 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Learning Contrastive Representations for Learning with Noisy Labels
Mar 03, 2022
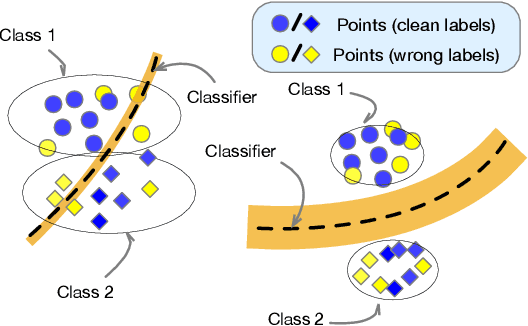
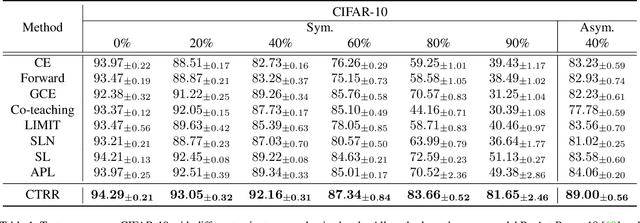
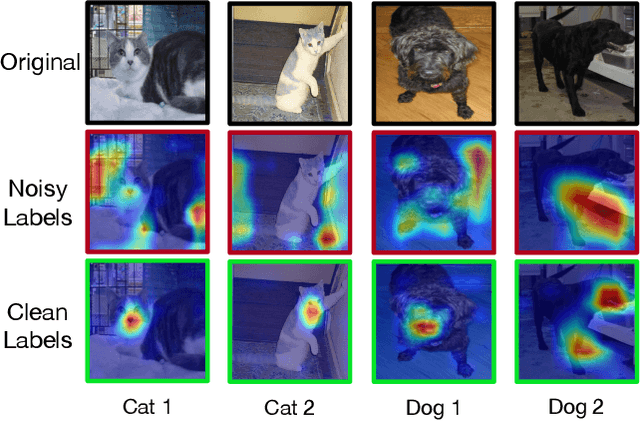
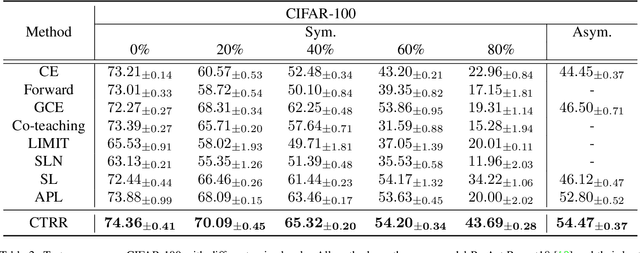
Deep neural networks are able to memorize noisy labels easily with a softmax cross-entropy (CE) loss. Previous studies attempted to address this issue focus on incorporating a noise-robust loss function to the CE loss. However, the memorization issue is alleviated but still remains due to the non-robust CE loss. To address this issue, we focus on learning robust contrastive representations of data on which the classifier is hard to memorize the label noise under the CE loss. We propose a novel contrastive regularization function to learn such representations over noisy data where label noise does not dominate the representation learning. By theoretically investigating the representations induced by the proposed regularization function, we reveal that the learned representations keep information related to true labels and discard information related to corrupted labels. Moreover, our theoretical results also indicate that the learned representations are robust to the label noise. The effectiveness of this method is demonstrated with experiments on benchmark datasets.
Wind power predictions from nowcasts to 4-hour forecasts: a learning approach with variable selection
Apr 20, 2022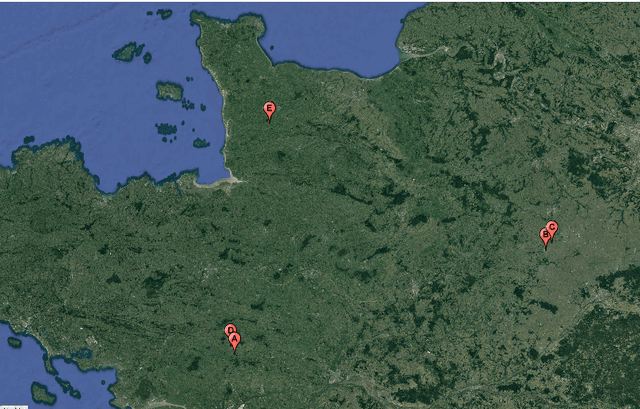

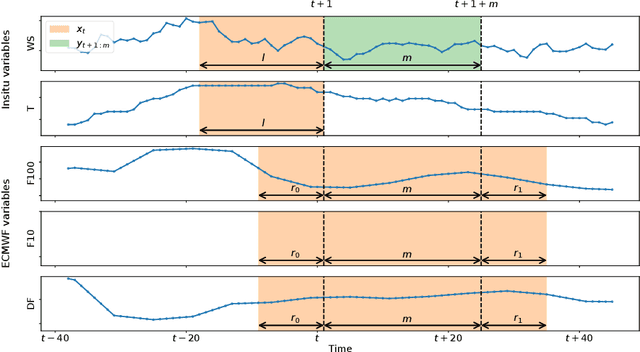
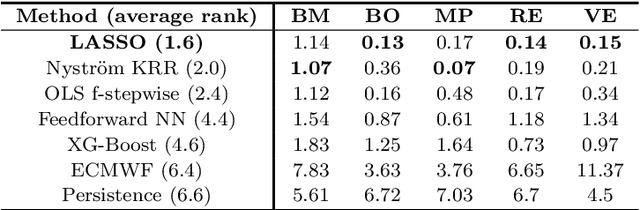
We study the prediction of short term wind speed and wind power (every 10 minutes up to 4 hours ahead). Accurate forecasts for those quantities are crucial to mitigate the negative effects of wind farms' intermittent production on energy systems and markets. For those time scales, outputs of numerical weather prediction models are usually overlooked even though they should provide valuable information on higher scales dynamics. In this work, we combine those outputs with local observations using machine learning. So as to make the results usable for practitioners, we focus on simple and well known methods which can handle a high volume of data. We study first variable selection through two simple techniques, a linear one and a nonlinear one. Then we exploit those results to forecast wind speed and wind power still with an emphasis on linear models versus nonlinear ones. For the wind power prediction, we also compare the indirect approach (wind speed predictions passed through a power curve) and the indirect one (directly predict wind power).
Unifying Language Learning Paradigms
May 10, 2022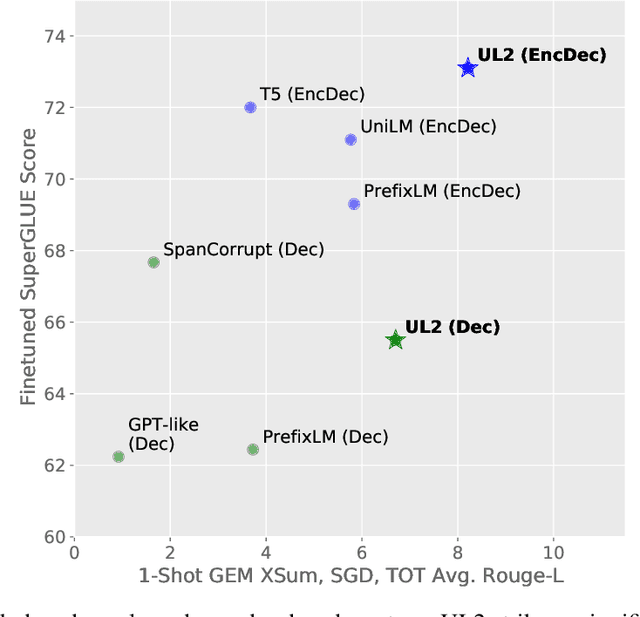

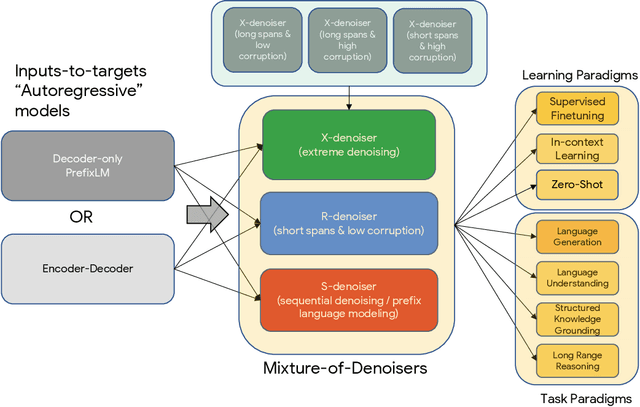
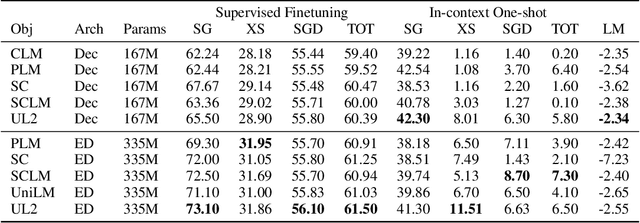
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization. We release Flax-based T5X model checkpoints for the 20B model at \url{https://github.com/google-research/google-research/tree/master/ul2}.
An Effective Graph Learning based Approach for Temporal Link Prediction: The First Place of WSDM Cup 2022
Mar 01, 2022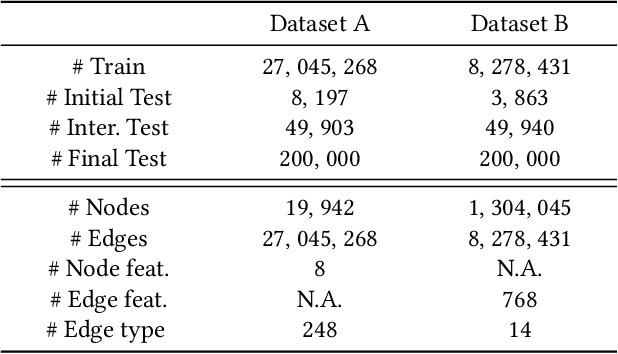


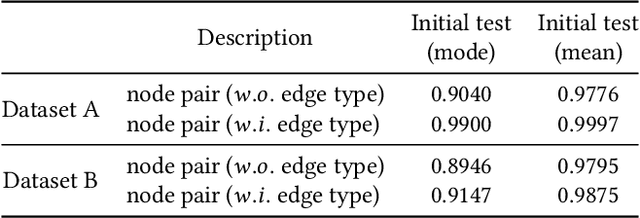
Temporal link prediction, as one of the most crucial work in temporal graphs, has attracted lots of attention from the research area. The WSDM Cup 2022 seeks for solutions that predict the existence probabilities of edges within time spans over temporal graph. This paper introduces the solution of AntGraph, which wins the 1st place in the competition. We first analysis the theoretical upper-bound of the performance by removing temporal information, which implies that only structure and attribute information on the graph could achieve great performance. Based on this hypothesis, then we introduce several well-designed features. Finally, experiments conducted on the competition datasets show the superiority of our proposal, which achieved AUC score of 0.666 on dataset A and 0.902 on dataset B, the ablation studies also prove the efficiency of each feature. Code is publicly available at https://github.com/im0qianqian/WSDM2022TGP-AntGraph.
Information-Theoretic Approximation to Causal Models
Jul 29, 2020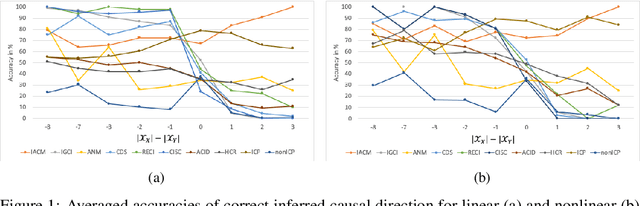
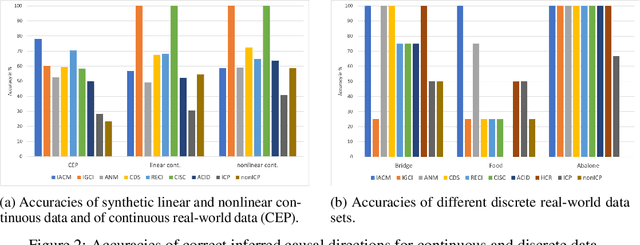
Inferring the causal direction and causal effect between two discrete random variables X and Y from a finite sample is often a crucial problem and a challenging task. However, if we have access to observational and interventional data, it is possible to solve that task. If X is causing Y, then it does not matter if we observe an effect in Y by observing changes in X or by intervening actively on X. This invariance principle creates a link between observational and interventional distributions in a higher dimensional probability space. We embed distributions that originate from samples of X and Y into that higher dimensional space such that the embedded distribution is closest to the distributions that follow the invariance principle, with respect to the relative entropy. This allows us to calculate the best information-theoretic approximation for a given empirical distribution, that follows an assumed underlying causal model. We show that this information-theoretic approximation to causal models (IACM) can be done by solving a linear optimization problem. In particular, by approximating the empirical distribution to a monotonic causal model, we can calculate probabilities of causation. It turns out that this approximation approach can be used to successfully solve causal discovery problems in the bivariate, discrete case. Experimental results on both labeled synthetic and real-world data demonstrate that our approach outperforms other state-of-the-art approaches in the discrete case with low cardinality.
Mechanisms for Hiding Sensitive Genotypes with Information-Theoretic Privacy
Jul 10, 2020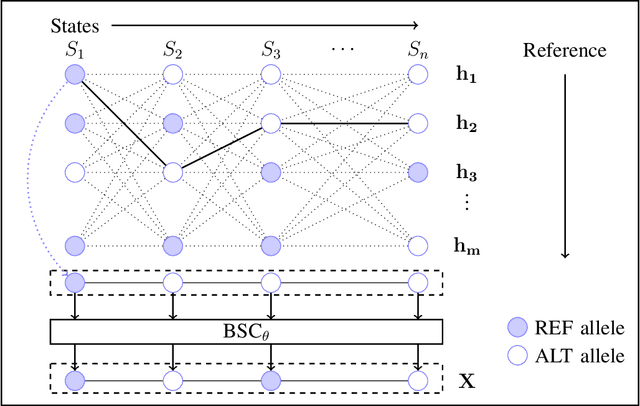
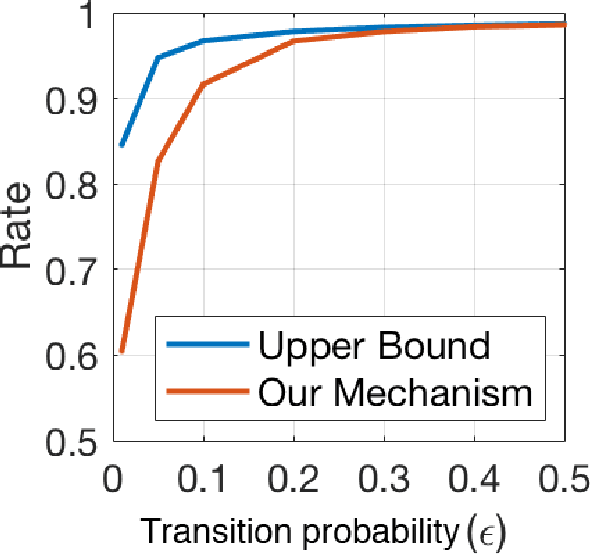
The growing availability of personal genomics services comes with increasing concerns for genomic privacy. Individuals may wish to withhold sensitive genotypes that contain critical health-related information when sharing their data with such services. A straightforward solution that masks only the sensitive genotypes does not ensure privacy due to the correlation structure within the genome. Here, we develop an information-theoretic mechanism for masking sensitive genotypes, which ensures no information about the sensitive genotypes is leaked. We also propose an efficient algorithmic implementation of our mechanism for genomic data governed by hidden Markov models. Our work is a step towards more rigorous control of privacy in genomic data sharing.
EntSUM: A Data Set for Entity-Centric Summarization
Apr 05, 2022
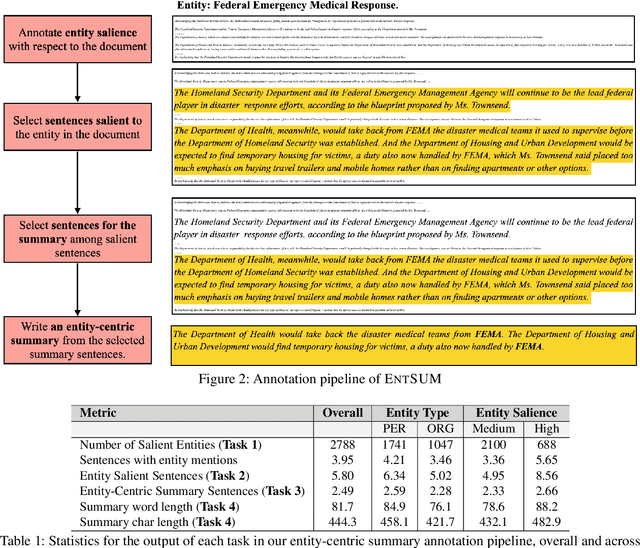

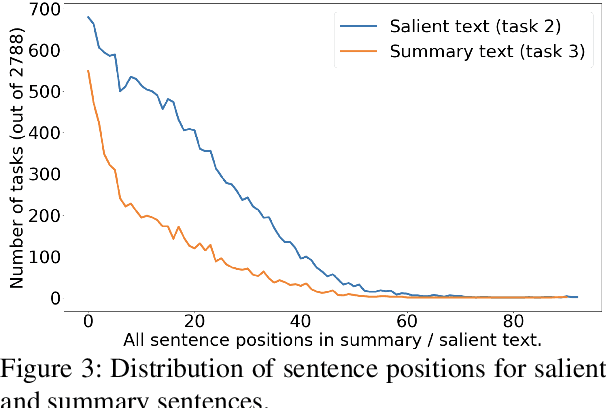
Controllable summarization aims to provide summaries that take into account user-specified aspects and preferences to better assist them with their information need, as opposed to the standard summarization setup which build a single generic summary of a document. We introduce a human-annotated data set EntSUM for controllable summarization with a focus on named entities as the aspects to control. We conduct an extensive quantitative analysis to motivate the task of entity-centric summarization and show that existing methods for controllable summarization fail to generate entity-centric summaries. We propose extensions to state-of-the-art summarization approaches that achieve substantially better results on our data set. Our analysis and results show the challenging nature of this task and of the proposed data set.
A Multimodal Canonical-Correlated Graph Neural Network for Energy-Efficient Speech Enhancement
Feb 09, 2022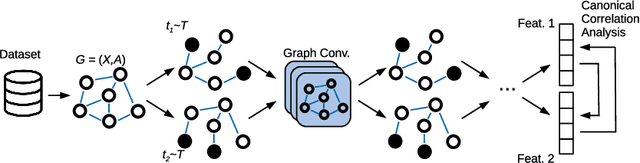
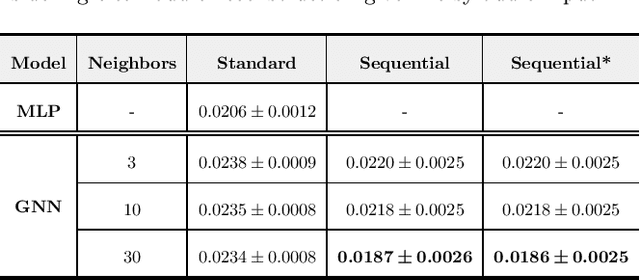
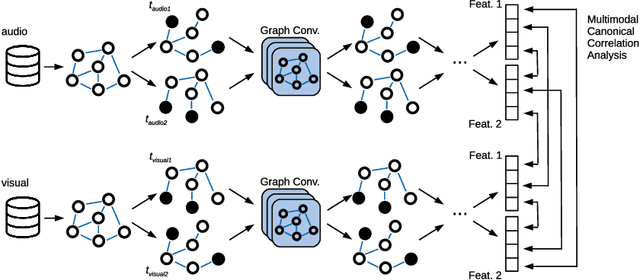
This paper proposes a novel multimodal self-supervised architecture for energy-efficient AV speech enhancement by integrating graph neural networks with canonical correlation analysis (CCA-GNN). This builds on a state-of-the-art CCA-GNN that aims to learn representative embeddings by maximizing the correlation between pairs of augmented views of the same input while decorrelating disconnected features. The key idea of the conventional CCA-GNN involves discarding augmentation-variant information and preserving augmentation-invariant information whilst preventing capturing of redundant information. Our proposed AV CCA-GNN model is designed to deal with the challenging multimodal representation learning context. Specifically, our model improves contextual AV speech processing by maximizing canonical correlation from augmented views of the same channel, as well as canonical correlation from audio and visual embeddings. In addition, we propose a positional encoding of the nodes that considers a prior-frame sequence distance instead of a feature-space representation while computing the node's nearest neighbors. This serves to introduce temporal information in the embeddings through the neighborhood's connectivity. Experiments conducted with the benchmark ChiME3 dataset show that our proposed prior frame-based AV CCA-GNN reinforces better feature learning in the temporal context, leading to more energy-efficient speech reconstruction compared to state-of-the-art CCA-GNN and multi-layer perceptron models. The results demonstrate the potential of our proposed approach for exploitation in future assistive technology and energy-efficient multimodal devices.
Cross-modal Memory Networks for Radiology Report Generation
Apr 28, 2022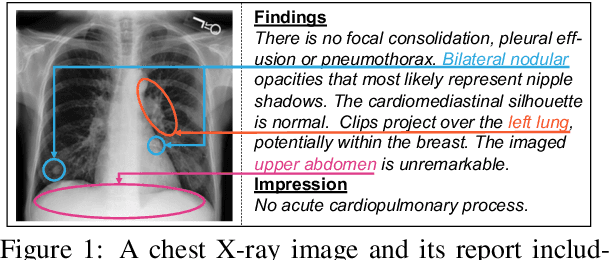
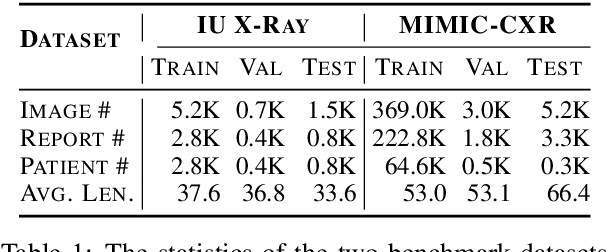
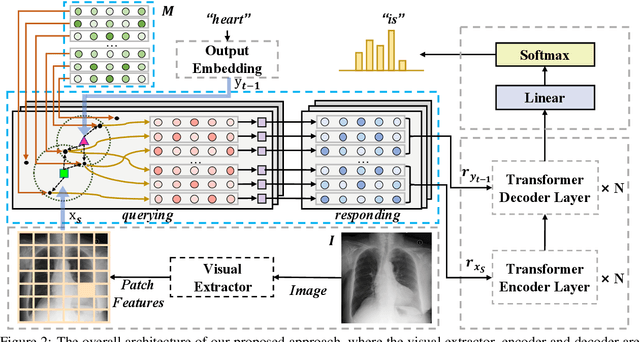
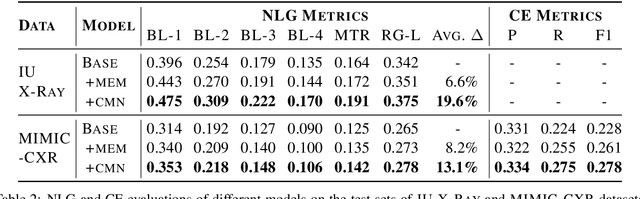
Medical imaging plays a significant role in clinical practice of medical diagnosis, where the text reports of the images are essential in understanding them and facilitating later treatments. By generating the reports automatically, it is beneficial to help lighten the burden of radiologists and significantly promote clinical automation, which already attracts much attention in applying artificial intelligence to medical domain. Previous studies mainly follow the encoder-decoder paradigm and focus on the aspect of text generation, with few studies considering the importance of cross-modal mappings and explicitly exploit such mappings to facilitate radiology report generation. In this paper, we propose a cross-modal memory networks (CMN) to enhance the encoder-decoder framework for radiology report generation, where a shared memory is designed to record the alignment between images and texts so as to facilitate the interaction and generation across modalities. Experimental results illustrate the effectiveness of our proposed model, where state-of-the-art performance is achieved on two widely used benchmark datasets, i.e., IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to better align information from radiology images and texts so as to help generating more accurate reports in terms of clinical indicators.
Visual-based Positioning and Pose Estimation
Apr 20, 2022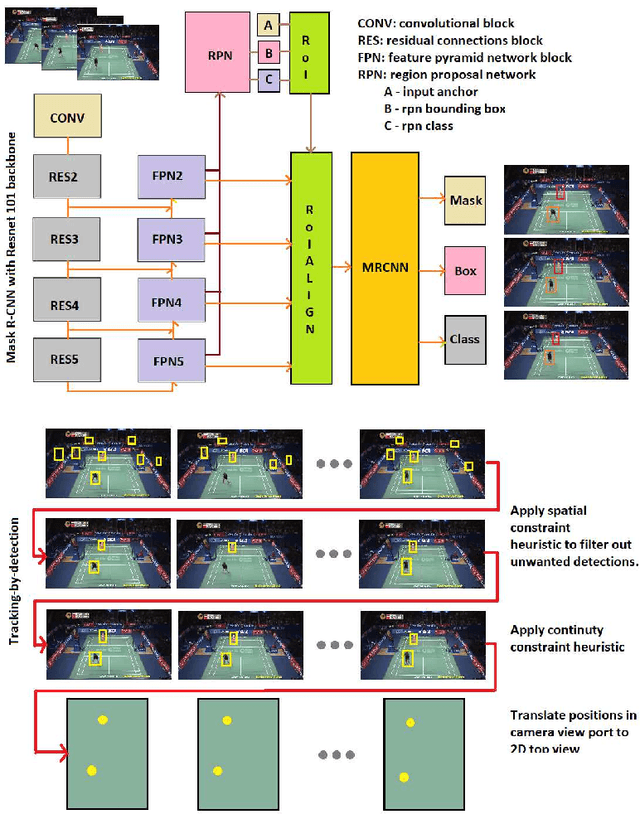
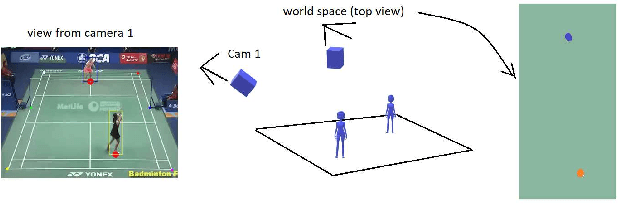
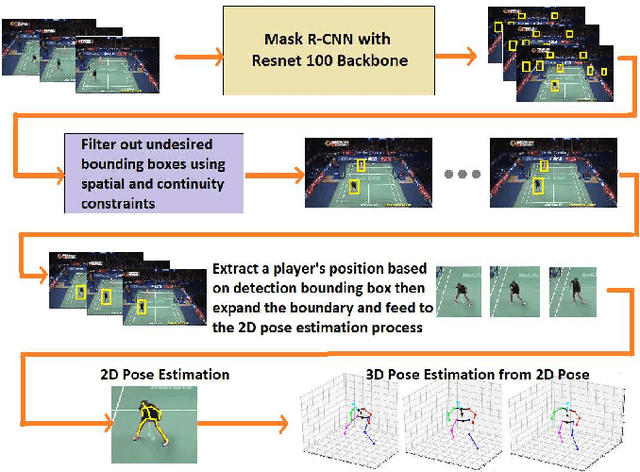
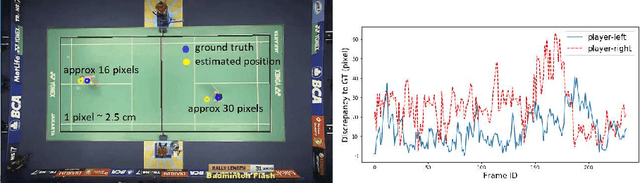
Recent advances in deep learning and computer vision offer an excellent opportunity to investigate high-level visual analysis tasks such as human localization and human pose estimation. Although the performance of human localization and human pose estimation has significantly improved in recent reports, they are not perfect and erroneous localization and pose estimation can be expected among video frames. Studies on the integration of these techniques into a generic pipeline that is robust to noise introduced from those errors are still lacking. This paper fills the missing study. We explored and developed two working pipelines that suited the visual-based positioning and pose estimation tasks. Analyses of the proposed pipelines were conducted on a badminton game. We showed that the concept of tracking by detection could work well, and errors in position and pose could be effectively handled by a linear interpolation technique using information from nearby frames. The results showed that the Visual-based Positioning and Pose Estimation could deliver position and pose estimations with good spatial and temporal resolutions.