 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARA: Agentic Reproducibility Assessment For Scalable Support Of Scientific Peer-Review
May 04, 2026Scientific peer review increasingly struggles to assess reproducibility at the scale and complexity of modern research output. Evaluating reproducibility requires reconstructing experimental dependencies, methodological choices, data flows, and result-generating procedures, which often exceeds what human reviewers can provide. Agentic Reproducibility Assessment (ARA) formalizes reproducibility assessment as a structured reasoning task over scientific documents. Given a paper, ARA extracts a directed workflow graph linking sources, methods, experiments, and outputs, then evaluates its reconstructability using structural and content-based scores for reproducibility assessments. Experiments on 213 ReScience C articles - the largest cross-domain benchmark of human-validated computational reproducibility studies considered to date - demonstrate ARA's generalizability and consistent workflow reconstruction and assessment across LLMs, model temperatures, and scientific domains. ARA achieves ~61% accuracy on three benchmarks, and the highest accuracy reported on ReproBench (60.71% vs. 36.84%) and GoldStandardDB (61.68% vs. 43.56%), highlighting its potential to complement human review at scale and enabling next-generation peer review. Code and Data available: https://github.com/AndresLaverdeMarin/agentic_reproducibility_assessment.
Patient-Level Multimodal Question Answering from Multi-Site Auscultation Recordings
Mar 09, 2026Auscultation is a vital diagnostic tool, yet its utility is often limited by subjective interpretation. While general-purpose Audio-Language Models (ALMs) excel in general domains, they struggle with the nuances of physiological signals. We propose a framework that aligns multi-site auscultation recordings directly with a frozen Large Language Model (LLM) embedding space via gated cross-attention. By leveraging the LLM's latent world knowledge, our approach moves beyond isolated classification toward holistic, patient-level assessment. On the CaReSound benchmark, our model achieves a state-of-the-art 0.865 F1-macro and 0.952 BERTScore. We demonstrate that lightweight, domain-specific encoders rival large-scale ALMs and that multi-site aggregation provides spatial redundancy that mitigates temporal truncation. This alignment of medical acoustics with text foundations offers a scalable path for bridging signal processing and clinical assessment.
How Well Do Multimodal Models Reason on ECG Signals?
Feb 27, 2026While multimodal large language models offer a promising solution to the "black box" nature of health AI by generating interpretable reasoning traces, verifying the validity of these traces remains a critical challenge. Existing evaluation methods are either unscalable, relying on manual clinician review, or superficial, utilizing proxy metrics (e.g. QA) that fail to capture the semantic correctness of clinical logic. In this work, we introduce a reproducible framework for evaluating reasoning in ECG signals. We propose decomposing reasoning into two distinct, components: (i) Perception, the accurate identification of patterns within the raw signal, and (ii) Deduction, the logical application of domain knowledge to those patterns. To evaluate Perception, we employ an agentic framework that generates code to empirically verify the temporal structures described in the reasoning trace. To evaluate Deduction, we measure the alignment of the model's logic against a structured database of established clinical criteria in a retrieval-based approach. This dual-verification method enables the scalable assessment of "true" reasoning capabilities.
TS-Haystack: A Multi-Scale Retrieval Benchmark for Time Series Language Models
Feb 15, 2026Time Series Language Models (TSLMs) are emerging as unified models for reasoning over continuous signals in natural language. However, long-context retrieval remains a major limitation: existing models are typically trained and evaluated on short sequences, while real-world time-series sensor streams can span millions of datapoints. This mismatch requires precise temporal localization under strict computational constraints, a regime that is not captured by current benchmarks. We introduce TS-Haystack, a long-context temporal retrieval benchmark comprising ten task types across four categories: direct retrieval, temporal reasoning, multi-step reasoning and contextual anomaly. The benchmark uses controlled needle insertion by embedding short activity bouts into longer longitudinal accelerometer recordings, enabling systematic evaluation across context lengths ranging from seconds to 2 hours per sample. We hypothesize that existing TSLM time series encoders overlook temporal granularity as context length increases, creating a task-dependent effect: compression aids classification but impairs retrieval of localized events. Across multiple model and encoding strategies, we observe a consistent divergence between classification and retrieval behavior. Learned latent compression preserves or improves classification accuracy at compression ratios up to 176$\times$, but retrieval performance degrades with context length, incurring in the loss of temporally localized information. These results highlight the importance of architectural designs that decouple sequence length from computational complexity while preserving temporal fidelity.
EvoMorph: Counterfactual Explanations for Continuous Time-Series Extrinsic Regression Applied to Photoplethysmography
Jan 15, 2026Wearable devices enable continuous, population-scale monitoring of physiological signals, such as photoplethysmography (PPG), creating new opportunities for data-driven clinical assessment. Time-series extrinsic regression (TSER) models increasingly leverage PPG signals to estimate clinically relevant outcomes, including heart rate, respiratory rate, and oxygen saturation. For clinical reasoning and trust, however, single point estimates alone are insufficient: clinicians must also understand whether predictions are stable under physiologically plausible variations and to what extent realistic, attainable changes in physiological signals would meaningfully alter a model's prediction. Counterfactual explanations (CFE) address these "what-if" questions, yet existing time series CFE generation methods are largely restricted to classification, overlook waveform morphology, and often produce physiologically implausible signals, limiting their applicability to continuous biomedical time series. To address these limitations, we introduce EvoMorph, a multi-objective evolutionary framework for generating physiologically plausible and diverse CFE for TSER applications. EvoMorph optimizes morphology-aware objectives defined on interpretable signal descriptors and applies transformations to preserve the waveform structure. We evaluated EvoMorph on three PPG datasets (heart rate, respiratory rate, and oxygen saturation) against a nearest-unlike-neighbor baseline. In addition, in a case study, we evaluated EvoMorph as a tool for uncertainty quantification by relating counterfactual sensitivity to bootstrap-ensemble uncertainty and data-density measures. Overall, EvoMorph enables the generation of physiologically-aware counterfactuals for continuous biomedical signals and supports uncertainty-aware interpretability, advancing trustworthy model analysis for clinical time-series applications.
Comparative Efficacy of Commercial Wearables for Circadian Rhythm Home Monitoring from Activity, Heart Rate, and Core Body Temperature
Apr 04, 2024



Circadian rhythms govern biological patterns that follow a 24-hour cycle. Dysfunctions in circadian rhythms can contribute to various health problems, such as sleep disorders. Current circadian rhythm assessment methods, often invasive or subjective, limit circadian rhythm monitoring to laboratories. Hence, this study aims to investigate scalable consumer-centric wearables for circadian rhythm monitoring outside traditional laboratories. In a two-week longitudinal study conducted in real-world settings, 36 participants wore an Actigraph, a smartwatch, and a core body temperature sensor to collect activity, temperature, and heart rate data. We evaluated circadian rhythms calculated from commercial wearables by comparing them with circadian rhythm reference measures, i.e., Actigraph activities and chronotype questionnaire scores. The circadian rhythm metric acrophases, determined from commercial wearables using activity, heart rate, and temperature data, significantly correlated with the acrophase derived from Actigraph activities (r=0.96, r=0.87, r=0.79; all p<0.001) and chronotype questionnaire (r=-0.66, r=-0.73, r=-0.61; all p<0.001). The acrophases obtained concurrently from consumer sensors significantly predicted the chronotype (R2=0.64; p<0.001). Our study validates commercial sensors for circadian rhythm assessment, highlighting their potential to support maintaining healthy rhythms and provide scalable and timely health monitoring in real-life scenarios.
Efficient and Robust Semantic Mapping for Indoor Environments
Mar 11, 2022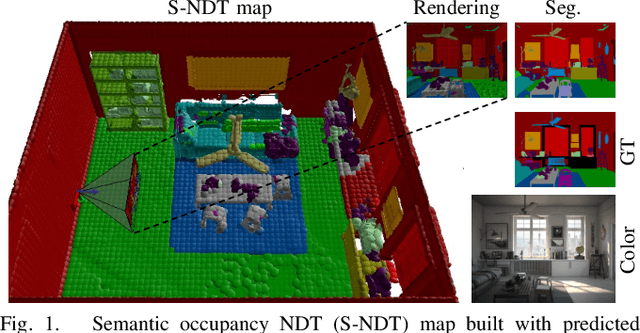
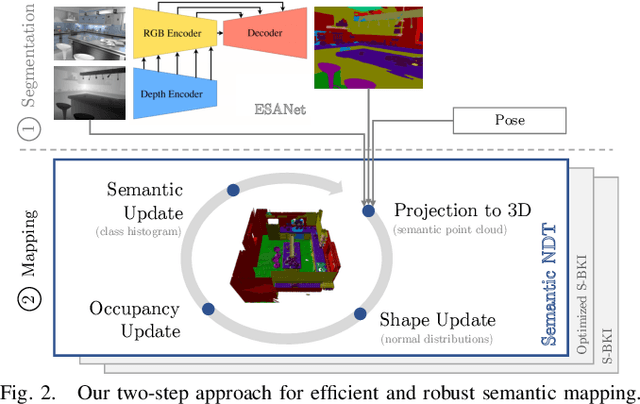


A key proficiency an autonomous mobile robot must have to perform high-level tasks is a strong understanding of its environment. This involves information about what types of objects are present, where they are, what their spatial extend is, and how they can be reached, i.e., information about free space is also crucial. Semantic maps are a powerful instrument providing such information. However, applying semantic segmentation and building 3D maps with high spatial resolution is challenging given limited resources on mobile robots. In this paper, we incorporate semantic information into efficient occupancy normal distribution transform (NDT) maps to enable real-time semantic mapping on mobile robots. On the publicly available dataset Hypersim, we show that, due to their sub-voxel accuracy, semantic NDT maps are superior to other approaches. We compare them to the recent state-of-the-art approach based on voxels and semantic Bayesian spatial kernel inference~(S-BKI) and to an optimized version of it derived in this paper. The proposed semantic NDT maps can represent semantics to the same level of detail, while mapping is 2.7 to 17.5 times faster. For the same grid resolution, they perform significantly better, while mapping is up to more than 5 times faster. Finally, we prove the real-world applicability of semantic NDT maps with qualitative results in a domestic application.