 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMo: Geometry-Aware Setup-Agnostic Modeling of Human Motion in the Wild
May 21, 2026As wearable and mobile devices become increasingly embedded in daily life, they offer a practical way to continuously sense human motion in the wild. But inertial signals are highly dependent on the sensing setup, including body location, mounting position, sensor orientation, device hardware, and sampling protocol. This setup dependence makes it difficult to learn motion representations that transfer across devices and datasets, and limits the broader use of wearable IMUs beyond closed-set recognition. We introduce AnyMo, a geometry-aware framework for setup-agnostic human motion modeling. AnyMo uses physics-grounded IMU simulation over dense body-surface placements to generate diverse and plausible synthetic signals, pre-trains a graph encoder from paired synthetic placement views and masked partial observations, tokenizes multi-position IMU into full-body motion tokens, and aligns these tokens with an LLM for motion-language understanding. We evaluate AnyMo on three complementary tasks: zero-shot activity recognition across 14 unseen downstream datasets, cross-modal retrieval, and wearable IMU motion captioning, where it improves average Accuracy/F1/R@2 by 11.7\%/11.6\%/22.6\% on HAR, increases zero-shot IMU-to-text and text-to-IMU retrieval MRR by 15.9\% and 28.6\%, respectively, and improves zero-shot captioning BERT-F1 by 18.8\%. These results support AnyMo as a generalist model for wearable motion understanding in the wild. Project page: https://baiyuchen.com/project/AnyMo.
GHGbench: A Unified Multi-Entity, Multi-Task Benchmark for Carbon Emission Prediction
May 13, 2026Open datasets and benchmarks for entity-level carbon-emission prediction remain fragmented across access, scale, granularity, and evaluation. We introduce GHGbench, an open dataset and benchmark for company- and building-level greenhouse-gas prediction. The company track contains 32,000+ company-year records from 12,000+ firms with Scope 1+2 and Scope 3 disclosures and financial/sectoral signals; the building track harmonises 491,591 building-year records from 13 open sources into a single schema across 26 metropolitan areas (10 U.S., 15 Australian, 1 Singaporean), with climate covariates and multimodal remote-sensing embeddings. GHGbench defines canonical splits with in-distribution and cross-region/city transfer as primary tasks and temporal hold-out plus short-horizon forecasting as supplementary appendix evidence; headline baselines span gradient-boosted trees, a tabular foundation model, MLP, FT-Transformer, and multimodal fusion, with an LLM panel as auxiliary, all evaluated under multi-seed paired-bootstrap tests. Three benchmark-level findings emerge: (i) building emissions are structurally harder than company emissions; (ii) the in-distribution to out-of-distribution gap dwarfs any within-model gap across both the company track and the building track, and a tabular foundation model is, to our knowledge, the first baseline to open a paired-bootstrap-significant gap over tuned trees on a multi-city building-emissions task; (iii) multimodal remote-sensing embeddings help precisely where tabular generalisation breaks. GHGbench also exposes catastrophic city transfer and the sector-factor lookup ceiling as systematic failure modes. Code and reconstruction recipes are available at GHGbench.
TrajPrism: A Multi-Task Benchmark for Language-Grounded Urban Trajectory Understanding
May 11, 2026Urban mobility is naturally expressed both as trajectories in space and as natural-language descriptions of travel intent, constraints, and preferences. However, prior work rarely evaluates these two modalities together on the same real-world trajectories: trajectory modeling often stays geometry-centric, while language-centric mobility benchmarks frequently target route planning and tool use rather than fine-grained, verifiable alignment between text and the underlying route. We introduce TrajPrism, a multi-task benchmark for language-trajectory alignment that unifies (i) instruction-conditioned trajectory generation, (ii) language-driven semantic trajectory retrieval, and (iii) trajectory captioning, together with an evaluation protocol that measures trajectory fidelity, retrieval quality, and language groundedness. We construct TrajPrism by pairing real urban trajectories with judge-filtered language annotations generated under a four-dimensional travel-intent taxonomy. The benchmark contains 300K selected trajectories across Porto, San Francisco, and Beijing, yielding 2.1M task instances from three instruction variants, three retrieval queries, and one caption per trajectory. We further develop proof-of-concept models for each task: TrajAnchor for instruction-conditioned trajectory generation, TrajFuse for semantic trajectory retrieval, and TrajRap for trajectory captioning. These models instantiate the proposed tasks and show that geometry-only trajectory baselines leave a large gap on our protocol, especially where language is part of the input-output interface. We release TrajPrism with code and a reproducible annotation pipeline that is designed to be portable across cities, given compatible trajectory inputs and map resources.
TrajDLM: Topology-Aware Block Diffusion Language Model for Trajectory Generation
May 11, 2026Generating high-fidelity synthetic GPS trajectories is increasingly important for applications in transportation, urban planning, and what-if scenario simulation, especially as privacy concerns limit access to real-world mobility data. Existing trajectory generation models face a trade-off between efficiency and faithfulness to road network topology: continuous-space methods enable fast generation but ignore the road network, while topology-aware approaches rely on search-based autoregressive decoding that limits generation speed. We propose TrajDLM, a topology-aware trajectory generation framework based on block diffusion language models that bridges this gap. TrajDLM models trajectories as sequences of discrete road segments, combining a block diffusion backbone for efficient denoising, topology-aware embeddings from a road network encoder, and topology-constrained sampling to ensure coherent and realistic trajectories. Across three city-scale datasets, TrajDLM achieves strong performance on fine-grained local similarity metrics while being up to $2.8\times$ faster than prior work, and demonstrates strong zero-shot transfer across domains, including unseen transportation modes. These results highlight the effectiveness of block-wise discrete diffusion as a scalable approach to accurate and efficient trajectory generation. Our code is available at https://github.com/cruiseresearchgroup/TrajDLM/
Route by State, Recover from Trace: STAR with Failure-Aware Markov Routing for Multi-Agent Spatiotemporal Reasoning
May 11, 2026Compositional spatiotemporal reasoning often requires a system to invoke multiple heterogeneous specialists, such as geometric, temporal, topological, and trajectory agents. A central question is how such a system should route among specialists when execution does not simply succeed or fail, but fails in qualitatively different ways. Existing tool-augmented and multi-agent LLM systems typically leave this routing decision implicit in language generation, making recovery ad hoc, difficult to interpret, and hard to optimize. This paper presents STAR (Spatio-Temporal Agent Router), a failure-aware routing framework that externalizes inter-agent control as a state-conditioned transition policy over the current agent, task type, and typed execution status. At the center of STARis an agent routing matrix that combines expert-specified nominal routes with recovery transitions learned from execution traces. Because the matrix conditions on distinct failure states, the router can respond differently to malformed outputs, missing dependencies, and tool--query mismatches, rather than collapsing them into a generic retry signal. Specialists execute through a tool-grounded extract--compute--deposit protocol and write intermediate results to a shared blackboard for downstream fusion. Results prove that retaining unsuccessful traces during training enlarges the support of the routing policy on error states, enabling recovery transitions that success-only training cannot represent. Across three spatiotemporal benchmarks and eight backbone LLMs, STAR improves over multiple baselines with the clearest gains on queries whose execution deviates from the nominal routing path. Router-specific ablations and recovery analyses further show that typed failure-aware routing, rather than specialist composition alone, is a key factor for these improvements.
Optimizing Electric Vehicle Charging Station Locations: A Data-driven System with Multi-source Fusion
Apr 18, 2025



With the growing electric vehicles (EVs) charging demand, urban planners face the challenges of providing charging infrastructure at optimal locations. For example, range anxiety during long-distance travel and the inadequate distribution of residential charging stations are the major issues many cities face. To achieve reasonable estimation and deployment of the charging demand, we develop a data-driven system based on existing EV trips in New South Wales (NSW) state, Australia, incorporating multiple factors that enhance the geographical feasibility of recommended charging stations. Our system integrates data sources including EV trip data, geographical data such as route data and Local Government Area (LGA) boundaries, as well as features like fire and flood risks, and Points of Interest (POIs). We visualize our results to intuitively demonstrate the findings from our data-driven, multi-source fusion system, and evaluate them through case studies. The outcome of this work can provide a platform for discussion to develop new insights that could be used to give guidance on where to position future EV charging stations.
T-JEPA: A Joint-Embedding Predictive Architecture for Trajectory Similarity Computation
Jun 13, 2024Trajectory similarity computation is an essential technique for analyzing moving patterns of spatial data across various applications such as traffic management, wildlife tracking, and location-based services. Modern methods often apply deep learning techniques to approximate heuristic metrics but struggle to learn more robust and generalized representations from the vast amounts of unlabeled trajectory data. Recent approaches focus on self-supervised learning methods such as contrastive learning, which have made significant advancements in trajectory representation learning. However, contrastive learning-based methods heavily depend on manually pre-defined data augmentation schemes, limiting the diversity of generated trajectories and resulting in learning from such variations in 2D Euclidean space, which prevents capturing high-level semantic variations. To address these limitations, we propose T-JEPA, a self-supervised trajectory similarity computation method employing Joint-Embedding Predictive Architecture (JEPA) to enhance trajectory representation learning. T-JEPA samples and predicts trajectory information in representation space, enabling the model to infer the missing components of trajectories at high-level semantics without relying on domain knowledge or manual effort. Extensive experiments conducted on three urban trajectory datasets and two Foursquare datasets demonstrate the effectiveness of T-JEPA in trajectory similarity computation.
Graph-based Spatial Transformer with Memory Replay for Multi-future Pedestrian Trajectory Prediction
Jun 12, 2022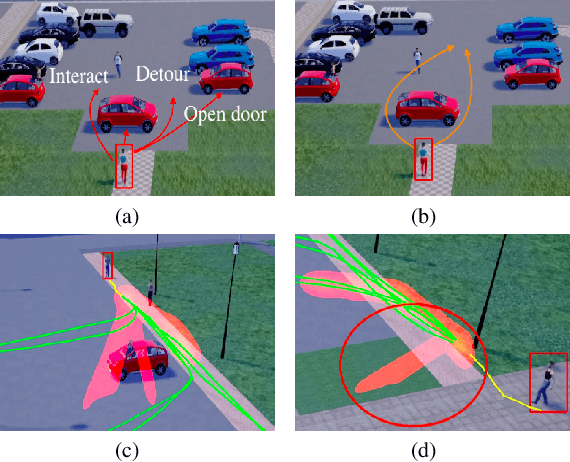
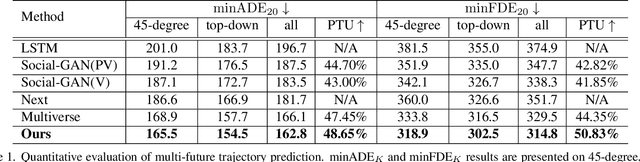
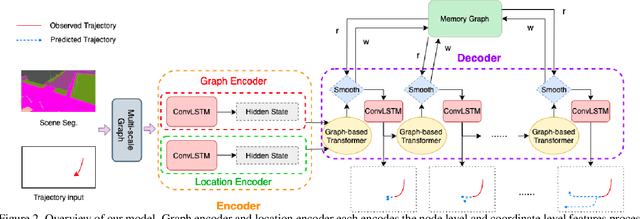
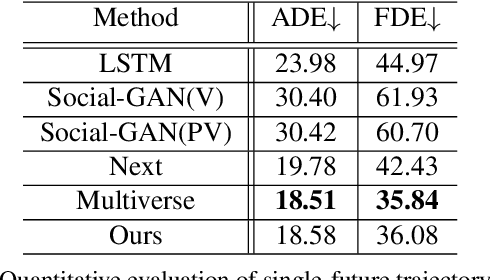
Pedestrian trajectory prediction is an essential and challenging task for a variety of real-life applications such as autonomous driving and robotic motion planning. Besides generating a single future path, predicting multiple plausible future paths is becoming popular in some recent work on trajectory prediction. However, existing methods typically emphasize spatial interactions between pedestrians and surrounding areas but ignore the smoothness and temporal consistency of predictions. Our model aims to forecast multiple paths based on a historical trajectory by modeling multi-scale graph-based spatial transformers combined with a trajectory smoothing algorithm named ``Memory Replay'' utilizing a memory graph. Our method can comprehensively exploit the spatial information as well as correct the temporally inconsistent trajectories (e.g., sharp turns). We also propose a new evaluation metric named ``Percentage of Trajectory Usage'' to evaluate the comprehensiveness of diverse multi-future predictions. Our extensive experiments show that the proposed model achieves state-of-the-art performance on multi-future prediction and competitive results for single-future prediction. Code released at https://github.com/Jacobieee/ST-MR.