 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation
Apr 03, 2022
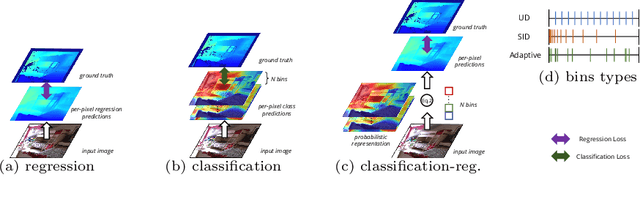
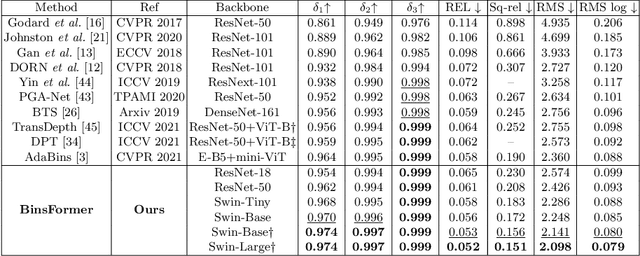
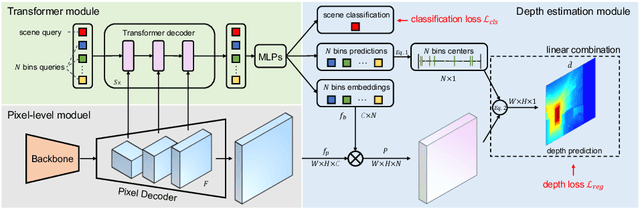
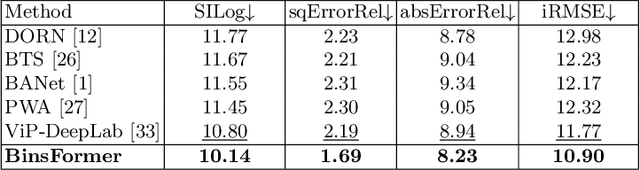
Monocular depth estimation is a fundamental task in computer vision and has drawn increasing attention. Recently, some methods reformulate it as a classification-regression task to boost the model performance, where continuous depth is estimated via a linear combination of predicted probability distributions and discrete bins. In this paper, we present a novel framework called BinsFormer, tailored for the classification-regression-based depth estimation. It mainly focuses on two crucial components in the specific task: 1) proper generation of adaptive bins and 2) sufficient interaction between probability distribution and bins predictions. To specify, we employ the Transformer decoder to generate bins, novelly viewing it as a direct set-to-set prediction problem. We further integrate a multi-scale decoder structure to achieve a comprehensive understanding of spatial geometry information and estimate depth maps in a coarse-to-fine manner. Moreover, an extra scene understanding query is proposed to improve the estimation accuracy, which turns out that models can implicitly learn useful information from an auxiliary environment classification task. Extensive experiments on the KITTI, NYU, and SUN RGB-D datasets demonstrate that BinsFormer surpasses state-of-the-art monocular depth estimation methods with prominent margins. Code and pretrained models will be made publicly available at \url{https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox}.
ProxyMix: Proxy-based Mixup Training with Label Refinery for Source-Free Domain Adaptation
May 29, 2022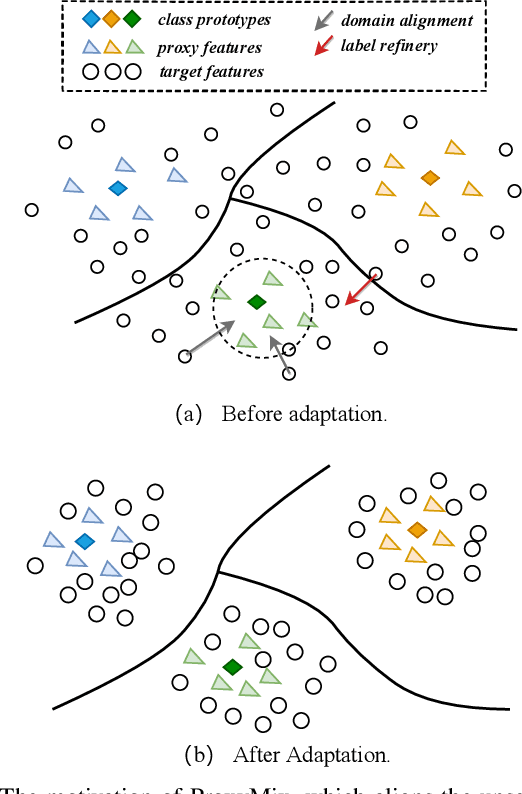
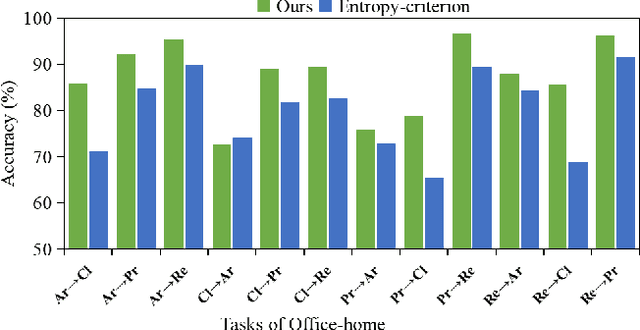
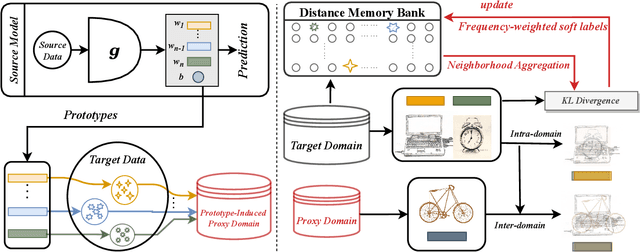
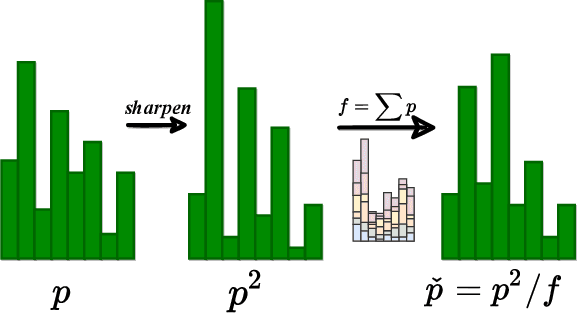
Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. Owing to privacy concerns and heavy data transmission, source-free UDA, exploiting the pre-trained source models instead of the raw source data for target learning, has been gaining popularity in recent years. Some works attempt to recover unseen source domains with generative models, however introducing additional network parameters. Other works propose to fine-tune the source model by pseudo labels, while noisy pseudo labels may misguide the decision boundary, leading to unsatisfied results. To tackle these issues, we propose an effective method named Proxy-based Mixup training with label refinery (ProxyMix). First of all, to avoid additional parameters and explore the information in the source model, ProxyMix defines the weights of the classifier as the class prototypes and then constructs a class-balanced proxy source domain by the nearest neighbors of the prototypes to bridge the unseen source domain and the target domain. To improve the reliability of pseudo labels, we further propose the frequency-weighted aggregation strategy to generate soft pseudo labels for unlabeled target data. The proposed strategy exploits the internal structure of target features, pulls target features to their semantic neighbors, and increases the weights of low-frequency classes samples during gradient updating. With the proxy domain and the reliable pseudo labels, we employ two kinds of mixup regularization, i.e., inter- and intra-domain mixup, in our framework, to align the proxy and the target domain, enforcing the consistency of predictions, thereby further mitigating the negative impacts of noisy labels. Experiments on three 2D image and one 3D point cloud object recognition benchmarks demonstrate that ProxyMix yields state-of-the-art performance for source-free UDA tasks.
Extracting Latent Steering Vectors from Pretrained Language Models
May 10, 2022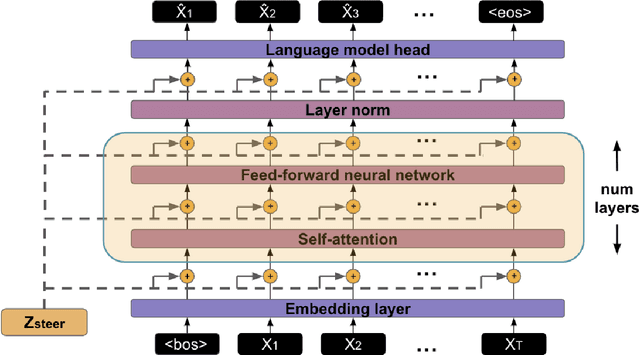

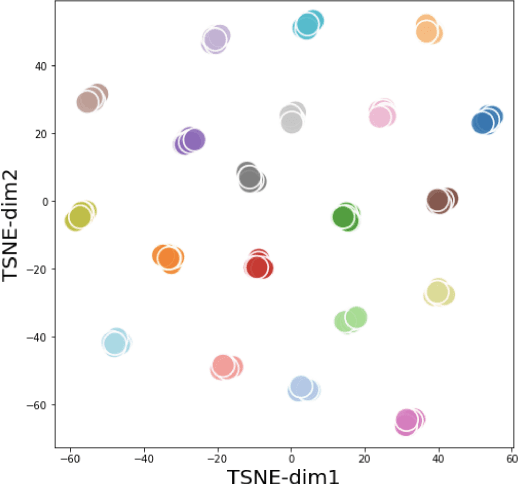

Prior work on controllable text generation has focused on learning how to control language models through trainable decoding, smart-prompt design, or fine-tuning based on a desired objective. We hypothesize that the information needed to steer the model to generate a target sentence is already encoded within the model. Accordingly, we explore a different approach altogether: extracting latent vectors directly from pretrained language model decoders without fine-tuning. Experiments show that there exist steering vectors, which, when added to the hidden states of the language model, generate a target sentence nearly perfectly (> 99 BLEU) for English sentences from a variety of domains. We show that vector arithmetic can be used for unsupervised sentiment transfer on the Yelp sentiment benchmark, with performance comparable to models tailored to this task. We find that distances between steering vectors reflect sentence similarity when evaluated on a textual similarity benchmark (STS-B), outperforming pooled hidden states of models. Finally, we present an analysis of the intrinsic properties of the steering vectors. Taken together, our results suggest that frozen LMs can be effectively controlled through their latent steering space.
Enabling Synthetic Data adoption in regulated domains
Apr 13, 2022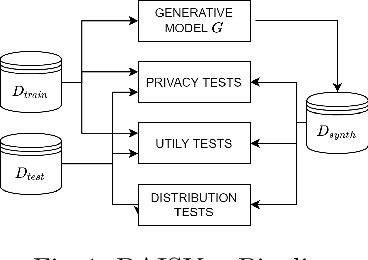
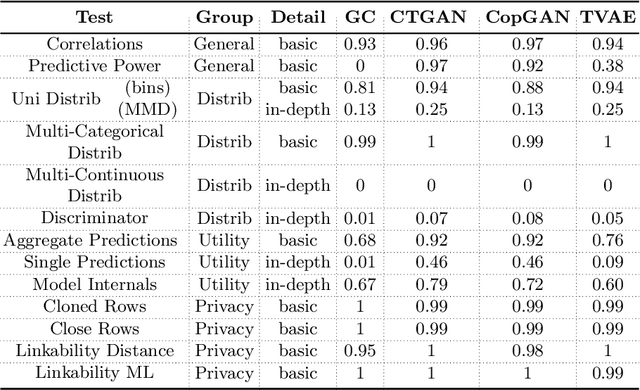

The switch from a Model-Centric to a Data-Centric mindset is putting emphasis on data and its quality rather than algorithms, bringing forward new challenges. In particular, the sensitive nature of the information in highly regulated scenarios needs to be accounted for. Specific approaches to address the privacy issue have been developed, as Privacy Enhancing Technologies. However, they frequently cause loss of information, putting forward a crucial trade-off among data quality and privacy. A clever way to bypass such a conundrum relies on Synthetic Data: data obtained from a generative process, learning the real data properties. Both Academia and Industry realized the importance of evaluating synthetic data quality: without all-round reliable metrics, the innovative data generation task has no proper objective function to maximize. Despite that, the topic remains under-explored. For this reason, we systematically catalog the important traits of synthetic data quality and privacy, and devise a specific methodology to test them. The result is DAISYnt (aDoption of Artificial Intelligence SYnthesis): a comprehensive suite of advanced tests, which sets a de facto standard for synthetic data evaluation. As a practical use-case, a variety of generative algorithms have been trained on real-world Credit Bureau Data. The best model has been assessed, using DAISYnt on the different synthetic replicas. Further potential uses, among others, entail auditing and fine-tuning of generative models or ensuring high quality of a given synthetic dataset. From a prescriptive viewpoint, eventually, DAISYnt may pave the way to synthetic data adoption in highly regulated domains, ranging from Finance to Healthcare, through Insurance and Education.
Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable
Sep 07, 2020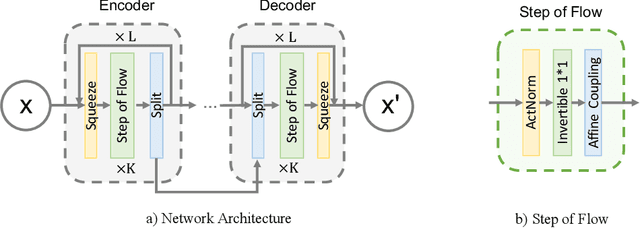
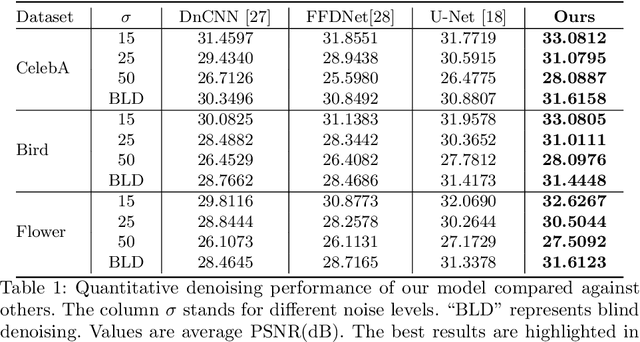

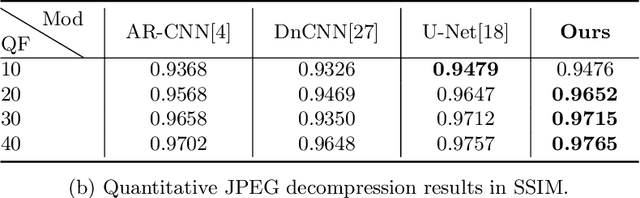
Ever since the advent of AlexNet, designing novel deep neural architectures for different tasks has consistently been a productive research direction. Despite the exceptional performance of various architectures in practice, we study a theoretical question: what is the condition for deep neural architectures to preserve all the information of the input data? Identifying the information lossless condition for deep neural architectures is important, because tasks such as image restoration require keep the detailed information of the input data as much as possible. Using the definition of mutual information, we show that: a deep neural architecture can preserve maximum details about the given data if and only if the architecture is invertible. We verify the advantages of our Invertible Restoring Autoencoder (IRAE) network by comparing it with competitive models on three perturbed image restoration tasks: image denoising, jpeg image decompression and image inpainting. Experimental results show that IRAE consistently outperforms non-invertible ones. Our model even contains far fewer parameters. Thus, it may be worthwhile to try replacing standard components of deep neural architectures, such as residual blocks and ReLU, with their invertible counterparts. We believe our work provides a unique perspective and direction for future deep learning research.
Hyper Attention Recurrent Neural Network: Tackling Temporal Covariate Shift in Time Series Analysis
Feb 22, 2022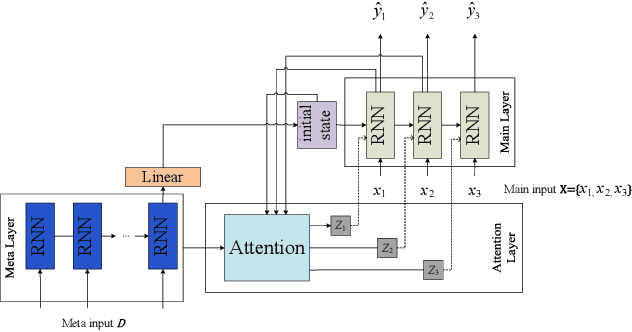
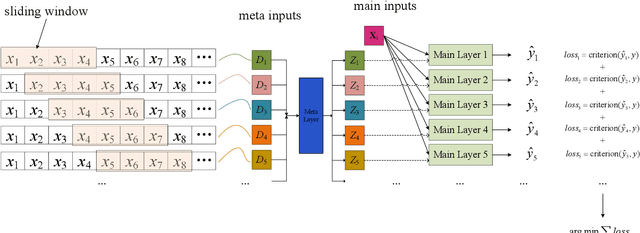
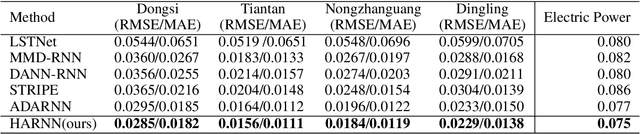
Analyzing long time series with RNNs often suffers from infeasible training. Segmentation is therefore commonly used in data pre-processing. However, in non-stationary time series, there exists often distribution shift among different segments. RNN is easily swamped in the dilemma of fitting bias in these segments due to the lack of global information, leading to poor generalization, known as Temporal Covariate Shift (TCS) problem, which is only addressed by a recently proposed RNN-based model. One of the assumptions in TCS is that the distribution of all divided intervals under the same segment are identical. This assumption, however, may not be true on high-frequency time series, such as traffic flow, that also have large stochasticity. Besides, macro information across long periods isn't adequately considered in the latest RNN-based methods. To address the above issues, we propose Hyper Attention Recurrent Neural Network (HARNN) for the modeling of temporal patterns containing both micro and macro information. An HARNN consists of a meta layer for parameter generation and an attention-enabled main layer for inference. High-frequency segments are transformed into low-frequency segments and fed into the meta layers, while the first main layer consumes the same high-frequency segments as conventional methods. In this way, each low-frequency segment in the meta inputs generates a unique main layer, enabling the integration of both macro information and micro information for inference. This forces all main layers to predict the same target which fully harnesses the common knowledge in varied distributions when capturing temporal patterns. Evaluations on multiple benchmarks demonstrated that our model outperforms a couple of RNN-based methods on a federation of key metrics.
A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction
Mar 26, 2022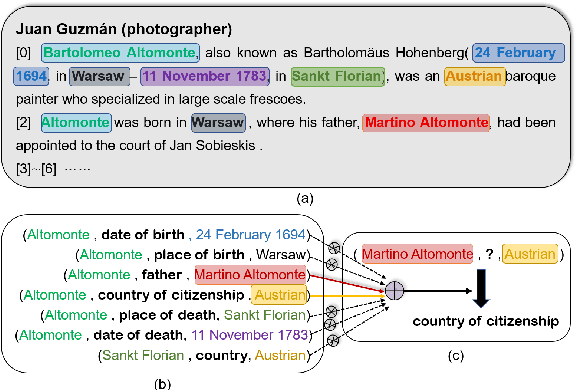
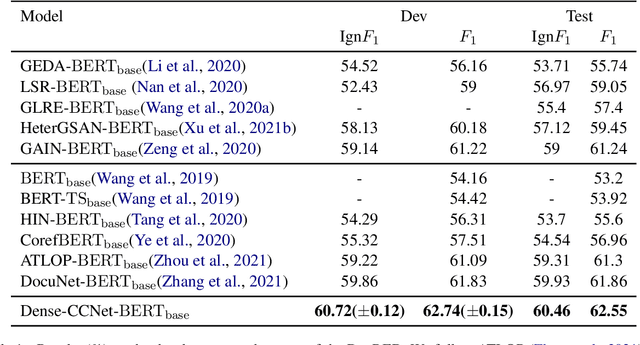
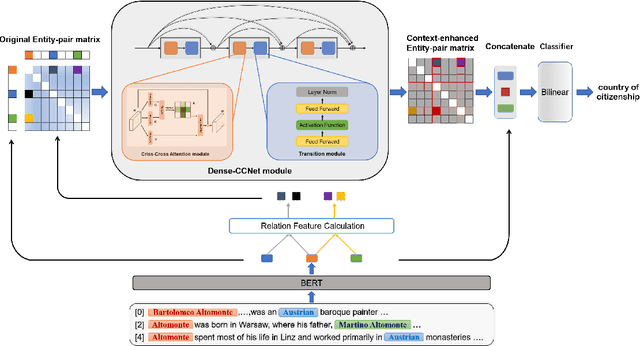
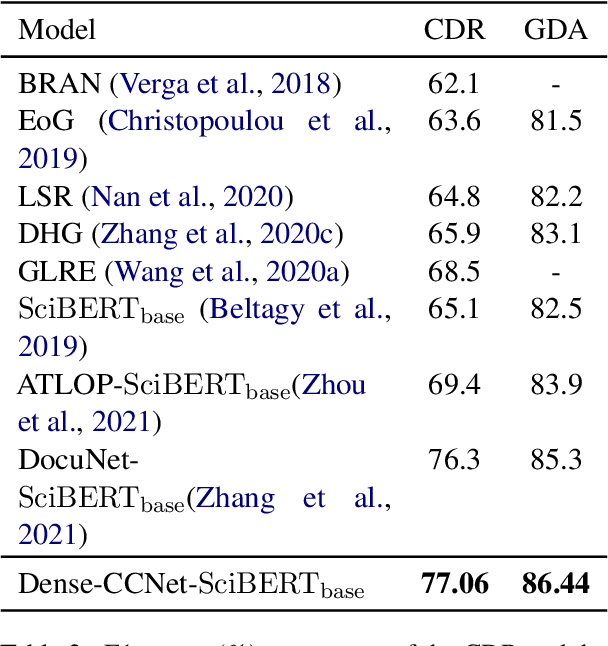
Document-level relation extraction (RE) aims to identify relations between two entities in a given document. Compared with its sentence-level counterpart, document-level RE requires complex reasoning. Previous research normally completed reasoning through information propagation on the mention-level or entity-level document-graph, but rarely considered reasoning at the entity-pair-level.In this paper, we propose a novel model, called Densely Connected Criss-Cross Attention Network (Dense-CCNet), for document-level RE, which can complete logical reasoning at the entity-pair-level. Specifically, the Dense-CCNet performs entity-pair-level logical reasoning through the Criss-Cross Attention (CCA), which can collect contextual information in horizontal and vertical directions on the entity-pair matrix to enhance the corresponding entity-pair representation. In addition, we densely connect multiple layers of the CCA to simultaneously capture the features of single-hop and multi-hop logical reasoning.We evaluate our Dense-CCNet model on three public document-level RE datasets, DocRED, CDR, and GDA. Experimental results demonstrate that our model achieves state-of-the-art performance on these three datasets.
Fundamental limitations on optimization in variational quantum algorithms
May 10, 2022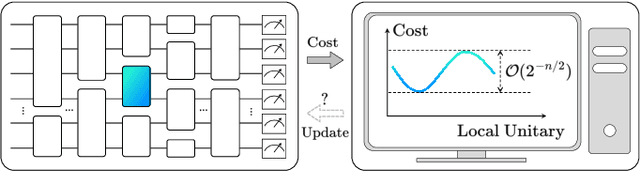
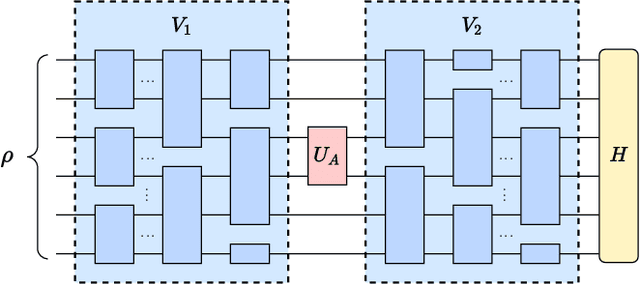
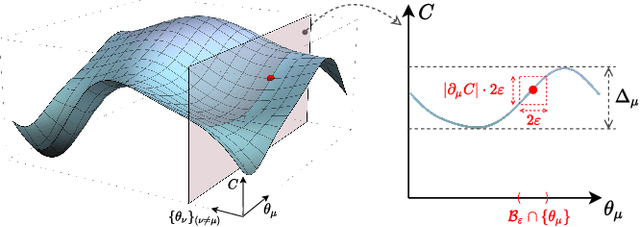

Exploring quantum applications of near-term quantum devices is a rapidly growing field of quantum information science with both theoretical and practical interests. A leading paradigm to establish such near-term quantum applications is variational quantum algorithms (VQAs). These algorithms use a classical optimizer to train a parameterized quantum circuit to accomplish certain tasks, where the circuits are usually randomly initialized. In this work, we prove that for a broad class of such random circuits, the variation range of the cost function via adjusting any local quantum gate within the circuit vanishes exponentially in the number of qubits with a high probability. This result can unify the restrictions on gradient-based and gradient-free optimizations in a natural manner and reveal extra harsh constraints on the training landscapes of VQAs. Hence a fundamental limitation on the trainability of VQAs is unraveled, indicating the essence of the optimization hardness in the Hilbert space with exponential dimension. We further showcase the validity of our results with numerical simulations of representative VQAs. We believe that these results would deepen our understanding of the scalability of VQAs and shed light on the search for near-term quantum applications with advantages.
New Insights on Target Speaker Extraction
Feb 01, 2022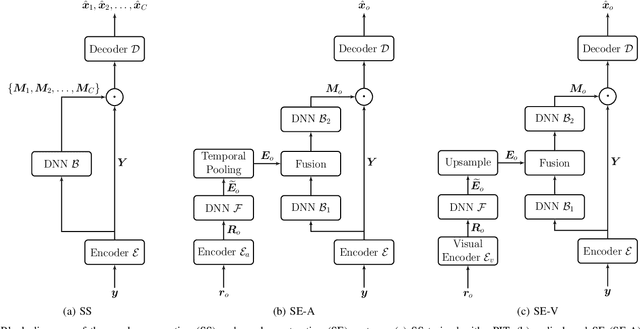
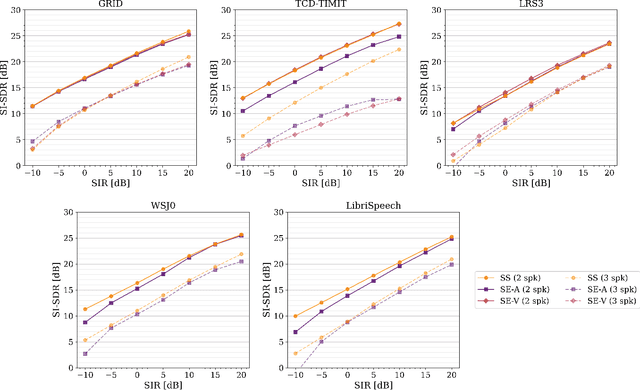
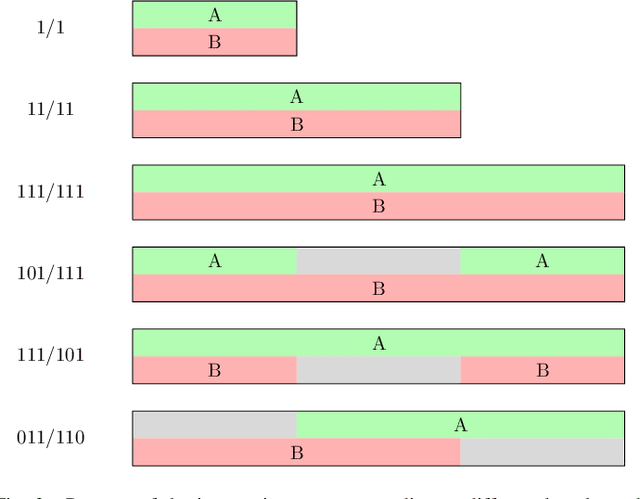
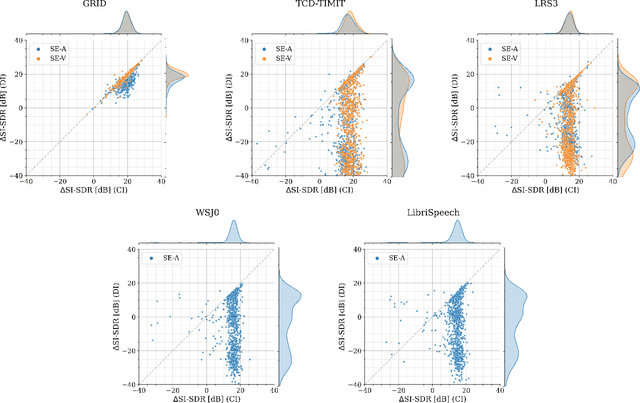
In recent years, researchers have become increasingly interested in speaker extraction (SE), which is the task of extracting the speech of a target speaker from a mixture of interfering speakers with the help of auxiliary information about the target speaker. Several forms of auxiliary information have been employed in single-channel SE, such as a speech snippet enrolled from the target speaker or visual information corresponding to the spoken utterance. Many SE studies have reported performance improvement compared to speaker separation (SS) methods with oracle selection, arguing that this is due to the use of auxiliary information. However, such works have not considered state-of-the-art SS methods that have shown impressive separation performance. In this paper, we revise and examine the role of the auxiliary information in SE. Specifically, we compare the performance of two SE systems (audio-based and video-based) with SS using a common framework that utilizes the state-of-the-art dual-path recurrent neural network as the main learning machine. In addition, we study how much the considered SE systems rely on the auxiliary information by analyzing the systems' output for random auxiliary signals. Experimental evaluation on various datasets suggests that the main purpose of the auxiliary information in the considered SE systems is only to specify the target speaker in the mixture and that it does not provide consistent extraction performance gain when compared to the uninformed SS system.
Sparse Compressed Spiking Neural Network Accelerator for Object Detection
May 02, 2022
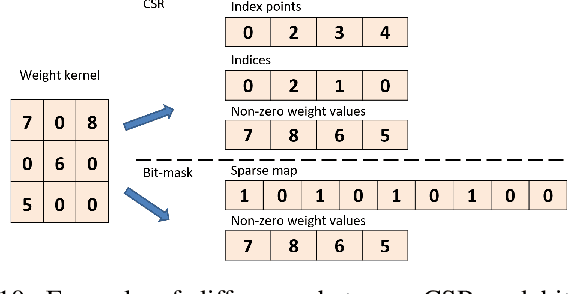
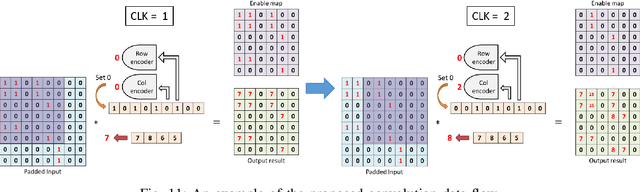
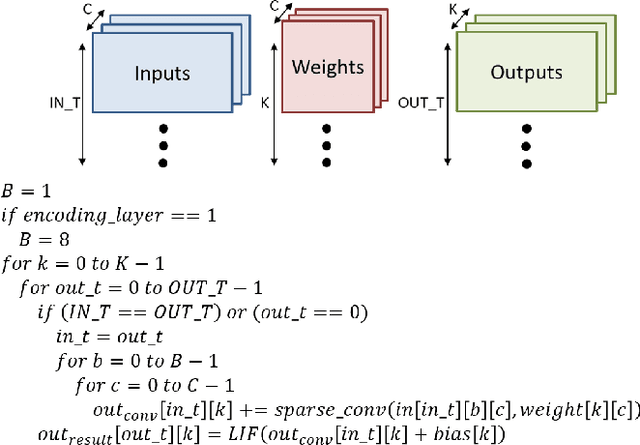
Spiking neural networks (SNNs), which are inspired by the human brain, have recently gained popularity due to their relatively simple and low-power hardware for transmitting binary spikes and highly sparse activation maps. However, because SNNs contain extra time dimension information, the SNN accelerator will require more buffers and take longer to infer, especially for the more difficult high-resolution object detection task. As a result, this paper proposes a sparse compressed spiking neural network accelerator that takes advantage of the high sparsity of activation maps and weights by utilizing the proposed gated one-to-all product for low power and highly parallel model execution. The experimental result of the neural network shows 71.5$\%$ mAP with mixed (1,3) time steps on the IVS 3cls dataset. The accelerator with the TSMC 28nm CMOS process can achieve 1024$\times$576@29 frames per second processing when running at 500MHz with 35.88TOPS/W energy efficiency and 1.05mJ energy consumption per frame.