 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Control of Two-way Coupled Fluid Systems with Differentiable Solvers
Jun 01, 2022
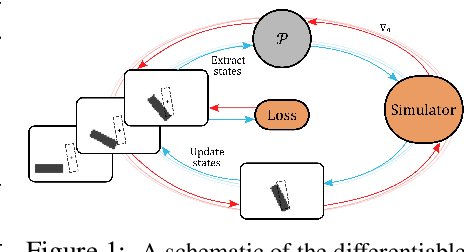
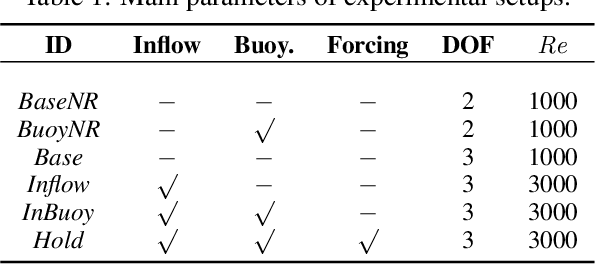
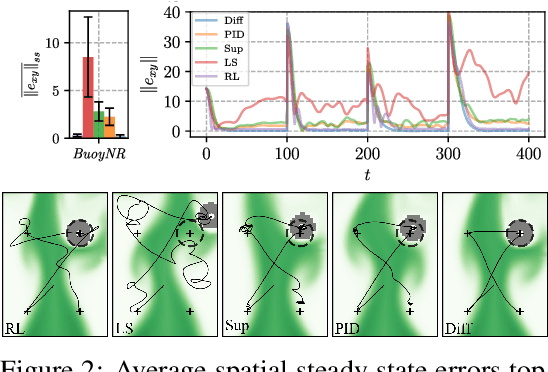
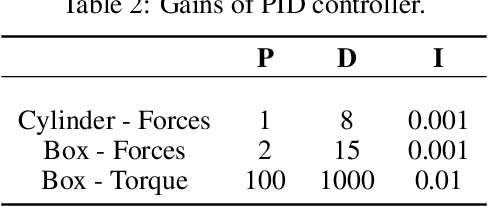
We investigate the use of deep neural networks to control complex nonlinear dynamical systems, specifically the movement of a rigid body immersed in a fluid. We solve the Navier Stokes equations with two way coupling, which gives rise to nonlinear perturbations that make the control task very challenging. Neural networks are trained in an unsupervised way to act as controllers with desired characteristics through a process of learning from a differentiable simulator. Here we introduce a set of physically interpretable loss terms to let the networks learn robust and stable interactions. We demonstrate that controllers trained in a canonical setting with quiescent initial conditions reliably generalize to varied and challenging environments such as previously unseen inflow conditions and forcing, although they do not have any fluid information as input. Further, we show that controllers trained with our approach outperform a variety of classical and learned alternatives in terms of evaluation metrics and generalization capabilities.
JNMR: Joint Non-linear Motion Regression for Video Frame Interpolation
Jun 09, 2022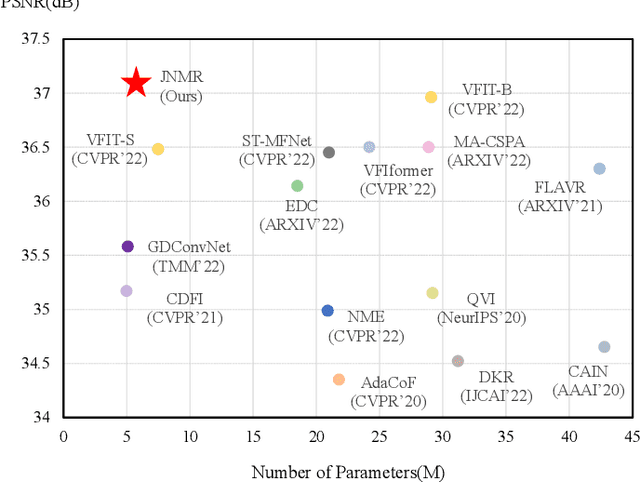

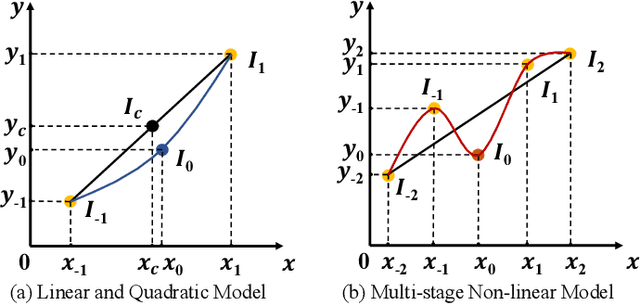
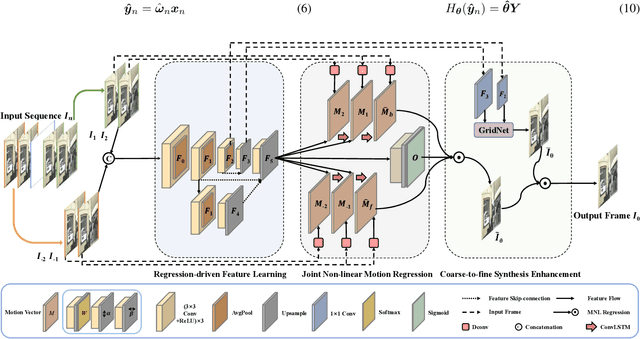
Video frame interpolation (VFI) aims to generate predictive frames by warping learnable motions from the bidirectional historical references. Most existing works utilize spatio-temporal semantic information extractor to realize motion estimation and interpolation modeling, not enough considering with the real mechanistic rationality of generated middle motions. In this paper, we reformulate VFI as a multi-variable non-linear (MNL) regression problem, and a Joint Non-linear Motion Regression (JNMR) strategy is proposed to model complicated motions of inter-frame. To establish the MNL regression, ConvLSTM is adopted to construct the distribution of complete motions in temporal dimension. The motion correlations between the target frame and multiple reference frames can be regressed by the modeled distribution. Moreover, the feature learning network is designed to optimize for the MNL regression modeling. A coarse-to-fine synthesis enhancement module is further conducted to learn visual dynamics at different resolutions through repetitive regression and interpolation. Highly competitive experimental results on frame interpolation show that the effectiveness and significant improvement compared with state-of-the-art performance, and the robustness of complicated motion estimation is improved by the MNL motion regression.
Learn from Structural Scope: Improving Aspect-Level Sentiment Analysis with Hybrid Graph Convolutional Networks
Apr 27, 2022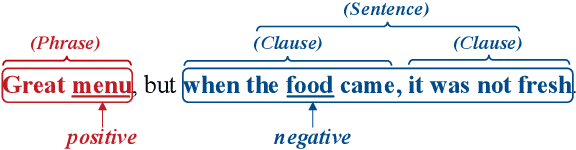
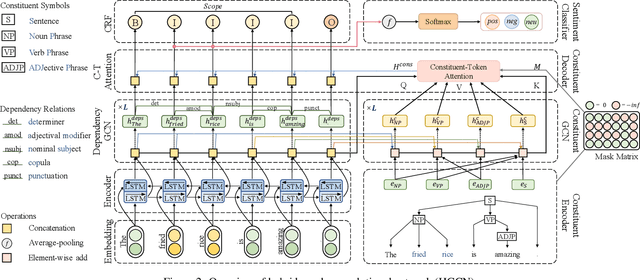
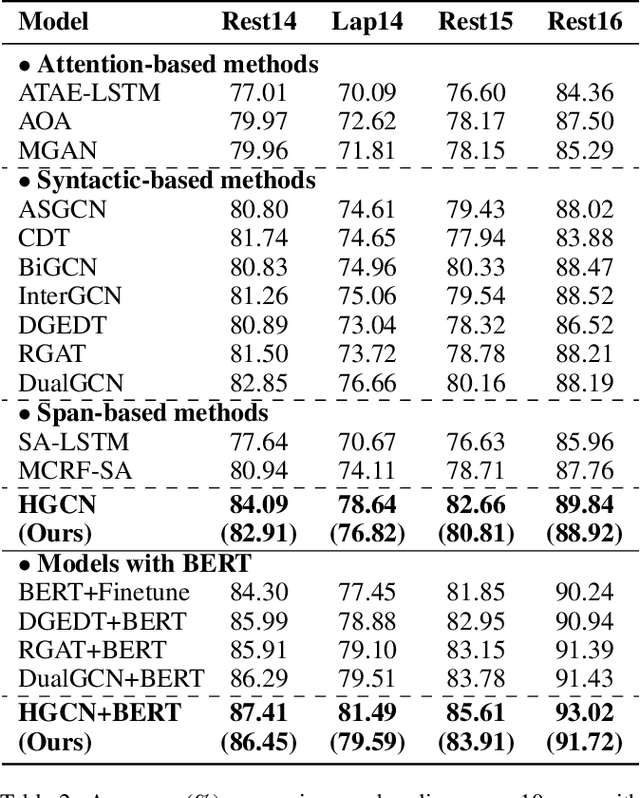
Aspect-level sentiment analysis aims to determine the sentiment polarity towards a specific target in a sentence. The main challenge of this task is to effectively model the relation between targets and sentiments so as to filter out noisy opinion words from irrelevant targets. Most recent efforts capture relations through target-sentiment pairs or opinion spans from a word-level or phrase-level perspective. Based on the observation that targets and sentiments essentially establish relations following the grammatical hierarchy of phrase-clause-sentence structure, it is hopeful to exploit comprehensive syntactic information for better guiding the learning process. Therefore, we introduce the concept of Scope, which outlines a structural text region related to a specific target. To jointly learn structural Scope and predict the sentiment polarity, we propose a hybrid graph convolutional network (HGCN) to synthesize information from constituency tree and dependency tree, exploring the potential of linking two syntax parsing methods to enrich the representation. Experimental results on four public datasets illustrate that our HGCN model outperforms current state-of-the-art baselines.
Stochastic Gradient Methods with Preconditioned Updates
Jun 01, 2022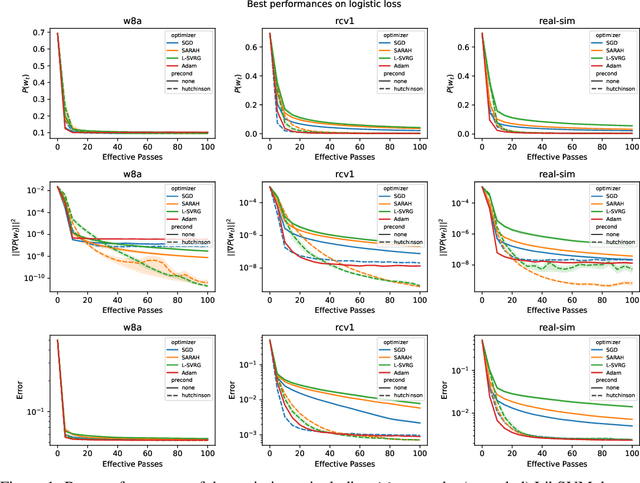
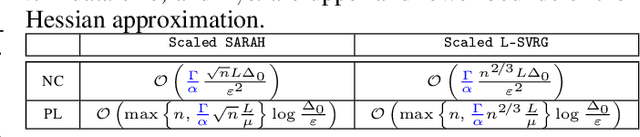
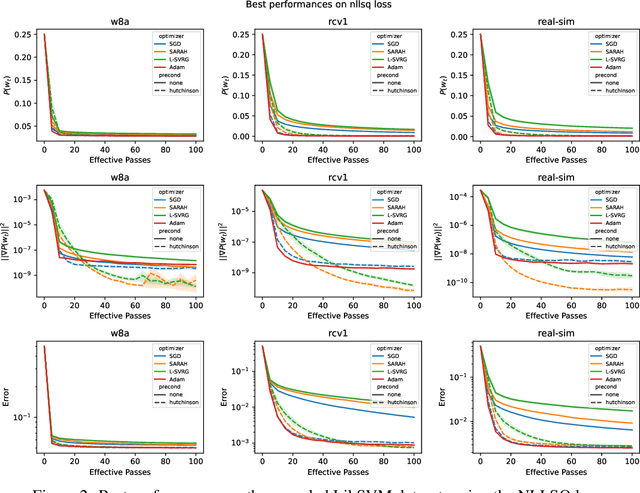

This work considers non-convex finite sum minimization. There are a number of algorithms for such problems, but existing methods often work poorly when the problem is badly scaled and/or ill-conditioned, and a primary goal of this work is to introduce methods that alleviate this issue. Thus, here we include a preconditioner that is based upon Hutchinson's approach to approximating the diagonal of the Hessian, and couple it with several gradient based methods to give new `scaled' algorithms: {\tt Scaled SARAH} and {\tt Scaled L-SVRG}. Theoretical complexity guarantees under smoothness assumptions are presented, and we prove linear convergence when both smoothness and the PL-condition is assumed. Because our adaptively scaled methods use approximate partial second order curvature information, they are better able to mitigate the impact of badly scaled problems, and this improved practical performance is demonstrated in the numerical experiments that are also presented in this work.
XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding
Mar 14, 2022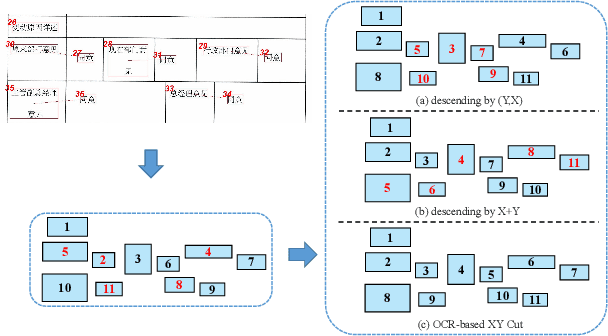
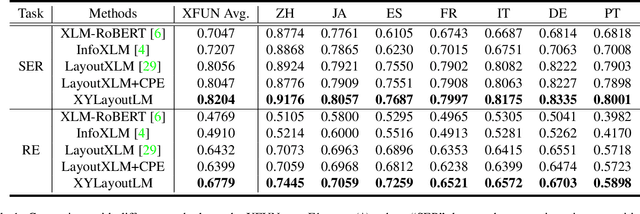
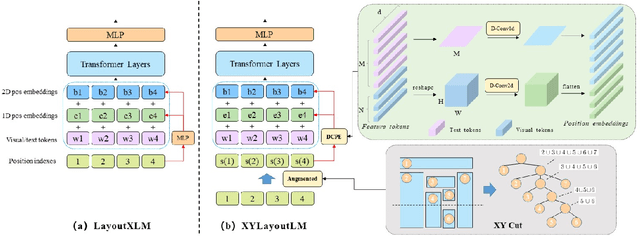
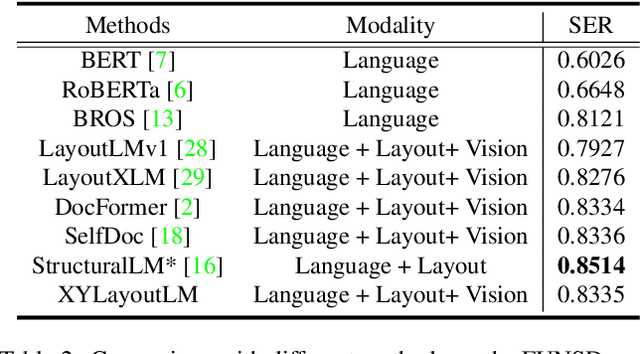
Recently, various multimodal networks for Visually-Rich Document Understanding(VRDU) have been proposed, showing the promotion of transformers by integrating visual and layout information with the text embeddings. However, most existing approaches utilize the position embeddings to incorporate the sequence information, neglecting the noisy improper reading order obtained by OCR tools. In this paper, we propose a robust layout-aware multimodal network named XYLayoutLM to capture and leverage rich layout information from proper reading orders produced by our Augmented XY Cut. Moreover, a Dilated Conditional Position Encoding module is proposed to deal with the input sequence of variable lengths, and it additionally extracts local layout information from both textual and visual modalities while generating position embeddings. Experiment results show that our XYLayoutLM achieves competitive results on document understanding tasks.
Learning Multitask Gaussian Bayesian Networks
May 11, 2022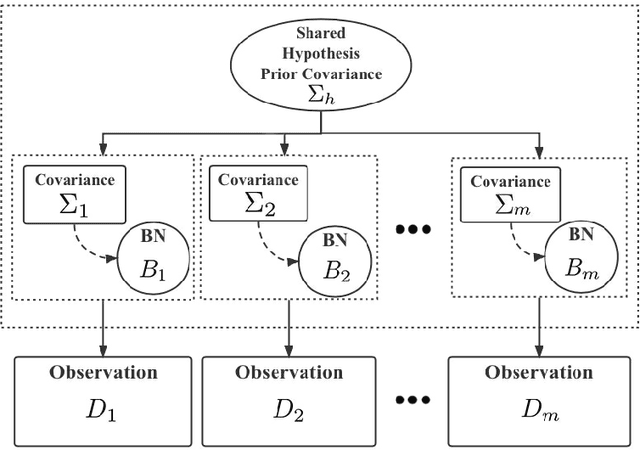
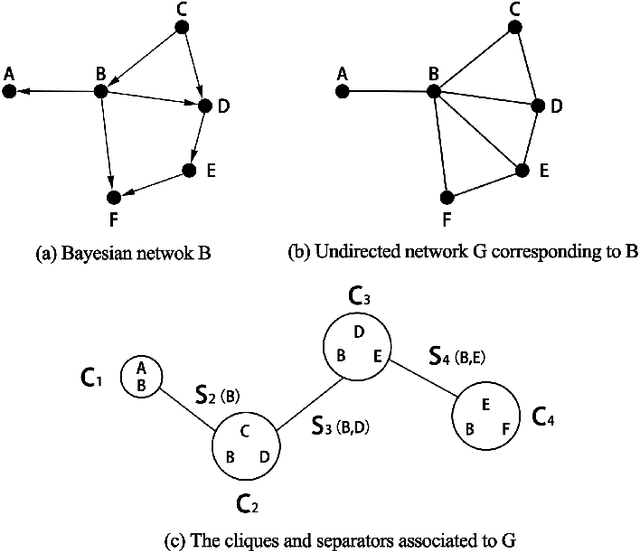
Major depressive disorder (MDD) requires study of brain functional connectivity alterations for patients, which can be uncovered by resting-state functional magnetic resonance imaging (rs-fMRI) data. We consider the problem of identifying alterations of brain functional connectivity for a single MDD patient. This is particularly difficult since the amount of data collected during an fMRI scan is too limited to provide sufficient information for individual analysis. Additionally, rs-fMRI data usually has the characteristics of incompleteness, sparsity, variability, high dimensionality and high noise. To address these problems, we proposed a multitask Gaussian Bayesian network (MTGBN) framework capable for identifying individual disease-induced alterations for MDD patients. We assume that such disease-induced alterations show some degrees of similarity with the tool to learn such network structures from observations to understanding of how system are structured jointly from related tasks. First, we treat each patient in a class of observation as a task and then learn the Gaussian Bayesian networks (GBNs) of this data class by learning from all tasks that share a default covariance matrix that encodes prior knowledge. This setting can help us to learn more information from limited data. Next, we derive a closed-form formula of the complete likelihood function and use the Monte-Carlo Expectation-Maximization(MCEM) algorithm to search for the approximately best Bayesian network structures efficiently. Finally, we assess the performance of our methods with simulated and real-world rs-fMRI data.
Temporal Multiresolution Graph Neural Networks For Epidemic Prediction
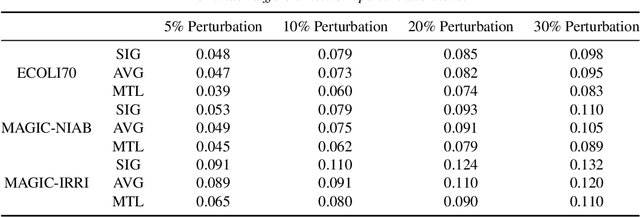
Jun 01, 2022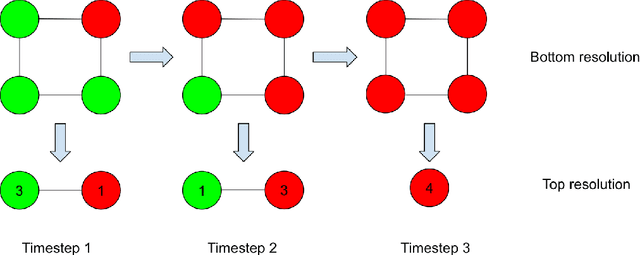
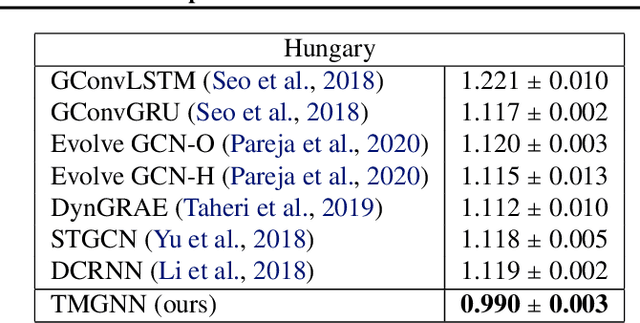
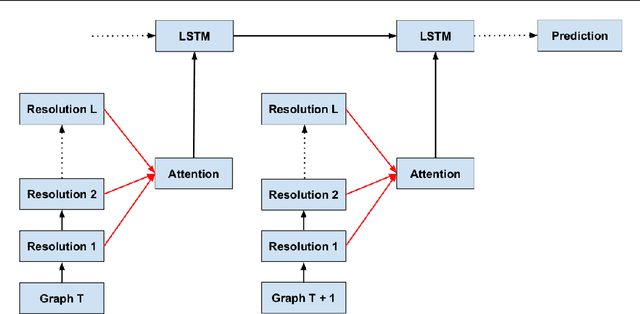
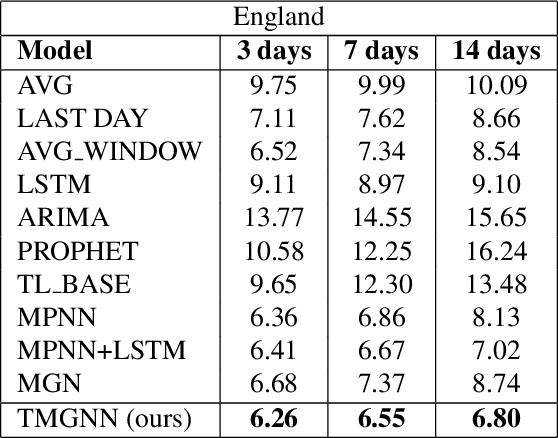
In this paper, we introduce Temporal Multiresolution Graph Neural Networks (TMGNN), the first architecture that both learns to construct the multiscale and multiresolution graph structures and incorporates the time-series signals to capture the temporal changes of the dynamic graphs. We have applied our proposed model to the task of predicting future spreading of epidemic and pandemic based on the historical time-series data collected from the actual COVID-19 pandemic and chickenpox epidemic in several European countries, and have obtained competitive results in comparison to other previous state-of-the-art temporal architectures and graph learning algorithms. We have shown that capturing the multiscale and multiresolution structures of graphs is important to extract either local or global information that play a critical role in understanding the dynamic of a global pandemic such as COVID-19 which started from a local city and spread to the whole world. Our work brings a promising research direction in forecasting and mitigating future epidemics and pandemics.
Trend analysis and forecasting air pollution in Rwanda
May 20, 2022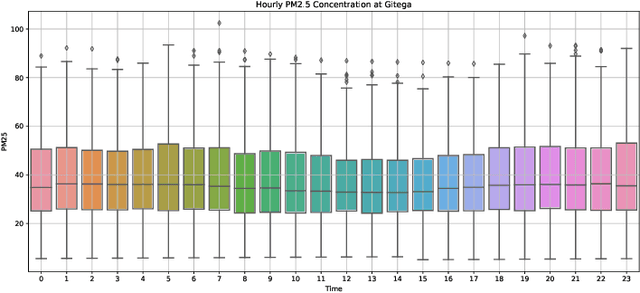
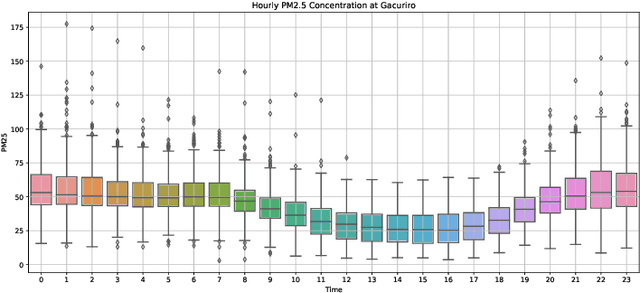
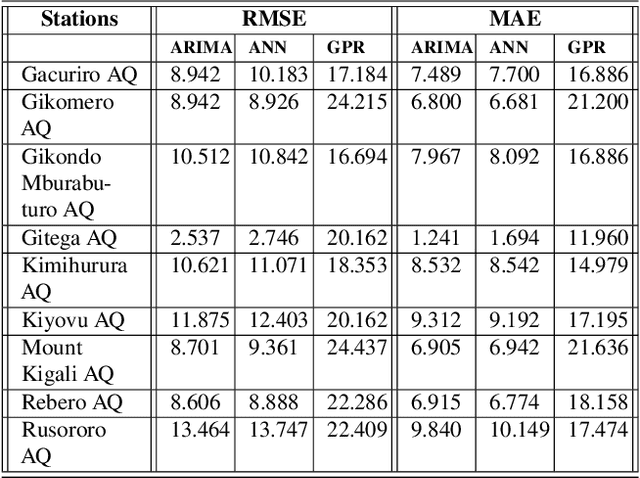
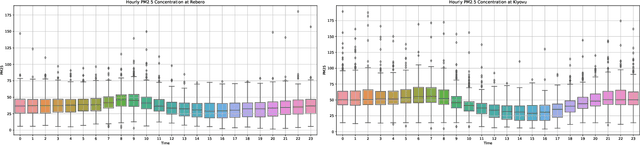
Air pollution is a major public health problem worldwide although the lack of data is a global issue for most low and middle income countries. Ambient air pollution in the form of fine particulate matter (PM2.5) exceeds the World Health Organization guidelines in Rwanda with a daily average of around 42.6 microgram per meter cube. Monitoring and mitigation strategies require an expensive investment in equipment to collect pollution data. Low-cost sensor technology and machine learning methods have appeared as an alternative solution to get reliable information for decision making. This paper analyzes the trend of air pollution in Rwanda and proposes forecasting models suitable to data collected by a network of low-cost sensors deployed in Rwanda.
Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks
Feb 25, 2021
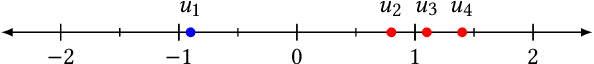

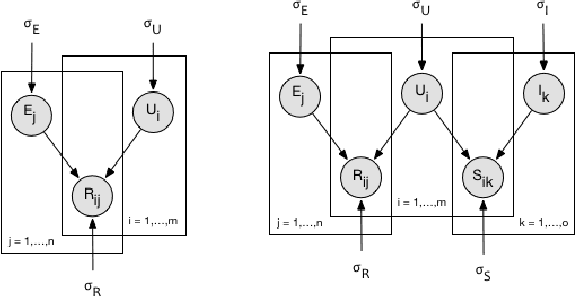
Most existing personalization systems promote items that match a user's previous choices or those that are popular among similar users. This results in recommendations that are highly similar to the ones users are already exposed to, resulting in their isolation inside familiar but insulated information silos. In this context, we develop a novel recommendation framework with a goal of improving information diversity using a modified random walk exploration of the user-item graph. We focus on the problem of political content recommendation, while addressing a general problem applicable to personalization tasks in other social and information networks. For recommending political content on social networks, we first propose a new model to estimate the ideological positions for both users and the content they share, which is able to recover ideological positions with high accuracy. Based on these estimated positions, we generate diversified personalized recommendations using our new random-walk based recommendation algorithm. With experimental evaluations on large datasets of Twitter discussions, we show that our method based on \emph{random walks with erasure} is able to generate more ideologically diverse recommendations. Our approach does not depend on the availability of labels regarding the bias of users or content producers. With experiments on open benchmark datasets from other social and information networks, we also demonstrate the effectiveness of our method in recommending diverse long-tail items.
* Web Conference 2021 (WWW '21)
Negative Sampling for Contrastive Representation Learning: A Review
Jun 01, 2022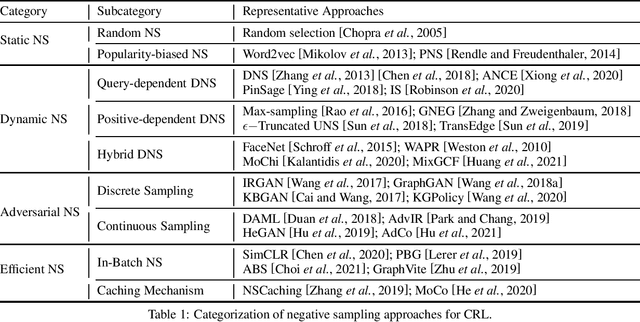
The learn-to-compare paradigm of contrastive representation learning (CRL), which compares positive samples with negative ones for representation learning, has achieved great success in a wide range of domains, including natural language processing, computer vision, information retrieval and graph learning. While many research works focus on data augmentations, nonlinear transformations or other certain parts of CRL, the importance of negative sample selection is usually overlooked in literature. In this paper, we provide a systematic review of negative sampling (NS) techniques and discuss how they contribute to the success of CRL. As the core part of this paper, we summarize the existing NS methods into four categories with pros and cons in each genre, and further conclude with several open research questions as future directions. By generalizing and aligning the fundamental NS ideas across multiple domains, we hope this survey can accelerate cross-domain knowledge sharing and motivate future researches for better CRL.