 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI$^2$VC: A Unified Framework for Intra- \& Inter-frame Video Compression
May 23, 2024



Video compression aims to reconstruct seamless frames by encoding the motion and residual information from existing frames. Previous neural video compression methods necessitate distinct codecs for three types of frames (I-frame, P-frame and B-frame), which hinders a unified approach and generalization across different video contexts. Intra-codec techniques lack the advanced Motion Estimation and Motion Compensation (MEMC) found in inter-codec, leading to fragmented frameworks lacking uniformity. Our proposed \textbf{Intra- \& Inter-frame Video Compression (I$^2$VC)} framework employs a single spatio-temporal codec that guides feature compression rates according to content importance. This unified codec transforms the dependence across frames into a conditional coding scheme, thus integrating intra- and inter-frame compression into one cohesive strategy. Given the absence of explicit motion data, achieving competent inter-frame compression with only a conditional codec poses a challenge. To resolve this, our approach includes an implicit inter-frame alignment mechanism. With the pre-trained diffusion denoising process, the utilization of a diffusion-inverted reference feature rather than random noise supports the initial compression state. This process allows for selective denoising of motion-rich regions based on decoded features, facilitating accurate alignment without the need for MEMC. Our experimental findings, across various compression configurations (AI, LD and RA) and frame types, prove that I$^2$VC outperforms the state-of-the-art perceptual learned codecs. Impressively, it exhibits a 58.4\% enhancement in perceptual reconstruction performance when benchmarked against the H.266/VVC standard (VTM). Official implementation can be found at \href{https://github.com/GYukai/I2VC}{https://github.com/GYukai/I2VC}
IBVC: Interpolation-driven B-frame Video Compression
Sep 25, 2023



Learned B-frame video compression aims to adopt bi-directional motion estimation and motion compensation (MEMC) coding for middle frame reconstruction. However, previous learned approaches often directly extend neural P-frame codecs to B-frame relying on bi-directional optical-flow estimation or video frame interpolation. They suffer from inaccurate quantized motions and inefficient motion compensation. To address these issues, we propose a simple yet effective structure called Interpolation-driven B-frame Video Compression (IBVC). Our approach only involves two major operations: video frame interpolation and artifact reduction compression. IBVC introduces a bit-rate free MEMC based on interpolation, which avoids optical-flow quantization and additional compression distortions. Later, to reduce duplicate bit-rate consumption and focus on unaligned artifacts, a residual guided masking encoder is deployed to adaptively select the meaningful contexts with interpolated multi-scale dependencies. In addition, a conditional spatio-temporal decoder is proposed to eliminate location errors and artifacts instead of using MEMC coding in other methods. The experimental results on B-frame coding demonstrate that IBVC has significant improvements compared to the relevant state-of-the-art methods. Meanwhile, our approach can save bit rates compared with the random access (RA) configuration of H.266 (VTM). The code will be available at https://github.com/ruhig6/IBVC.
A simple normalization technique using window statistics to improve the out-of-distribution generalization on medical images
Jul 14, 2022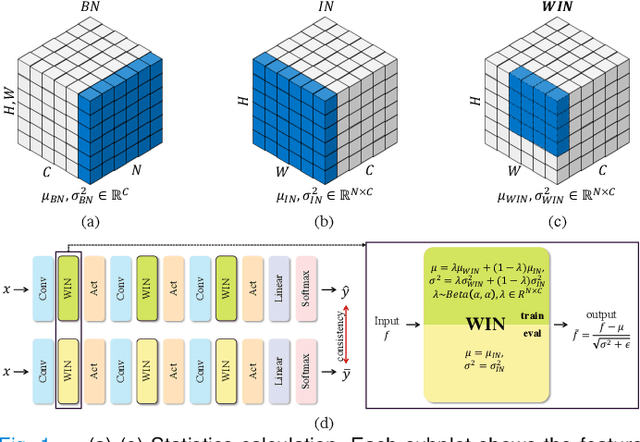
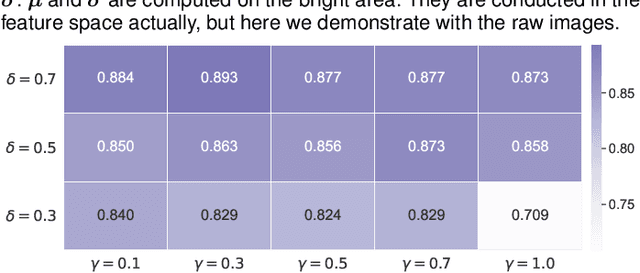

Since data scarcity and data heterogeneity are prevailing for medical images, well-trained Convolutional Neural Networks (CNNs) using previous normalization methods may perform poorly when deployed to a new site. However, a reliable model for real-world clinical applications should be able to generalize well both on in-distribution (IND) and out-of-distribution (OOD) data (e.g., the new site data). In this study, we present a novel normalization technique called window normalization (WIN) to improve the model generalization on heterogeneous medical images, which is a simple yet effective alternative to existing normalization methods. Specifically, WIN perturbs the normalizing statistics with the local statistics computed on the window of features. This feature-level augmentation technique regularizes the models well and improves their OOD generalization significantly. Taking its advantage, we propose a novel self-distillation method called WIN-WIN for classification tasks. WIN-WIN is easily implemented with twice forward passes and a consistency constraint, which can be a simple extension for existing methods. Extensive experimental results on various tasks (6 tasks) and datasets (24 datasets) demonstrate the generality and effectiveness of our methods.
JNMR: Joint Non-linear Motion Regression for Video Frame Interpolation
Jun 09, 2022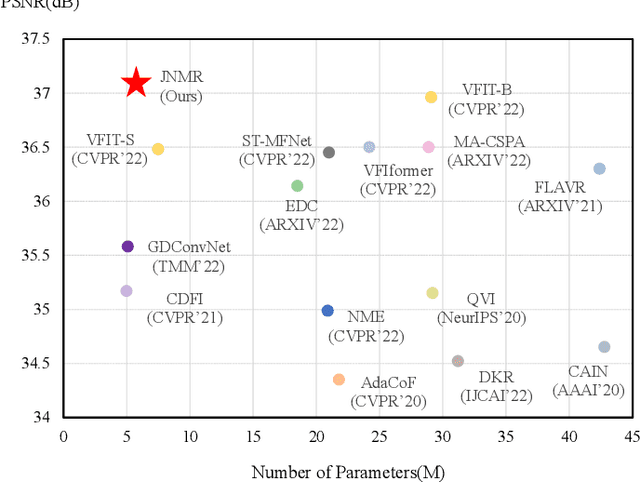

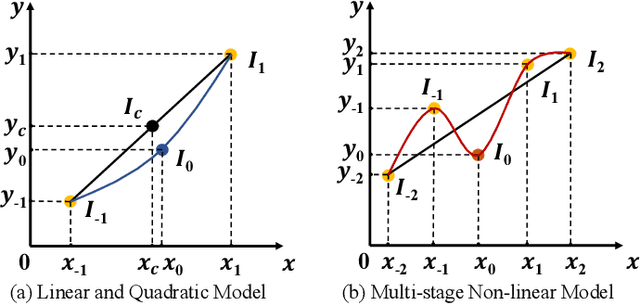
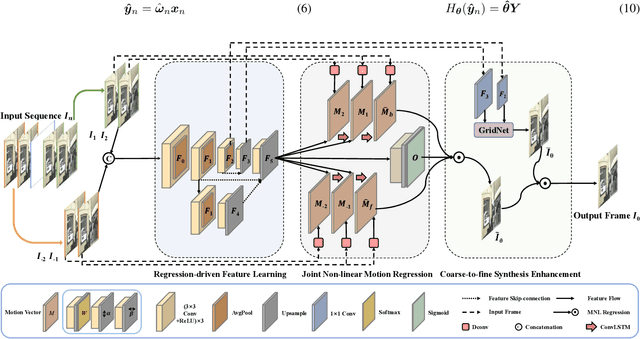
Video frame interpolation (VFI) aims to generate predictive frames by warping learnable motions from the bidirectional historical references. Most existing works utilize spatio-temporal semantic information extractor to realize motion estimation and interpolation modeling, not enough considering with the real mechanistic rationality of generated middle motions. In this paper, we reformulate VFI as a multi-variable non-linear (MNL) regression problem, and a Joint Non-linear Motion Regression (JNMR) strategy is proposed to model complicated motions of inter-frame. To establish the MNL regression, ConvLSTM is adopted to construct the distribution of complete motions in temporal dimension. The motion correlations between the target frame and multiple reference frames can be regressed by the modeled distribution. Moreover, the feature learning network is designed to optimize for the MNL regression modeling. A coarse-to-fine synthesis enhancement module is further conducted to learn visual dynamics at different resolutions through repetitive regression and interpolation. Highly competitive experimental results on frame interpolation show that the effectiveness and significant improvement compared with state-of-the-art performance, and the robustness of complicated motion estimation is improved by the MNL motion regression.
An attention-based Bi-GRU-CapsNet model for hypernymy detection between compound entities
May 18, 2018
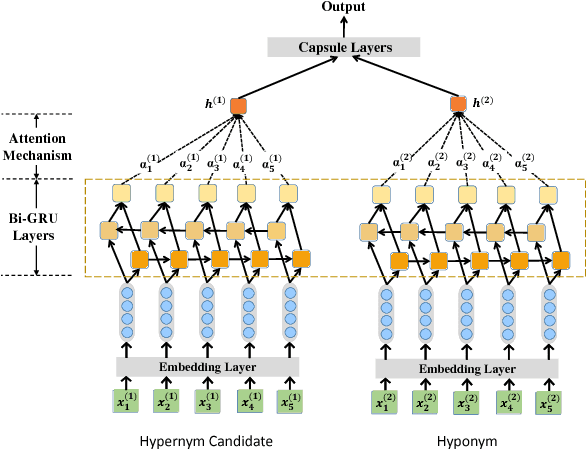
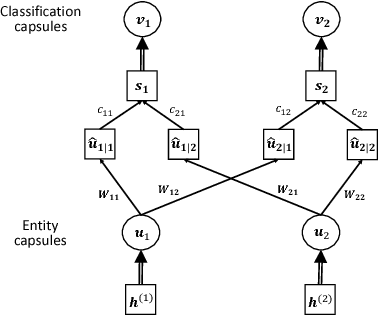
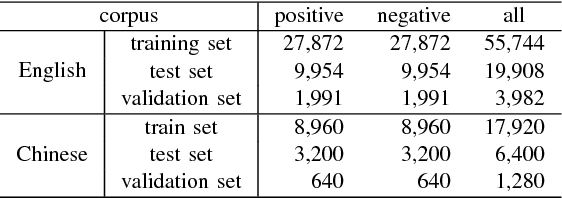
Named entities which composed of multiple continuous words frequently occur in domain-specific knowledge graphs. These entities are usually composable and extensible. Typical examples are names of symptoms and diseases in medical areas. To distinguish these entities from general entities, we name them compound entities. Hypernymy detection between compound entities plays an important role in domain-specific knowledge graph construction. Traditional hypernymy detection approaches cannot perform well on compound entities due to the lack of contextual information in texts, and even the absence of compound entities in training sets, i.e. Out-Of-Vocabulary (OOV) problem. In this paper, we present a novel attention-based Bi-GRU-CapsNet model to detect hypernymy relationship between compound entities. Our model consists of several important components. To avoid the OOV problem, English words or Chinese characters in compound entities are fed into Bidirectional Gated Recurrent Units (Bi-GRUs). An attention mechanism is designed to focus on the differences between two compound entities. Since there are some different cases in hypernymy relationship between compound entities, Capsule Network (CapsNet) is finally employed to decide whether the hypernymy relationship exists or not. Experimental results demonstrate the advantages of our model over the state-of-the-art methods both on English and Chinese corpora of symptom and disease pairs.