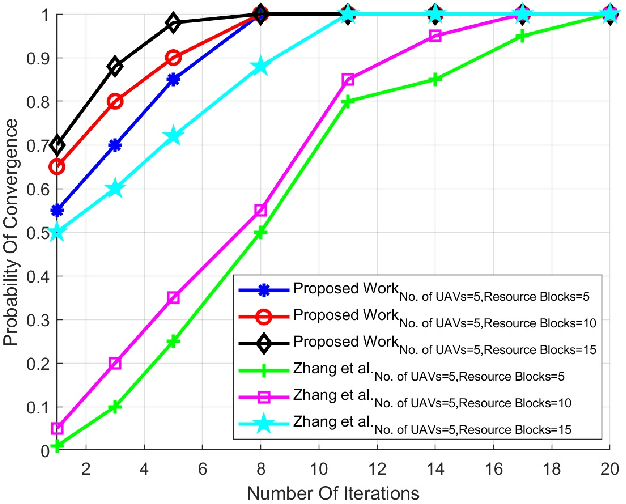
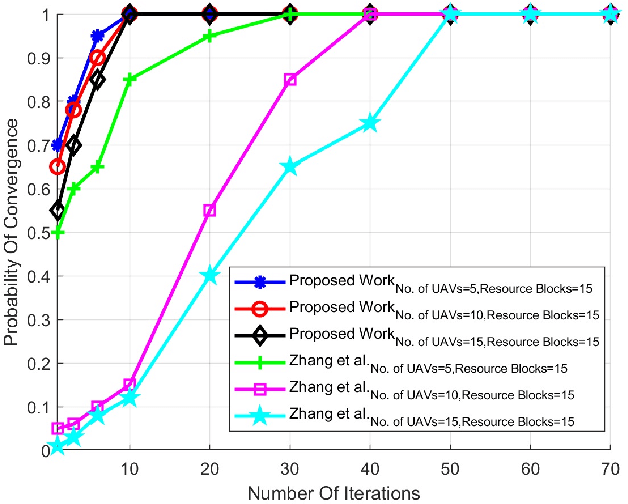
5G enabled maritime unmanned aerial vehicle (UAV) communication is one of the important applications of 5G wireless network which requires minimum latency and higher reliability to support mission-critical applications. Therefore, lossless reliable communication with a high data rate is the key requirement in modern wireless communication systems. These all factors highly depend upon channel conditions. In this work, a channel model is proposed for air-to-surface link exploiting millimeter wave (mmWave) for 5G enabled maritime unmanned aerial vehicle (UAV) communication. Firstly, we will present the formulated channel estimation method which directly aims to adopt channel state information (CSI) of mmWave from the channel model inculcated by UAV operating within the Long Short Term Memory (LSTM)-Distributed Conditional generative adversarial network (DCGAN) i.e. (LSTM-DCGAN) for each beamforming direction. Secondly, to enhance the applications for the proposed trained channel model for the spatial domain, we have designed an LSTM-DCGAN based UAV network, where each one will learn mmWave CSI for all the distributions. Lastly, we have categorized the most favorable LSTM-DCGAN training method and emanated certain conditions for our UAV network to increase the channel model learning rate. Simulation results have shown that the proposed LSTM-DCGAN based network is vigorous to the error generated through local training. A detailed comparison has been done with the other available state-of-the-art CGAN network architectures i.e. stand-alone CGAN (without CSI sharing), Simple CGAN (with CSI sharing), multi-discriminator CGAN, federated learning CGAN and DCGAN. Simulation results have shown that the proposed LSTM-DCGAN structure demonstrates higher accuracy during the learning process and attained more data rate for downlink transmission as compared to the previous state of artworks.