 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSomnuk Phon-Amnuaisuk
Visual-based Positioning and Pose Estimation
Apr 20, 2022
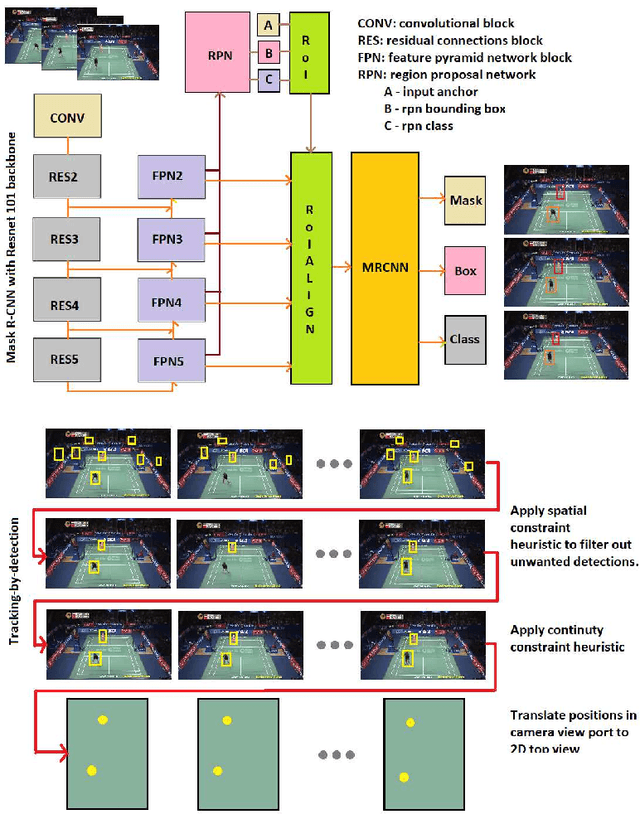
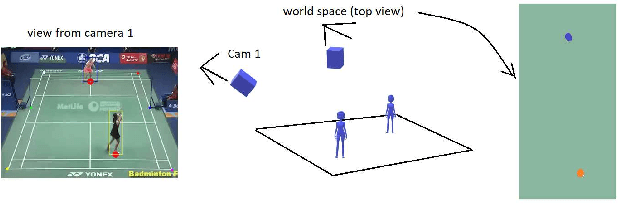
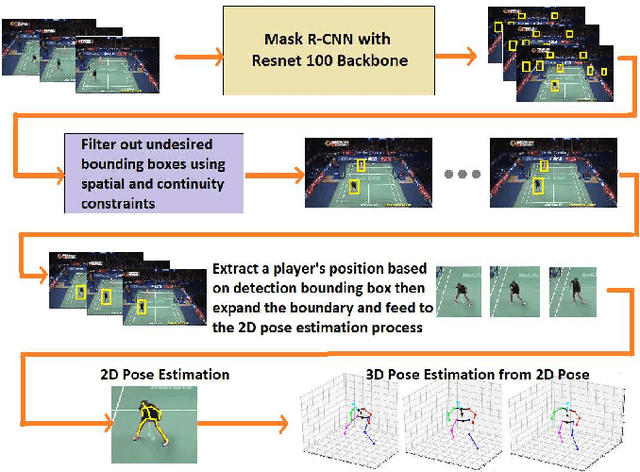
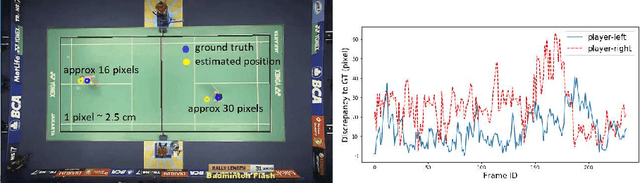
Recent advances in deep learning and computer vision offer an excellent opportunity to investigate high-level visual analysis tasks such as human localization and human pose estimation. Although the performance of human localization and human pose estimation has significantly improved in recent reports, they are not perfect and erroneous localization and pose estimation can be expected among video frames. Studies on the integration of these techniques into a generic pipeline that is robust to noise introduced from those errors are still lacking. This paper fills the missing study. We explored and developed two working pipelines that suited the visual-based positioning and pose estimation tasks. Analyses of the proposed pipelines were conducted on a badminton game. We showed that the concept of tracking by detection could work well, and errors in position and pose could be effectively handled by a linear interpolation technique using information from nearby frames. The results showed that the Visual-based Positioning and Pose Estimation could deliver position and pose estimations with good spatial and temporal resolutions.
Exploring Graph Representation of Chorales
Jan 27, 2022

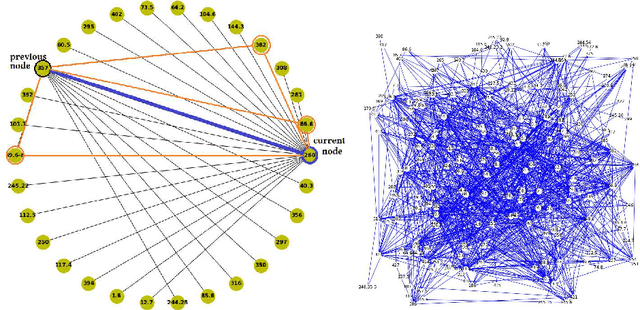

This work explores areas overlapping music, graph theory, and machine learning. An embedding representation of a node, in a weighted undirected graph $\mathcal{G}$, is a representation that captures the meaning of nodes in an embedding space. In this work, 383 Bach chorales were compiled and represented as a graph. Two application cases were investigated in this paper (i) learning node embedding representation using \emph{Continuous Bag of Words (CBOW), skip-gram}, and \emph{node2vec} algorithms, and (ii) learning node labels from neighboring nodes based on a collective classification approach. The results of this exploratory study ascertains many salient features of the graph-based representation approach applicable to music applications.
Exploring the Applications of Faster R-CNN and Single-Shot Multi-box Detection in a Smart Nursery Domain
Aug 27, 2018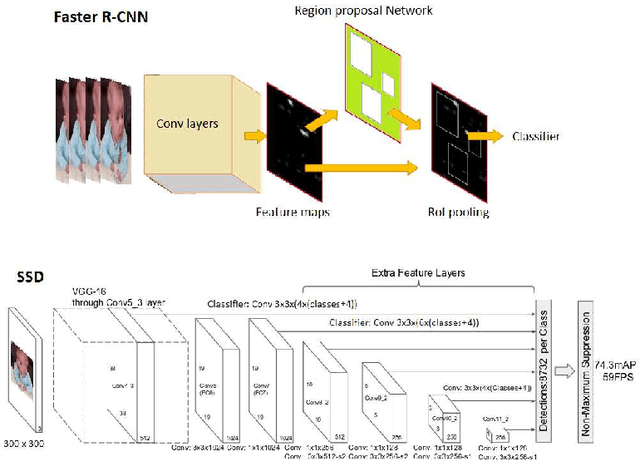
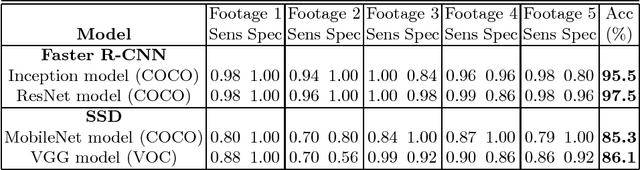

The ultimate goal of a baby detection task concerns detecting the presence of a baby and other objects in a sequence of 2D images, tracking them and understanding the semantic contents of the scene. Recent advances in deep learning and computer vision offer various powerful tools in general object detection and can be applied to a baby detection task. In this paper, the Faster Region-based Convolutional Neural Network and the Single-Shot Multi-Box Detection approaches are explored. They are the two state-of-the-art object detectors based on the region proposal tactic and the multi-box tactic. The presence of a baby in the scene obtained from these detectors, tested using different pre-trained models, are discussed. This study is important since the behaviors of these detectors in a baby detection task using different pre-trained models are still not well understood. This exploratory study reveals many useful insights into the applications of these object detectors in the smart nursery domain.
Learning to Play Pong using Policy Gradient Learning
Jul 23, 2018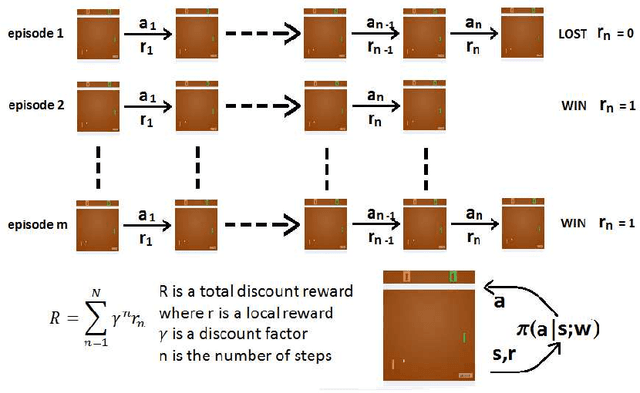
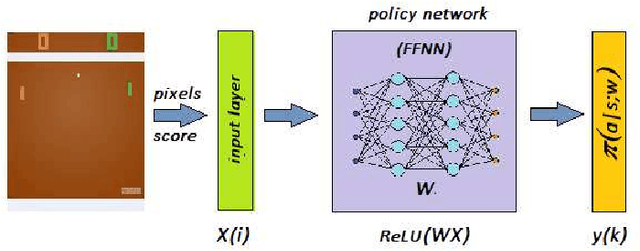

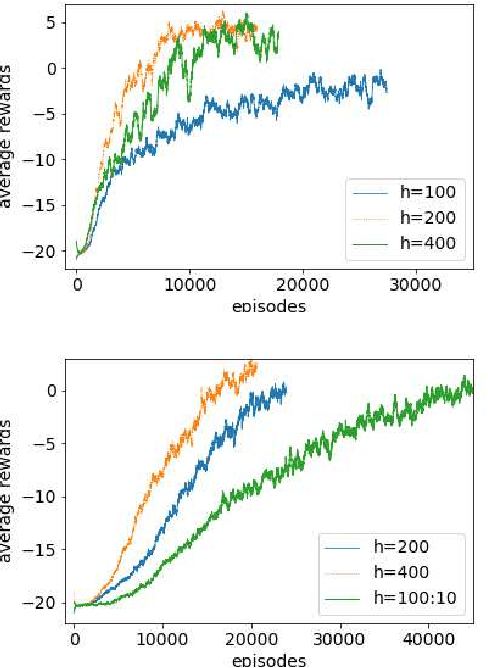
Activities in reinforcement learning (RL) revolve around learning the Markov decision process (MDP) model, in particular, the following parameters: state values, V; state-action values, Q; and policy, pi. These parameters are commonly implemented as an array. Scaling up the problem means scaling up the size of the array and this will quickly lead to a computational bottleneck. To get around this, the RL problem is commonly formulated to learn a specific task using hand-crafted input features to curb the size of the array. In this report, we discuss an alternative end-to-end Deep Reinforcement Learning (DRL) approach where the DRL attempts to learn general task representations which in our context refers to learning to play the Pong game from a sequence of screen snapshots without game-specific hand-crafted features. We apply artificial neural networks (ANN) to approximate a policy of the RL model. The policy network, via Policy Gradients (PG) method, learns to play the Pong game from a sequence of frames without any extra semantics apart from the pixel information and the score. In contrast to the traditional tabular RL approach where the contents in the array have clear interpretations such as V or Q, the interpretation of knowledge content from the weights of the policy network is more illusive. In this work, we experiment with various Deep ANN architectures i.e., Feed forward ANN (FFNN), Convolution ANN (CNN) and Asynchronous Advantage Actor-Critic (A3C). We also examine the activation of hidden nodes and the weights between the input and the hidden layers, before and after the DRL has successfully learnt to play the Pong game. Insights into the internal learning mechanisms and future research directions are then discussed.