 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cannot See the Forest for the Trees: Aggregating Multiple Viewpoints to Better Classify Objects in Videos
Jun 05, 2022
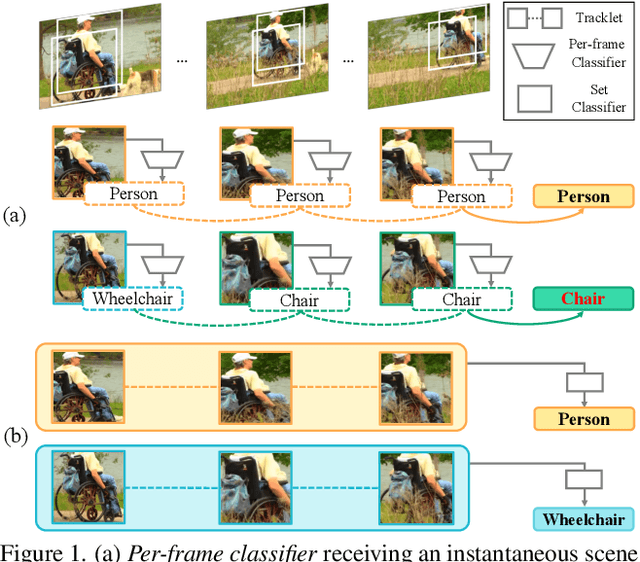

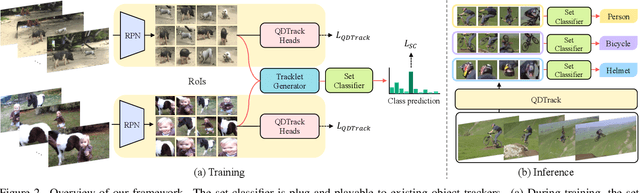
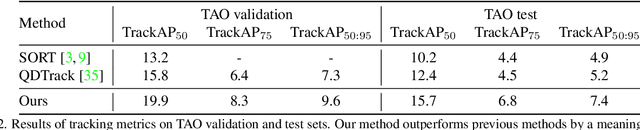
Recently, both long-tailed recognition and object tracking have made great advances individually. TAO benchmark presented a mixture of the two, long-tailed object tracking, in order to further reflect the aspect of the real-world. To date, existing solutions have adopted detectors showing robustness in long-tailed distributions, which derive per-frame results. Then, they used tracking algorithms that combine the temporally independent detections to finalize tracklets. However, as the approaches did not take temporal changes in scenes into account, inconsistent classification results in videos led to low overall performance. In this paper, we present a set classifier that improves accuracy of classifying tracklets by aggregating information from multiple viewpoints contained in a tracklet. To cope with sparse annotations in videos, we further propose augmentation of tracklets that can maximize data efficiency. The set classifier is plug-and-playable to existing object trackers, and highly improves the performance of long-tailed object tracking. By simply attaching our method to QDTrack on top of ResNet-101, we achieve the new state-of-the-art, 19.9% and 15.7% TrackAP_50 on TAO validation and test sets, respectively.
Learning Binarized Graph Representations with Multi-faceted Quantization Reinforcement for Top-K Recommendation
Jun 05, 2022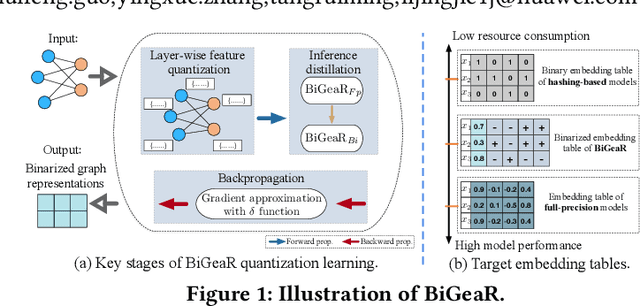
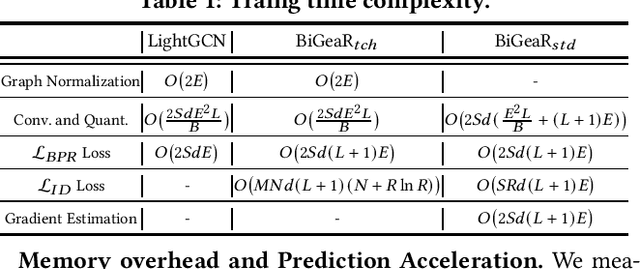
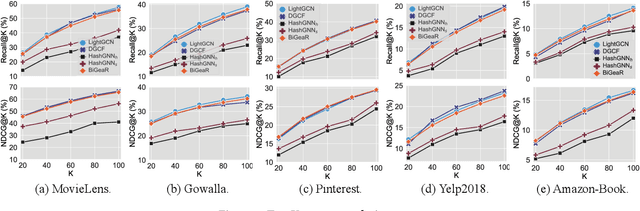
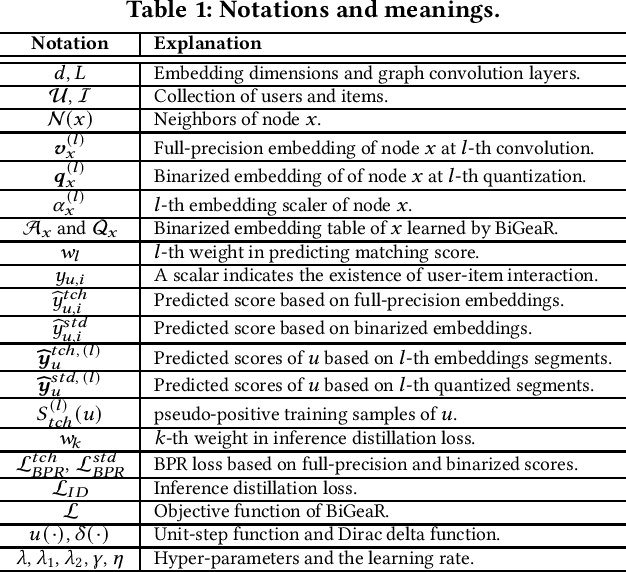
Learning vectorized embeddings is at the core of various recommender systems for user-item matching. To perform efficient online inference, representation quantization, aiming to embed the latent features by a compact sequence of discrete numbers, recently shows the promising potentiality in optimizing both memory and computation overheads. However, existing work merely focuses on numerical quantization whilst ignoring the concomitant information loss issue, which, consequently, leads to conspicuous performance degradation. In this paper, we propose a novel quantization framework to learn Binarized Graph Representations for Top-K Recommendation (BiGeaR). BiGeaR introduces multi-faceted quantization reinforcement at the pre-, mid-, and post-stage of binarized representation learning, which substantially retains the representation informativeness against embedding binarization. In addition to saving the memory footprint, BiGeaR further develops solid online inference acceleration with bitwise operations, providing alternative flexibility for the realistic deployment. The empirical results over five large real-world benchmarks show that BiGeaR achieves about 22%~40% performance improvement over the state-of-the-art quantization-based recommender system, and recovers about 95%~102% of the performance capability of the best full-precision counterpart with over 8x time and space reduction.
Networked Sensing in 6G Cellular Networks: Opportunities and Challenges
Jun 01, 2022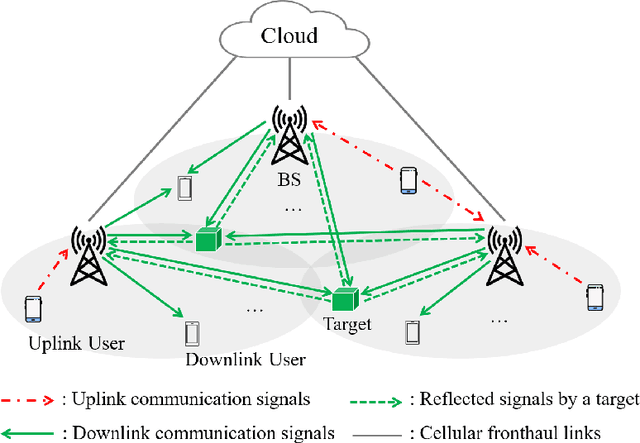
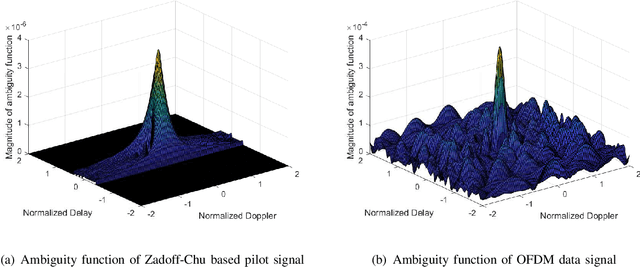
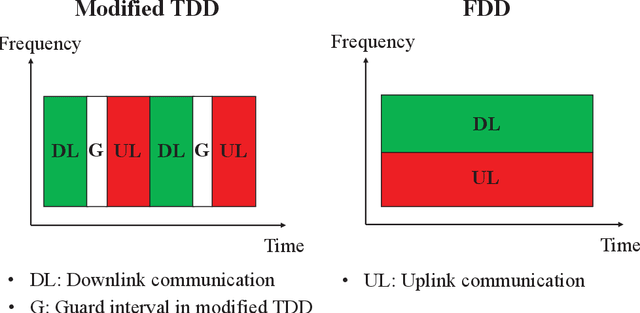
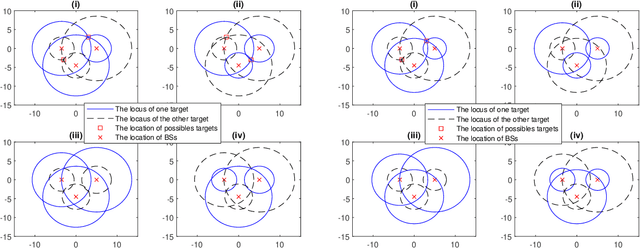
Radar and wireless communication are widely acknowledged as the two most successful applications of the radio technology over the past decades. Recently, there is a trend in both academia and industry to achieve integrated sensing and communication (ISAC) in one system via utilizing a common radio spectrum and the same hardware platform. This article will discuss about the possibility of exploiting the future sixth-generation (6G) cellular network to realize ISAC. Our vision is that the cellular base stations (BSs) deployed all over the world can be transformed into a powerful sensor to provide highresolution localization services. Specifically, motivated by the joint encoding/decoding gain in multi-cell coordinated communication, we advocate the adoption of the networked sensing technique in 6G network to achieve the above goal, where the BSs can share the sensing information with each other for jointly estimating the locations and velocities of the targets. Several opportunities and challenges to realize networked sensing in the 6G era will be revealed in this article. Moreover, the future research directions for this promising trend will be outlined as well.
Learning Meta Representations of One-shot Relations for Temporal Knowledge Graph Link Prediction
May 21, 2022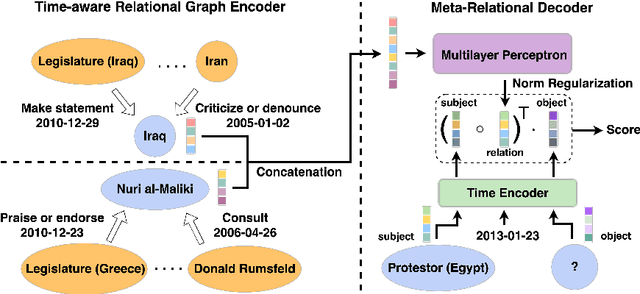
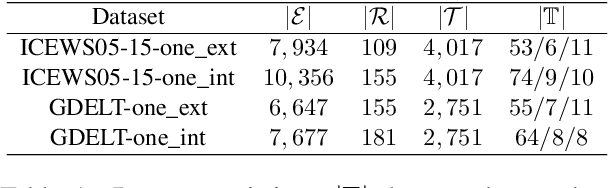
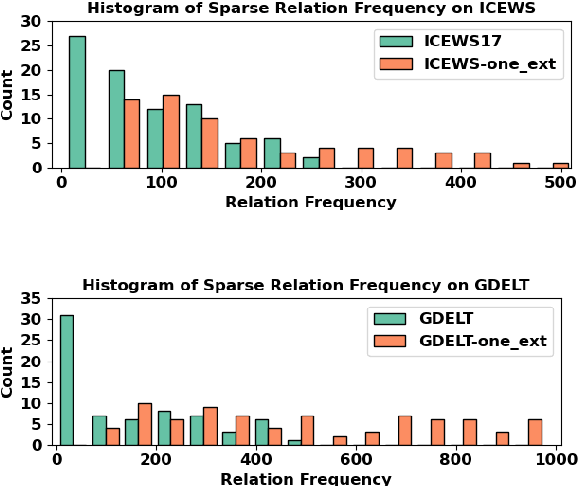
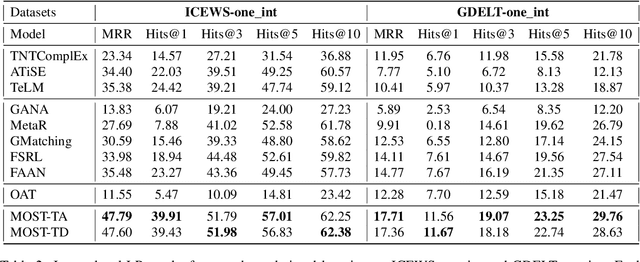
Few-shot relational learning for static knowledge graphs (KGs) has drawn greater interest in recent years, while few-shot learning for temporal knowledge graphs (TKGs) has hardly been studied. Compared to KGs, TKGs contain rich temporal information, thus requiring temporal reasoning techniques for modeling. This poses a greater challenge in learning few-shot relations in the temporal context. In this paper, we revisit the previous work related to few-shot relational learning in KGs and extend two existing TKG reasoning tasks, i.e., interpolated and extrapolated link prediction, to the one-shot setting. We propose four new large-scale benchmark datasets and develop a TKG reasoning model for learning one-shot relations in TKGs. Experimental results show that our model can achieve superior performance on all datasets in both interpolation and extrapolation tasks.
Fake News Detection Using Majority Voting Technique
Mar 27, 2022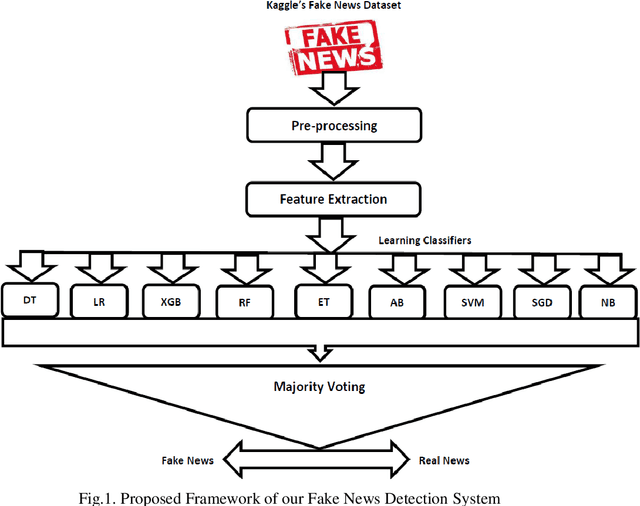
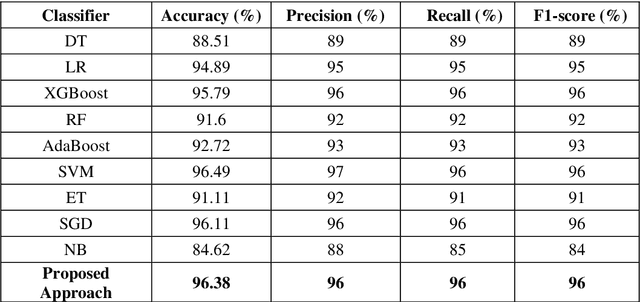
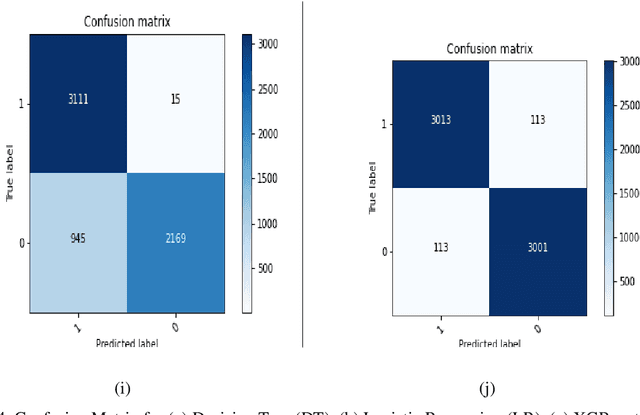
Due to the evolution of the Web and social network platforms it becomes very easy to disseminate the information. Peoples are creating and sharing more information than ever before, which may be misleading, misinformation or fake information. Fake news detection is a crucial and challenging task due to the unstructured nature of the available information. In the recent years, researchers have provided significant solutions to tackle with the problem of fake news detection, but due to its nature there are still many open issues. In this paper, we have proposed majority voting approach to detect fake news articles. We have used different textual properties of fake and real news. We have used publicly available fake news dataset, comprising of 20,800 news articles among which 10,387 are real and 10,413 are fake news labeled as binary 0 and 1. For the evaluation of our approach, we have used commonly used machine learning classifiers like, Decision Tree, Logistic Regression, XGBoost, Random Forest, Extra Trees, AdaBoost, SVM, SGD and Naive Bayes. Using the aforementioned classifiers, we built a multi-model fake news detection system using Majority Voting technique to achieve the more accurate results. The experimental results show that, our proposed approach achieved accuracy of 96.38%, precision of 96%, recall of 96% and F1-measure of 96%. The evaluation confirms that, Majority Voting technique achieved more acceptable results as compare to individual learning technique.
Lightweight Human Pose Estimation Using Heatmap-Weighting Loss
May 21, 2022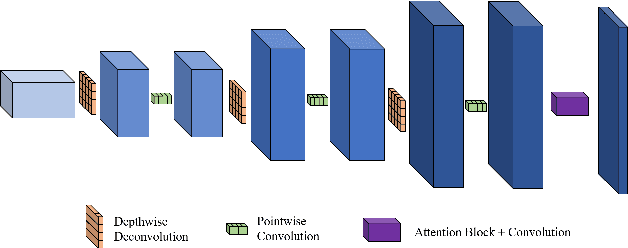
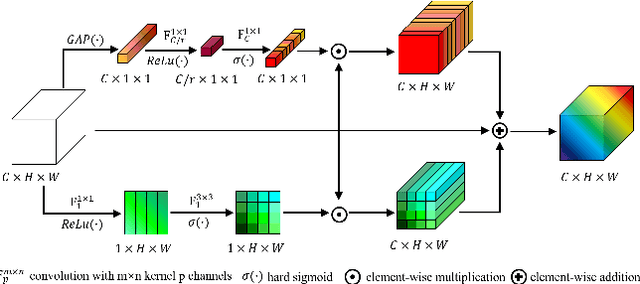
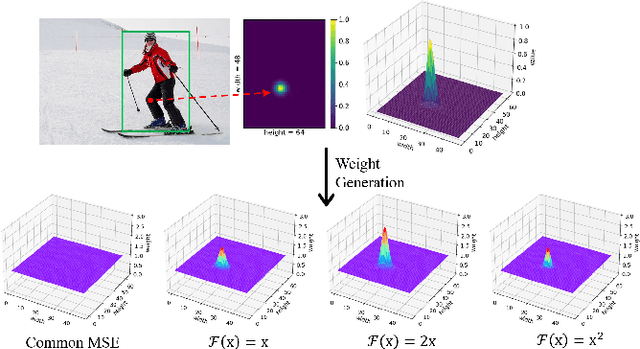
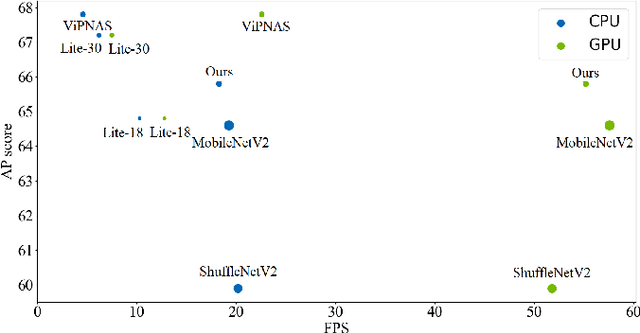
Recent research on human pose estimation exploits complex structures to improve performance on benchmark datasets, ignoring the resource overhead and inference speed when the model is actually deployed. In this paper, we lighten the computation cost and parameters of the deconvolution head network in SimpleBaseline and introduce an attention mechanism that utilizes original, inter-level, and intra-level information to intensify the accuracy. Additionally, we propose a novel loss function called heatmap weighting loss, which generates weights for each pixel on the heatmap that makes the model more focused on keypoints. Experiments demonstrate our method achieves a balance between performance, resource volume, and inference speed. Specifically, our method can achieve 65.3 AP score on COCO test-dev, while the inference speed is 55 FPS and 18 FPS on the mobile GPU and CPU, respectively.
Position Tracking using Likelihood Modeling of Channel Features with Gaussian Processes
Mar 24, 2022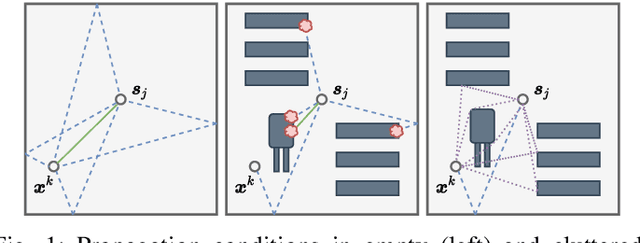
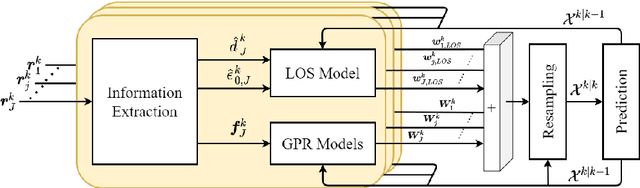
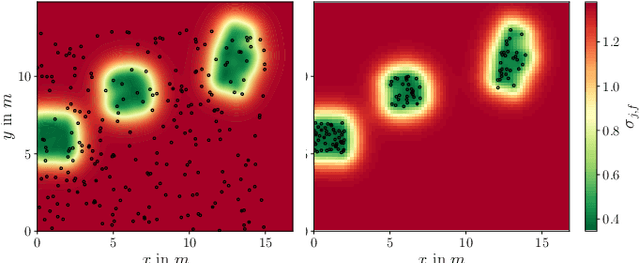

Recent localization frameworks exploit spatial information of complex channel measurements (CMs) to estimate accurate positions even in multipath propagation scenarios. State-of-the art CM fingerprinting(FP)-based methods employ convolutional neural networks (CNN) to extract the spatial information. However, they need spatially dense data sets (associated with high acquisition and maintenance efforts) to work well -- which is rarely the case in practical applications. If such data is not available (or its quality is low), we cannot compensate the performance degradation of CNN-based FP as they do not provide statistical position estimates, which prevents a fusion with other sources of information on the observation level. We propose a novel localization framework that adapts well to sparse datasets that only contain CMs of specific areas within the environment with strong multipath propagation. Our framework compresses CMs into informative features to unravel spatial information. It then regresses Gaussian processes (GPs) for each of them, which imply statistical observation models based on distance-dependent covariance kernels. Our framework combines the trained GPs with line-of-sight ranges and a dynamics model in a particle filter. Our measurements show that our approach outperforms state-of-the-art CNN fingerprinting (0.52 m vs. 1.3 m MAE) on spatially sparse data collected in a realistic industrial indoor environment.
SHAPE: An Unified Approach to Evaluate the Contribution and Cooperation of Individual Modalities
Apr 30, 2022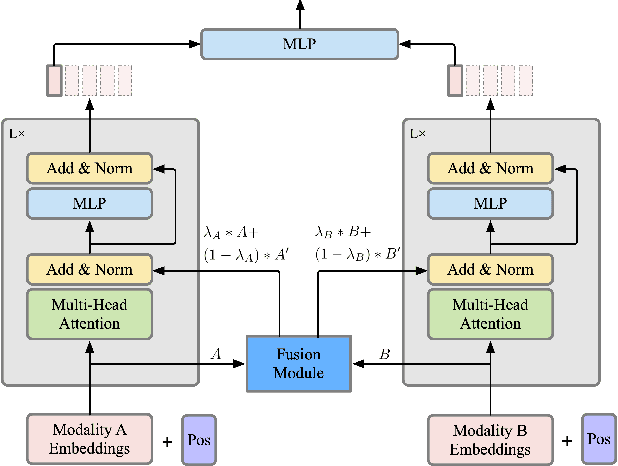

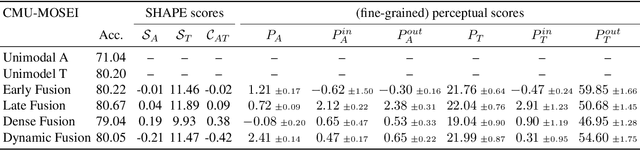
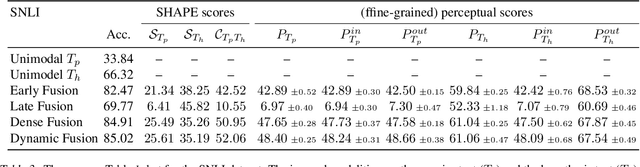
As deep learning advances, there is an ever-growing demand for models capable of synthesizing information from multi-modal resources to address the complex tasks raised from real-life applications. Recently, many large multi-modal datasets have been collected, on which researchers actively explore different methods of fusing multi-modal information. However, little attention has been paid to quantifying the contribution of different modalities within the proposed models. In this paper, we propose the {\bf SH}apley v{\bf A}lue-based {\bf PE}rceptual (SHAPE) scores that measure the marginal contribution of individual modalities and the degree of cooperation across modalities. Using these scores, we systematically evaluate different fusion methods on different multi-modal datasets for different tasks. Our experiments suggest that for some tasks where different modalities are complementary, the multi-modal models still tend to use the dominant modality alone and ignore the cooperation across modalities. On the other hand, models learn to exploit cross-modal cooperation when different modalities are indispensable for the task. In this case, the scores indicate it is better to fuse different modalities at relatively early stages. We hope our scores can help improve the understanding of how the present multi-modal models operate on different modalities and encourage more sophisticated methods of integrating multiple modalities.
Extracting Image Characteristics to Predict Crowdfunding Success
Mar 28, 2022
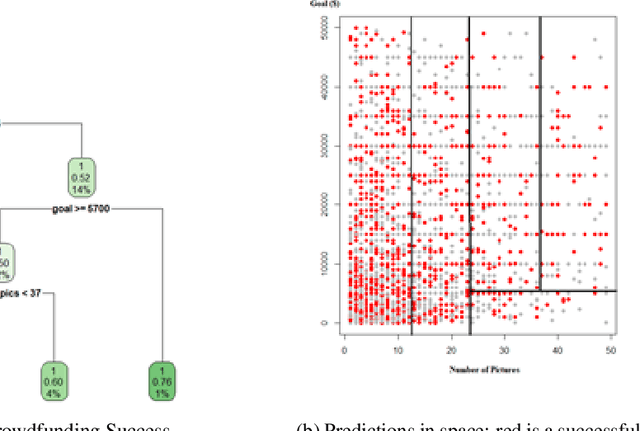
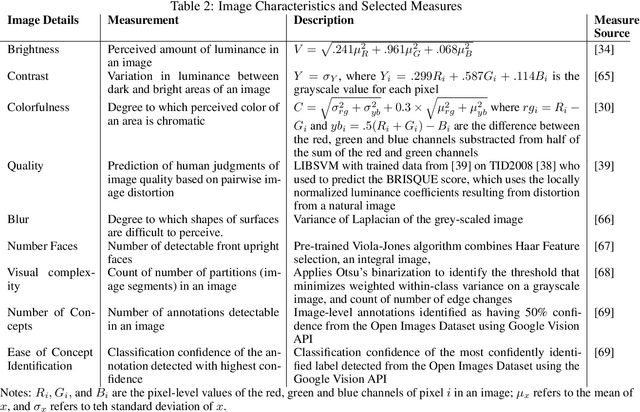
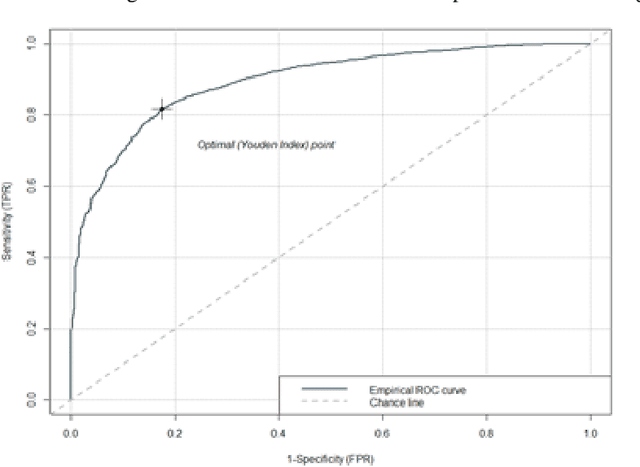
Despite an increase in the empirical study of crowdfunding platforms and the prevalence of visual information, operations management and marketing literature has yet to explore the role that image characteristics play in crowdfunding success. The authors of this manuscript begin by synthesizing literature on visual processing to identify several image characteristics that are likely to shape crowdfunding success. After detailing measures for each image characteristic, they use them as part of a machine-learning algorithm (Bayesian additive trees), along with project characteristics and textual information, to predict crowdfunding success. Results show that the inclusion of these image characteristics substantially improves prediction over baseline project variables, as well as textual features. Furthermore, image characteristic variables exhibit high importance, similar to variables linked to the number of pictures and number of videos. This research therefore offers valuable resources to researchers and managers who are interested in the role of visual information in ensuring new product success.
Neural Improvement Heuristics for Preference Ranking
Jun 01, 2022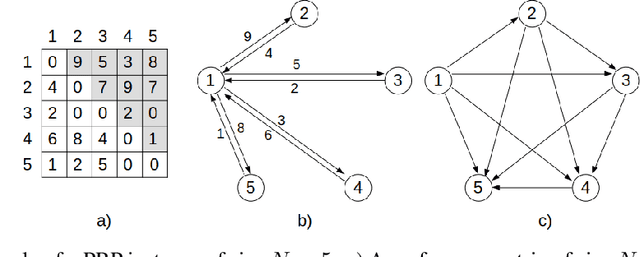
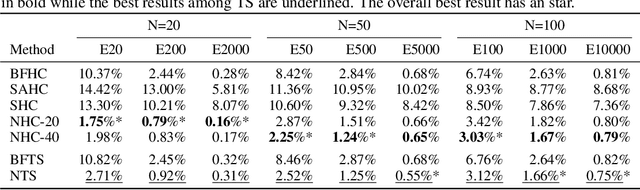
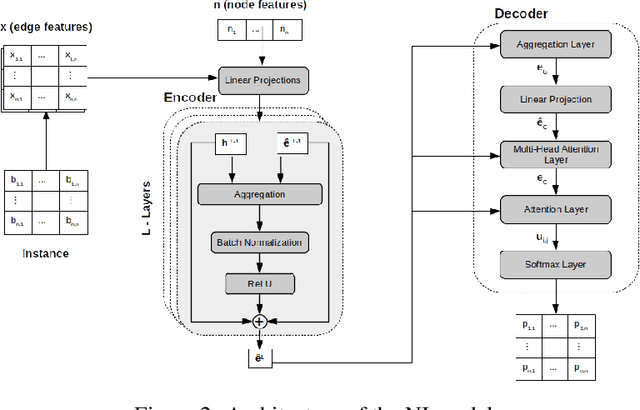
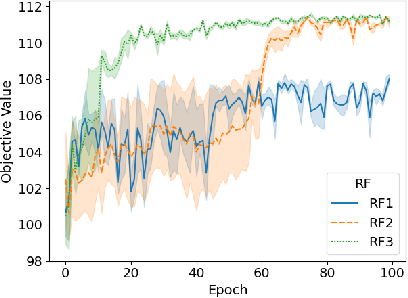
In recent years, Deep Learning based methods have been a revolution in the field of combinatorial optimization. They learn to approximate solutions and constitute an interesting choice when dealing with repetitive problems drawn from similar distributions. Most effort has been devoted to investigating neural constructive methods, while the works that propose neural models to iteratively improve a candidate solution are less frequent. In this paper, we present a Neural Improvement (NI) model for graph-based combinatorial problems that, given an instance and a candidate solution, encodes the problem information by means of edge features. Our model proposes a modification on the pairwise precedence of items to increase the quality of the solution. We demonstrate the practicality of the model by applying it as the building block of a Neural Hill Climber and other trajectory-based methods. The algorithms are used to solve the Preference Ranking Problem and results show that they outperform conventional alternatives in simulated and real-world data. Conducted experiments also reveal that the proposed model can be a milestone in the development of efficiently guided trajectory-based optimization algorithms.