 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Perceptual Learned Source-Channel Coding for High-Fidelity Image Semantic Transmission
May 26, 2022

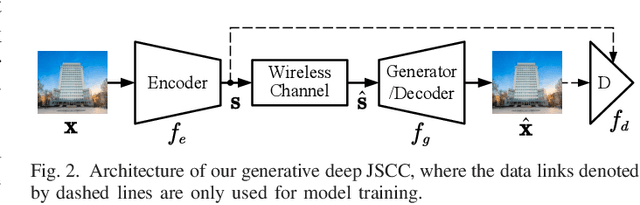
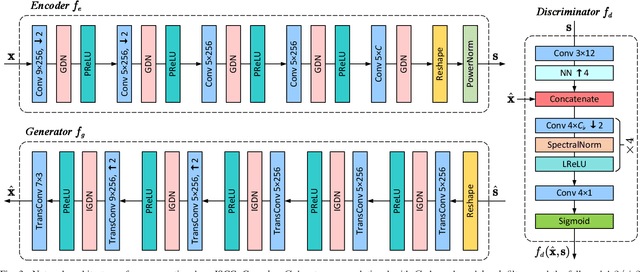
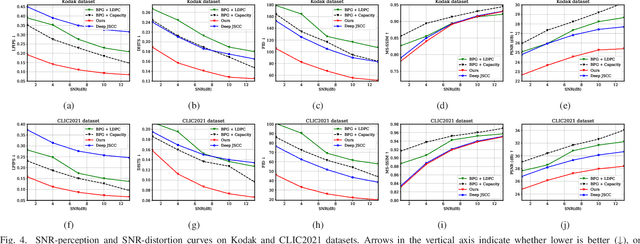
As one novel approach to realize end-to-end wireless image semantic transmission, deep learning-based joint source-channel coding (deep JSCC) method is emerging in both deep learning and communication communities. However, current deep JSCC image transmission systems are typically optimized for traditional distortion metrics such as peak signal-to-noise ratio (PSNR) or multi-scale structural similarity (MS-SSIM). But for low transmission rates, due to the imperfect wireless channel, these distortion metrics lose significance as they favor pixel-wise preservation. To account for human visual perception in semantic communications, it is of great importance to develop new deep JSCC systems optimized beyond traditional PSNR and MS-SSIM metrics. In this paper, we introduce adversarial losses to optimize deep JSCC, which tends to preserve global semantic information and local texture. Our new deep JSCC architecture combines encoder, wireless channel, decoder/generator, and discriminator, which are jointly learned under both perceptual and adversarial losses. Our method yields human visually much more pleasing results than state-of-the-art engineered image coded transmission systems and traditional deep JSCC systems. A user study confirms that achieving the perceptually similar end-to-end image transmission quality, the proposed method can save about 50\% wireless channel bandwidth cost.
Importance is in your attention: agent importance prediction for autonomous driving
Apr 19, 2022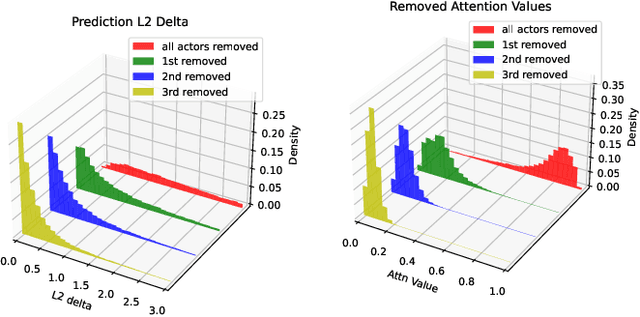
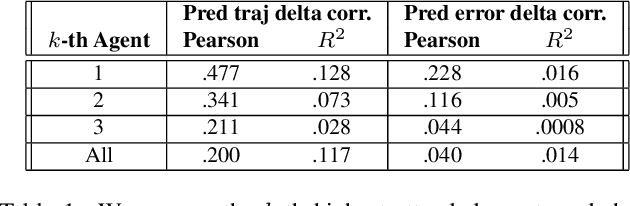

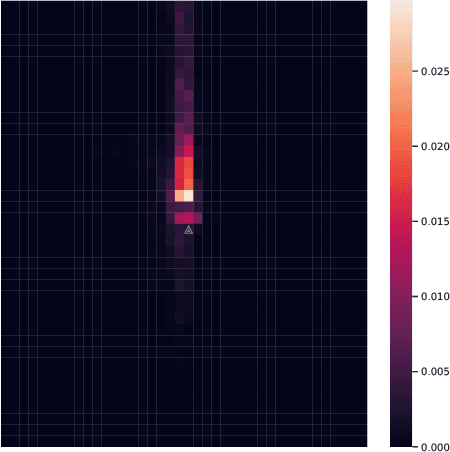
Trajectory prediction is an important task in autonomous driving. State-of-the-art trajectory prediction models often use attention mechanisms to model the interaction between agents. In this paper, we show that the attention information from such models can also be used to measure the importance of each agent with respect to the ego vehicle's future planned trajectory. Our experiment results on the nuPlans dataset show that our method can effectively find and rank surrounding agents by their impact on the ego's plan.
Safeguarding NOMA Networks via Reconfigurable Dual-Functional Surface under Imperfect CSI
May 29, 2022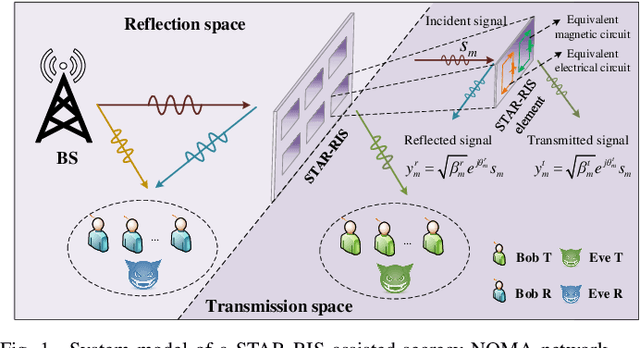
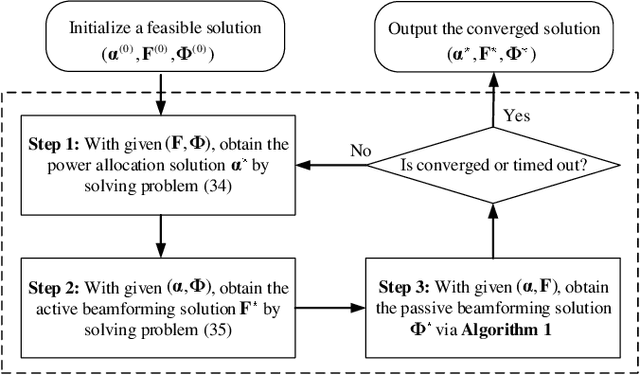
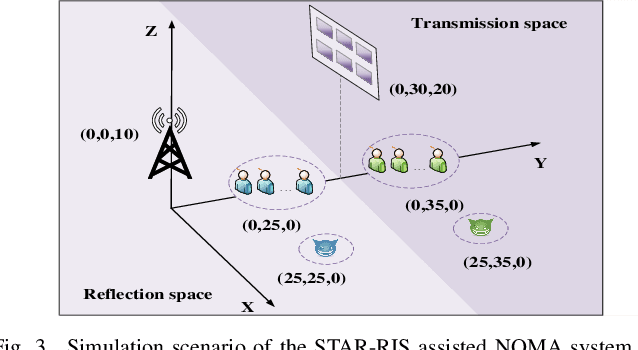
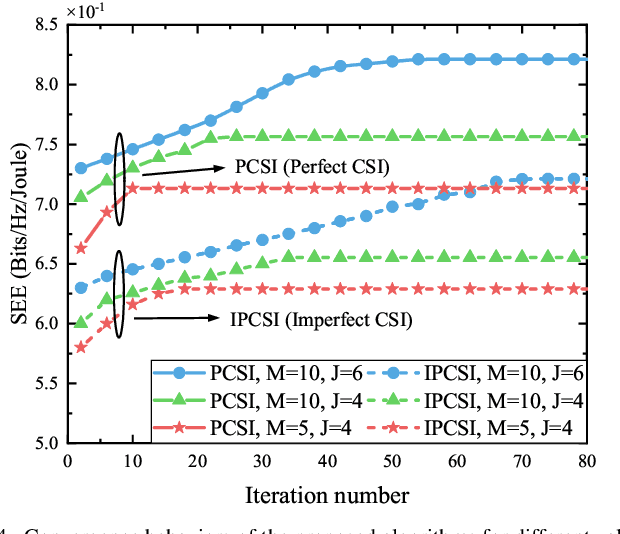
This paper investigates the use of the reconfigurable dual-functional surface to guarantee the full-space secure transmission in non-orthogonal multiple access (NOMA) networks. In the presence of eavesdroppers, the downlink communication from the base station to the legitimate users is safeguarded by the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS), where three practical operating protocols, namely energy splitting (ES), mode selection (MS), and time splitting (TS), are studied. The joint optimization of power allocation, active and passive beamforming is investigated to maximize the secrecy energy efficiency (SEE), taking into account the imperfect channel state information (CSI) of all channels. For ES, by approximating the semi-infinite constraints with the S-procedure and general sign-definiteness, the problem is solved by an alternating optimization framework. Besides, the proposed algorithm is extended to the MS protocol by solving a mixed-integer non-convex problem. While for TS, a two-layer iterative method is proposed. Simulation results show that: 1) The proposed STAR-RIS assisted NOMA networks are able to provide up to 33.6\% higher SEE than conventional RIS counterparts; 2) TS and ES protocols are generally preferable for low and high power domain, respectively; 3) The accuracy of CSI estimation and the bit resolution power consumption are crucial to reap the SEE benefits offered by STAR-RIS.
* This paper has been accepted by the IEEE Journal of Selected Topics in Signal Processing
Perception-Intention-Action Cycle in Human-Robot Collaborative Tasks
Jun 01, 2022
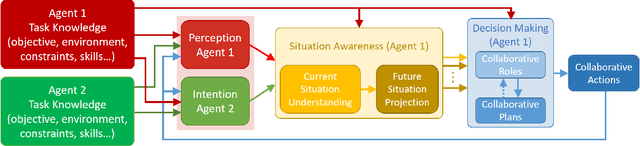
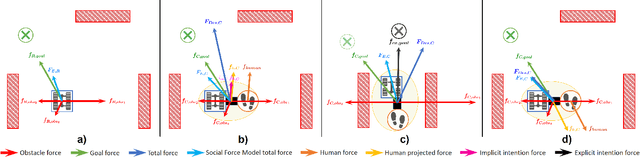

In this work we argue that in Human-Robot Collaboration (HRC) tasks, the Perception-Action cycle in HRC tasks can not fully explain the collaborative behaviour of the human and robot and it has to be extended to Perception-Intention-Action cycle, where Intention is a key topic. In some cases, agent Intention can be perceived or inferred by the other agent, but in others, it has to be explicitly informed to the other agent to succeed the goal of the HRC task. The Perception-Intention-Action cycle includes three basic functional procedures: Perception-Intention, Situation Awareness and Action. The Perception and the Intention are the input of the Situation Awareness, which evaluates the current situation and projects it, into the future situation. The agents receive this information, plans and agree with the actions to be executed and modify their action roles while perform the HRC task. In this work, we validate the Perception-Intention-Action cycle in a joint object transportation task, modeling the Perception-Intention-Action cycle through a force model which uses real life and social forces. The perceived world is projected into a force world and the human intention (perceived or informed) is also modelled as a force that acts in the HRC task. Finally, we show that the action roles (master-slave, collaborative, neutral or adversary) are intrinsic to any HRC task and they appear in the different steps of a collaborative sequence of actions performed during the task.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
May 26, 2022
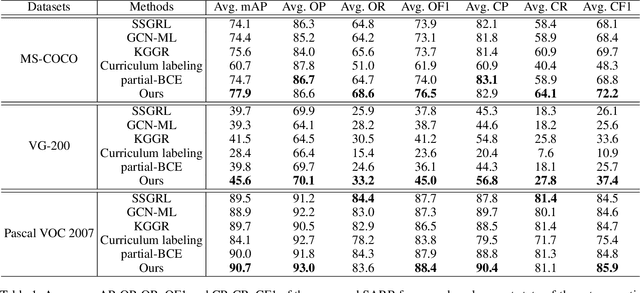
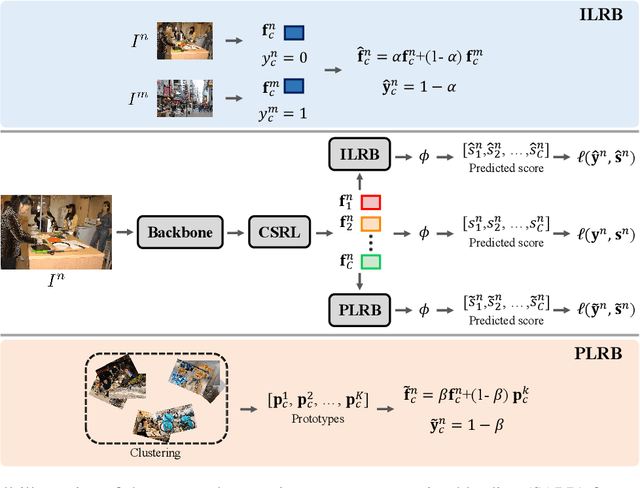
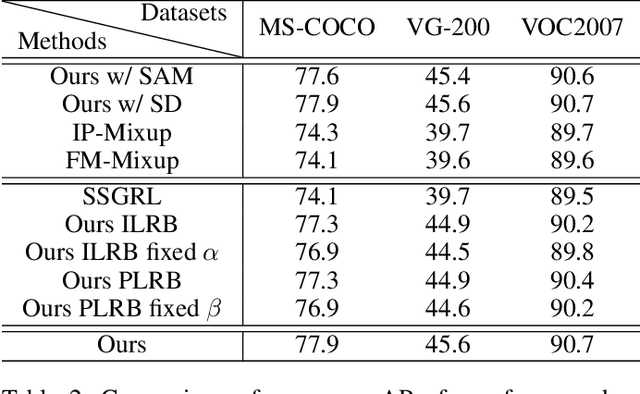
Despite achieving impressive progress, current multi-label image recognition (MLR) algorithms heavily depend on large-scale datasets with complete labels, making collecting large-scale datasets extremely time-consuming and labor-intensive. Training the multi-label image recognition models with partial labels (MLR-PL) is an alternative way to address this issue, in which merely some labels are known while others are unknown for each image (see Figure 1). However, current MLP-PL algorithms mainly rely on the pre-trained image classification or similarity models to generate pseudo labels for the unknown labels. Thus, they depend on a certain amount of data annotations and inevitably suffer from obvious performance drops, especially when the known label proportion is low. To address this dilemma, we propose a unified semantic-aware representation blending (SARB) that consists of two crucial modules to blend multi-granularity category-specific semantic representation across different images to transfer information of known labels to complement unknown labels. Extensive experiments on the MS-COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed SARB consistently outperforms current state-of-the-art algorithms on all known label proportion settings. Concretely, it obtain the average mAP improvement of 1.9%, 4.5%, 1.0% on the three benchmark datasets compared with the second-best algorithm.
Sensitive Information Detection: Recursive Neural Networks for Encoding Context
Aug 25, 2020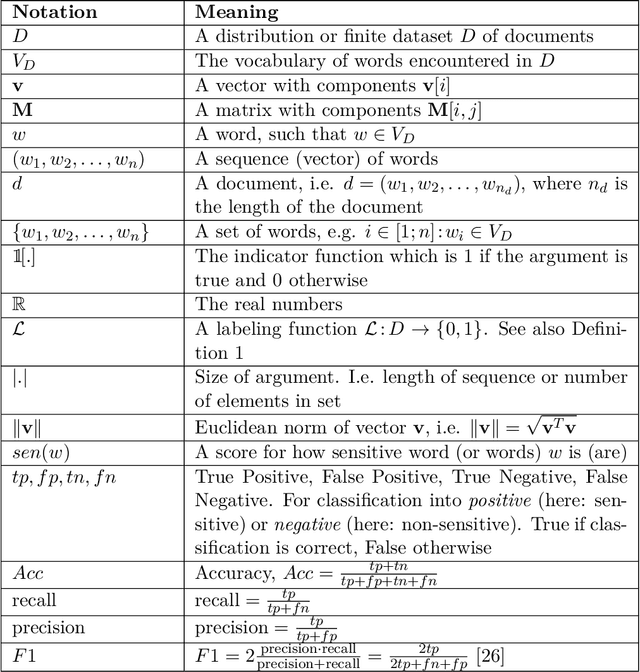
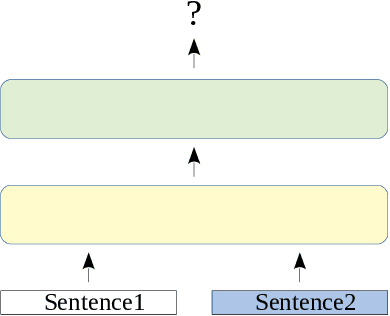
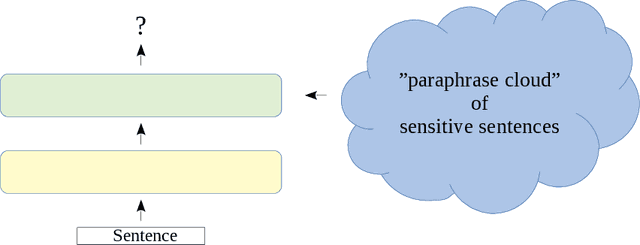

The amount of data for processing and categorization grows at an ever increasing rate. At the same time the demand for collaboration and transparency in organizations, government and businesses, drives the release of data from internal repositories to the public or 3rd party domain. This in turn increase the potential of sharing sensitive information. The leak of sensitive information can potentially be very costly, both financially for organizations, but also for individuals. In this work we address the important problem of sensitive information detection. Specially we focus on detection in unstructured text documents. We show that simplistic, brittle rule sets for detecting sensitive information only find a small fraction of the actual sensitive information. Furthermore we show that previous state-of-the-art approaches have been implicitly tailored to such simplistic scenarios and thus fail to detect actual sensitive content. We develop a novel family of sensitive information detection approaches which only assumes access to labeled examples, rather than unrealistic assumptions such as access to a set of generating rules or descriptive topical seed words. Our approaches are inspired by the current state-of-the-art for paraphrase detection and we adapt deep learning approaches over recursive neural networks to the problem of sensitive information detection. We show that our context-based approaches significantly outperforms the family of previous state-of-the-art approaches for sensitive information detection, so-called keyword-based approaches, on real-world data and with human labeled examples of sensitive and non-sensitive documents.
InducT-GCN: Inductive Graph Convolutional Networks for Text Classification
Jun 01, 2022
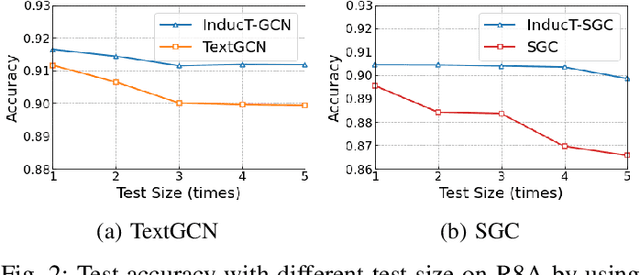
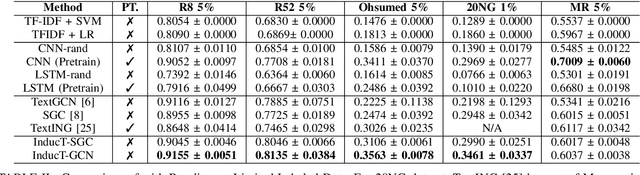
Text classification aims to assign labels to textual units by making use of global information. Recent studies have applied graph neural network (GNN) to capture the global word co-occurrence in a corpus. Existing approaches require that all the nodes (training and test) in a graph are present during training, which are transductive and do not naturally generalise to unseen nodes. To make those models inductive, they use extra resources, like pretrained word embedding. However, high-quality resource is not always available and hard to train. Under the extreme settings with no extra resource and limited amount of training set, can we still learn an inductive graph-based text classification model? In this paper, we introduce a novel inductive graph-based text classification framework, InducT-GCN (InducTive Graph Convolutional Networks for Text classification). Compared to transductive models that require test documents in training, we construct a graph based on the statistics of training documents only and represent document vectors with a weighted sum of word vectors. We then conduct one-directional GCN propagation during testing. Across five text classification benchmarks, our InducT-GCN outperformed state-of-the-art methods that are either transductive in nature or pre-trained additional resources. We also conducted scalability testing by gradually increasing the data size and revealed that our InducT-GCN can reduce the time and space complexity. The code is available on: https://github.com/usydnlp/InductTGCN.
Efficient and Robust Semantic Mapping for Indoor Environments
Mar 11, 2022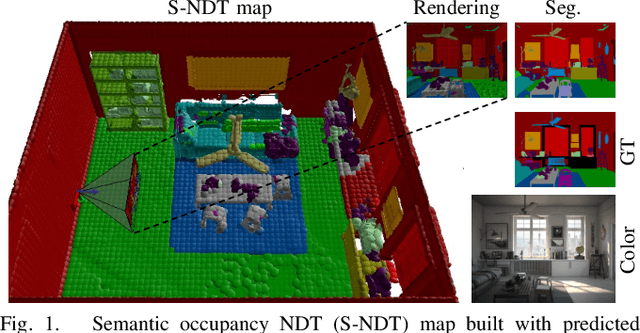
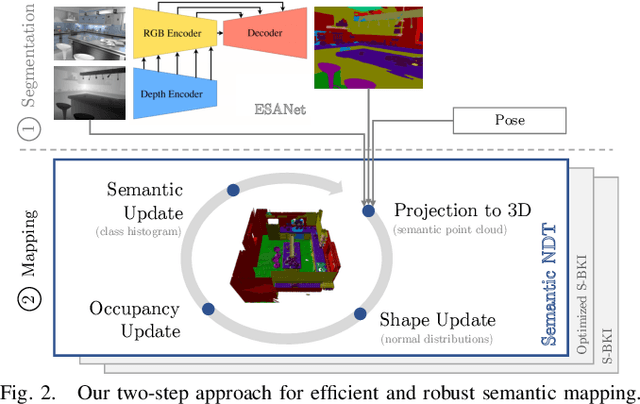


A key proficiency an autonomous mobile robot must have to perform high-level tasks is a strong understanding of its environment. This involves information about what types of objects are present, where they are, what their spatial extend is, and how they can be reached, i.e., information about free space is also crucial. Semantic maps are a powerful instrument providing such information. However, applying semantic segmentation and building 3D maps with high spatial resolution is challenging given limited resources on mobile robots. In this paper, we incorporate semantic information into efficient occupancy normal distribution transform (NDT) maps to enable real-time semantic mapping on mobile robots. On the publicly available dataset Hypersim, we show that, due to their sub-voxel accuracy, semantic NDT maps are superior to other approaches. We compare them to the recent state-of-the-art approach based on voxels and semantic Bayesian spatial kernel inference~(S-BKI) and to an optimized version of it derived in this paper. The proposed semantic NDT maps can represent semantics to the same level of detail, while mapping is 2.7 to 17.5 times faster. For the same grid resolution, they perform significantly better, while mapping is up to more than 5 times faster. Finally, we prove the real-world applicability of semantic NDT maps with qualitative results in a domestic application.
Recurrence-in-Recurrence Networks for Video Deblurring
Mar 12, 2022
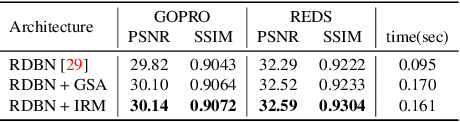
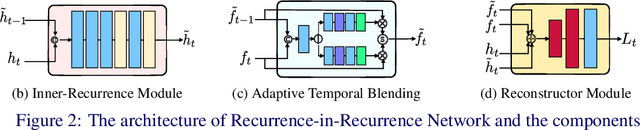
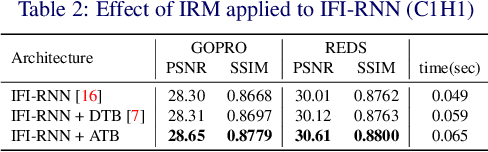
State-of-the-art video deblurring methods often adopt recurrent neural networks to model the temporal dependency between the frames. While the hidden states play key role in delivering information to the next frame, abrupt motion blur tend to weaken the relevance in the neighbor frames. In this paper, we propose recurrence-in-recurrence network architecture to cope with the limitations of short-ranged memory. We employ additional recurrent units inside the RNN cell. First, we employ inner-recurrence module (IRM) to manage the long-ranged dependency in a sequence. IRM learns to keep track of the cell memory and provides complementary information to find the deblurred frames. Second, we adopt an attention-based temporal blending strategy to extract the necessary part of the information in the local neighborhood. The adpative temporal blending (ATB) can either attenuate or amplify the features by the spatial attention. Our extensive experimental results and analysis validate the effectiveness of IRM and ATB on various RNN architectures.
* accepted paper in BMVC 2021
Relation-guided acoustic scene classification aided with event embeddings
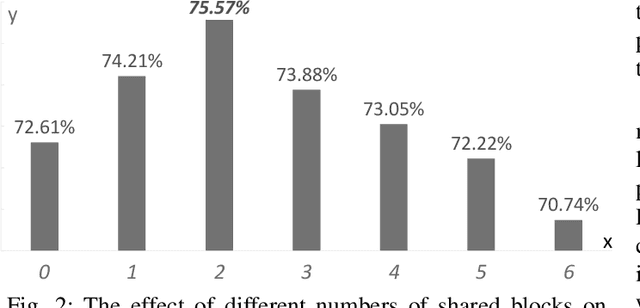
May 01, 2022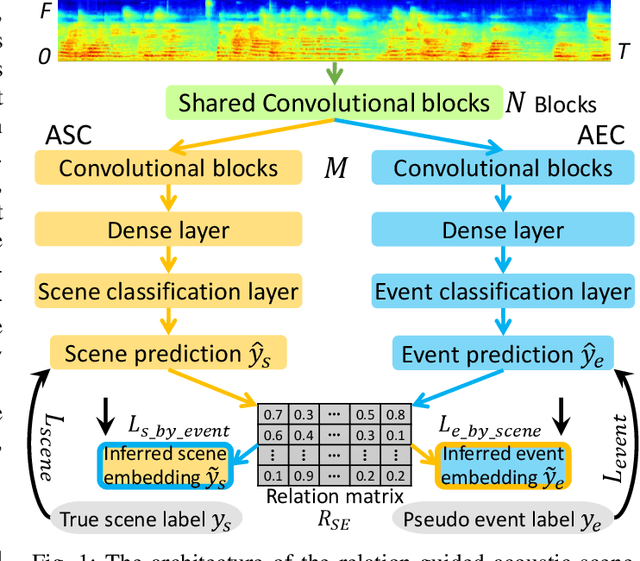
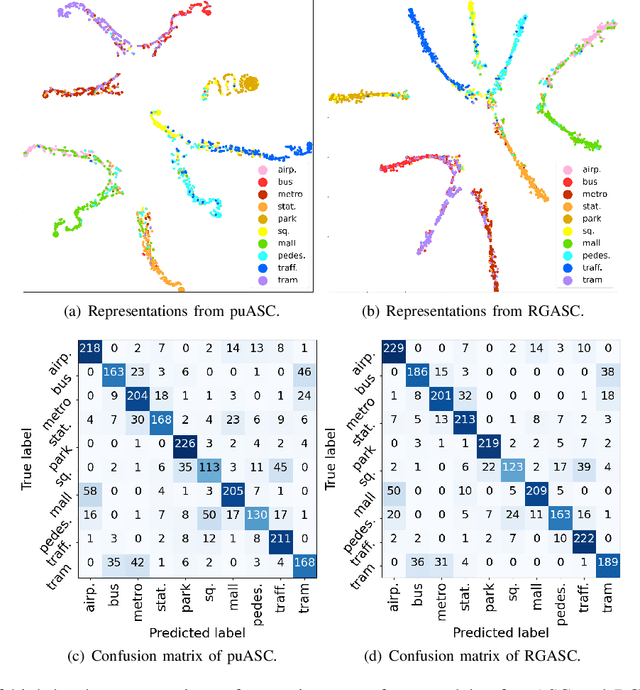
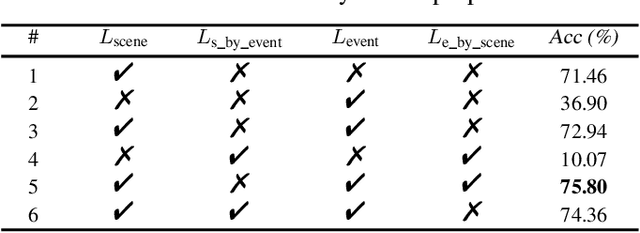
In real life, acoustic scenes and audio events are naturally correlated. Humans instinctively rely on fine-grained audio events as well as the overall sound characteristics to distinguish diverse acoustic scenes. Yet, most previous approaches treat acoustic scene classification (ASC) and audio event classification (AEC) as two independent tasks. A few studies on scene and event joint classification either use synthetic audio datasets that hardly match the real world, or simply use the multi-task framework to perform two tasks at the same time. Neither of these two ways makes full use of the implicit and inherent relation between fine-grained events and coarse-grained scenes. To this end, this paper proposes a relation-guided ASC (RGASC) model to further exploit and coordinate the scene-event relation for the mutual benefit of scene and event recognition. The TUT Urban Acoustic Scenes 2018 dataset (TUT2018) is annotated with pseudo labels of events by a simple and efficient audio-related pre-trained model PANN, which is one of the state-of-the-art AEC models. Then, a prior scene-event relation matrix is defined as the average probability of the presence of each event type in each scene class. Finally, the two-tower RGASC model is jointly trained on the real-life dataset TUT2018 for both scene and event classification. The following results are achieved. 1) RGASC effectively coordinates the true information of coarse-grained scenes and the pseudo information of fine-grained events. 2) The event embeddings learned from pseudo labels under the guidance of prior scene-event relations help reduce the confusion between similar acoustic scenes. 3) Compared with other (non-ensemble) methods, RGASC improves the scene classification accuracy on the real-life dataset.