 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sublinear-Time Clustering Oracle for Signed Graphs
Jun 28, 2022
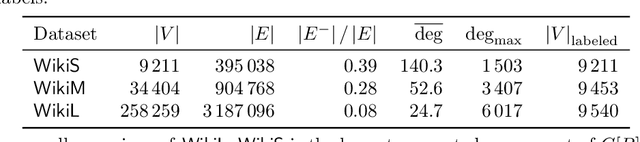
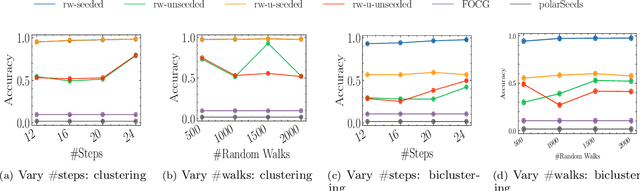
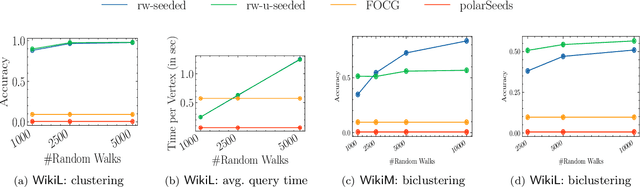
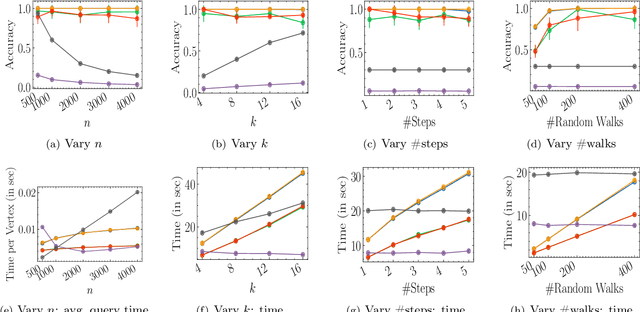
Social networks are often modeled using signed graphs, where vertices correspond to users and edges have a sign that indicates whether an interaction between users was positive or negative. The arising signed graphs typically contain a clear community structure in the sense that the graph can be partitioned into a small number of polarized communities, each defining a sparse cut and indivisible into smaller polarized sub-communities. We provide a local clustering oracle for signed graphs with such a clear community structure, that can answer membership queries, i.e., "Given a vertex $v$, which community does $v$ belong to?", in sublinear time by reading only a small portion of the graph. Formally, when the graph has bounded maximum degree and the number of communities is at most $O(\log n)$, then with $\tilde{O}(\sqrt{n}\operatorname{poly}(1/\varepsilon))$ preprocessing time, our oracle can answer each membership query in $\tilde{O}(\sqrt{n}\operatorname{poly}(1/\varepsilon))$ time, and it correctly classifies a $(1-\varepsilon)$-fraction of vertices w.r.t. a set of hidden planted ground-truth communities. Our oracle is desirable in applications where the clustering information is needed for only a small number of vertices. Previously, such local clustering oracles were only known for unsigned graphs; our generalization to signed graphs requires a number of new ideas and gives a novel spectral analysis of the behavior of random walks with signs. We evaluate our algorithm for constructing such an oracle and answering membership queries on both synthetic and real-world datasets, validating its performance in practice.
DreamNet: A Deep Riemannian Network based on SPD Manifold Learning for Visual Classification
Jun 16, 2022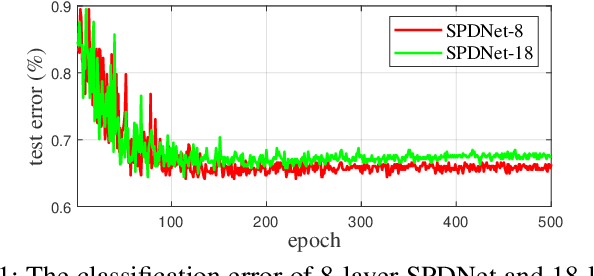
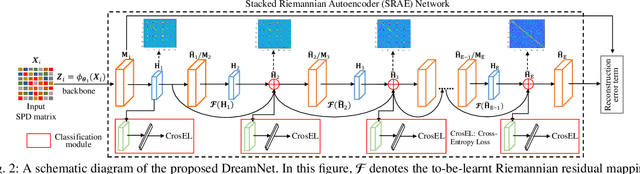
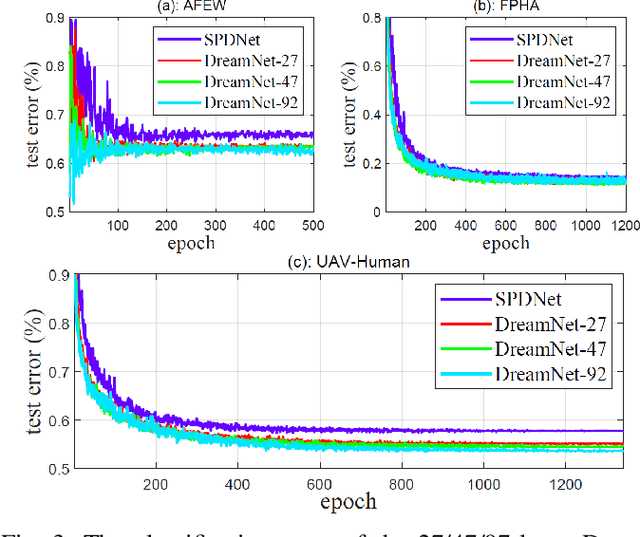
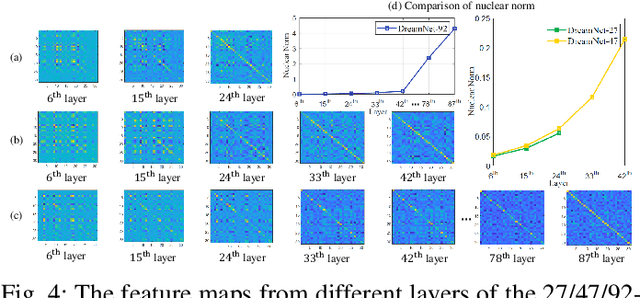
Image set-based visual classification methods have achieved remarkable performance, via characterising the image set in terms of a non-singular covariance matrix on a symmetric positive definite (SPD) manifold. To adapt to complicated visual scenarios better, several Riemannian networks (RiemNets) for SPD matrix nonlinear processing have recently been studied. However, it is pertinent to ask, whether greater accuracy gains can be achieved by simply increasing the depth of RiemNets. The answer appears to be negative, as deeper RiemNets tend to lose generalization ability. To explore a possible solution to this issue, we propose a new architecture for SPD matrix learning. Specifically, to enrich the deep representations, we adopt SPDNet [1] as the backbone, with a stacked Riemannian autoencoder (SRAE) built on the tail. The associated reconstruction error term can make the embedding functions of both SRAE and of each RAE an approximate identity mapping, which helps to prevent the degradation of statistical information. We then insert several residual-like blocks with shortcut connections to augment the representational capacity of SRAE, and to simplify the training of a deeper network. The experimental evidence demonstrates that our DreamNet can achieve improved accuracy with increased depth of the network.
Apport des ontologies pour le calcul de la similarité sémantique au sein d'un système de recommandation
May 25, 2022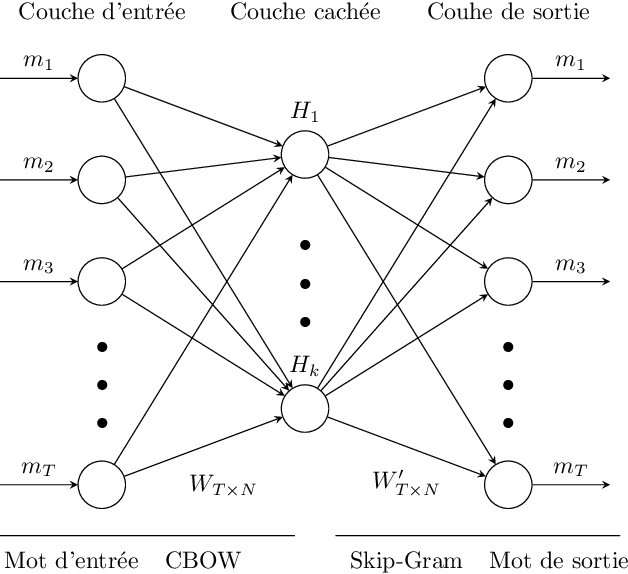
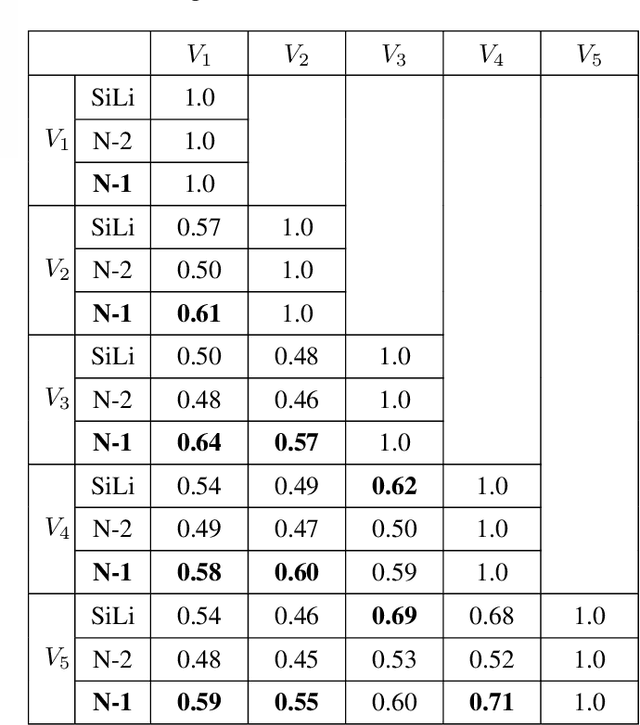
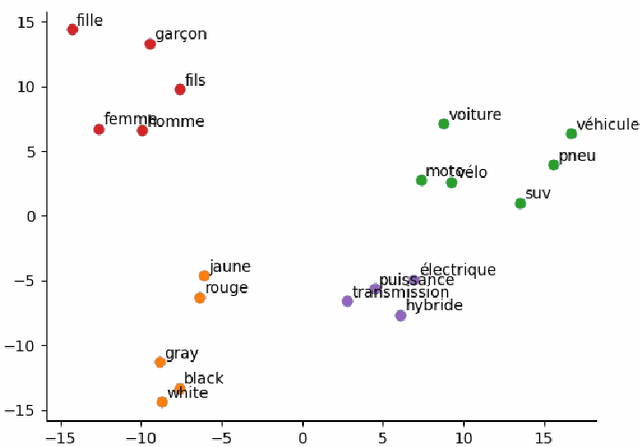
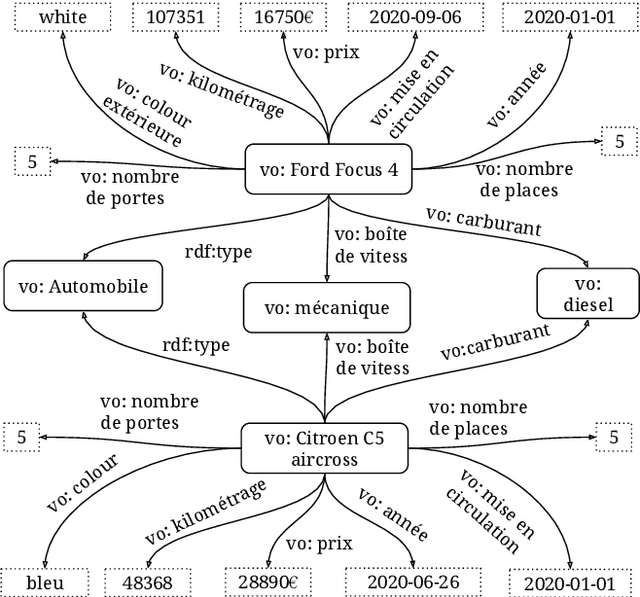
Measurement of the semantic relatedness or likeness between terms, words, or text data plays an important role in different applications dealing with textual data such as knowledge acquisition, recommender system, and natural language processing. Over the past few years, many ontologies have been developed and used as a form of structured representation of knowledge bases for information systems. The calculation of semantic similarity from ontology has developed and depending on the context is complemented by other similarity calculation methods. In this paper, we propose and carry on an approach for the calculation of ontology-based semantic similarity using in the context of a recommender system.
Continuous Sign Language Recognition via Temporal Super-Resolution Network
Jul 03, 2022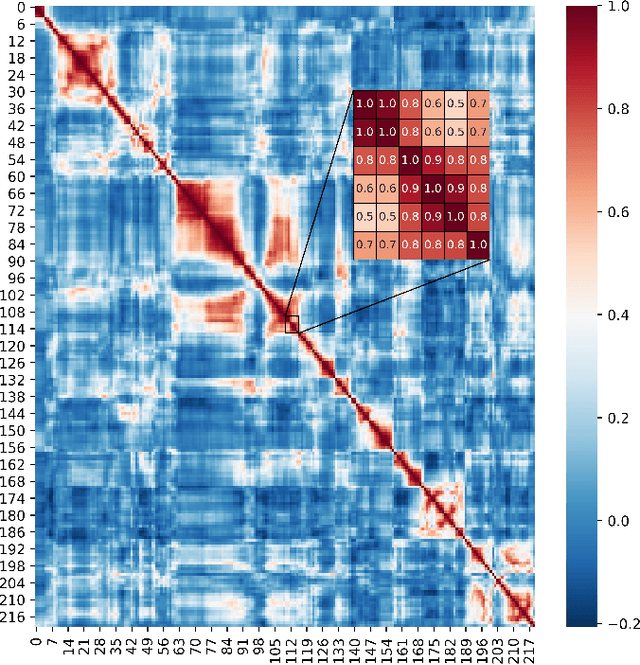
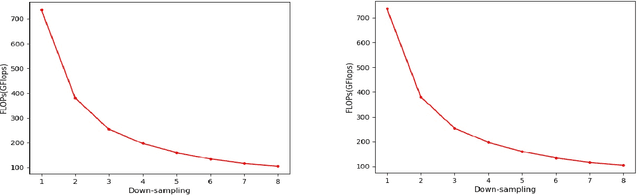
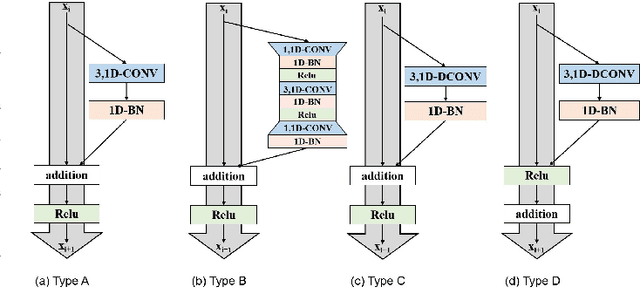
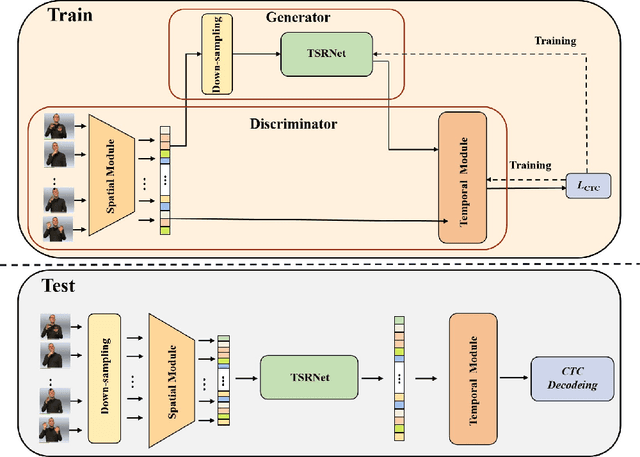
Aiming at the problem that the spatial-temporal hierarchical continuous sign language recognition model based on deep learning has a large amount of computation, which limits the real-time application of the model, this paper proposes a temporal super-resolution network(TSRNet). The data is reconstructed into a dense feature sequence to reduce the overall model computation while keeping the final recognition accuracy loss to a minimum. The continuous sign language recognition model(CSLR) via TSRNet mainly consists of three parts: frame-level feature extraction, time series feature extraction and TSRNet, where TSRNet is located between frame-level feature extraction and time-series feature extraction, which mainly includes two branches: detail descriptor and rough descriptor. The sparse frame-level features are fused through the features obtained by the two designed branches as the reconstructed dense frame-level feature sequence, and the connectionist temporal classification(CTC) loss is used for training and optimization after the time-series feature extraction part. To better recover semantic-level information, the overall model is trained with the self-generating adversarial training method proposed in this paper to reduce the model error rate. The training method regards the TSRNet as the generator, and the frame-level processing part and the temporal processing part as the discriminator. In addition, in order to unify the evaluation criteria of model accuracy loss under different benchmarks, this paper proposes word error rate deviation(WERD), which takes the error rate between the estimated word error rate (WER) and the reference WER obtained by the reconstructed frame-level feature sequence and the complete original frame-level feature sequence as the WERD. Experiments on two large-scale sign language datasets demonstrate the effectiveness of the proposed model.
Predictive Rate Selection for Ultra-Reliable Communication using Statistical Radio Maps
May 30, 2022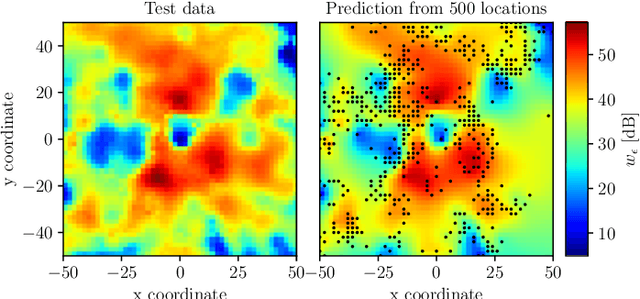
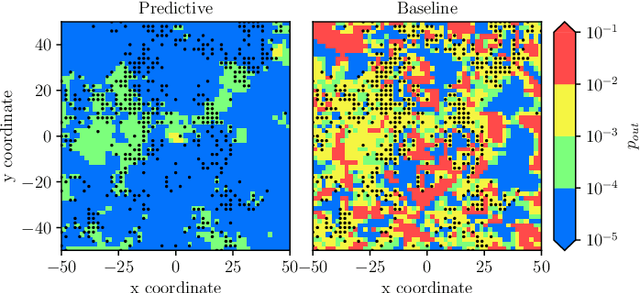
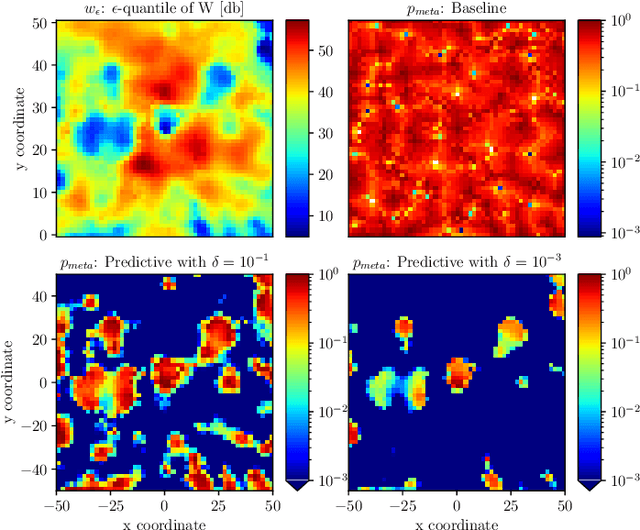
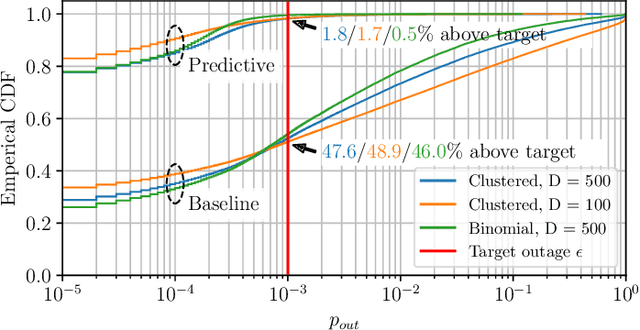
This paper proposes exploiting the spatial correlation of wireless channel statistics beyond the conventional received signal strength maps by constructing statistical radio maps to predict any relevant channel statistics to assist communications. Specifically, from stored channel samples acquired by previous users in the network, we use Gaussian processes (GPs) to estimate quantiles of the channel distribution at a new position using a non-parametric model. This prior information is then used to select the transmission rate for some target level of reliability. The approach is tested with synthetic data, simulated from urban micro-cell environments, highlighting how the proposed solution helps to reduce the training estimation phase, which is especially attractive for the tight latency constraints inherent to ultra-reliable low-latency (URLLC) deployments.
Comprehensive Study: How the Context Information of Different Granularity Affects Dialogue State Tracking?
May 31, 2021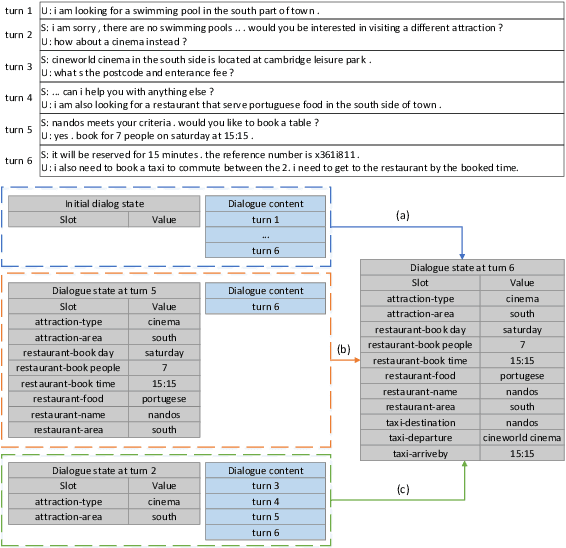
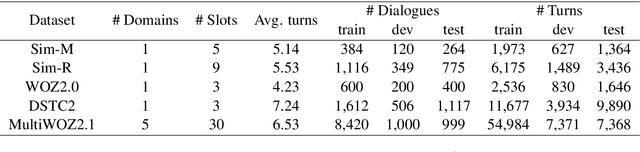

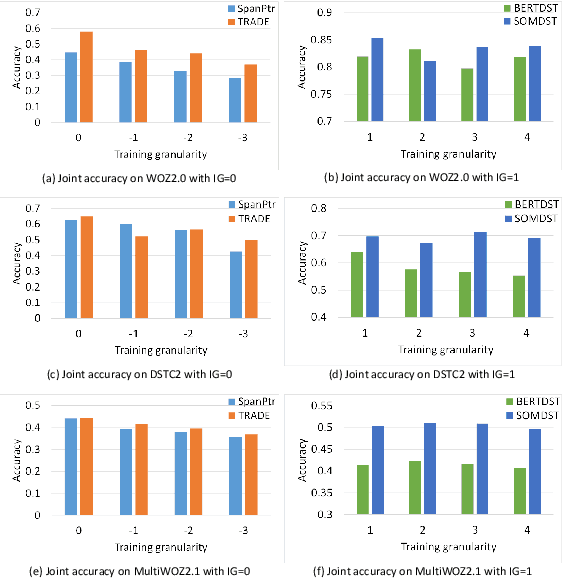
Dialogue state tracking (DST) plays a key role in task-oriented dialogue systems to monitor the user's goal. In general, there are two strategies to track a dialogue state: predicting it from scratch and updating it from previous state. The scratch-based strategy obtains each slot value by inquiring all the dialogue history, and the previous-based strategy relies on the current turn dialogue to update the previous dialogue state. However, it is hard for the scratch-based strategy to correctly track short-dependency dialogue state because of noise; meanwhile, the previous-based strategy is not very useful for long-dependency dialogue state tracking. Obviously, it plays different roles for the context information of different granularity to track different kinds of dialogue states. Thus, in this paper, we will study and discuss how the context information of different granularity affects dialogue state tracking. First, we explore how greatly different granularities affect dialogue state tracking. Then, we further discuss how to combine multiple granularities for dialogue state tracking. Finally, we apply the findings about context granularity to few-shot learning scenario. Besides, we have publicly released all codes.
Low Altitude 3-D Coverage Performance Analysis in Cell-Free Distributed Collaborative Massive MIMO Systems
Jun 28, 2022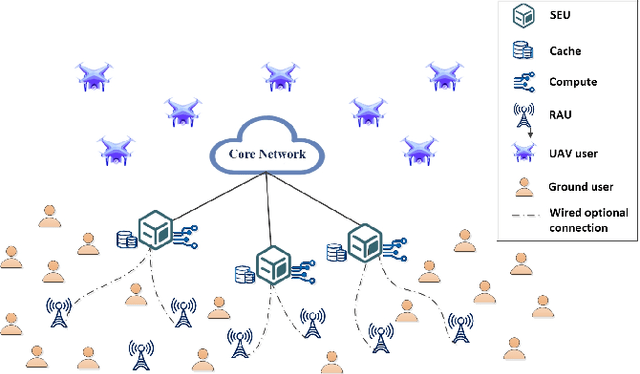
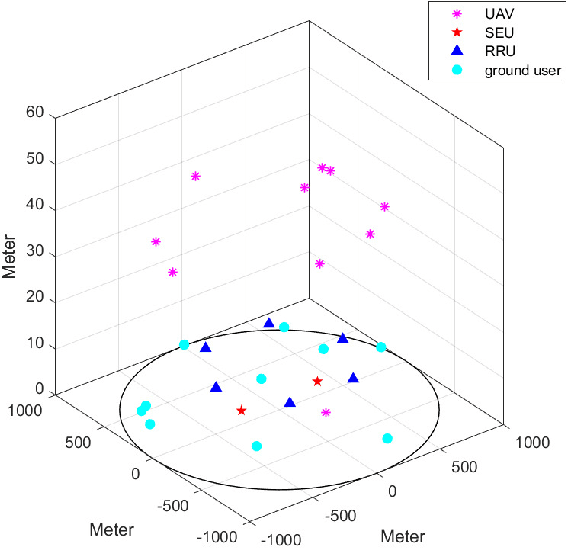
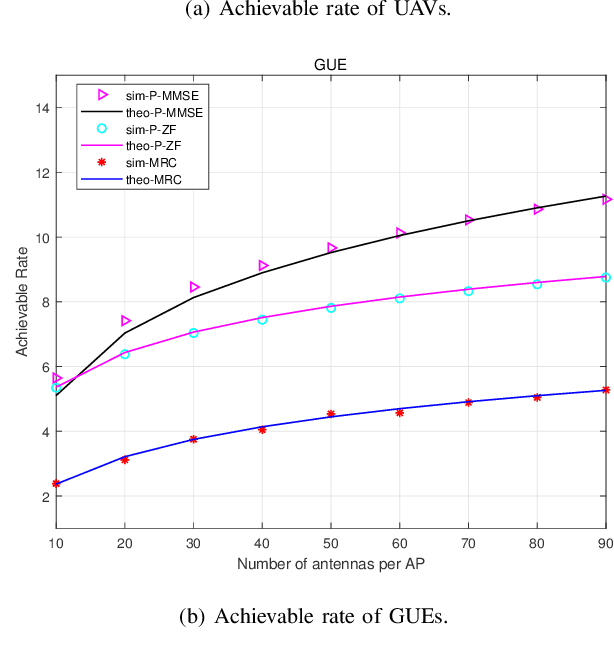
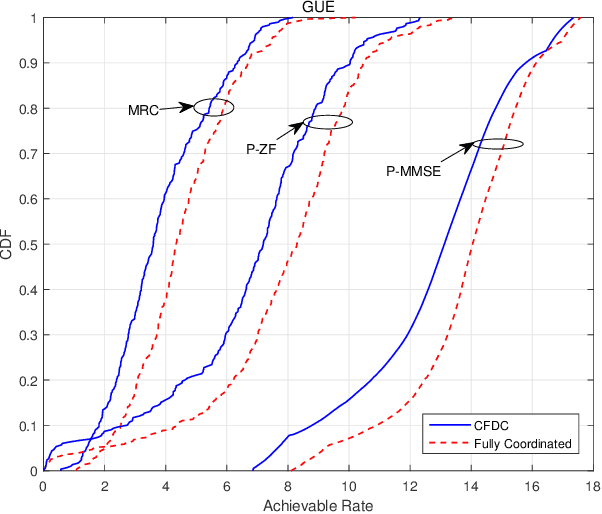
To improve the poor performance of distributed operation and non-scalability of centralized operation in traditional cell-free massive MIMO, we propose a cell-free distributed collaborative (CFDC) massive multiple-input multiple-output (MIMO) system based on a novel two-layer model to take advantages of the distributed cloud-edge-end collaborative architecture in beyond 5G (B5G) internet of things (IoT) environment to provide strong flexibility and scalability. We further ultilize the proposed CFDC massive MIMO system to support the low altitude three-dimensional (3-D) coverage scenario with unmanned aerial vehicles (UAVs), while accounting for 3-D Rician channel estimation, user-centric association and different scalable receiving schemes. Since coexisted UAVs and ground users (GUEs) cause greater interference, we ultilize user-centric association strategy and minimum-mean-square error (MMSE) channel state information (CSI) estimation to obtain the estimated CSI of UAVs and GUEs. Under the CFDC scenarios, scalable receiving schemes as maximum ratio combing (MRC), partial zero-forcing (P-ZF) and partial minimum-mean-square error (P-MMSE) can be performed at edge servers and the closed-form expressions for uplink spectral efficiency (SE) are derived. Based on the derived expressions, we propose an efficient power control algorithm by solving a multi-objective optimization problem (MOOP) between maximizing the average SE of UAVs and GUEs simultaneously with Deep Q-Network (DQN). Numerical results verify the accuracy of the derived closed-form expressions and the effectiveness of the coexisted UAVs and GUEs transmission scheme in CFDC massive MIMO systems. The SE analysis under various system parameters offers numerous flexibilities for system optimization.
Self-Supervised Video Representation Learning with Motion-Contrastive Perception
Apr 10, 2022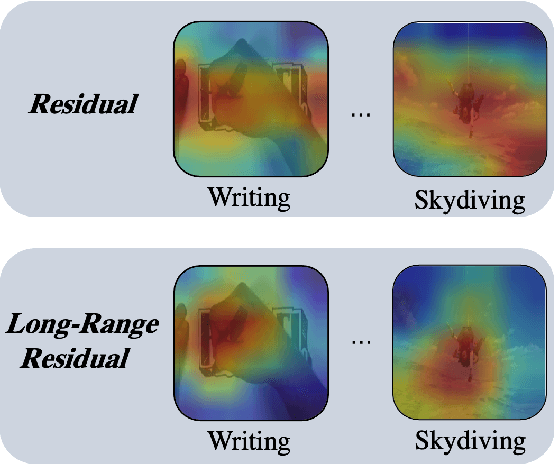
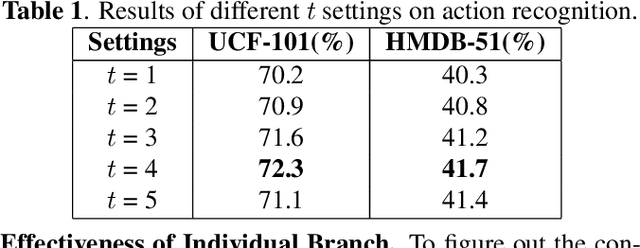
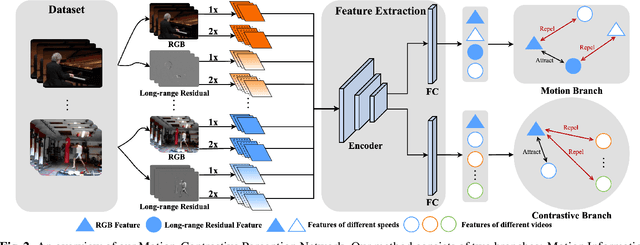

Visual-only self-supervised learning has achieved significant improvement in video representation learning. Existing related methods encourage models to learn video representations by utilizing contrastive learning or designing specific pretext tasks. However, some models are likely to focus on the background, which is unimportant for learning video representations. To alleviate this problem, we propose a new view called long-range residual frame to obtain more motion-specific information. Based on this, we propose the Motion-Contrastive Perception Network (MCPNet), which consists of two branches, namely, Motion Information Perception (MIP) and Contrastive Instance Perception (CIP), to learn generic video representations by focusing on the changing areas in videos. Specifically, the MIP branch aims to learn fine-grained motion features, and the CIP branch performs contrastive learning to learn overall semantics information for each instance. Experiments on two benchmark datasets UCF-101 and HMDB-51 show that our method outperforms current state-of-the-art visual-only self-supervised approaches.
0/1 Deep Neural Networks via Block Coordinate Descent
Jun 19, 2022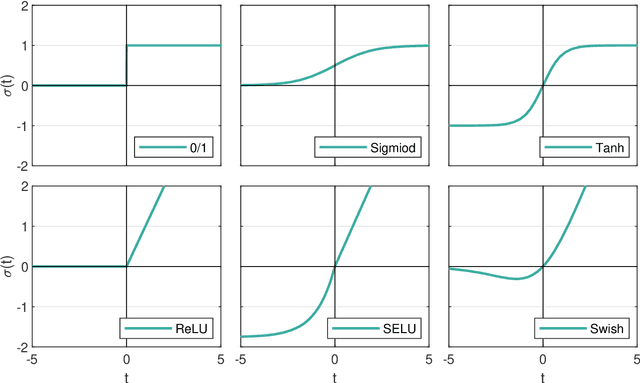
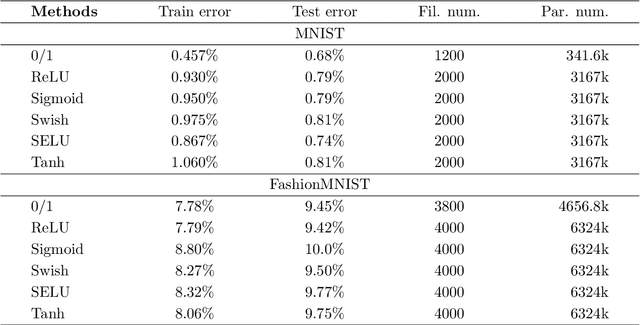
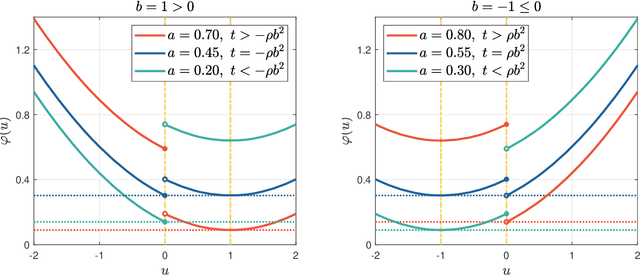
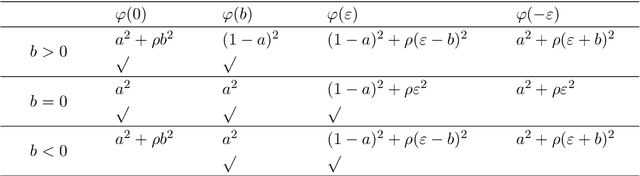
The step function is one of the simplest and most natural activation functions for deep neural networks (DNNs). As it counts 1 for positive variables and 0 for others, its intrinsic characteristics (e.g., discontinuity and no viable information of subgradients) impede its development for several decades. Even if there is an impressive body of work on designing DNNs with continuous activation functions that can be deemed as surrogates of the step function, it is still in the possession of some advantageous properties, such as complete robustness to outliers and being capable of attaining the best learning-theoretic guarantee of predictive accuracy. Hence, in this paper, we aim to train DNNs with the step function used as an activation function (dubbed as 0/1 DNNs). We first reformulate 0/1 DNNs as an unconstrained optimization problem and then solve it by a block coordinate descend (BCD) method. Moreover, we acquire closed-form solutions for sub-problems of BCD as well as its convergence properties. Furthermore, we also integrate $\ell_{2,0}$-regularization into 0/1 DNN to accelerate the training process and compress the network scale. As a result, the proposed algorithm has a high performance on classifying MNIST and Fashion-MNIST datasets.
Graph-based Spatial Transformer with Memory Replay for Multi-future Pedestrian Trajectory Prediction
Jun 12, 2022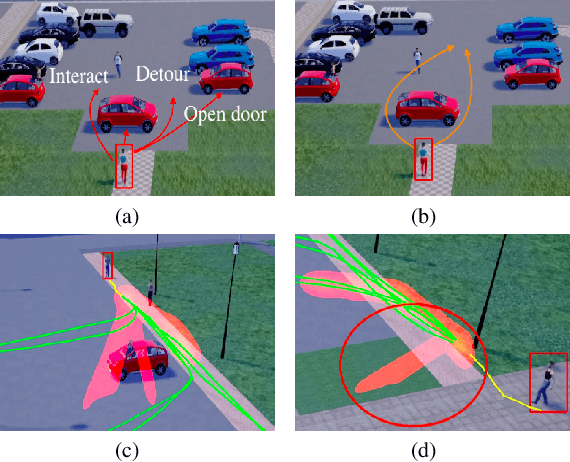
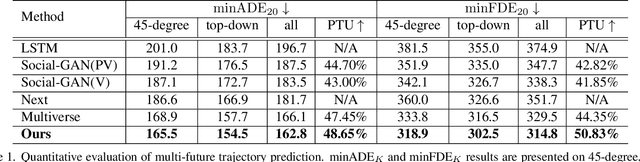
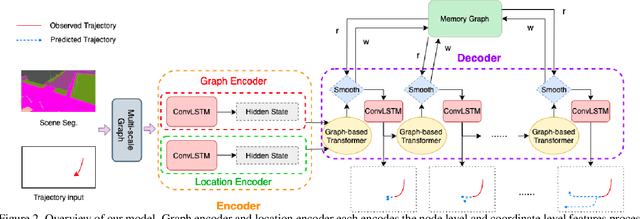
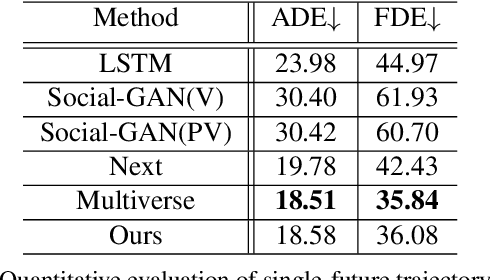
Pedestrian trajectory prediction is an essential and challenging task for a variety of real-life applications such as autonomous driving and robotic motion planning. Besides generating a single future path, predicting multiple plausible future paths is becoming popular in some recent work on trajectory prediction. However, existing methods typically emphasize spatial interactions between pedestrians and surrounding areas but ignore the smoothness and temporal consistency of predictions. Our model aims to forecast multiple paths based on a historical trajectory by modeling multi-scale graph-based spatial transformers combined with a trajectory smoothing algorithm named ``Memory Replay'' utilizing a memory graph. Our method can comprehensively exploit the spatial information as well as correct the temporally inconsistent trajectories (e.g., sharp turns). We also propose a new evaluation metric named ``Percentage of Trajectory Usage'' to evaluate the comprehensiveness of diverse multi-future predictions. Our extensive experiments show that the proposed model achieves state-of-the-art performance on multi-future prediction and competitive results for single-future prediction. Code released at https://github.com/Jacobieee/ST-MR.