 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI for Energy-Efficient and Interference-Aware Compressed Sensing of GNSS Signals on a Google Edge TPU
May 14, 2026Traditional methods for classifying global navigation satellite system (GNSS) jamming signals typically involve post-processing raw or spectral data streams, requiring complex and costly data transmission to cloud-based interference classification systems. In contrast, our proposed approach efficiently compresses GNSS data streams directly at the hardware receiver while simultaneously classifying jamming and spoofing attacks in real time. Given the growing prevalence of GNSS jamming, there is a critical need for real-time solutions suitable for power-constrained environments. This paper introduces a novel method for compressing and classifying GNSS jamming threats using generative artificial intelligence (GenAI), specifically variational autoencoders (VAEs), deployed on Google Edge tensor processing units (TPUs). The study evaluates various autoencoder (AE) architectures to compress and reconstruct GNSS signals, focusing on preserving interference characteristics while minimizing data size near the receiver hardware. The pipeline adapts large-scale AE models for Google Edge TPUs through 8-bit quantization to ensure energy-efficient deployment. Tests on raw in-phase and quadrature-phase (IQ) data, Fast Fourier Transform (FFT) data, and handcrafted features show the system achieves significant compression (>42x) and accurate classification of approximately 72 interference types on reconstructed signals (F2-score 0.915), closely matching the original signals (F2-score 0.923). The hardware-centric GenAI approach also substantially reduces jammer signal transmission costs, offering a practical solution for interference mitigation. Ablation studies on conditional and factorized VAEs (i.e., FactorVAE) explore latent feature disentanglement for data generation, enhancing model interpretability and fostering trust in machine learning (ML) solutions for sensitive interference applications.
* 12 pages
Exploitation of Hidden Context in Dynamic Movement Forecasting: A Neural Network Journey from Recurrent to Graph Neural Networks and General Purpose Transformers
May 14, 2026Forecasting within signal processing pipelines is crucial for mitigating delays, particularly in predicting the dynamic movements of objects such as NBA players. This task poses significant challenges due to the inherently interactive and unpredictable nature of sports, where abrupt changes in velocity and direction are prevalent. Traditional approaches, including (S)ARIMA(X), Kalman filters (KF), and Particle filters (PF), often struggle to model the non-linear dynamics present in such scenarios. Machine learning (ML) methods, such as long short-term memory (LSTM) networks, graph neural networks (GNNs), and Transformers, offer greater flexibility and accuracy but frequently fail to explicitly capture the interplay between temporal dependencies and contextual interactions, which are critical in chaotic sports environments. In this paper, we evaluate these models and assess their strengths and weaknesses. Experimental results reveal key performance trade-offs across input history length, generalizability, and the ability to incorporate contextual information. ML-based methods demonstrated substantial improvements over linear models across forecast horizons of up to 2s. Among the tested architectures, our hybrid LSTM augmented with contextual information achieved the lowest final displacement error (FDE) of 1.51m, outperforming temporal convolutional neural network (TCNN), graph attention network (GAT), and Transformers, while also requiring less data and training time compared to GAT and Transformers. Our findings indicate that no single architecture excels across all metrics, emphasizing the need for task-specific considerations in trajectory prediction for fast-paced, dynamic environments such as NBA gameplay.
* 12 pages
Active Sensing with Meta-Reinforcement Learning for Emitter Localization from RF Observations
May 12, 2026Global navigation satellite system (GNSS) interference poses a serious threat to reliable positioning, especially in indoor and multipath-rich environments where source localization is highly challenging. In this paper, we formulate GNSS interference localization as an active sensing problem and propose a reinforcement learning (RL) framework in which an agent sequentially explores the environment to infer the position of an emitter source from radio frequency (RF) observations acquired with a 2x2 patch antenna. The localization task is modeled as a partially observable decision process, since single-snapshot measurements are often ambiguous under multipath propagation and changing channel conditions. To address this, the proposed framework combines high-dimensional RF sensing with deep RL and recurrent policy learning. We investigate both value-based and policy-based approaches, namely Deep Q-Networks (DQN) and Proximal Policy Optimization (PPO), and study their behavior under domain shift. The approach is evaluated on a simulated dataset generated with the Sionna ray-tracing module, which provides realistic propagation effects and diverse environment configurations. Experimental results show that the proposed method achieves a localization success rate of 80.1%, demonstrating the potential of RL for adaptive GNSS interference localization. Overall, the results highlight simulation-assisted training as a promising direction for robust interference localization in challenging propagation environments.
Resilient Channel Charting Under Varying Radio Link Availability
Feb 04, 2026Channel charting (CC) has become a key technology for RF-based localization, enabling unsupervised radio fingerprinting, even in non line of sight scenarios, with a minimum of reference position labels. However, most CC models assume fixed-size inputs, such as a constant number of antennas or channel measurements. In practical systems, antennas may fail, signals may be blocked, or antenna sets may change during handovers, making fixed-input architectures fragile. Existing radio-fingerprinting approaches address this by training separate models for each antenna configuration, but the resulting training effort scales prohibitively with the array size. We propose Adaptive Positioning (AdaPos), a CC architecture that natively handles variable numbers of channel measurements. AdaPos combines convolutional feature extraction with a transformer-based encoder using learnable antenna identifiers and self-attention to fuse arbitrary subsets of CSI inputs. Experiments on two public real-world datasets (SISO and MIMO) show that AdaPos maintains state-of-the-art accuracy under missing-antenna conditions and replaces roughly 57 configuration-specific models with a single unified model. With AdaPos and our novel training strategies, we provide resilience to both individual antenna failures and full-array outages.
Simplicity is Key: An Unsupervised Pretraining Approach for Sparse Radio Channels
May 19, 2025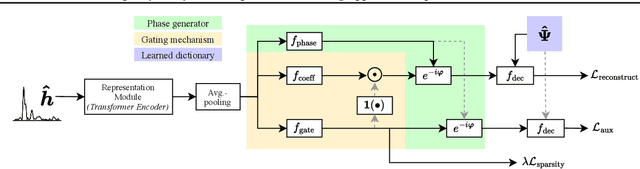

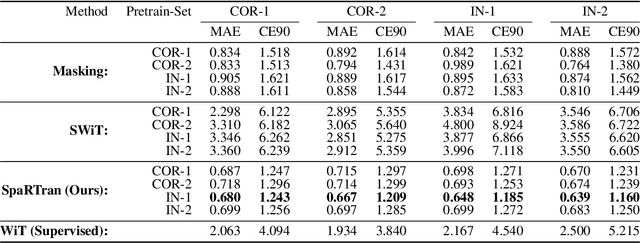
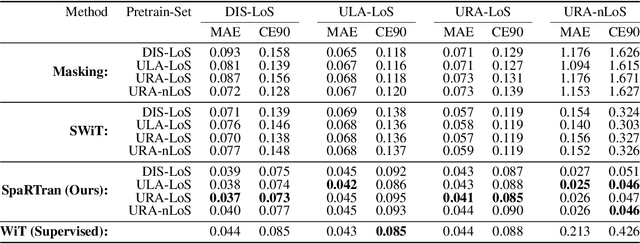
We introduce the Sparse pretrained Radio Transformer (SpaRTran), an unsupervised representation learning approach based on the concept of compressed sensing for radio channels. Our approach learns embeddings that focus on the physical properties of radio propagation, to create the optimal basis for fine-tuning on radio-based downstream tasks. SpaRTran uses a sparse gated autoencoder that induces a simplicity bias to the learned representations, resembling the sparse nature of radio propagation. For signal reconstruction, it learns a dictionary that holds atomic features, which increases flexibility across signal waveforms and spatiotemporal signal patterns. Our experiments show that SpaRTran reduces errors by up to 85 % compared to state-of-the-art methods when fine-tuned on radio fingerprinting, a challenging downstream task. In addition, our method requires less pretraining effort and offers greater flexibility, as we train it solely on individual radio signals. SpaRTran serves as an excellent base model that can be fine-tuned for various radio-based downstream tasks, effectively reducing the cost for labeling. In addition, it is significantly more versatile than existing methods and demonstrates superior generalization.
VAE-based Feature Disentanglement for Data Augmentation and Compression in Generalized GNSS Interference Classification
Apr 14, 2025Distributed learning and Edge AI necessitate efficient data processing, low-latency communication, decentralized model training, and stringent data privacy to facilitate real-time intelligence on edge devices while reducing dependency on centralized infrastructure and ensuring high model performance. In the context of global navigation satellite system (GNSS) applications, the primary objective is to accurately monitor and classify interferences that degrade system performance in distributed environments, thereby enhancing situational awareness. To achieve this, machine learning (ML) models can be deployed on low-resource devices, ensuring minimal communication latency and preserving data privacy. The key challenge is to compress ML models while maintaining high classification accuracy. In this paper, we propose variational autoencoders (VAEs) for disentanglement to extract essential latent features that enable accurate classification of interferences. We demonstrate that the disentanglement approach can be leveraged for both data compression and data augmentation by interpolating the lower-dimensional latent representations of signal power. To validate our approach, we evaluate three VAE variants - vanilla, factorized, and conditional generative - on four distinct datasets, including two collected in controlled indoor environments and two real-world highway datasets. Additionally, we conduct extensive hyperparameter searches to optimize performance. Our proposed VAE achieves a data compression rate ranging from 512 to 8,192 and achieves an accuracy up to 99.92%.
Evaluation of (Un-)Supervised Machine Learning Methods for GNSS Interference Classification with Real-World Data Discrepancies
Mar 31, 2025



The accuracy and reliability of vehicle localization on roads are crucial for applications such as self-driving cars, toll systems, and digital tachographs. To achieve accurate positioning, vehicles typically use global navigation satellite system (GNSS) receivers to validate their absolute positions. However, GNSS-based positioning can be compromised by interference signals, necessitating the identification, classification, determination of purpose, and localization of such interference to mitigate or eliminate it. Recent approaches based on machine learning (ML) have shown superior performance in monitoring interference. However, their feasibility in real-world applications and environments has yet to be assessed. Effective implementation of ML techniques requires training datasets that incorporate realistic interference signals, including real-world noise and potential multipath effects that may occur between transmitter, receiver, and satellite in the operational area. Additionally, these datasets require reference labels. Creating such datasets is often challenging due to legal restrictions, as causing interference to GNSS sources is strictly prohibited. Consequently, the performance of ML-based methods in practical applications remains unclear. To address this gap, we describe a series of large-scale measurement campaigns conducted in real-world settings at two highway locations in Germany and the Seetal Alps in Austria, and in large-scale controlled indoor environments. We evaluate the latest supervised ML-based methods to report on their performance in real-world settings and present the applicability of pseudo-labeling for unsupervised learning. We demonstrate the challenges of combining datasets due to data discrepancies and evaluate outlier detection, domain adaptation, and data augmentation techniques to present the models' capabilities to adapt to changes in the datasets.
* 34 pages, 25 figures
Multimodal-to-Text Prompt Engineering in Large Language Models Using Feature Embeddings for GNSS Interference Characterization
Jan 09, 2025



Large language models (LLMs) are advanced AI systems applied across various domains, including NLP, information retrieval, and recommendation systems. Despite their adaptability and efficiency, LLMs have not been extensively explored for signal processing tasks, particularly in the domain of global navigation satellite system (GNSS) interference monitoring. GNSS interference monitoring is essential to ensure the reliability of vehicle localization on roads, a critical requirement for numerous applications. However, GNSS-based positioning is vulnerable to interference from jamming devices, which can compromise its accuracy. The primary objective is to identify, classify, and mitigate these interferences. Interpreting GNSS snapshots and the associated interferences presents significant challenges due to the inherent complexity, including multipath effects, diverse interference types, varying sensor characteristics, and satellite constellations. In this paper, we extract features from a large GNSS dataset and employ LLaVA to retrieve relevant information from an extensive knowledge base. We employ prompt engineering to interpret the interferences and environmental factors, and utilize t-SNE to analyze the feature embeddings. Our findings demonstrate that the proposed method is capable of visual and logical reasoning within the GNSS context. Furthermore, our pipeline outperforms state-of-the-art machine learning models in interference classification tasks.
Federated Learning with MMD-based Early Stopping for Adaptive GNSS Interference Classification
Oct 21, 2024



Federated learning (FL) enables multiple devices to collaboratively train a global model while maintaining data on local servers. Each device trains the model on its local server and shares only the model updates (i.e., gradient weights) during the aggregation step. A significant challenge in FL is managing the feature distribution of novel, unbalanced data across devices. In this paper, we propose an FL approach using few-shot learning and aggregation of the model weights on a global server. We introduce a dynamic early stopping method to balance out-of-distribution classes based on representation learning, specifically utilizing the maximum mean discrepancy of feature embeddings between local and global models. An exemplary application of FL is orchestrating machine learning models along highways for interference classification based on snapshots from global navigation satellite system (GNSS) receivers. Extensive experiments on four GNSS datasets from two real-world highways and controlled environments demonstrate that our FL method surpasses state-of-the-art techniques in adapting to both novel interference classes and multipath scenarios.
Radio Foundation Models: Pre-training Transformers for 5G-based Indoor Localization
Oct 01, 2024Artificial Intelligence (AI)-based radio fingerprinting (FP) outperforms classic localization methods in propagation environments with strong multipath effects. However, the model and data orchestration of FP are time-consuming and costly, as it requires many reference positions and extensive measurement campaigns for each environment. Instead, modern unsupervised and self-supervised learning schemes require less reference data for localization, but either their accuracy is low or they require additional sensor information, rendering them impractical. In this paper we propose a self-supervised learning framework that pre-trains a general transformer (TF) neural network on 5G channel measurements that we collect on-the-fly without expensive equipment. Our novel pretext task randomly masks and drops input information to learn to reconstruct it. So, it implicitly learns the spatiotemporal patterns and information of the propagation environment that enable FP-based localization. Most interestingly, when we optimize this pre-trained model for localization in a given environment, it achieves the accuracy of state-of-the-art methods but requires ten times less reference data and significantly reduces the time from training to operation.