 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dither Signal Design for PAPR Reduction in OFDM-IM over a Rayleigh Fading Channel
May 27, 2022
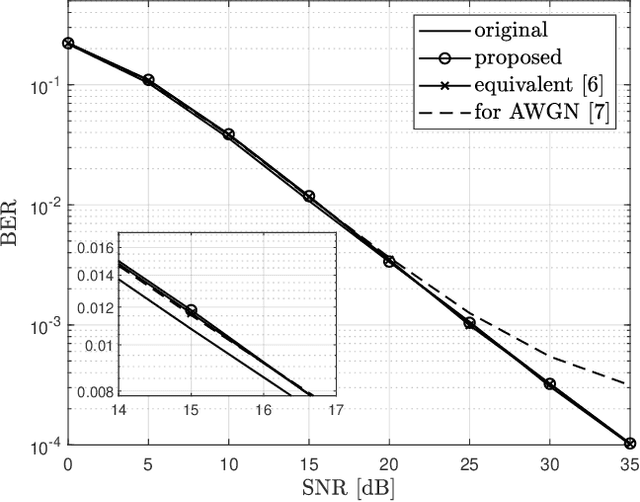
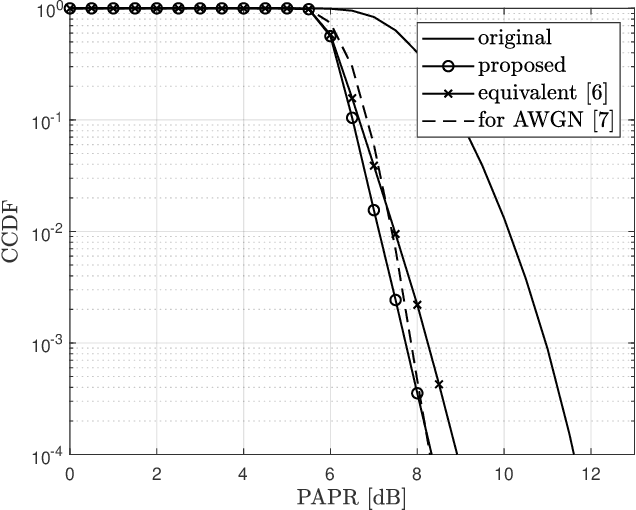
Orthogonal frequency division multiplexing with index modulation (OFDM-IM) is a novel scheme where the information bits are conveyed through the subcarrier activation pattern (SAP) and the symbols on the active subcarriers. Unfortunately, OFDM-IM inherits the high peak-to-average power ratio (PAPR) problem from the classical OFDM. The OFDMIM signal with high PAPR induces in-band distortion and out-of-band radiation when it passes through high power amplifier (HPA). There are attempts to reduce PAPR by adding dither signals in the idle subcarriers, where the dither signals can have various amplitude constraints according to the characteristic of the corresponding OFDM-IM subblock. But, there is no result for the specific amplitude constraint for the dither signals over a Rayleigh fading channel. In this letter, based on pairwise error probability (PEP) analysis, a specific constraint for the dither signals is derived over a Rayleigh fading channel.
On Neural Architecture Inductive Biases for Relational Tasks
Jun 09, 2022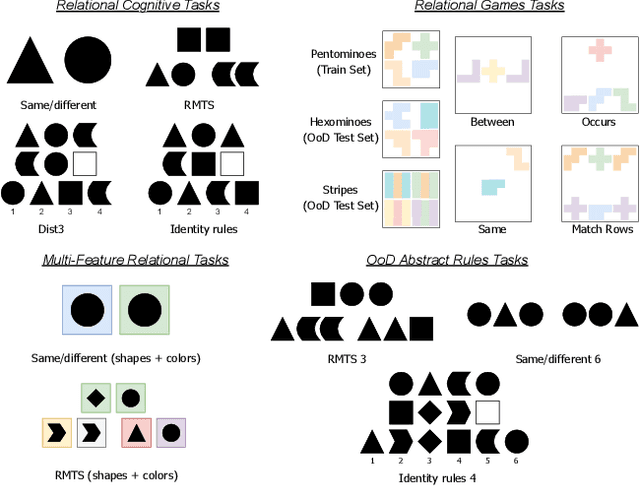
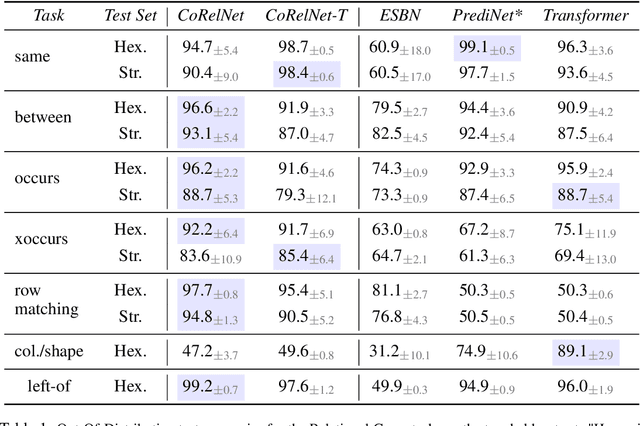
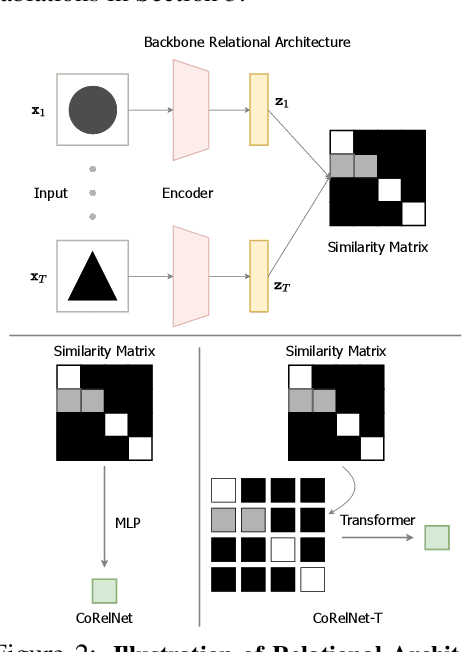
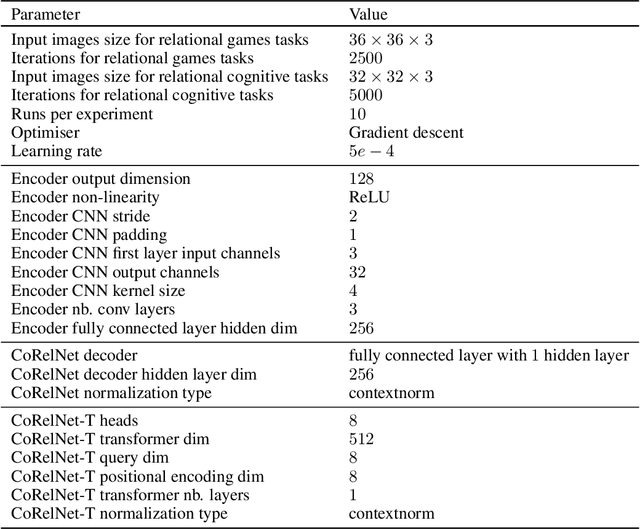
Current deep learning approaches have shown good in-distribution generalization performance, but struggle with out-of-distribution generalization. This is especially true in the case of tasks involving abstract relations like recognizing rules in sequences, as we find in many intelligence tests. Recent work has explored how forcing relational representations to remain distinct from sensory representations, as it seems to be the case in the brain, can help artificial systems. Building on this work, we further explore and formalize the advantages afforded by 'partitioned' representations of relations and sensory details, and how this inductive bias can help recompose learned relational structure in newly encountered settings. We introduce a simple architecture based on similarity scores which we name Compositional Relational Network (CoRelNet). Using this model, we investigate a series of inductive biases that ensure abstract relations are learned and represented distinctly from sensory data, and explore their effects on out-of-distribution generalization for a series of relational psychophysics tasks. We find that simple architectural choices can outperform existing models in out-of-distribution generalization. Together, these results show that partitioning relational representations from other information streams may be a simple way to augment existing network architectures' robustness when performing out-of-distribution relational computations.
Clustering with Queries under Semi-Random Noise
Jun 09, 2022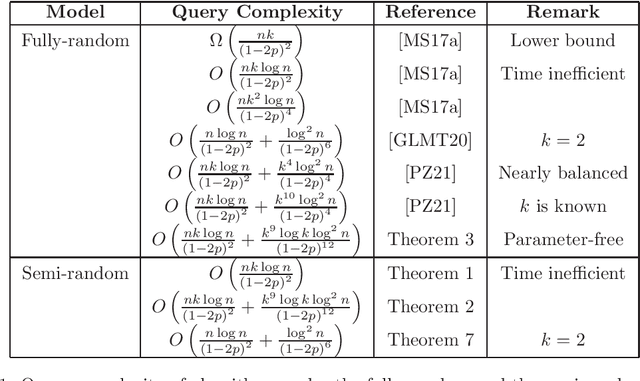
The seminal paper by Mazumdar and Saha \cite{MS17a} introduced an extensive line of work on clustering with noisy queries. Yet, despite significant progress on the problem, the proposed methods depend crucially on knowing the exact probabilities of errors of the underlying fully-random oracle. In this work, we develop robust learning methods that tolerate general semi-random noise obtaining qualitatively the same guarantees as the best possible methods in the fully-random model. More specifically, given a set of $n$ points with an unknown underlying partition, we are allowed to query pairs of points $u,v$ to check if they are in the same cluster, but with probability $p$, the answer may be adversarially chosen. We show that information theoretically $O\left(\frac{nk \log n} {(1-2p)^2}\right)$ queries suffice to learn any cluster of sufficiently large size. Our main result is a computationally efficient algorithm that can identify large clusters with $O\left(\frac{nk \log n} {(1-2p)^2}\right) + \text{poly}\left(\log n, k, \frac{1}{1-2p} \right)$ queries, matching the guarantees of the best known algorithms in the fully-random model. As a corollary of our approach, we develop the first parameter-free algorithm for the fully-random model, answering an open question by \cite{MS17a}.
MISO-wiLDCosts: Multi Information Source Optimization with Location Dependent Costs
Feb 09, 2021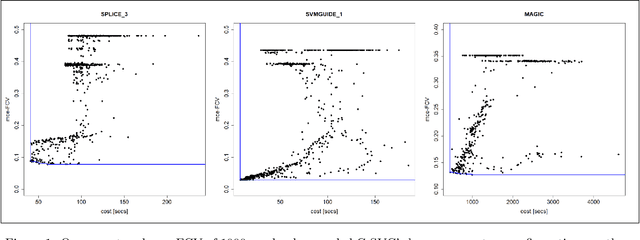
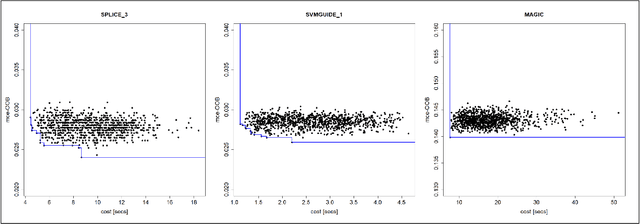
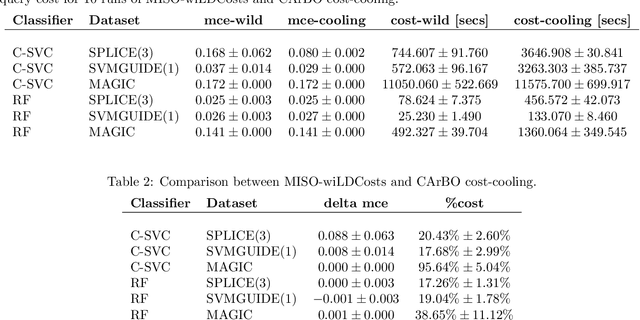
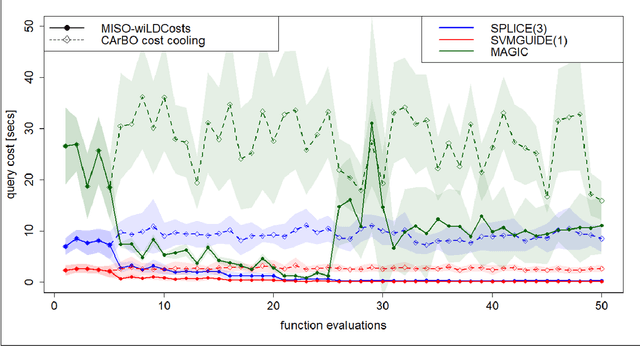
This paper addresses black-box optimization over multiple information sources whose both fidelity and query cost change over the search space, that is they are location dependent. The approach uses: (i) an Augmented Gaussian Process, recently proposed in multi-information source optimization as a single model of the objective function over search space and sources, and (ii) a Gaussian Process to model the location-dependent cost of each source. The former is used into a Confidence Bound based acquisition function to select the next source and location to query, while the latter is used to penalize the value of the acquisition depending on the expected query cost for any source-location pair. The proposed approach is evaluated on a set of Hyperparameters Optimization tasks, consisting of two Machine Learning classifiers and three datasets of different sizes.
Differentially Private AUC Computation in Vertical Federated Learning
May 24, 2022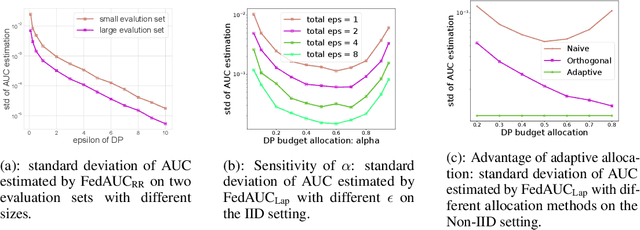
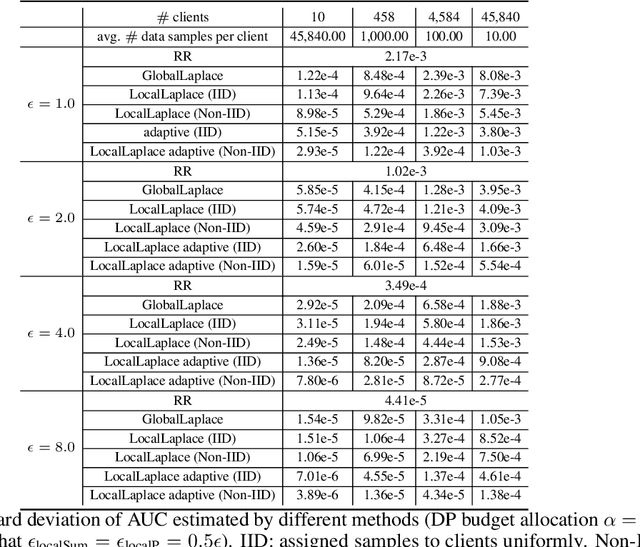
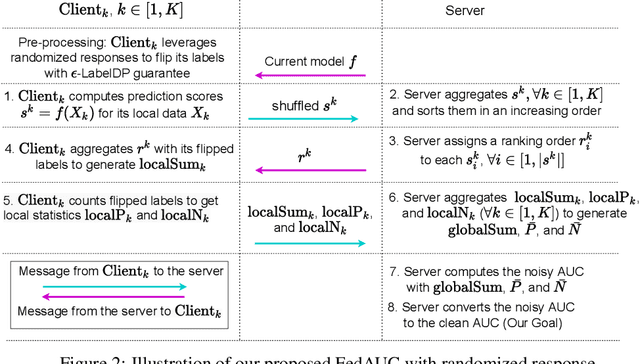
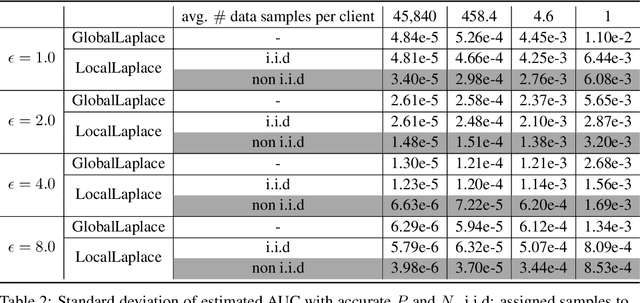
Federated learning has gained great attention recently as a privacy-enhancing tool to jointly train a machine learning model by multiple parties. As a sub-category, vertical federated learning (vFL) focuses on the scenario where features and labels are split into different parties. The prior work on vFL has mostly studied how to protect label privacy during model training. However, model evaluation in vFL might also lead to potential leakage of private label information. One mitigation strategy is to apply label differential privacy (DP) but it gives bad estimations of the true (non-private) metrics. In this work, we propose two evaluation algorithms that can more accurately compute the widely used AUC (area under curve) metric when using label DP in vFL. Through extensive experiments, we show our algorithms can achieve more accurate AUCs compared to the baselines.
On the Exploitation of Neuroevolutionary Information: Analyzing the Past for a More Efficient Future
May 26, 2021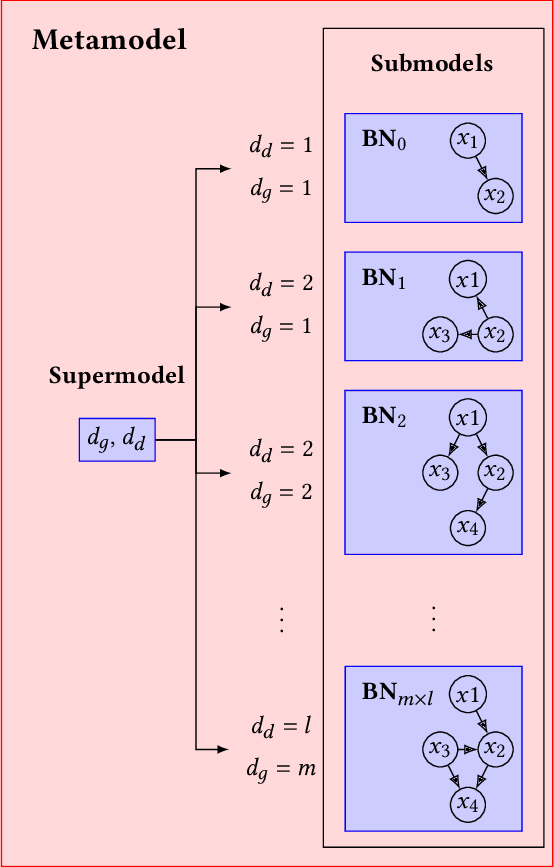
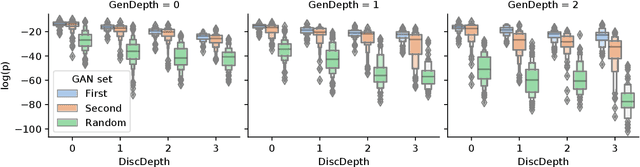
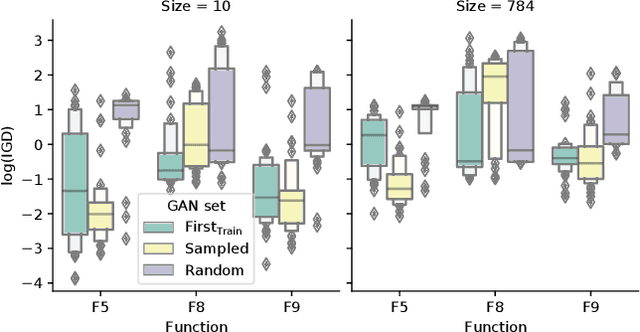
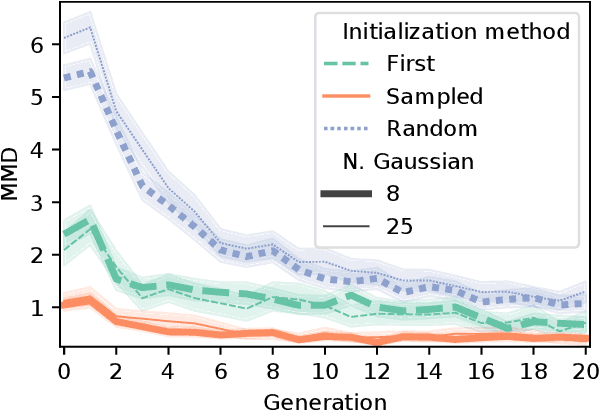
Neuroevolutionary algorithms, automatic searches of neural network structures by means of evolutionary techniques, are computationally costly procedures. In spite of this, due to the great performance provided by the architectures which are found, these methods are widely applied. The final outcome of neuroevolutionary processes is the best structure found during the search, and the rest of the procedure is commonly omitted in the literature. However, a good amount of residual information consisting of valuable knowledge that can be extracted is also produced during these searches. In this paper, we propose an approach that extracts this information from neuroevolutionary runs, and use it to build a metamodel that could positively impact future neural architecture searches. More specifically, by inspecting the best structures found during neuroevolutionary searches of generative adversarial networks with varying characteristics (e.g., based on dense or convolutional layers), we propose a Bayesian network-based model which can be used to either find strong neural structures right away, conveniently initialize different structural searches for different problems, or help future optimization of structures of any type to keep finding increasingly better structures where uninformed methods get stuck into local optima.
Science through Machine Learning: Quantification of Poststorm Thermospheric Cooling
Jun 12, 2022

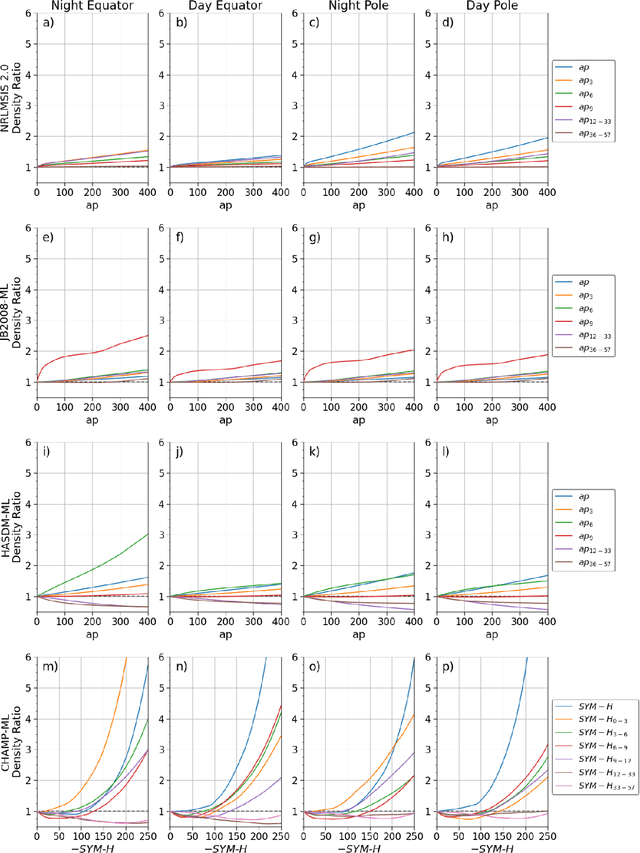
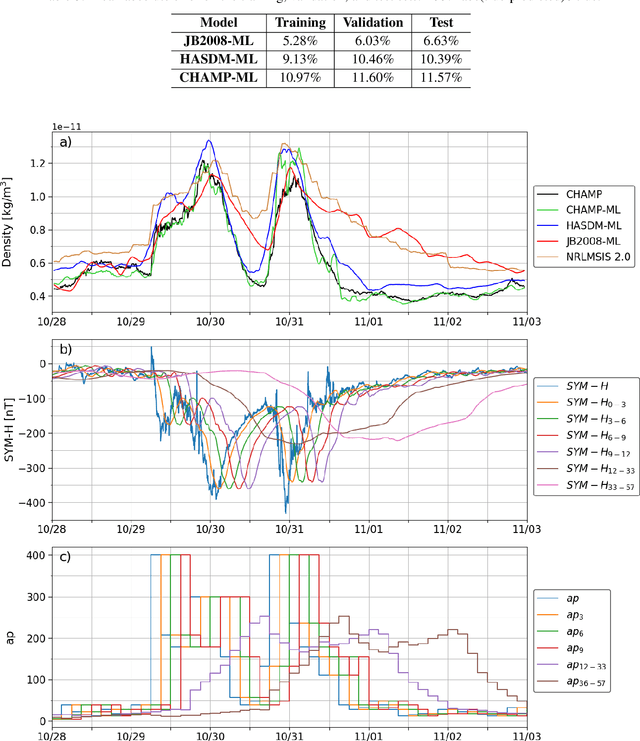
Machine learning (ML) is often viewed as a black-box regression technique that is unable to provide considerable scientific insight. ML models are universal function approximators and - if used correctly - can provide scientific information related to the ground-truth dataset used for fitting. A benefit to ML over parametric models is that there are no predefined basis functions limiting the phenomena that can be modeled. In this work, we develop ML models on three datasets: the Space Environment Technologies (SET) High Accuracy Satellite Drag Model (HASDM) density database, a spatiotemporally matched dataset of outputs from the Jacchia-Bowman 2008 Empirical Thermospheric Density Model (JB2008), and an accelerometer-derived density dataset from CHAllenging Minisatellite Payload (CHAMP). These ML models are compared to the Naval Research Laboratory Mass Spectrometer and Incoherent Scatter radar (NRLMSIS 2.0) model to study the presence of post-storm cooling in the middle-thermosphere. We find that both NRLMSIS 2.0 and JB2008-ML do not account for post-storm cooling and consequently perform poorly in periods following strong geomagnetic storms (e.g. the 2003 Halloween storms). Conversely, HASDM-ML and CHAMP-ML do show evidence of post-storm cooling indicating that this phenomenon is present in the original datasets. Results show that density reductions up to 40% can occur 1--3 days post-storm depending on location and the strength of the storm.
Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks
Feb 18, 2021

Most existing personalization systems promote items that match a user's previous choices or those that are popular among similar users. This results in recommendations that are highly similar to the ones users are already exposed to, resulting in their isolation inside familiar but insulated information silos. In this context, we develop a novel recommendation framework with a goal of improving information diversity using a modified random walk exploration of the user-item graph. We focus on the problem of political content recommendation, while addressing a general problem applicable to personalization tasks in other social and information networks. For recommending political content on social networks, we first propose a new model to estimate the ideological positions for both users and the content they share, which is able to recover ideological positions with high accuracy. Based on these estimated positions, we generate diversified personalized recommendations using our new random-walk based recommendation algorithm. With experimental evaluations on large datasets of Twitter discussions, we show that our method based on \emph{random walks with erasure} is able to generate more ideologically diverse recommendations. Our approach does not depend on the availability of labels regarding the bias of users or content producers. With experiments on open benchmark datasets from other social and information networks, we also demonstrate the effectiveness of our method in recommending diverse long-tail items.
* Web Conference 2021 (WWW '21)
Masked Frequency Modeling for Self-Supervised Visual Pre-Training
Jun 15, 2022



We present Masked Frequency Modeling (MFM), a unified frequency-domain-based approach for self-supervised pre-training of visual models. Instead of randomly inserting mask tokens to the input embeddings in the spatial domain, in this paper, we shift the perspective to the frequency domain. Specifically, MFM first masks out a portion of frequency components of the input image and then predicts the missing frequencies on the frequency spectrum. Our key insight is that predicting masked components in the frequency domain is more ideal to reveal underlying image patterns rather than predicting masked patches in the spatial domain, due to the heavy spatial redundancy. Our findings suggest that with the right configuration of mask-and-predict strategy, both the structural information within high-frequency components and the low-level statistics among low-frequency counterparts are useful in learning good representations. For the first time, MFM demonstrates that, for both ViT and CNN, a simple non-Siamese framework can learn meaningful representations even using none of the following: (i) extra data, (ii) extra model, (iii) mask token. Experimental results on ImageNet and several robustness benchmarks show the competitive performance and advanced robustness of MFM compared with recent masked image modeling approaches. Furthermore, we also comprehensively investigate the effectiveness of classical image restoration tasks for representation learning from a unified frequency perspective and reveal their intriguing relations with our MFM approach. Project page: https://www.mmlab-ntu.com/project/mfm/index.html.
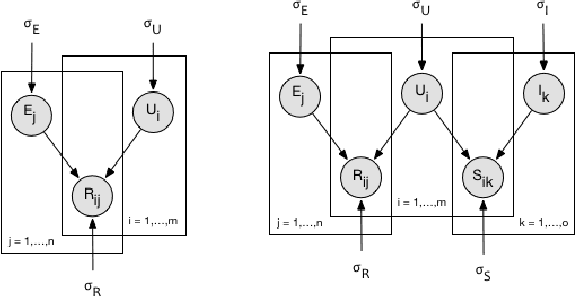
An Environmental Feature Representation in I-vector Space for Room Verification and Metadata Estimation
Mar 09, 2022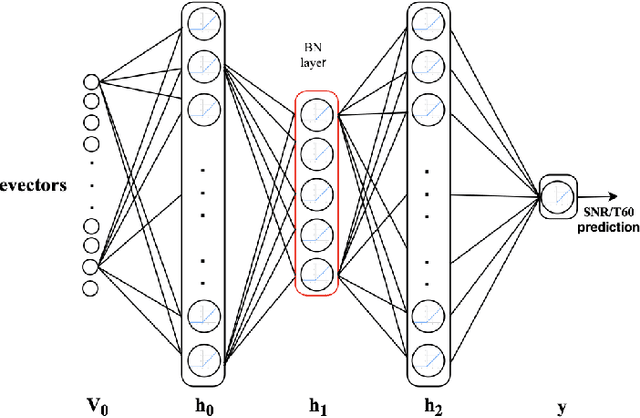
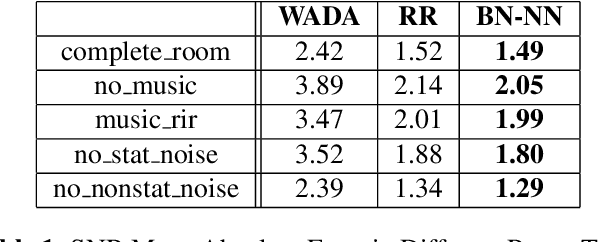
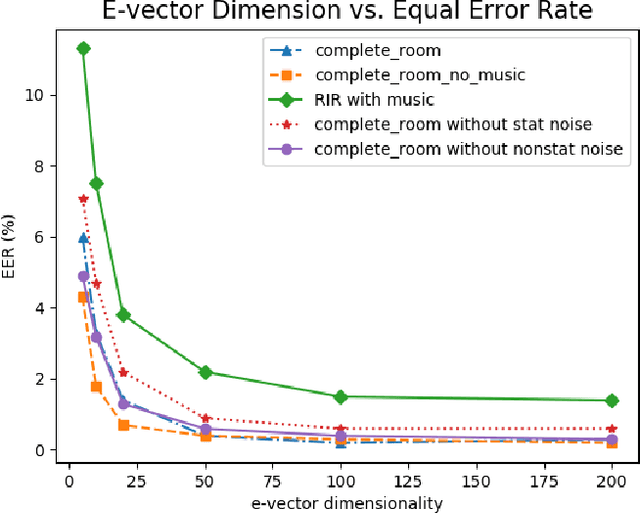
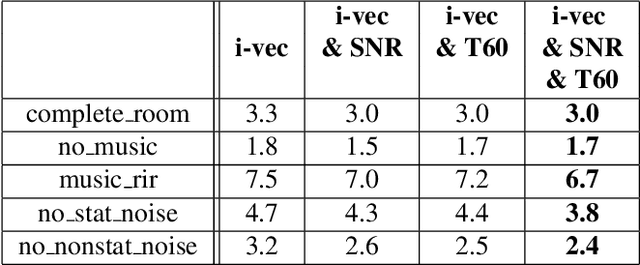
This paper investigates the application of environmental feature representations for room verification tasks and acoustic meta-data estimation. Audio recordings contain both speaker and non-speaker information. We refer to the non-speaker-related information, including channel and other environmental factors, as e-vectors. I-vectors, commonly used in speaker identification, are extracted in the total variability space and capture both speaker and channel-environment information without discrimination. Accordingly, e-vectors can be extracted from i-vectors using methods such as linear discriminant analysis. In this paper, we first demonstrate that e-vectors can be successfully applied to room verification tasks with a low equal error rate. Second, we propose two methods for estimating metadata information -- signal-to-noise (SNR) and reverberation (T60) -- from these e-vectors. When comparing our system to contemporary global SNR estimation methods, in terms of accuracy, we perform favorably even with low dimensional i-vectors. Lastly, we show that room verification tasks can be improved if e-vectors are augmented with the extracted metadata information.