 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disentangled and Side-aware Unsupervised Domain Adaptation for Cross-dataset Subjective Tinnitus Diagnosis
May 03, 2022
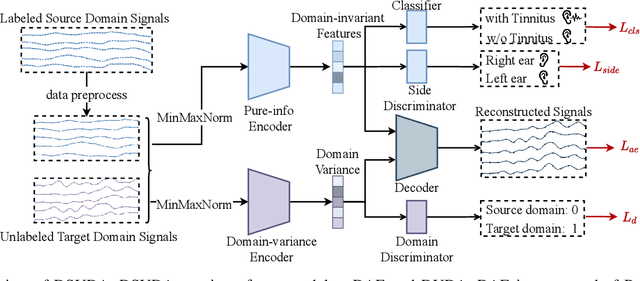
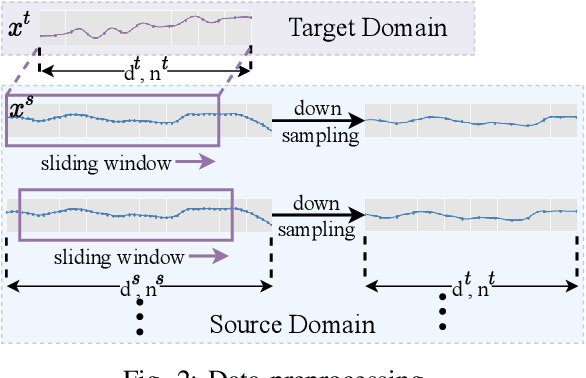
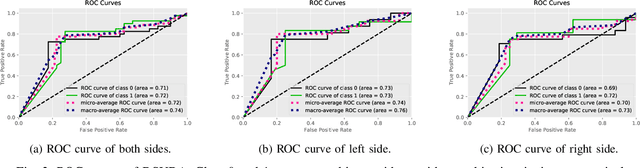
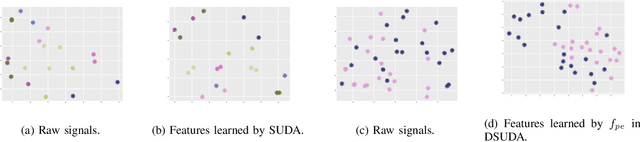
EEG-based tinnitus classification is a valuable tool for tinnitus diagnosis, research, and treatments. Most current works are limited to a single dataset where data patterns are similar. But EEG signals are highly non-stationary, resulting in model's poor generalization to new users, sessions or datasets. Thus, designing a model that can generalize to new datasets is beneficial and indispensable. To mitigate distribution discrepancy across datasets, we propose to achieve Disentangled and Side-aware Unsupervised Domain Adaptation (DSUDA) for cross-dataset tinnitus diagnosis. A disentangled auto-encoder is developed to decouple class-irrelevant information from the EEG signals to improve the classifying ability. The side-aware unsupervised domain adaptation module adapts the class-irrelevant information as domain variance to a new dataset and excludes the variance to obtain the class-distill features for the new dataset classification. It also align signals of left and right ears to overcome inherent EEG pattern difference. We compare DSUDA with state-of-the-art methods, and our model achieves significant improvements over competitors regarding comprehensive evaluation criteria. The results demonstrate our model can successfully generalize to a new dataset and effectively diagnose tinnitus.
All Mistakes Are Not Equal: Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP)
Jun 17, 2022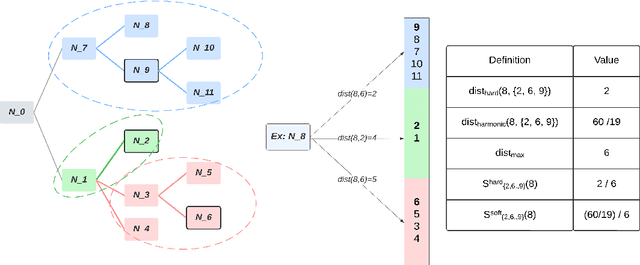
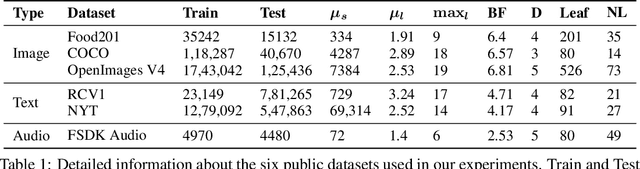
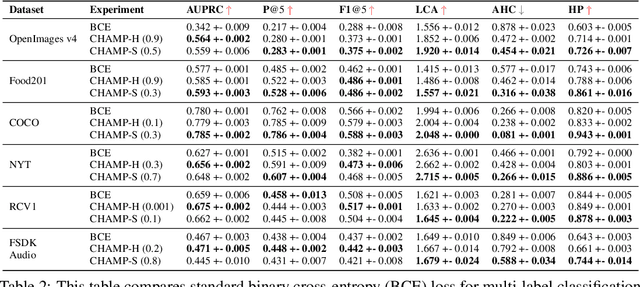
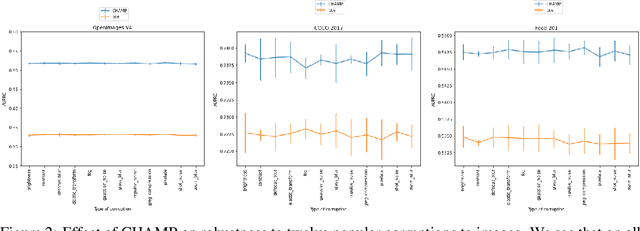
This paper considers the problem of Hierarchical Multi-Label Classification (HMC), where (i) several labels can be present for each example, and (ii) labels are related via a domain-specific hierarchy tree. Guided by the intuition that all mistakes are not equal, we present Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP), a framework that penalizes a misprediction depending on its severity as per the hierarchy tree. While there have been works that apply such an idea to single-label classification, to the best of our knowledge, there are limited such works for multilabel classification focusing on the severity of mistakes. The key reason is that there is no clear way of quantifying the severity of a misprediction a priori in the multilabel setting. In this work, we propose a simple but effective metric to quantify the severity of a mistake in HMC, naturally leading to CHAMP. Extensive experiments on six public HMC datasets across modalities (image, audio, and text) demonstrate that incorporating hierarchical information leads to substantial gains as CHAMP improves both AUPRC (2.6% median percentage improvement) and hierarchical metrics (2.85% median percentage improvement), over stand-alone hierarchical or multilabel classification methods. Compared to standard multilabel baselines, CHAMP provides improved AUPRC in both robustness (8.87% mean percentage improvement ) and less data regimes. Further, our method provides a framework to enhance existing multilabel classification algorithms with better mistakes (18.1% mean percentage increment).
Learning to Minimize Age of Information over an Unreliable Channel with Energy Harvesting
Jun 30, 2021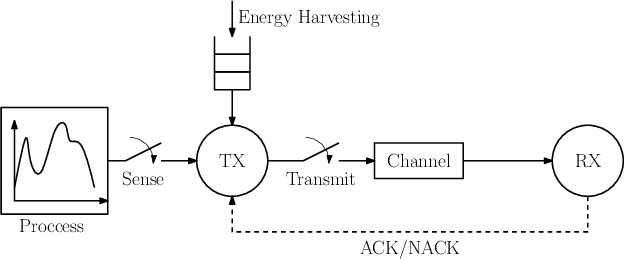
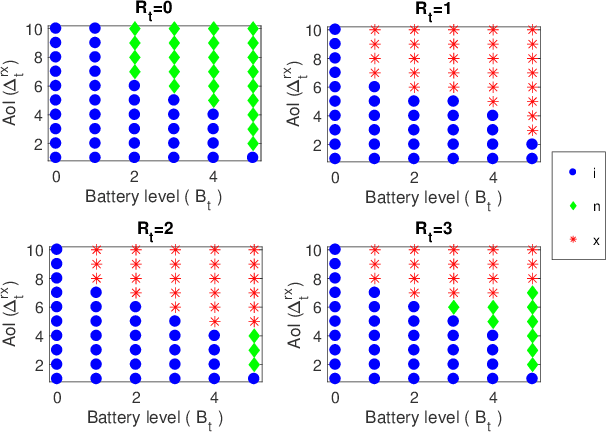
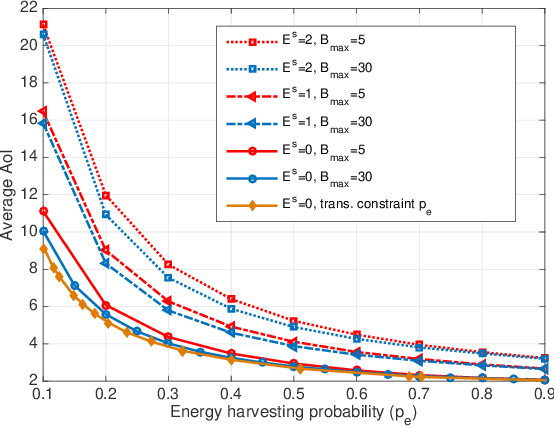
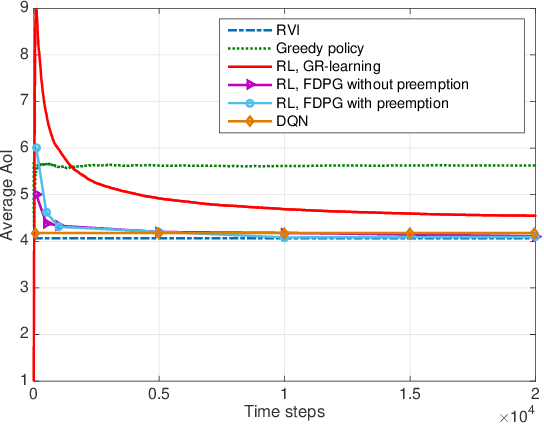
The time average expected age of information (AoI) is studied for status updates sent over an error-prone channel from an energy-harvesting transmitter with a finite-capacity battery. Energy cost of sensing new status updates is taken into account as well as the transmission energy cost better capturing practical systems. The optimal scheduling policy is first studied under the hybrid automatic repeat request (HARQ) protocol when the channel and energy harvesting statistics are known, and the existence of a threshold-based optimal policy is shown. For the case of unknown environments, average-cost reinforcement-learning algorithms are proposed that learn the system parameters and the status update policy in real-time. The effectiveness of the proposed methods is demonstrated through numerical results.
Structured Context Transformer for Generic Event Boundary Detection
Jun 07, 2022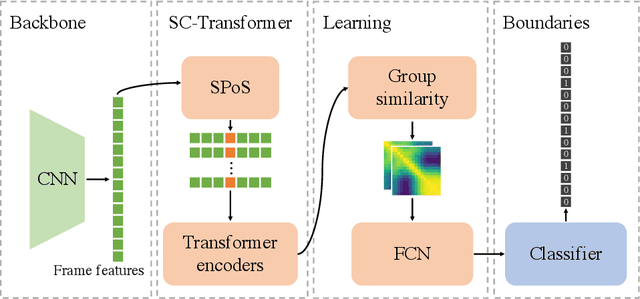
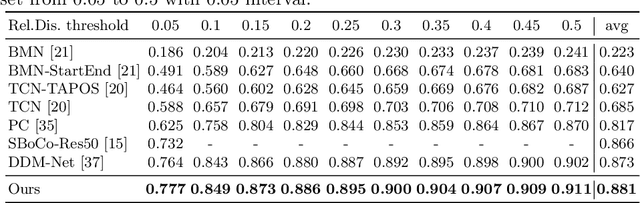
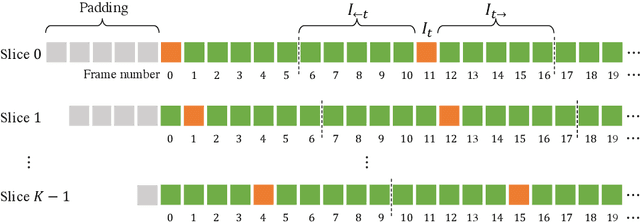
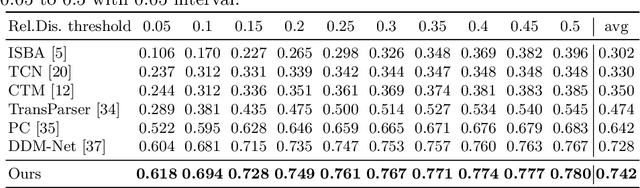
Generic Event Boundary Detection (GEBD) aims to detect moments where humans naturally perceive as event boundaries. In this paper, we present Structured Context Transformer (or SC-Transformer) to solve the GEBD task, which can be trained in an end-to-end fashion. Specifically, we use the backbone convolutional neural network (CNN) to extract the features of each video frame. To capture temporal context information of each frame, we design the structure context transformer (SC-Transformer) by re-partitioning input frame sequence. Note that, the overall computation complexity of SC-Transformer is linear to the video length. After that, the group similarities are computed to capture the differences between frames. Then, a lightweight fully convolutional network is used to determine the event boundaries based on the grouped similarity maps. To remedy the ambiguities of boundary annotations, the Gaussian kernel is adopted to preprocess the ground-truth event boundaries to further boost the accuracy. Extensive experiments conducted on the challenging Kinetics-GEBD and TAPOS datasets demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods.
Jacobian Granger Causal Neural Networks for Analysis of Stationary and Nonstationary Data
May 19, 2022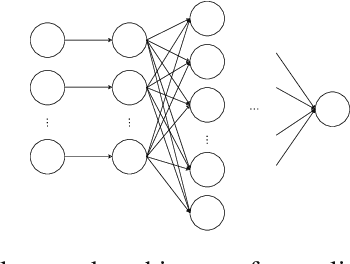
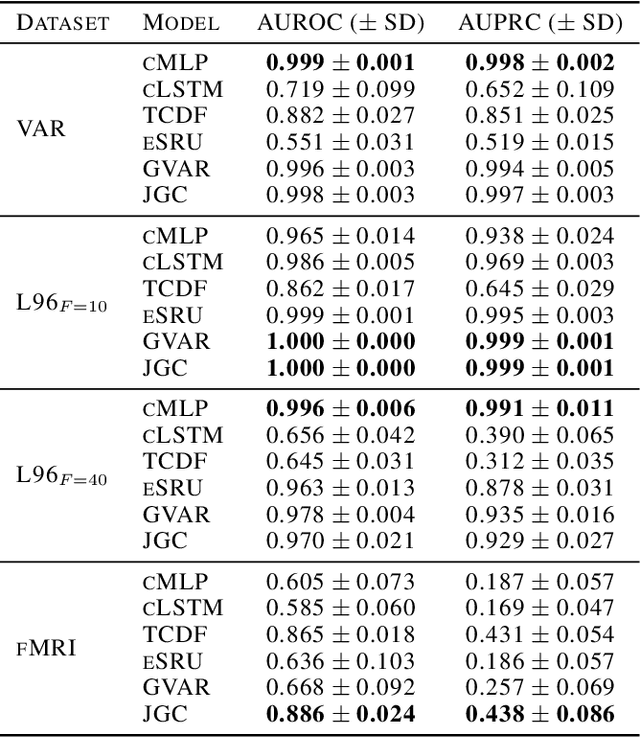
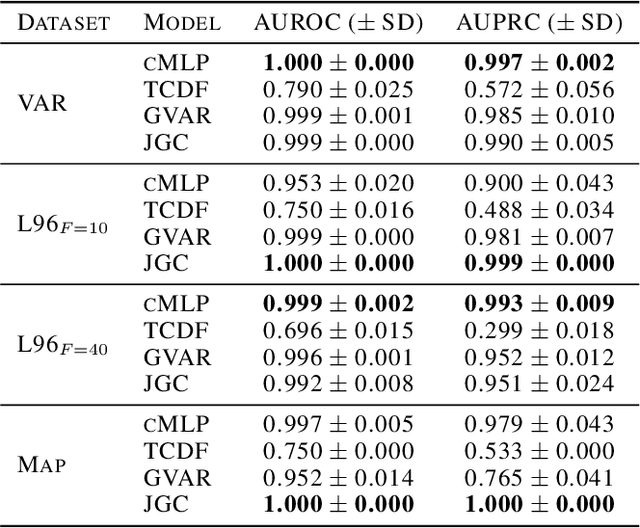
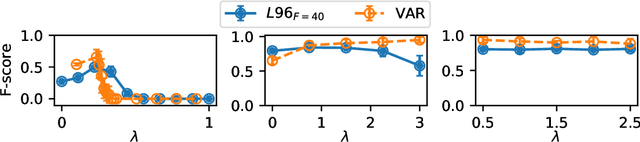
Granger causality is a commonly used method for uncovering information flow and dependencies in a time series. Here we introduce JGC (Jacobian Granger Causality), a neural network-based approach to Granger causality using the Jacobian as a measure of variable importance, and propose a thresholding procedure for inferring Granger causal variables using this measure. The resulting approach performs consistently well compared to other approaches in identifying Granger causal variables, the associated time lags, as well as interaction signs. Lastly, through the inclusion of a time variable, we show that this approach is able to learn the temporal dependencies for nonstationary systems whose Granger causal structures change in time.
GANSlider: How Users Control Generative Models for Images using Multiple Sliders with and without Feedforward Information
Feb 02, 2022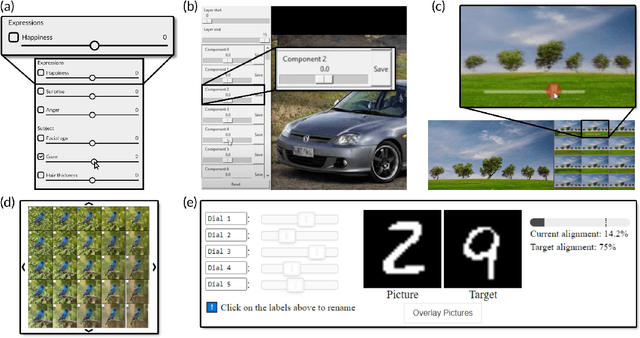
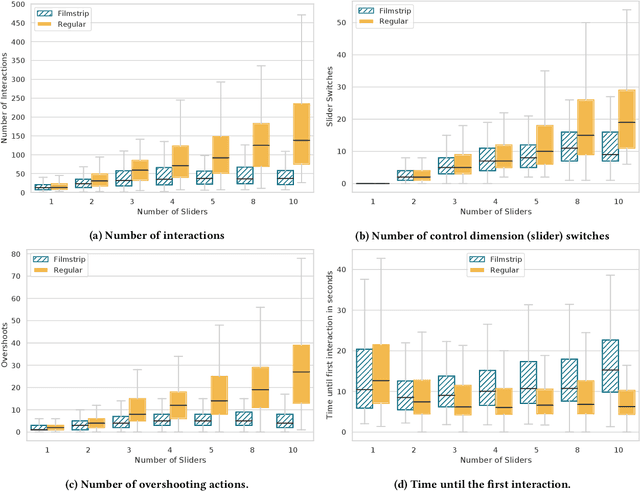
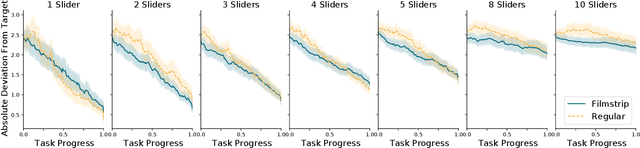
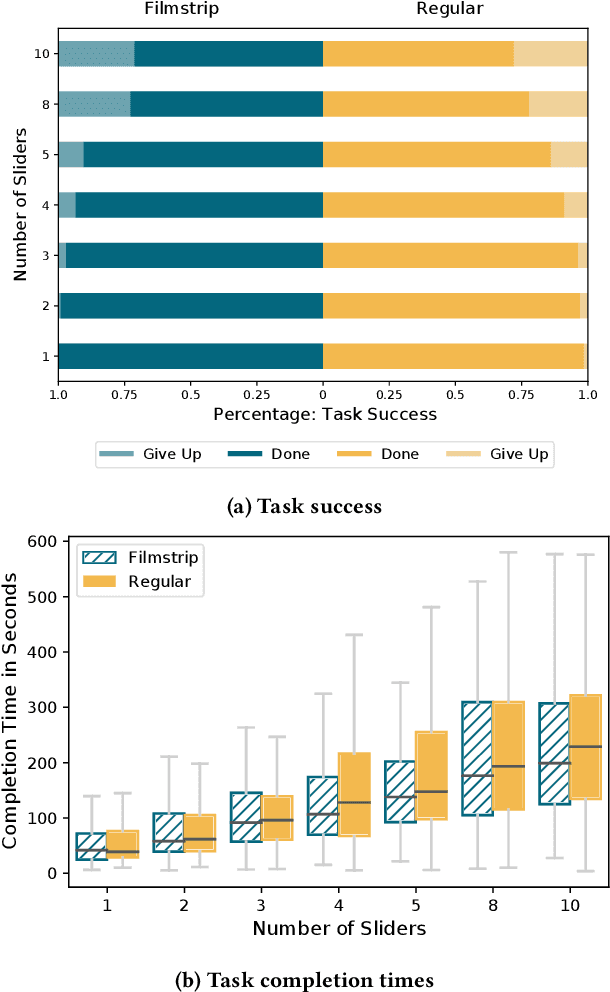
We investigate how multiple sliders with and without feedforward visualizations influence users' control of generative models. In an online study (N=138), we collected a dataset of people interacting with a generative adversarial network (StyleGAN2) in an image reconstruction task. We found that more control dimensions (sliders) significantly increase task difficulty and user actions. Visual feedforward partly mitigates this by enabling more goal-directed interaction. However, we found no evidence of faster or more accurate task performance. This indicates a tradeoff between feedforward detail and implied cognitive costs, such as attention. Moreover, we found that visualizations alone are not always sufficient for users to understand individual control dimensions. Our study quantifies fundamental UI design factors and resulting interaction behavior in this context, revealing opportunities for improvement in the UI design for interactive applications of generative models. We close by discussing design directions and further aspects.
Characterizing the Value of Information in Medical Notes
Oct 07, 2020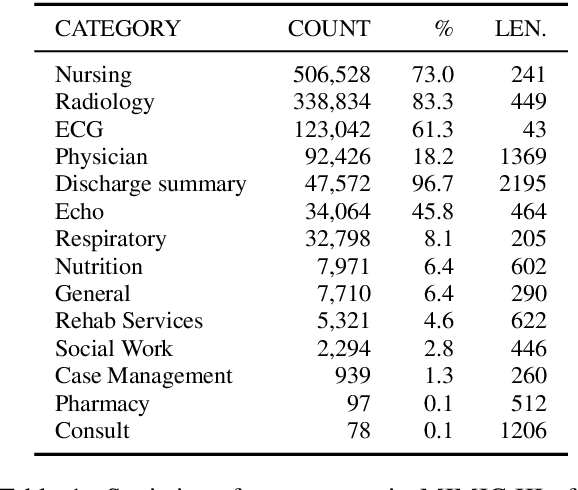
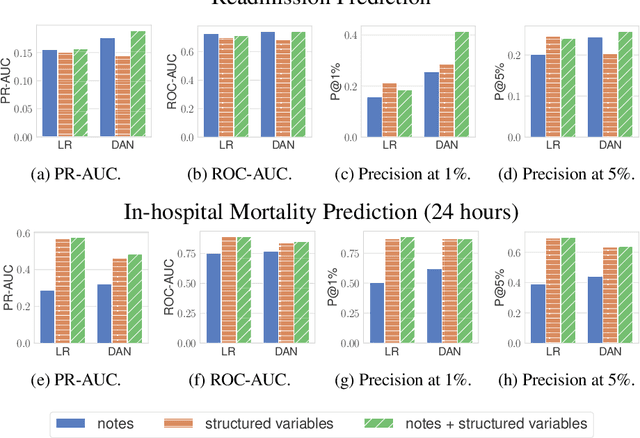

Machine learning models depend on the quality of input data. As electronic health records are widely adopted, the amount of data in health care is growing, along with complaints about the quality of medical notes. We use two prediction tasks, readmission prediction and in-hospital mortality prediction, to characterize the value of information in medical notes. We show that as a whole, medical notes only provide additional predictive power over structured information in readmission prediction. We further propose a probing framework to select parts of notes that enable more accurate predictions than using all notes, despite that the selected information leads to a distribution shift from the training data ("all notes"). Finally, we demonstrate that models trained on the selected valuable information achieve even better predictive performance, with only 6.8% of all the tokens for readmission prediction.
Efficient Annotation and Learning for 3D Hand Pose Estimation: A Survey
Jun 07, 2022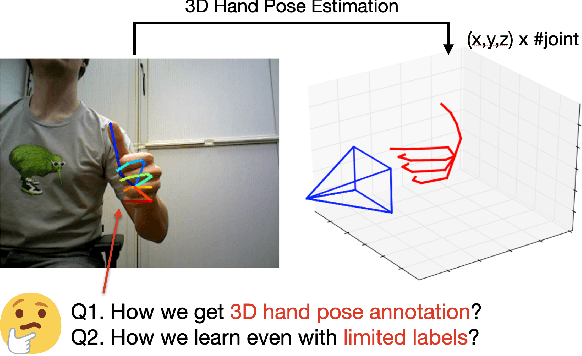
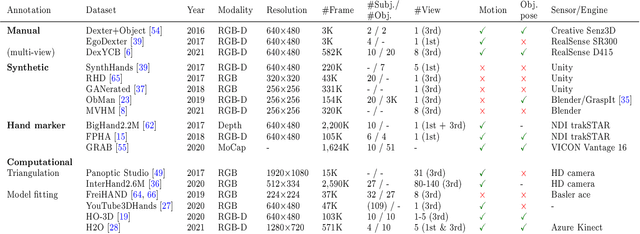
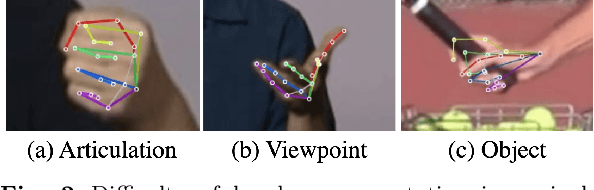
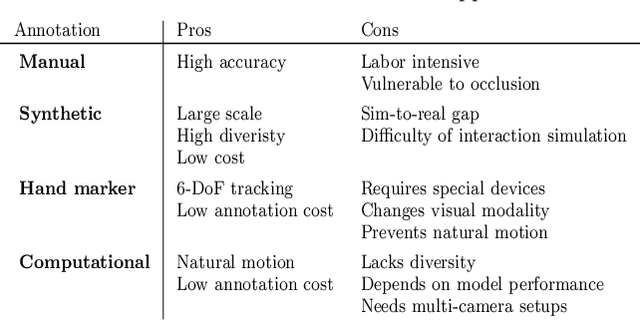
In this survey, we present comprehensive analysis of 3D hand pose estimation from the perspective of efficient annotation and learning. In particular, we study recent approaches for 3D hand pose annotation and learning methods with limited annotated data. In 3D hand pose estimation, collecting 3D hand pose annotation is a key step in developing hand pose estimators and their applications, such as video understanding, AR/VR, and robotics. However, acquiring annotated 3D hand poses is cumbersome, e.g., due to the difficulty of accessing 3D information and occlusion. Motivated by elucidating how recent works address the annotation issue, we investigated annotation methods classified as manual, synthetic-model-based, hand-sensor-based, and computational approaches. Since these annotation methods are not always available on a large scale, we examined methods of learning 3D hand poses when we do not have enough annotated data, namely self-supervised pre-training, semi-supervised learning, and domain adaptation. Based on the analysis of these efficient annotation and learning, we further discuss limitations and possible future directions of this field.
DDoS-UNet: Incorporating temporal information using Dynamic Dual-channel UNet for enhancing super-resolution of dynamic MRI
Feb 10, 2022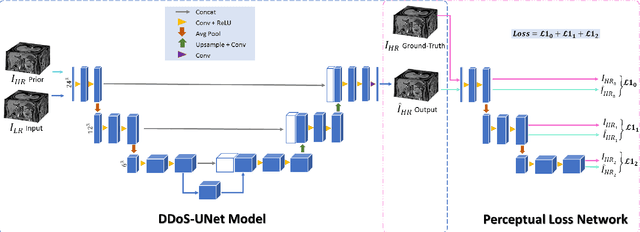
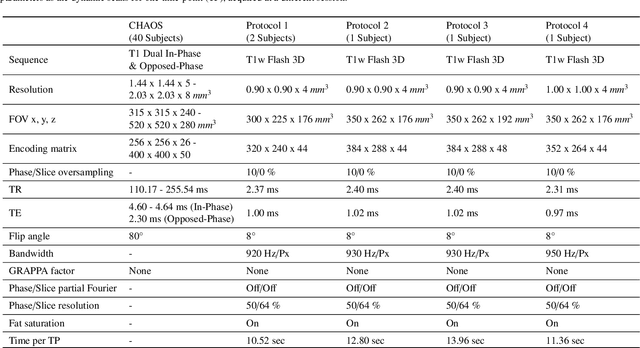

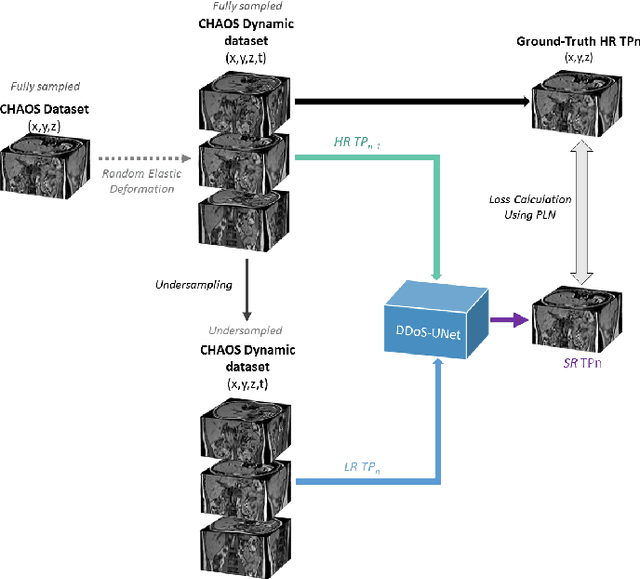
Magnetic resonance imaging (MRI) provides high spatial resolution and excellent soft-tissue contrast without using harmful ionising radiation. Dynamic MRI is an essential tool for interventions to visualise movements or changes of the target organ. However, such MRI acquisition with high temporal resolution suffers from limited spatial resolution - also known as the spatio-temporal trade-off of dynamic MRI. Several approaches, including deep learning based super-resolution approaches, have been proposed to mitigate this trade-off. Nevertheless, such an approach typically aims to super-resolve each time-point separately, treating them as individual volumes. This research addresses the problem by creating a deep learning model which attempts to learn both spatial and temporal relationships. A modified 3D UNet model, DDoS-UNet, is proposed - which takes the low-resolution volume of the current time-point along with a prior image volume. Initially, the network is supplied with a static high-resolution planning scan as the prior image along with the low-resolution input to super-resolve the first time-point. Then it continues step-wise by using the super-resolved time-points as the prior image while super-resolving the subsequent time-points. The model performance was tested with 3D dynamic data that was undersampled to different in-plane levels. The proposed network achieved an average SSIM value of 0.951$\pm$0.017 while reconstructing the lowest resolution data (i.e. only 4\% of the k-space acquired) - which could result in a theoretical acceleration factor of 25. The proposed approach can be used to reduce the required scan-time while achieving high spatial resolution.
End-to-End Information Extraction by Character-Level Embedding and Multi-Stage Attentional U-Net
Jun 02, 2021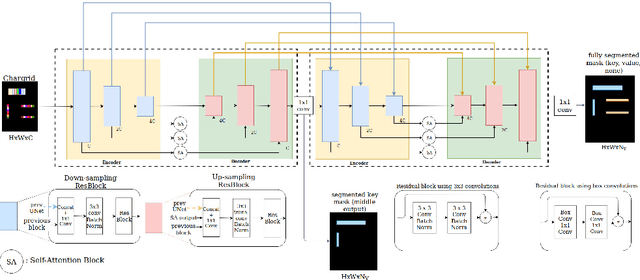

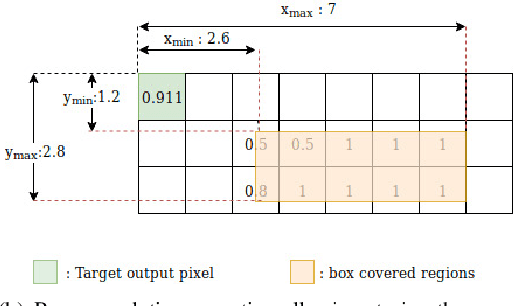
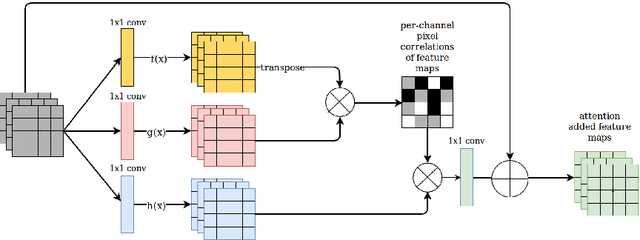
Information extraction from document images has received a lot of attention recently, due to the need for digitizing a large volume of unstructured documents such as invoices, receipts, bank transfers, etc. In this paper, we propose a novel deep learning architecture for end-to-end information extraction on the 2D character-grid embedding of the document, namely the \textit{Multi-Stage Attentional U-Net}. To effectively capture the textual and spatial relations between 2D elements, our model leverages a specialized multi-stage encoder-decoders design, in conjunction with efficient uses of the self-attention mechanism and the box convolution. Experimental results on different datasets show that our model outperforms the baseline U-Net architecture by a large margin while using 40\% fewer parameters. Moreover, it also significantly improved the baseline in erroneous OCR and limited training data scenario, thus becomes practical for real-world applications.
* Accepted to BMVC 2019