 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAN-Cap: A Multi-Purpose English-Bangla Image Descriptions Dataset
May 28, 2022

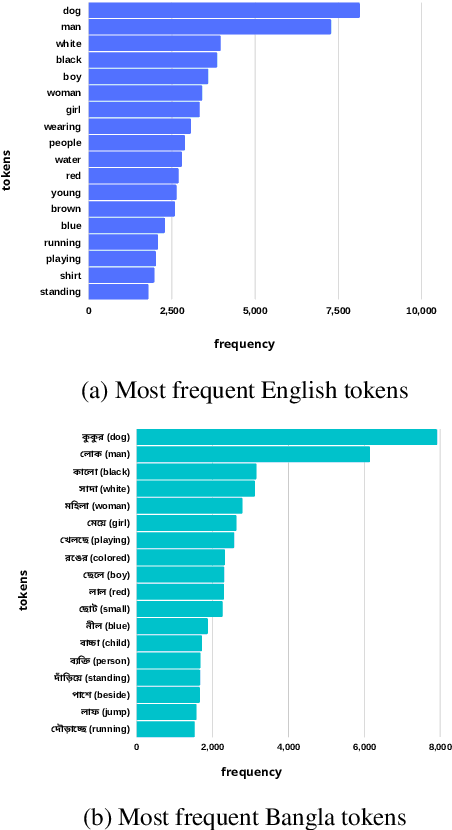

As computers have become efficient at understanding visual information and transforming it into a written representation, research interest in tasks like automatic image captioning has seen a significant leap over the last few years. While most of the research attention is given to the English language in a monolingual setting, resource-constrained languages like Bangla remain out of focus, predominantly due to a lack of standard datasets. Addressing this issue, we present a new dataset BAN-Cap following the widely used Flickr8k dataset, where we collect Bangla captions of the images provided by qualified annotators. Our dataset represents a wider variety of image caption styles annotated by trained people from different backgrounds. We present a quantitative and qualitative analysis of the dataset and the baseline evaluation of the recent models in Bangla image captioning. We investigate the effect of text augmentation and demonstrate that an adaptive attention-based model combined with text augmentation using Contextualized Word Replacement (CWR) outperforms all state-of-the-art models for Bangla image captioning. We also present this dataset's multipurpose nature, especially on machine translation for Bangla-English and English-Bangla. This dataset and all the models will be useful for further research.
Improved Bengali Image Captioning via deep convolutional neural network based encoder-decoder model
Feb 14, 2021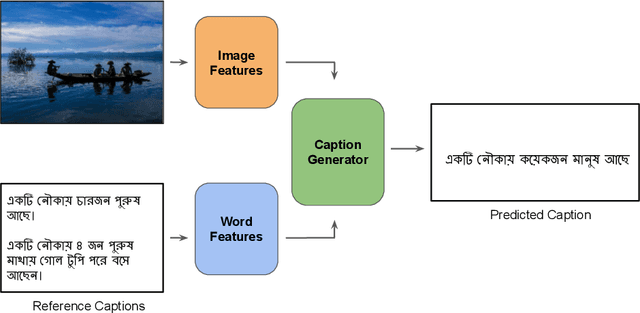
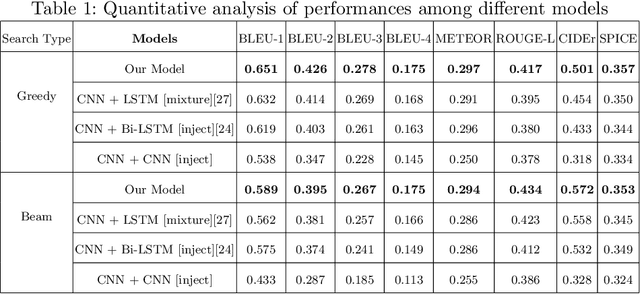
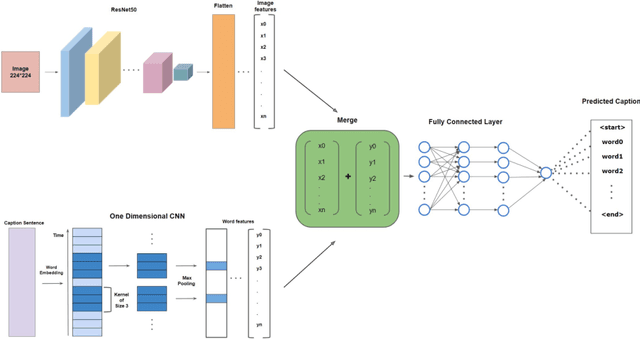

Image Captioning is an arduous task of producing syntactically and semantically correct textual descriptions of an image in natural language with context related to the image. Existing notable pieces of research in Bengali Image Captioning (BIC) are based on encoder-decoder architecture. This paper presents an end-to-end image captioning system utilizing a multimodal architecture by combining a one-dimensional convolutional neural network (CNN) to encode sequence information with a pre-trained ResNet-50 model image encoder for extracting region-based visual features. We investigate our approach's performance on the BanglaLekhaImageCaptions dataset using the existing evaluation metrics and perform a human evaluation for qualitative analysis. Experiments show that our approach's language encoder captures the fine-grained information in the caption, and combined with the image features, it generates accurate and diversified caption. Our work outperforms all the existing BIC works and achieves a new state-of-the-art (SOTA) performance by scoring 0.651 on BLUE-1, 0.572 on CIDEr, 0.297 on METEOR, 0.434 on ROUGE, and 0.357 on SPICE.
A transformer based approach for fighting COVID-19 fake news
Jan 28, 2021
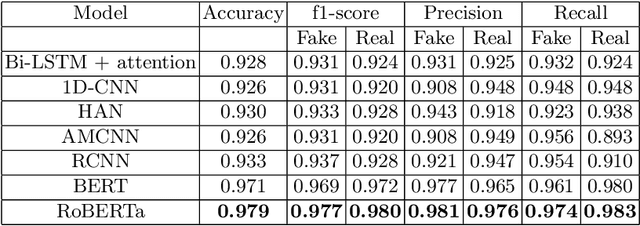
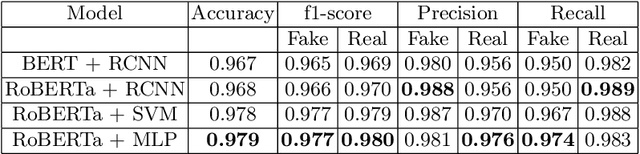
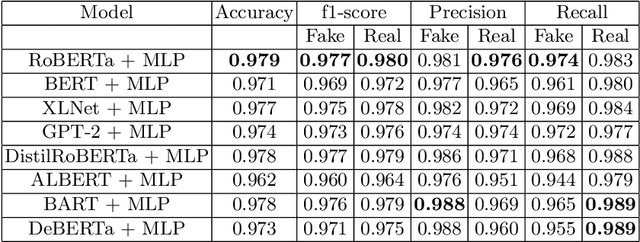
The rapid outbreak of COVID-19 has caused humanity to come to a stand-still and brought with it a plethora of other problems. COVID-19 is the first pandemic in history when humanity is the most technologically advanced and relies heavily on social media platforms for connectivity and other benefits. Unfortunately, fake news and misinformation regarding this virus is also available to people and causing some massive problems. So, fighting this infodemic has become a significant challenge. We present our solution for the "Constraint@AAAI2021 - COVID19 Fake News Detection in English" challenge in this work. After extensive experimentation with numerous architectures and techniques, we use eight different transformer-based pre-trained models with additional layers to construct a stacking ensemble classifier and fine-tuned them for our purpose. We achieved 0.979906542 accuracy, 0.979913119 precision, 0.979906542 recall, and 0.979907901 f1-score on the test dataset of the competition.