 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Structure of Do-Calculus Reasoning via Derivation Graphs
Jun 02, 2026The do-calculus defines a general system of inference for interventional queries, allowing causal quantities to be transformed through successive applications of its rules. This process induces a rich space of equivalent interventional expressions, but combining and ordering these rules remains challenging. In this work, we introduce derivation graphs, which represent how do-calculus rules are applied and combined, and characterize the full space of observational and interventional probabilities which are equivalent under the do-calculus. The structure of these graphs yields a simple procedure that uses at most four applications of do-calculus rules. Finally, we show how applying identification algorithms to equivalent causal queries produces multiple valid estimands for the same causal quantity, eventually yielding more efficient estimators.
Identifiable Multimodal Causal Representation Learning under Partial Latent Sharing
May 18, 2026Causal representation learning (CRL) seeks to uncover meaningful latent variables and their corresponding causal structure from high-dimensional observational data. Although its significance, CRL identifiability remains a crucial property, as it ensures the recovery of the mechanisms behind the data generation process, and hence the interpretability and robustness of the representation. Proving identifiability in CRL is intrinsically difficult, and we address in this work an even more challenging setting: multimodality. We consider multimodal observed data with a latent partially shared structure. Each modality is generated, through non linear mixing functions, from a specific subset of causal latent variables. Under flexible assumptions and without imposing any parametric distribution on the latent variables, we establish component-wise identifiability guarantees for the causal latent representation. Our identifiability results, furthermore, apply to the undercomplete scenario where we have, for each modality, more observed than latent variables. To instantiate our theoretical analysis, we introduce a Wasserstein-based module to recover the partially shared latent structure. Due to its differentiability, the latter can be easily integrated into all types of architecture, only requiring minimal changes. Extensive experiments on synthetic and realistic datasets validate the superiority of our approach over SOTA methods.
Identifiability in Causal Abstractions: A Hierarchy of Criteria
Jul 08, 2025Identifying the effect of a treatment from observational data typically requires assuming a fully specified causal diagram. However, such diagrams are rarely known in practice, especially in complex or high-dimensional settings. To overcome this limitation, recent works have explored the use of causal abstractions-simplified representations that retain partial causal information. In this paper, we consider causal abstractions formalized as collections of causal diagrams, and focus on the identifiability of causal queries within such collections. We introduce and formalize several identifiability criteria under this setting. Our main contribution is to organize these criteria into a structured hierarchy, highlighting their relationships. This hierarchical view enables a clearer understanding of what can be identified under varying levels of causal knowledge. We illustrate our framework through examples from the literature and provide tools to reason about identifiability when full causal knowledge is unavailable.
ImmunoFOMO: Are Language Models missing what oncologists see?
Jun 13, 2025Language models (LMs) capabilities have grown with a fast pace over the past decade leading researchers in various disciplines, such as biomedical research, to increasingly explore the utility of LMs in their day-to-day applications. Domain specific language models have already been in use for biomedical natural language processing (NLP) applications. Recently however, the interest has grown towards medical language models and their understanding capabilities. In this paper, we investigate the medical conceptual grounding of various language models against expert clinicians for identification of hallmarks of immunotherapy in breast cancer abstracts. Our results show that pre-trained language models have potential to outperform large language models in identifying very specific (low-level) concepts.
Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?
Jul 17, 2024



The success of pretrained language models (PLMs) across a spate of use-cases has led to significant investment from the NLP community towards building domain-specific foundational models. On the other hand, in mission critical settings such as biomedical applications, other aspects also factor in-chief of which is a model's ability to produce reasonable estimates of its own uncertainty. In the present study, we discuss these two desiderata through the lens of how they shape the entropy of a model's output probability distribution. We find that domain specificity and uncertainty awareness can often be successfully combined, but the exact task at hand weighs in much more strongly.
Ensembles of Probabilistic Regression Trees
Jun 20, 2024



Tree-based ensemble methods such as random forests, gradient-boosted trees, and Bayesianadditive regression trees have been successfully used for regression problems in many applicationsand research studies. In this paper, we study ensemble versions of probabilisticregression trees that provide smooth approximations of the objective function by assigningeach observation to each region with respect to a probability distribution. We prove thatthe ensemble versions of probabilistic regression trees considered are consistent, and experimentallystudy their bias-variance trade-off and compare them with the state-of-the-art interms of performance prediction.
Risk prediction of pathological gambling on social media
Mar 28, 2024This paper addresses the problem of risk prediction on social media data, specifically focusing on the classification of Reddit users as having a pathological gambling disorder. To tackle this problem, this paper focuses on incorporating temporal and emotional features into the model. The preprocessing phase involves dealing with the time irregularity of posts by padding sequences. Two baseline architectures are used for preliminary evaluation: BERT classifier on concatenated posts per user and GRU with LSTM on sequential data. Experimental results demonstrate that the sequential models outperform the concatenation-based model. The results of the experiments conclude that the incorporation of a time decay layer (TD) and passing the emotion classification layer (EmoBERTa) through LSTM improves the performance significantly. Experiments concluded that the addition of a self-attention layer didn't significantly improve the performance of the model, however provided easily interpretable attention scores. The developed architecture with the inclusion of EmoBERTa and TD layers achieved a high F1 score, beating existing benchmarks on pathological gambling dataset. Future work may involve the early prediction of risk factors associated with pathological gambling disorder and testing models on other datasets. Overall, this research highlights the significance of the sequential processing of posts including temporal and emotional features to boost the predictive power, as well as adding an attention layer for interpretability.
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023



Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.
Polarimetric phase retrieval: uniqueness and algorithms
Jun 26, 2022
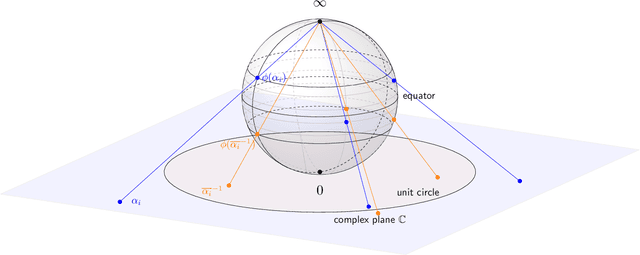
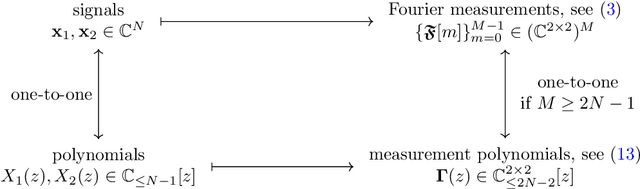

This work introduces a novel Fourier phase retrieval model, called polarimetric phase retrieval that enables a systematic use of polarization information in Fourier phase retrieval problems. We provide a complete characterization of uniqueness properties of this new model by unraveling equivalencies with a peculiar polynomial factorization problem. We introduce two different but complementary categories of reconstruction methods. The first one is algebraic and relies on the use of approximate greatest common divisor computations using Sylvester matrices. The second one carefully adapts existing algorithms for Fourier phase retrieval, namely semidefinite positive relaxation and Wirtinger-Flow, to solve the polarimetric phase retrieval problem. Finally, a set of numerical experiments permits a detailed assessment of the numerical behavior and relative performances of each proposed reconstruction strategy. We further highlight a reconstruction strategy that combines both approaches for scalable, computationally efficient and asymptotically MSE optimal performance.
Wind power predictions from nowcasts to 4-hour forecasts: a learning approach with variable selection
Apr 20, 2022

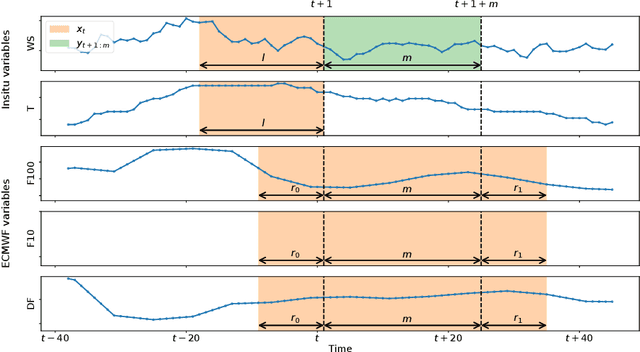
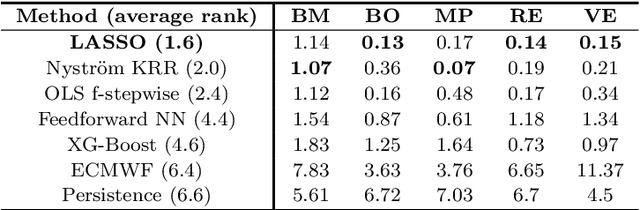
We study the prediction of short term wind speed and wind power (every 10 minutes up to 4 hours ahead). Accurate forecasts for those quantities are crucial to mitigate the negative effects of wind farms' intermittent production on energy systems and markets. For those time scales, outputs of numerical weather prediction models are usually overlooked even though they should provide valuable information on higher scales dynamics. In this work, we combine those outputs with local observations using machine learning. So as to make the results usable for practitioners, we focus on simple and well known methods which can handle a high volume of data. We study first variable selection through two simple techniques, a linear one and a nonlinear one. Then we exploit those results to forecast wind speed and wind power still with an emphasis on linear models versus nonlinear ones. For the wind power prediction, we also compare the indirect approach (wind speed predictions passed through a power curve) and the indirect one (directly predict wind power).