 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepRM: Deep Recurrent Matching for 6D Pose Refinement
May 28, 2022
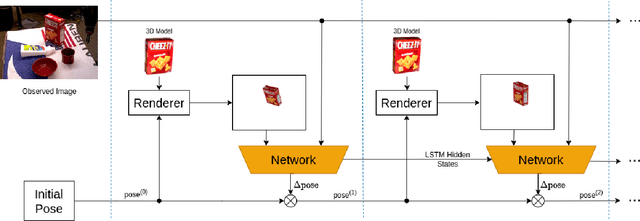
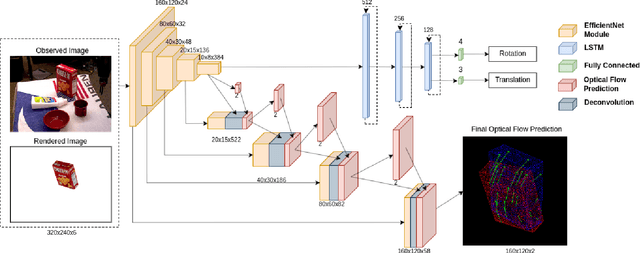
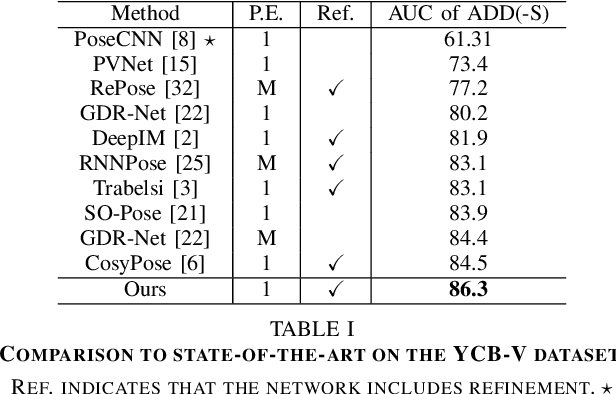
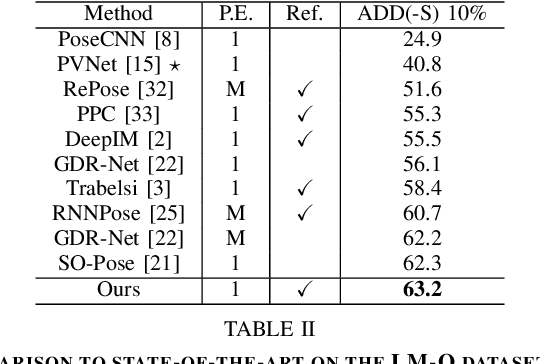
Precise 6D pose estimation of rigid objects from RGB images is a critical but challenging task in robotics and augmented reality. To address this problem, we propose DeepRM, a novel recurrent network architecture for 6D pose refinement. DeepRM leverages initial coarse pose estimates to render synthetic images of target objects. The rendered images are then matched with the observed images to predict a rigid transform for updating the previous pose estimate. This process is repeated to incrementally refine the estimate at each iteration. LSTM units are used to propagate information through each refinement step, significantly improving overall performance. In contrast to many 2-stage Perspective-n-Point based solutions, DeepRM is trained end-to-end, and uses a scalable backbone that can be tuned via a single parameter for accuracy and efficiency. During training, a multi-scale optical flow head is added to predict the optical flow between the observed and synthetic images. Optical flow prediction stabilizes the training process, and enforces the learning of features that are relevant to the task of pose estimation. Our results demonstrate that DeepRM achieves state-of-the-art performance on two widely accepted challenging datasets.
BAN-Cap: A Multi-Purpose English-Bangla Image Descriptions Dataset
May 28, 2022

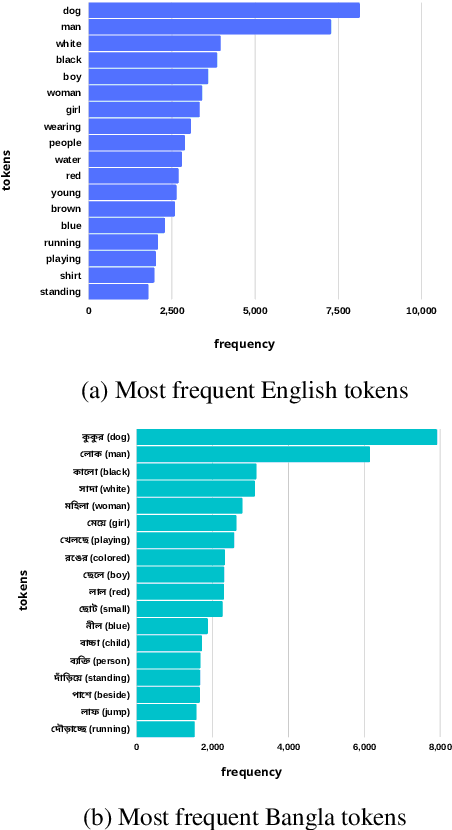

As computers have become efficient at understanding visual information and transforming it into a written representation, research interest in tasks like automatic image captioning has seen a significant leap over the last few years. While most of the research attention is given to the English language in a monolingual setting, resource-constrained languages like Bangla remain out of focus, predominantly due to a lack of standard datasets. Addressing this issue, we present a new dataset BAN-Cap following the widely used Flickr8k dataset, where we collect Bangla captions of the images provided by qualified annotators. Our dataset represents a wider variety of image caption styles annotated by trained people from different backgrounds. We present a quantitative and qualitative analysis of the dataset and the baseline evaluation of the recent models in Bangla image captioning. We investigate the effect of text augmentation and demonstrate that an adaptive attention-based model combined with text augmentation using Contextualized Word Replacement (CWR) outperforms all state-of-the-art models for Bangla image captioning. We also present this dataset's multipurpose nature, especially on machine translation for Bangla-English and English-Bangla. This dataset and all the models will be useful for further research.
Neural operator learning of heterogeneous mechanobiological insults contributing to aortic aneurysms
May 08, 2022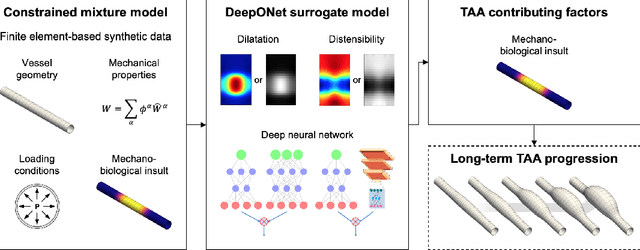

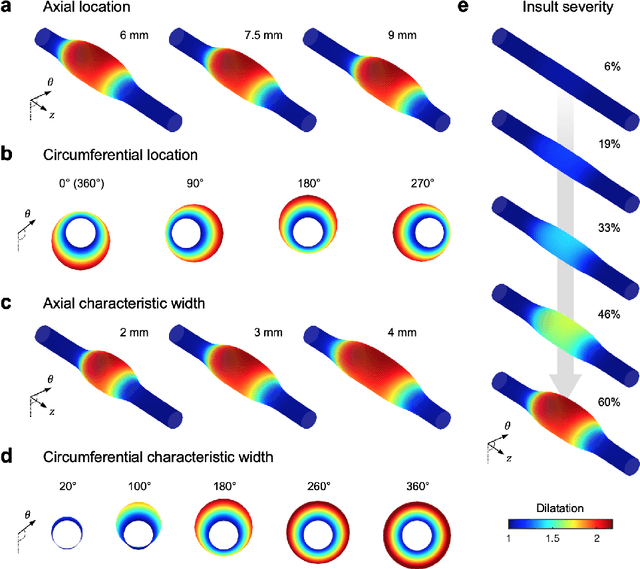

Thoracic aortic aneurysm (TAA) is a localized dilatation of the aorta resulting from compromised wall composition, structure, and function, which can lead to life-threatening dissection or rupture. Several genetic mutations and predisposing factors that contribute to TAA have been studied in mouse models to characterize specific changes in aortic microstructure and material properties that result from a wide range of mechanobiological insults. Assessments of TAA progression in vivo is largely limited to measurements of aneurysm size and growth rate. It has been shown that aortic geometry alone is not sufficient to predict the patient-specific progression of TAA but computational modeling of the evolving biomechanics of the aorta could predict future geometry and properties from initiating insults. In this work, we present an integrated framework to train a deep operator network (DeepONet)-based surrogate model to identify contributing factors for TAA by using FE-based datasets of aortic growth and remodeling resulting from prescribed insults. For training data, we investigate multiple types of TAA risk factors and spatial distributions within a constrained mixture model to generate axial--azimuthal maps of aortic dilatation and distensibility. The trained network is then capable of predicting the initial distribution and extent of the insult from a given set of dilatation and distensibility information. Two DeepONet frameworks are proposed, one trained on sparse information and one on full-field grayscale images, to gain insight into a preferred neural operator-based approach. Performance of the surrogate models is evaluated through multiple simulations carried out on insult distributions varying from fusiform to complex. We show that the proposed approach can predict patient-specific mechanobiological insult profile with a high accuracy, particularly when based on full-field images.
Chained Generalisation Bounds
Mar 02, 2022
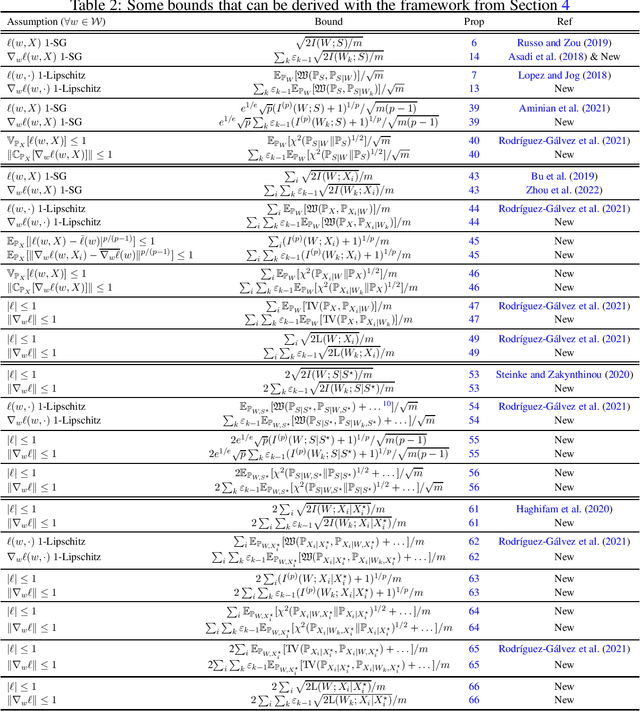
This work discusses how to derive upper bounds for the expected generalisation error of supervised learning algorithms by means of the chaining technique. By developing a general theoretical framework, we establish a duality between generalisation bounds based on the regularity of the loss function, and their chained counterparts, which can be obtained by lifting the regularity assumption from the loss onto its gradient. This allows us to re-derive the chaining mutual information bound from the literature, and to obtain novel chained information-theoretic generalisation bounds, based on the Wasserstein distance and other probability metrics. We show on some toy examples that the chained generalisation bound can be significantly tighter than its standard counterpart, particularly when the distribution of the hypotheses selected by the algorithm is very concentrated. Keywords: Generalisation bounds; Chaining; Information-theoretic bounds; Mutual information; Wasserstein distance; PAC-Bayes.
Chunk-based Nearest Neighbor Machine Translation
May 24, 2022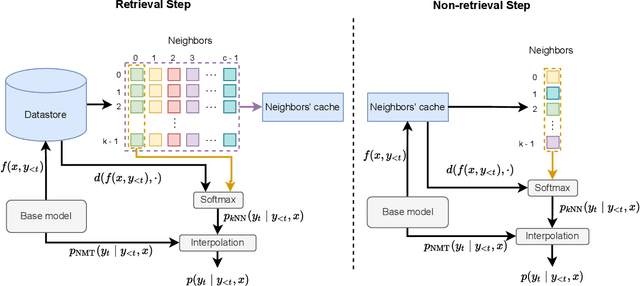
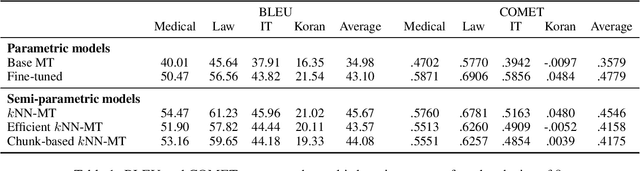
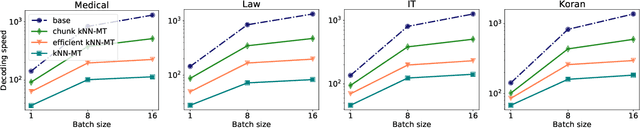
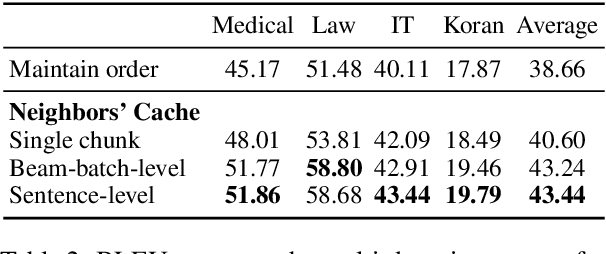
Semi-parametric models, which augment generation with retrieval, have led to impressive results in language modeling and machine translation, due to their ability to leverage information retrieved from a datastore of examples. One of the most prominent approaches, $k$NN-MT, has an outstanding performance on domain adaptation by retrieving tokens from a domain-specific datastore \citep{khandelwal2020nearest}. However, $k$NN-MT requires retrieval for every single generated token, leading to a very low decoding speed (around 8 times slower than a parametric model). In this paper, we introduce a \textit{chunk-based} $k$NN-MT model which retrieves chunks of tokens from the datastore, instead of a single token. We propose several strategies for incorporating the retrieved chunks into the generation process, and for selecting the steps at which the model needs to search for neighbors in the datastore. Experiments on machine translation in two settings, static domain adaptation and ``on-the-fly'' adaptation, show that the chunk-based $k$NN-MT model leads to a significant speed-up (up to 4 times) with only a small drop in translation quality.
E-Scooter Rider Detection and Classification in Dense Urban Environments
May 20, 2022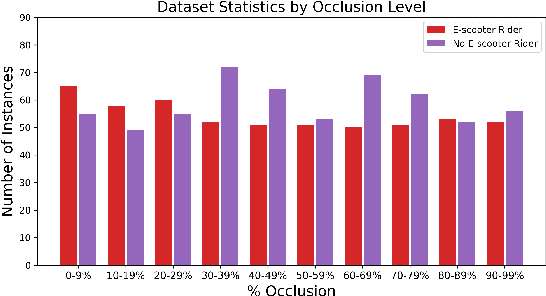

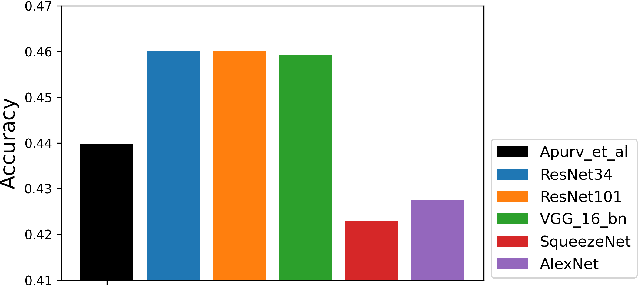
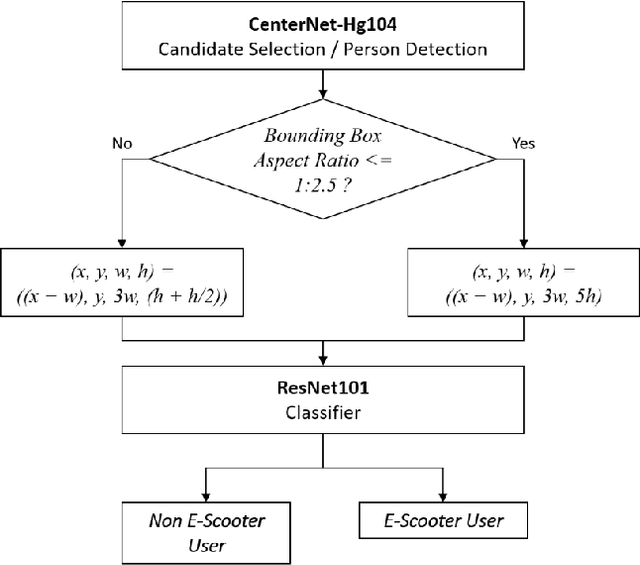
Accurate detection and classification of vulnerable road users is a safety critical requirement for the deployment of autonomous vehicles in heterogeneous traffic. Although similar in physical appearance to pedestrians, e-scooter riders follow distinctly different characteristics of movement and can reach speeds of up to 45kmph. The challenge of detecting e-scooter riders is exacerbated in urban environments where the frequency of partial occlusion is increased as riders navigate between vehicles, traffic infrastructure and other road users. This can lead to the non-detection or mis-classification of e-scooter riders as pedestrians, providing inaccurate information for accident mitigation and path planning in autonomous vehicle applications. This research introduces a novel benchmark for partially occluded e-scooter rider detection to facilitate the objective characterization of detection models. A novel, occlusion-aware method of e-scooter rider detection is presented that achieves a 15.93% improvement in detection performance over the current state of the art.
Multi-Source Transfer Learning for Deep Model-Based Reinforcement Learning
May 28, 2022
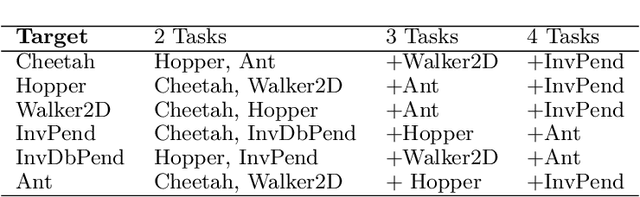
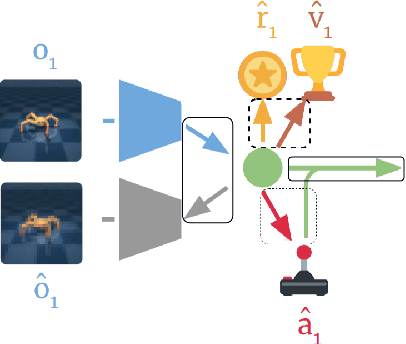
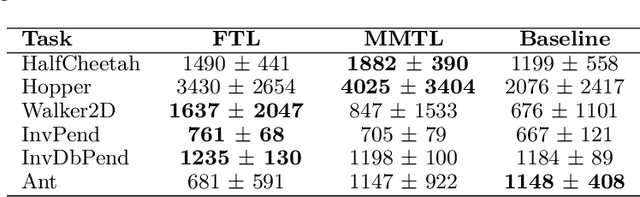
Recent progress in deep model-based reinforcement learning allows agents to be significantly more sample efficient by constructing world models of high-dimensional environments from visual observations, which enables agents to learn complex behaviours in summarized lower-dimensional spaces. Reusing knowledge from relevant previous tasks is another approach for achieving better data-efficiency, which becomes especially more likely when information of multiple previously learned tasks is accessible. We show that the simplified representations of environments resulting from world models provide for promising transfer learning opportunities, by introducing several methods that facilitate world model agents to benefit from multi-source transfer learning. Methods are proposed for autonomously extracting relevant knowledge from both multi-task and multi-agent settings as multi-source origins, resulting in substantial performance improvements compared to learning from scratch. We introduce two additional novel techniques that enable and enhance the proposed approaches respectively: fractional transfer learning and universal feature spaces from a universal autoencoder. We demonstrate that our methods enable transfer learning from different domains with different state, reward, and action spaces by performing extensive and challenging multi-domain experiments on Dreamer, the state-of-the-art world model based algorithm for visual continuous control tasks.
Unbiased Implicit Feedback via Bi-level Optimization
May 31, 2022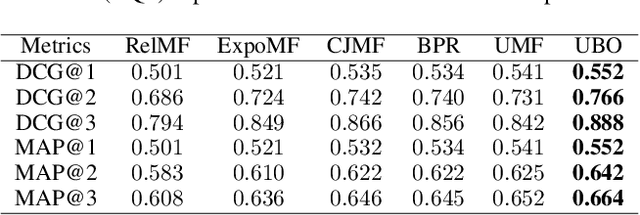
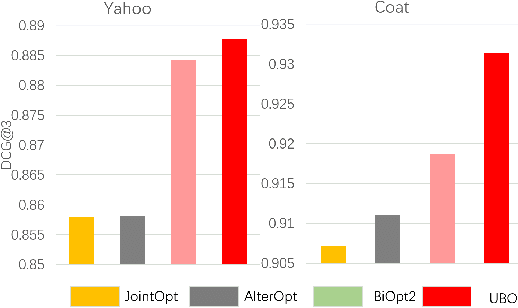
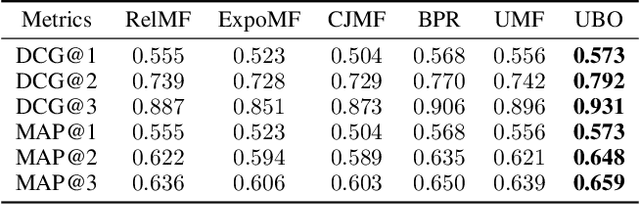
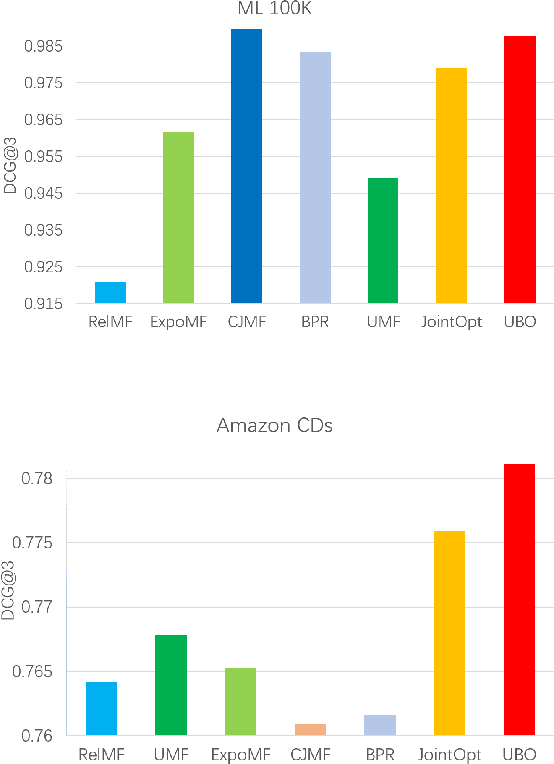
Implicit feedback is widely leveraged in recommender systems since it is easy to collect and provides weak supervision signals. Recent works reveal a huge gap between the implicit feedback and user-item relevance due to the fact that implicit feedback is also closely related to the item exposure. To bridge this gap, existing approaches explicitly model the exposure and propose unbiased estimators to improve the relevance. Unfortunately, these unbiased estimators suffer from the high gradient variance, especially for long-tail items, leading to inaccurate gradient updates and degraded model performance. To tackle this challenge, we propose a low-variance unbiased estimator from a probabilistic perspective, which effectively bounds the variance of the gradient. Unlike previous works which either estimate the exposure via heuristic-based strategies or use a large biased training set, we propose to estimate the exposure via an unbiased small-scale validation set. Specifically, we first parameterize the user-item exposure by incorporating both user and item information, and then construct an unbiased validation set from the biased training set. By leveraging the unbiased validation set, we adopt bi-level optimization to automatically update exposure-related parameters along with recommendation model parameters during the learning. Experiments on two real-world datasets and two semi-synthetic datasets verify the effectiveness of our method.
Instantaneous GNSS Ambiguity Resolution and Attitude Determination via Riemannian Manifold Optimization
May 20, 2022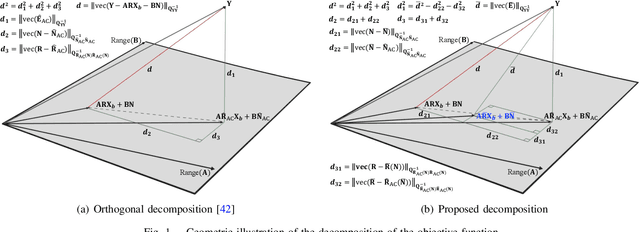
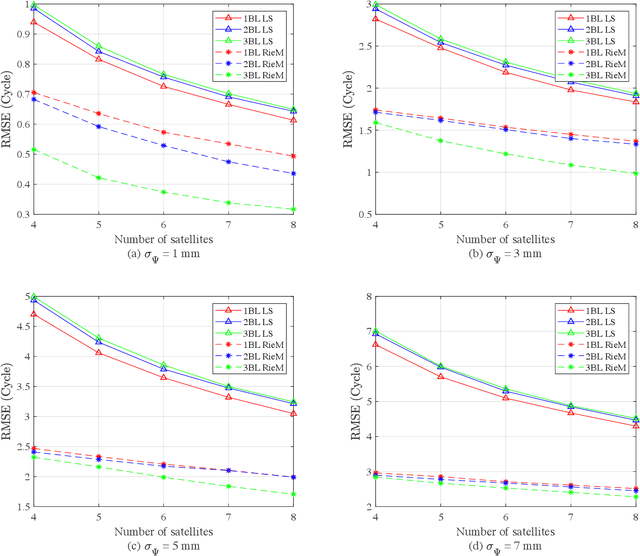
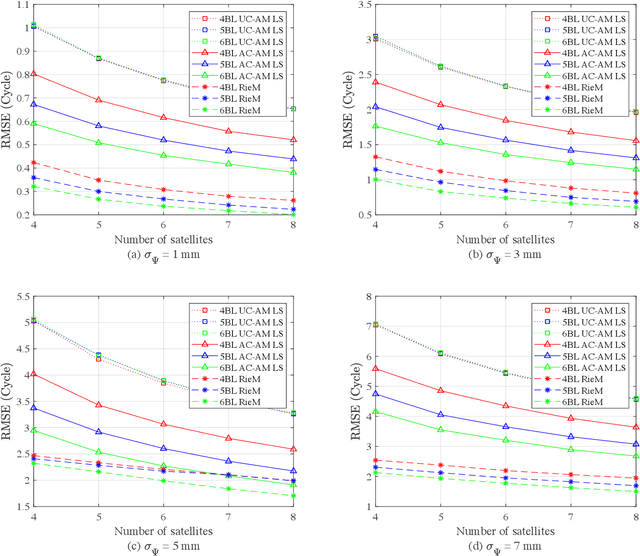
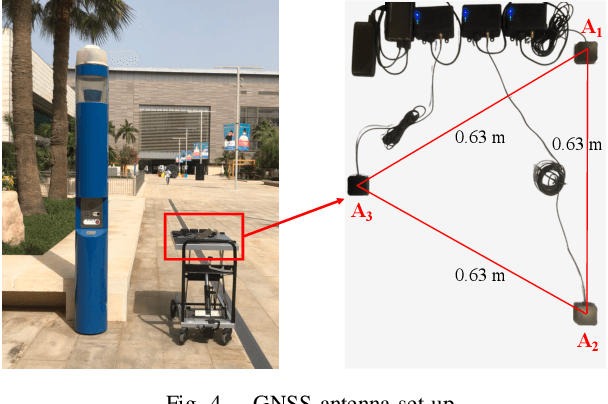
We present an ambiguity resolution method for Global Navigation Satellite System (GNSS)-based attitude determination. A GNSS attitude model with nonlinear constraints is used to rigorously incorporate a priori information. Given the characteristics of the employed nonlinear constraints, we formulate GNSS attitude determination as an optimization problem on a manifold. Then, Riemannian manifold optimization algorithms are utilized to aid ambiguity resolution based on a proposed decomposition of the objective function. The application of manifold geometry enables high-quality float solutions that are critical to reinforcing search-based integer ambiguity resolution in terms of efficiency, availability, and reliability. The proposed approach is characterized by a low computational complexity and a high probability of resolving the ambiguities correctly. The performance of the proposed ambiguity resolution method is tested through a series of simulations and real experiments. Comparisons with the principal benchmarks indicate the superiority of the proposed method as reflected by the high ambiguity resolution success rates.
[Re] Distilling Knowledge via Knowledge Review
May 18, 2022![Figure 1 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F5-Table1-1.png&w=640&q=75)
![Figure 3 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F6-Table2-1.png&w=640&q=75)
![Figure 4 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F3-Figure3-1.png&w=640&q=75)
This effort aims to reproduce the results of experiments and analyze the robustness of the review framework for knowledge distillation introduced in the CVPR '21 paper 'Distilling Knowledge via Knowledge Review' by Chen et al. Previous works in knowledge distillation only studied connections paths between the same levels of the student and the teacher, and cross-level connection paths had not been considered. Chen et al. propose a new residual learning framework to train a single student layer using multiple teacher layers. They also design a novel fusion module to condense feature maps across levels and a loss function to compare feature information stored across different levels to improve performance. In this work, we consistently verify the improvements in test accuracy across student models as reported in the original paper and study the effectiveness of the novel modules introduced by conducting ablation studies and new experiments.