 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-modal Memory Networks for Radiology Report Generation
Apr 28, 2022
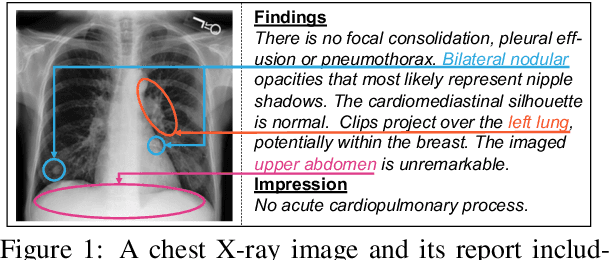
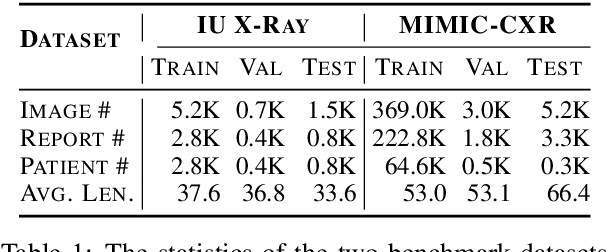
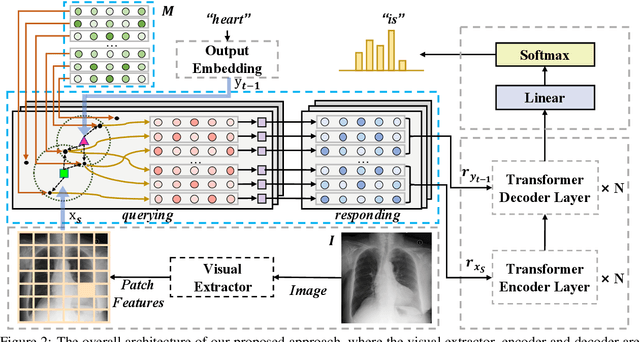
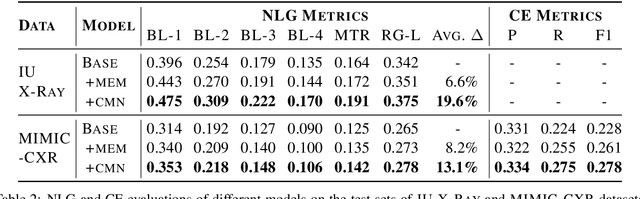
Medical imaging plays a significant role in clinical practice of medical diagnosis, where the text reports of the images are essential in understanding them and facilitating later treatments. By generating the reports automatically, it is beneficial to help lighten the burden of radiologists and significantly promote clinical automation, which already attracts much attention in applying artificial intelligence to medical domain. Previous studies mainly follow the encoder-decoder paradigm and focus on the aspect of text generation, with few studies considering the importance of cross-modal mappings and explicitly exploit such mappings to facilitate radiology report generation. In this paper, we propose a cross-modal memory networks (CMN) to enhance the encoder-decoder framework for radiology report generation, where a shared memory is designed to record the alignment between images and texts so as to facilitate the interaction and generation across modalities. Experimental results illustrate the effectiveness of our proposed model, where state-of-the-art performance is achieved on two widely used benchmark datasets, i.e., IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to better align information from radiology images and texts so as to help generating more accurate reports in terms of clinical indicators.
SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism
Jan 20, 2021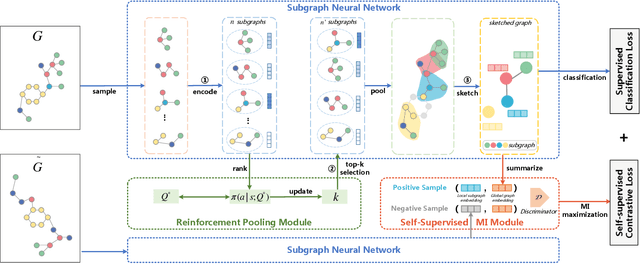
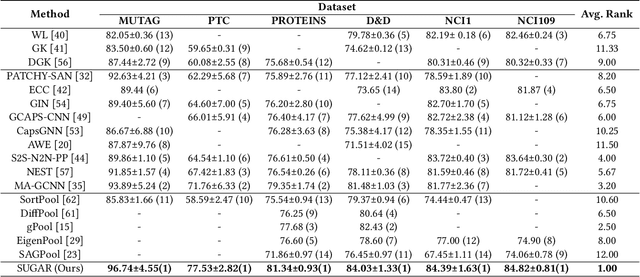
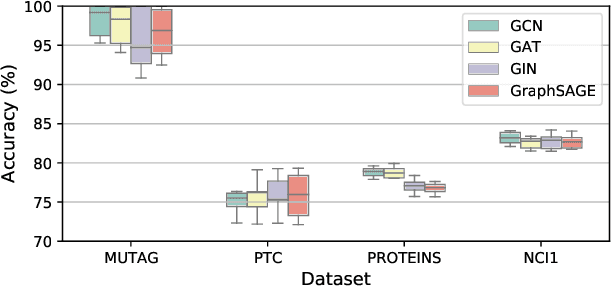
Graph representation learning has attracted increasing research attention. However, most existing studies fuse all structural features and node attributes to provide an overarching view of graphs, neglecting finer substructures' semantics, and suffering from interpretation enigmas. This paper presents a novel hierarchical subgraph-level selection and embedding based graph neural network for graph classification, namely SUGAR, to learn more discriminative subgraph representations and respond in an explanatory way. SUGAR reconstructs a sketched graph by extracting striking subgraphs as the representative part of the original graph to reveal subgraph-level patterns. To adaptively select striking subgraphs without prior knowledge, we develop a reinforcement pooling mechanism, which improves the generalization ability of the model. To differentiate subgraph representations among graphs, we present a self-supervised mutual information mechanism to encourage subgraph embedding to be mindful of the global graph structural properties by maximizing their mutual information. Extensive experiments on six typical bioinformatics datasets demonstrate a significant and consistent improvement in model quality with competitive performance and interpretability.
Context-aware Automatic Music Transcription
Mar 30, 2022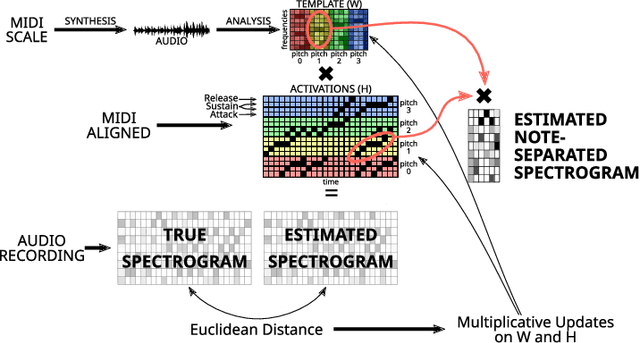
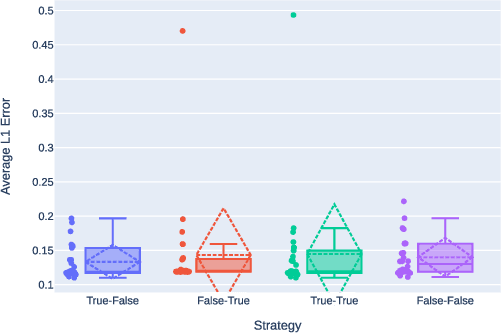
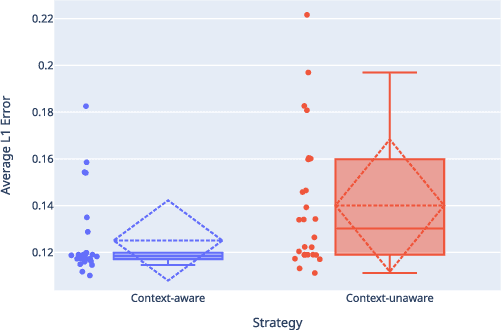
This paper presents an Automatic Music Transcription system that incorporates context-related information. Motivated by the state-of-art psychological research, we propose a methodology boosting the accuracy of AMT systems by modeling the adaptations that performers apply to successfully convey their interpretation in any acoustical context. In this work, we show that exploiting the knowledge of the source acoustical context allows reducing the error related to the inference of MIDI velocity. The proposed model structure first extracts the interpretation features and then applies the modeled performer adaptations. Interestingly, such a methodology is extensible in a straightforward way since only slight efforts are required to train completely context-aware AMT models.
Locality Sensitive Hashing for Structured Data: A Survey
Apr 24, 2022
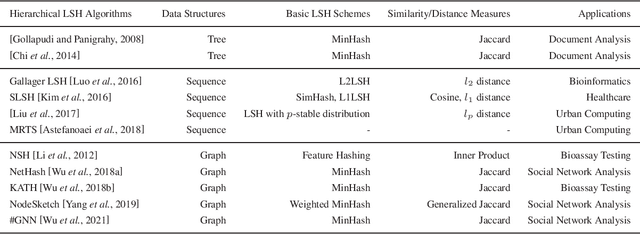

Data similarity (or distance) computation is a fundamental research topic which fosters a variety of similarity-based machine learning and data mining applications. In big data analytics, it is impractical to compute the exact similarity of data instances due to high computational cost. To this end, the Locality Sensitive Hashing (LSH) technique has been proposed to provide accurate estimators for various similarity measures between sets or vectors in an efficient manner without the learning process. Structured data (e.g., sequences, trees and graphs), which are composed of elements and relations between the elements, are commonly seen in the real world, but the traditional LSH algorithms cannot preserve the structure information represented as relations between elements. In order to conquer the issue, researchers have been devoted to the family of the hierarchical LSH algorithms. In this paper, we explore the present progress of the research into hierarchical LSH from the following perspectives: 1) Data structures, where we review various hierarchical LSH algorithms for three typical data structures and uncover their inherent connections; 2) Applications, where we review the hierarchical LSH algorithms in multiple application scenarios; 3) Challenges, where we discuss some potential challenges as future directions.
Fine-grained Information Status Classification Using Discourse Context-Aware BERT
Oct 26, 2020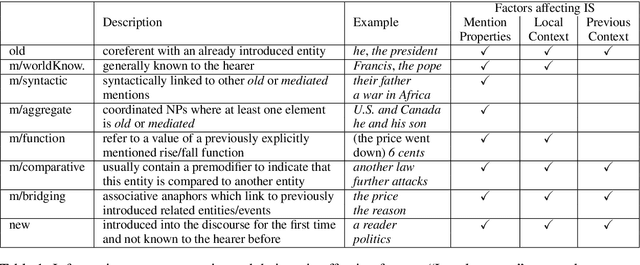
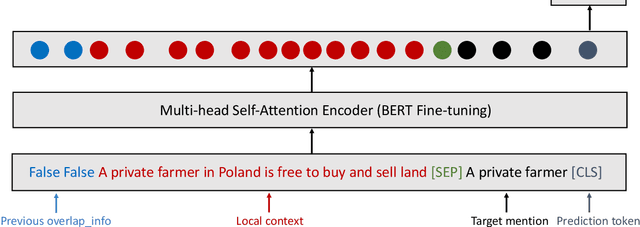
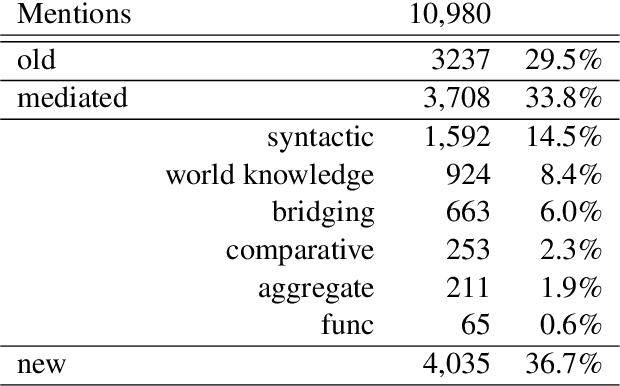
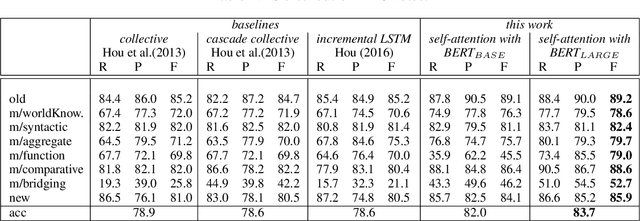
Previous work on bridging anaphora recognition (Hou et al., 2013a) casts the problem as a subtask of learning fine-grained information status (IS). However, these systems heavily depend on many hand-crafted linguistic features. In this paper, we propose a simple discourse context-aware BERT model for fine-grained IS classification. On the ISNotes corpus (Markert et al., 2012), our model achieves new state-of-the-art performance on fine-grained IS classification, obtaining a 4.8 absolute overall accuracy improvement compared to Hou et al. (2013a). More importantly, we also show an improvement of 10.5 F1 points for bridging anaphora recognition without using any complex hand-crafted semantic features designed for capturing the bridging phenomenon. We further analyze the trained model and find that the most attended signals for each IS category correspond well to linguistic notions of information status.
Guiding Attention using Partial-Order Relationships for Image Captioning
Apr 15, 2022
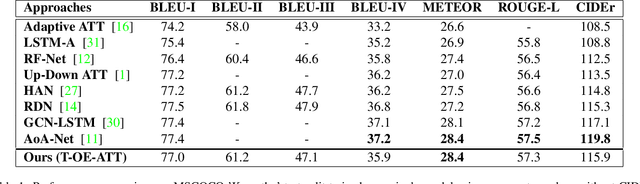
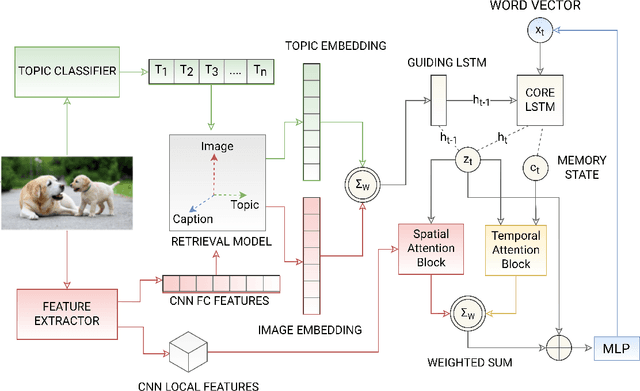
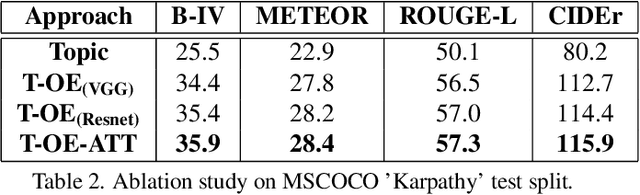
The use of attention models for automated image captioning has enabled many systems to produce accurate and meaningful descriptions for images. Over the years, many novel approaches have been proposed to enhance the attention process using different feature representations. In this paper, we extend this approach by creating a guided attention network mechanism, that exploits the relationship between the visual scene and text-descriptions using spatial features from the image, high-level information from the topics, and temporal context from caption generation, which are embedded together in an ordered embedding space. A pairwise ranking objective is used for training this embedding space which allows similar images, topics and captions in the shared semantic space to maintain a partial order in the visual-semantic hierarchy and hence, helps the model to produce more visually accurate captions. The experimental results based on MSCOCO dataset shows the competitiveness of our approach, with many state-of-the-art models on various evaluation metrics.
Mutual Information for Explainable Deep Learning of Multiscale Systems
Sep 07, 2020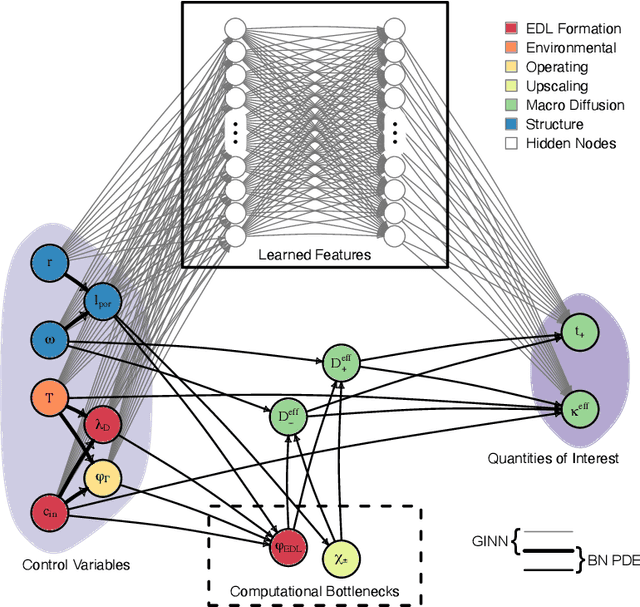
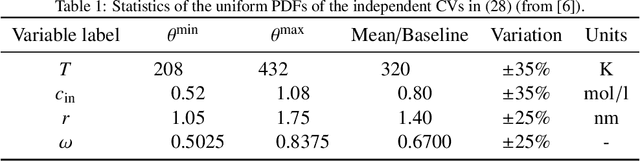
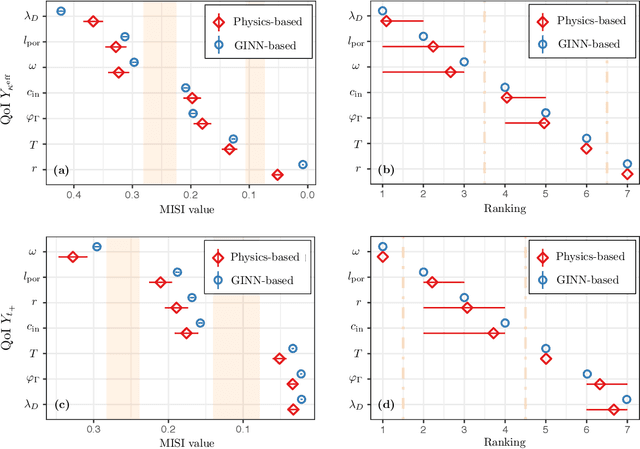
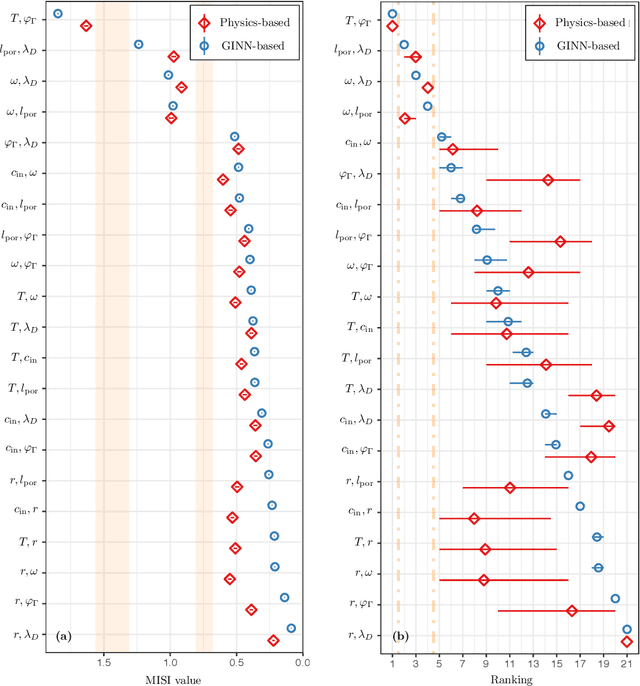
Timely completion of design cycles for multiscale and multiphysics systems ranging from consumer electronics to hypersonic vehicles relies on rapid simulation-based prototyping. The latter typically involves high-dimensional spaces of possibly correlated control variables (CVs) and quantities of interest (QoIs) with non-Gaussian and/or multimodal distributions. We develop a model-agnostic, moment-independent global sensitivity analysis (GSA) that relies on differential mutual information to rank the effects of CVs on QoIs. Large amounts of data, which are necessary to rank CVs with confidence, are cheaply generated by a deep neural network (DNN) surrogate model of the underlying process. The DNN predictions are made explainable by the GSA so that the DNN can be deployed to close design loops. Our information-theoretic framework is compatible with a wide variety of black-box models. Its application to multiscale supercapacitor design demonstrates that the CV rankings facilitated by a domain-aware Graph-Informed Neural Network are better resolved than their counterparts obtained with a physics-based model for a fixed computational budget. Consequently, our information-theoretic GSA provides an "outer loop" for accelerated product design by identifying the most and least sensitive input directions and performing subsequent optimization over appropriately reduced parameter subspaces.
Estimation of Consistent Time Delays in Subsample via Auxiliary-Function-Based Iterative Updates
Mar 23, 2022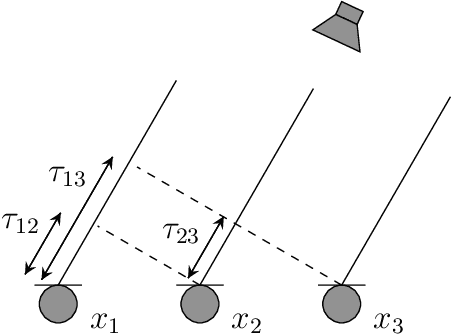
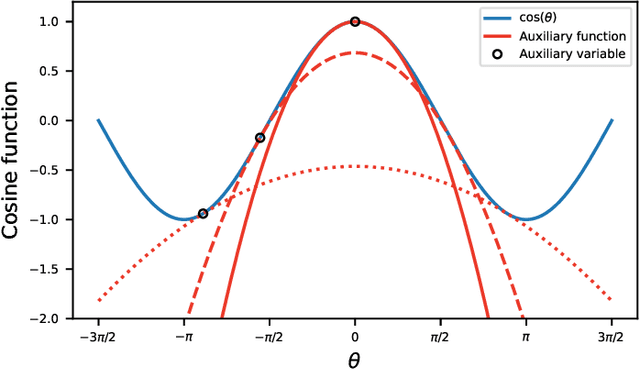
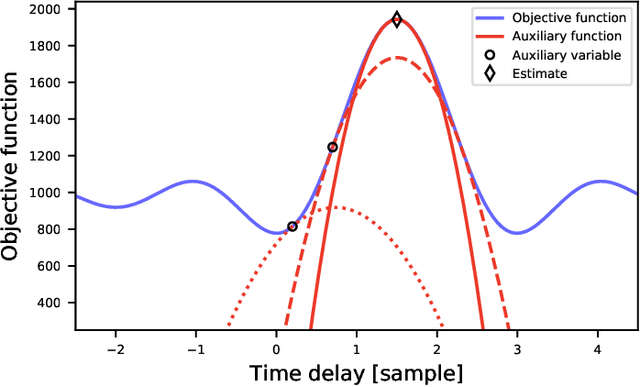
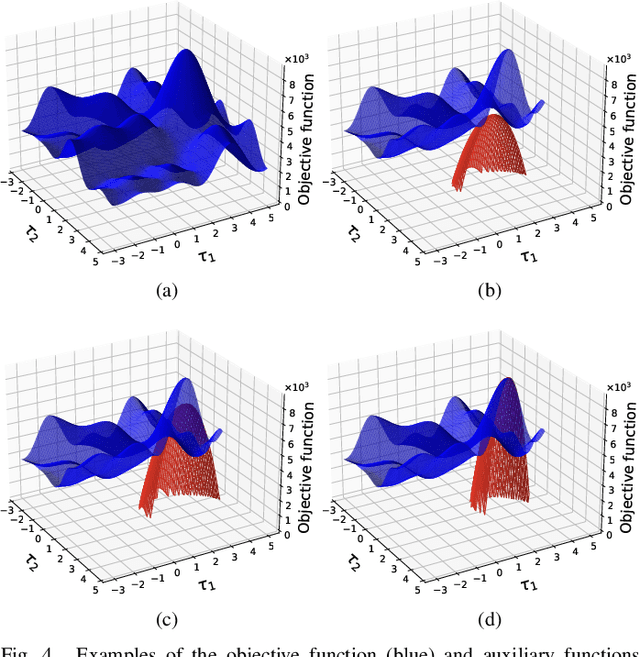
In this paper, we propose a new algorithm for the estimation of multiple time delays (TDs). Since a TD is a fundamental spatial cue for sensor array signal processing techniques, many methods for estimating it have been studied. Most of them, including generalized cross correlation (CC)-based methods, focus on how to estimate a TD between two sensors. These methods can then be easily adapted for multiple TDs by applying them to every pair of a reference sensor and another one. However, these pairwise methods can use only the partial information obtained by the selected sensors, resulting in inconsistent TD estimates and limited estimation accuracy. In contrast, we propose joint optimization of entire TD parameters, where spatial information obtained from all sensors is taken into account. We also introduce a consistent constraint regarding TD parameters to the observation model. We then consider a multidimensional CC (MCC) as the objective function, which is derived on the basis of maximum likelihood estimation. To maximize the MCC, which is a nonconvex function, we derive the auxiliary function for the MCC and design efficient update rules. We additionally estimate the amplitudes of the transfer functions for supporting the TD estimation, where we maximize the Rayleigh quotient under the non-negative constraint. We experimentally analyze essential features of the proposed method and evaluate its effectiveness in TD estimation. Code will be available at https://github.com/onolab-tmu/AuxTDE.
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
Apr 27, 2022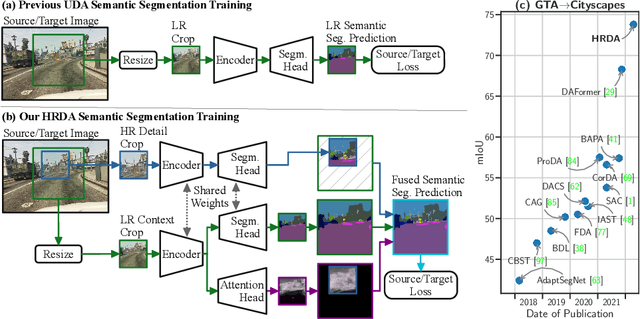
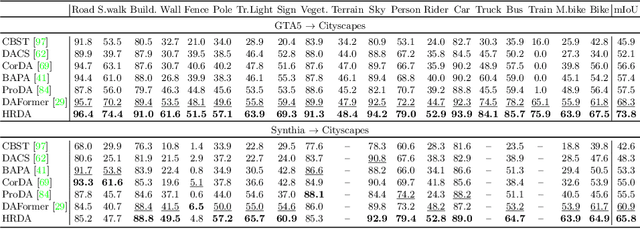
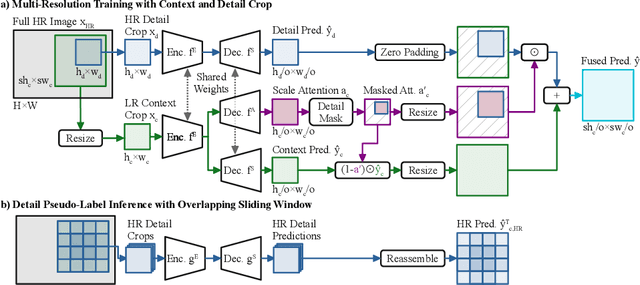
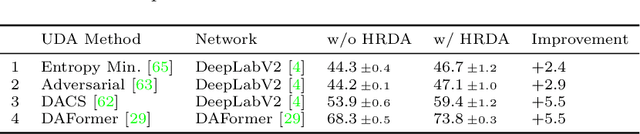
Unsupervised domain adaptation (UDA) aims to adapt a model trained on the source domain (e.g. synthetic data) to the target domain (e.g. real-world data) without requiring further annotations on the target domain. This work focuses on UDA for semantic segmentation as real-world pixel-wise annotations are particularly expensive to acquire. As UDA methods for semantic segmentation are usually GPU memory intensive, most previous methods operate only on downscaled images. We question this design as low-resolution predictions often fail to preserve fine details. The alternative of training with random crops of high-resolution images alleviates this problem but falls short in capturing long-range, domain-robust context information. Therefore, we propose HRDA, a multi-resolution training approach for UDA, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention, while maintaining a manageable GPU memory footprint. HRDA enables adapting small objects and preserving fine segmentation details. It significantly improves the state-of-the-art performance by 5.5 mIoU for GTA-to-Cityscapes and 4.9 mIoU for Synthia-to-Cityscapes, resulting in unprecedented 73.8 and 65.8 mIoU, respectively. The implementation is available at https://github.com/lhoyer/HRDA.
Self-Supervised Learning of Object Parts for Semantic Segmentation
Apr 27, 2022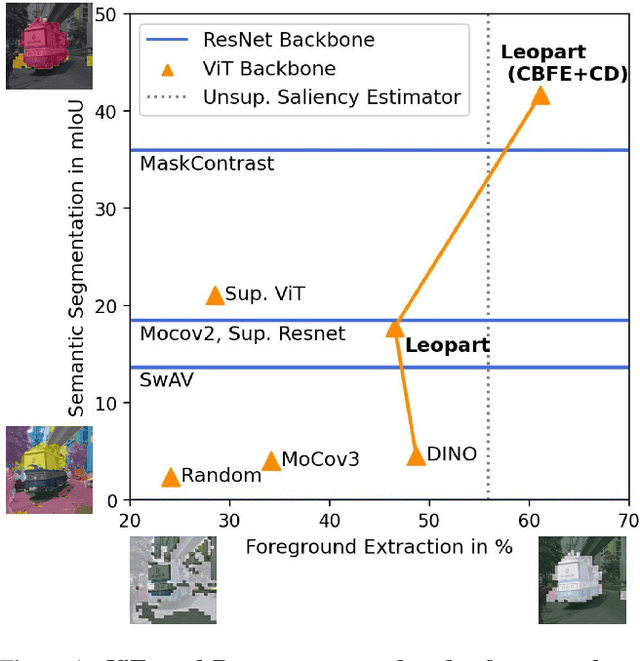
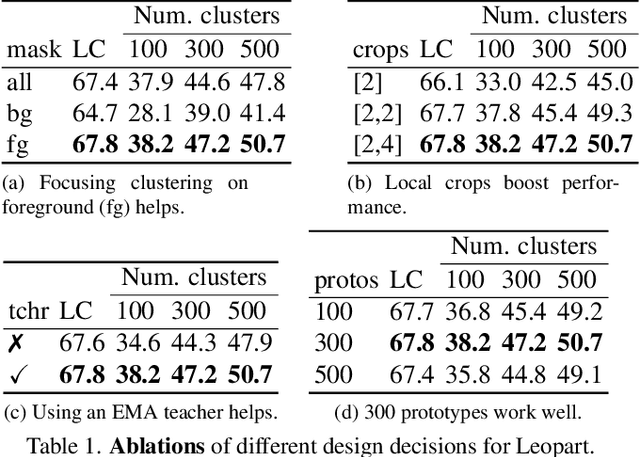
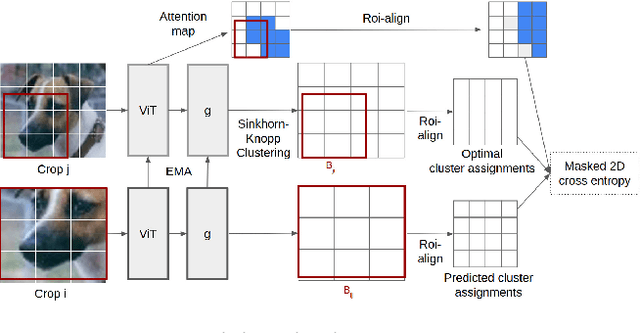
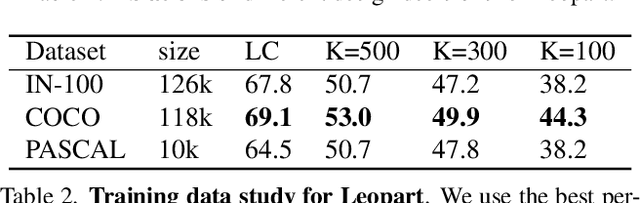
Progress in self-supervised learning has brought strong general image representation learning methods. Yet so far, it has mostly focused on image-level learning. In turn, tasks such as unsupervised image segmentation have not benefited from this trend as they require spatially-diverse representations. However, learning dense representations is challenging, as in the unsupervised context it is not clear how to guide the model to learn representations that correspond to various potential object categories. In this paper, we argue that self-supervised learning of object parts is a solution to this issue. Object parts are generalizable: they are a priori independent of an object definition, but can be grouped to form objects a posteriori. To this end, we leverage the recently proposed Vision Transformer's capability of attending to objects and combine it with a spatially dense clustering task for fine-tuning the spatial tokens. Our method surpasses the state-of-the-art on three semantic segmentation benchmarks by 17%-3%, showing that our representations are versatile under various object definitions. Finally, we extend this to fully unsupervised segmentation - which refrains completely from using label information even at test-time - and demonstrate that a simple method for automatically merging discovered object parts based on community detection yields substantial gains.