 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Voxel-informed Language Grounding
May 19, 2022
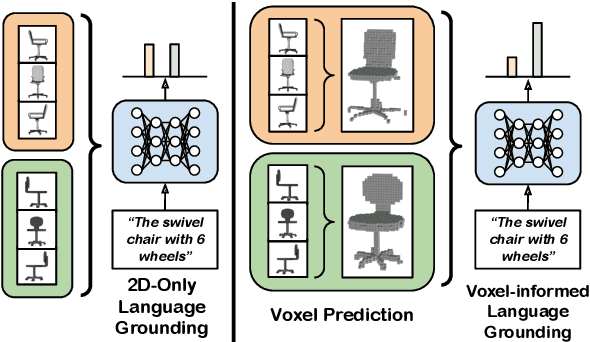
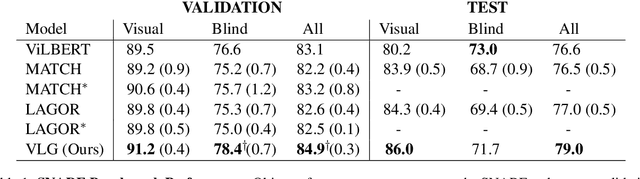
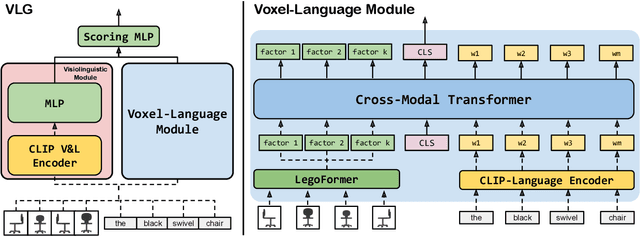
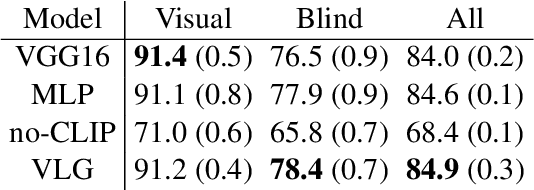
Natural language applied to natural 2D images describes a fundamentally 3D world. We present the Voxel-informed Language Grounder (VLG), a language grounding model that leverages 3D geometric information in the form of voxel maps derived from the visual input using a volumetric reconstruction model. We show that VLG significantly improves grounding accuracy on SNARE, an object reference game task. At the time of writing, VLG holds the top place on the SNARE leaderboard, achieving SOTA results with a 2.0% absolute improvement.
Analyzing the behaviour of D'WAVE quantum annealer: fine-tuning parameterization and tests with restrictive Hamiltonian formulations
Jul 01, 2022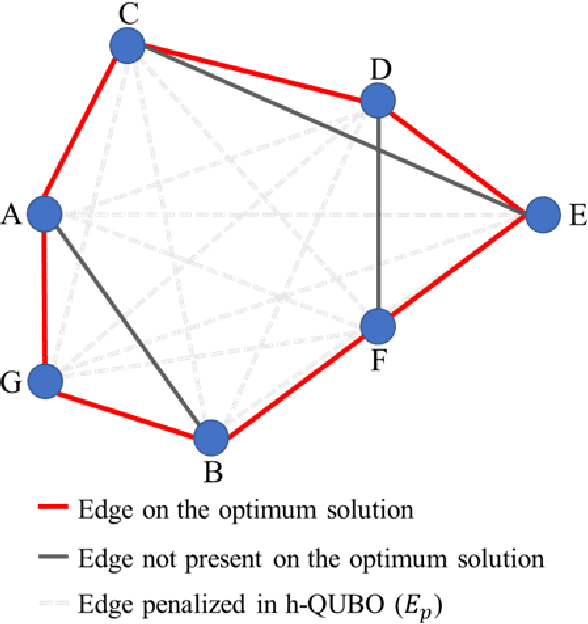
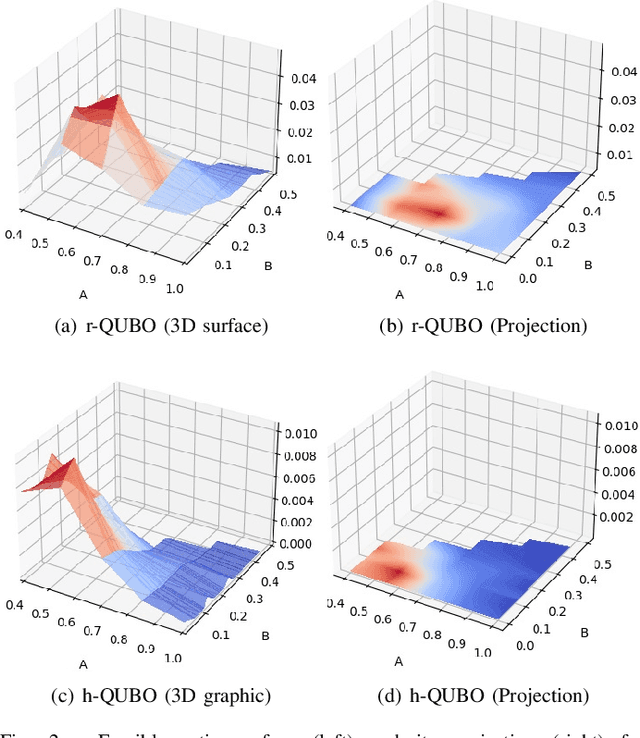
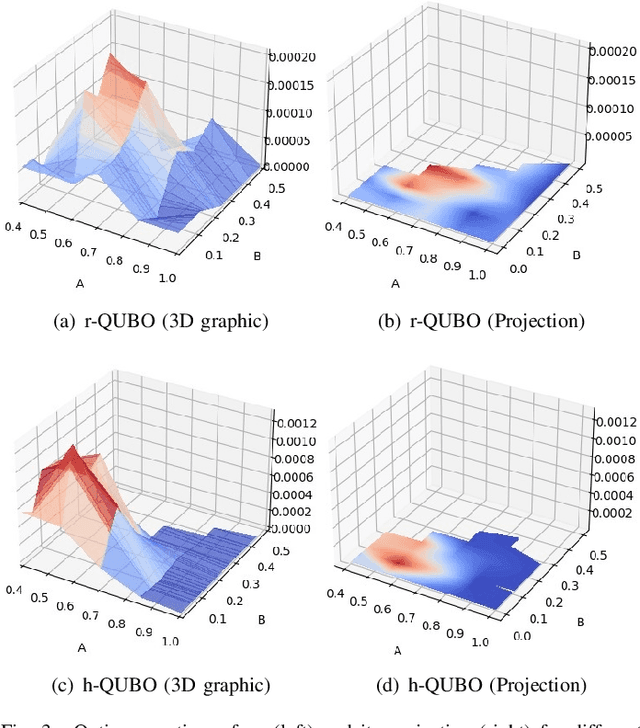
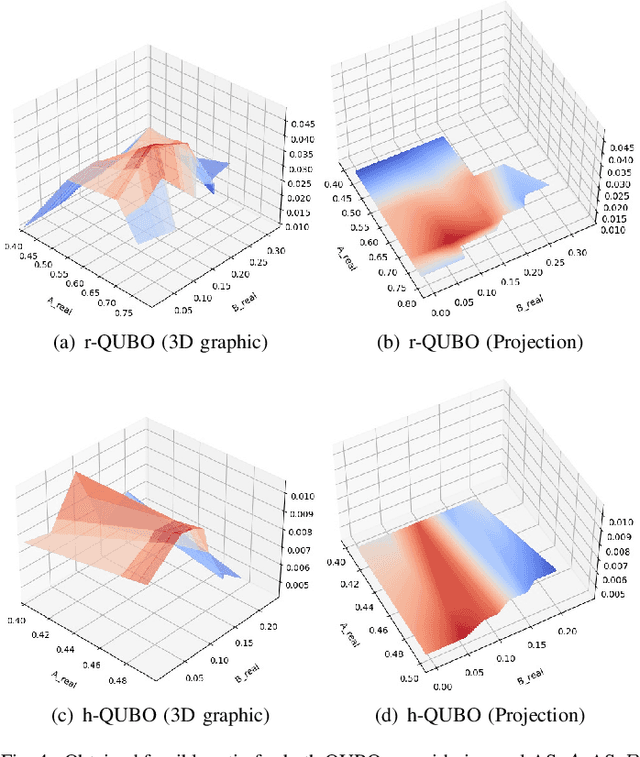
Despite being considered as the next frontier in computation, Quantum Computing is still in an early stage of development. Indeed, current commercial quantum computers suffer from some critical restraints, such as noisy processes and a limited amount of qubits, among others, that affect the performance of quantum algorithms. Despite these limitations, researchers have devoted much effort to propose different frameworks for efficiently using these Noisy Intermediate-Scale Quantum (NISQ) devices. One of these procedures is D'WAVE Systems' quantum-annealer, which can be use to solve optimization problems by translating them into an energy minimization problem. In this context, this work is focused on providing useful insights and information into the behaviour of the quantum-annealer when addressing real-world combinatorial optimization problems. Our main motivation with this study is to open some quantum computing frontiers to non-expert stakeholders. To this end, we perform an extensive experimentation, in the form of a parameter sensitive analysis. This experimentation has been conducted using the Traveling Salesman Problem as benchmarking problem, and adopting two QUBOs: state-of-the-art and a heuristically generated. Our analysis has been performed on a single 7-noded instance, and it is based on more than 200 different parameter configurations, comprising more than 3700 unitary runs and 7 million of quantum reads. Thanks to this study, findings related to the energy distribution and most appropriate parameter settings have been obtained. Finally, an additional study has been performed, aiming to determine the efficiency of the heuristically built QUBO in further TSP instances.
Are Quantum Computers Practical Yet? A Case for Feature Selection in Recommender Systems using Tensor Networks
May 12, 2022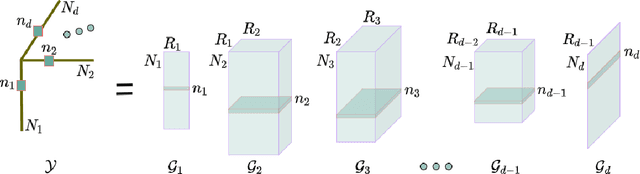
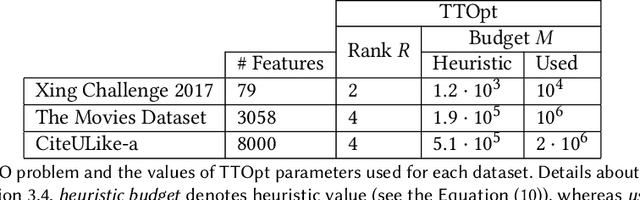
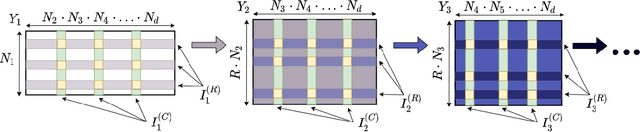
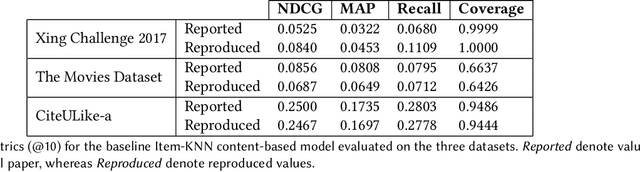
Collaborative filtering models generally perform better than content-based filtering models and do not require careful feature engineering. However, in the cold-start scenario collaborative information may be scarce or even unavailable, whereas the content information may be abundant, but also noisy and expensive to acquire. Thus, selection of particular features that improve cold-start recommendations becomes an important and non-trivial task. In the recent approach by Nembrini et al., the feature selection is driven by the correlational compatibility between collaborative and content-based models. The problem is formulated as a Quadratic Unconstrained Binary Optimization (QUBO) which, due to its NP-hard complexity, is solved using Quantum Annealing on a quantum computer provided by D-Wave. Inspired by the reported results, we contend the idea that current quantum annealers are superior for this problem and instead focus on classical algorithms. In particular, we tackle QUBO via TTOpt, a recently proposed black-box optimizer based on tensor networks and multilinear algebra. We show the computational feasibility of this method for large problems with thousands of features, and empirically demonstrate that the solutions found are comparable to the ones obtained with D-Wave across all examined datasets.
Hierarchical Context Tagging for Utterance Rewriting
Jun 22, 2022
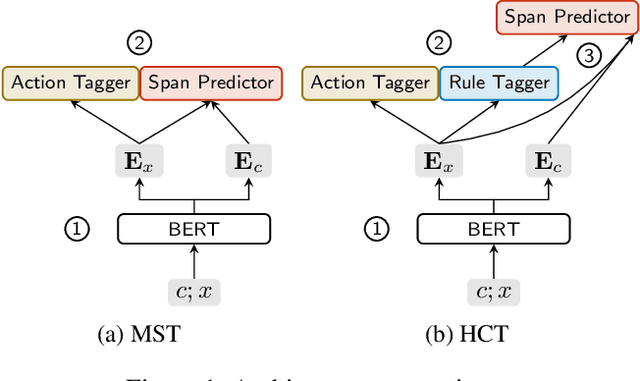

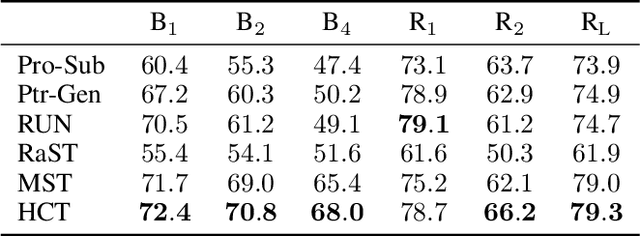
Utterance rewriting aims to recover coreferences and omitted information from the latest turn of a multi-turn dialogue. Recently, methods that tag rather than linearly generate sequences have proven stronger in both in- and out-of-domain rewriting settings. This is due to a tagger's smaller search space as it can only copy tokens from the dialogue context. However, these methods may suffer from low coverage when phrases that must be added to a source utterance cannot be covered by a single context span. This can occur in languages like English that introduce tokens such as prepositions into the rewrite for grammaticality. We propose a hierarchical context tagger (HCT) that mitigates this issue by predicting slotted rules (e.g., "besides _") whose slots are later filled with context spans. HCT (i) tags the source string with token-level edit actions and slotted rules and (ii) fills in the resulting rule slots with spans from the dialogue context. This rule tagging allows HCT to add out-of-context tokens and multiple spans at once; we further cluster the rules to truncate the long tail of the rule distribution. Experiments on several benchmarks show that HCT can outperform state-of-the-art rewriting systems by ~2 BLEU points.
Continual Learning with Transformers for Image Classification
Jun 28, 2022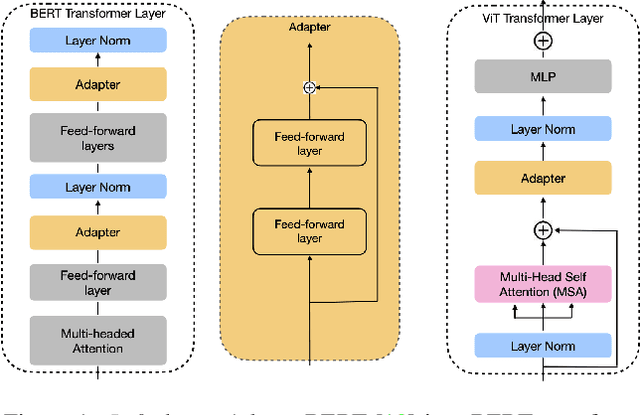
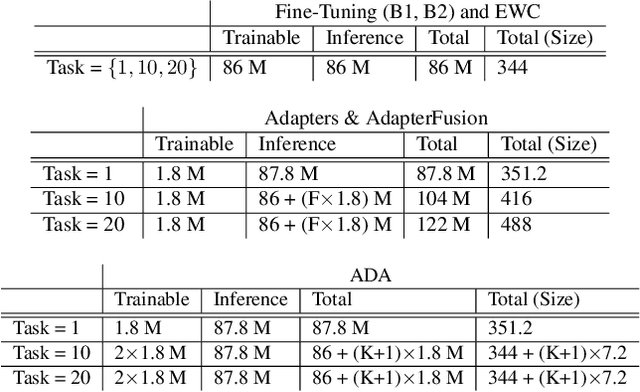
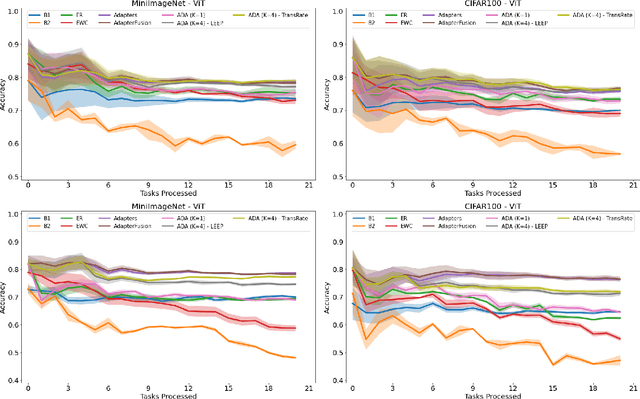
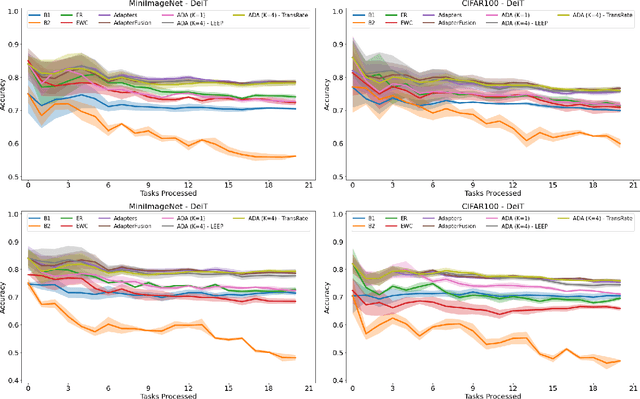
In many real-world scenarios, data to train machine learning models become available over time. However, neural network models struggle to continually learn new concepts without forgetting what has been learnt in the past. This phenomenon is known as catastrophic forgetting and it is often difficult to prevent due to practical constraints, such as the amount of data that can be stored or the limited computation sources that can be used. Moreover, training large neural networks, such as Transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. A recent trend indicates that dynamic architectures based on an expansion of the parameters can reduce catastrophic forgetting efficiently in continual learning, but this needs complex tuning to balance the growing number of parameters and barely share any information across tasks. As a result, they struggle to scale to a large number of tasks without significant overhead. In this paper, we validate in the computer vision domain a recent solution called Adaptive Distillation of Adapters (ADA), which is developed to perform continual learning using pre-trained Transformers and Adapters on text classification tasks. We empirically demonstrate on different classification tasks that this method maintains a good predictive performance without retraining the model or increasing the number of model parameters over the time. Besides it is significantly faster at inference time compared to the state-of-the-art methods.
Open-domain question classification and completion in conversational information search
Feb 26, 2021Searching for new information requires talking to the system. In this research, an Open-domain Conversational information search system has been developed. This system has been implemented using the TREC CAsT 2019 track, which is one of the first attempts to build a framework in this area. According to the user's previous questions, the system firstly completes the question (using the first and the previous question in each turn) and then classifies it (based on the question words). This system extracts the related answers according to the rules of each question. In this research, a simple yet effective method with high performance has been used, which on average, extracts 20% more relevant results than the baseline.
On the probability-quality paradox in language generation
Mar 31, 2022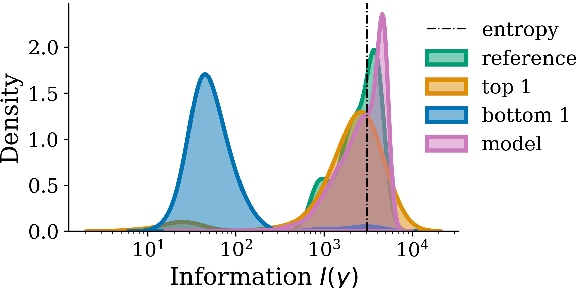
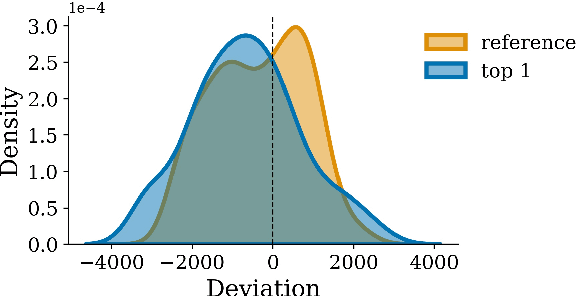
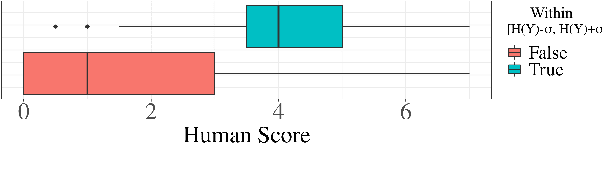
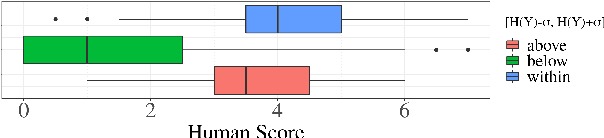
When generating natural language from neural probabilistic models, high probability does not always coincide with high quality: It has often been observed that mode-seeking decoding methods, i.e., those that produce high-probability text under the model, lead to unnatural language. On the other hand, the lower-probability text generated by stochastic methods is perceived as more human-like. In this note, we offer an explanation for this phenomenon by analyzing language generation through an information-theoretic lens. Specifically, we posit that human-like language should contain an amount of information (quantified as negative log-probability) that is close to the entropy of the distribution over natural strings. Further, we posit that language with substantially more (or less) information is undesirable. We provide preliminary empirical evidence in favor of this hypothesis; quality ratings of both human and machine-generated text -- covering multiple tasks and common decoding strategies -- suggest high-quality text has an information content significantly closer to the entropy than we would expect by chance.
Learnable Frequency Filters for Speech Feature Extraction in Speaker Verification
Jun 15, 2022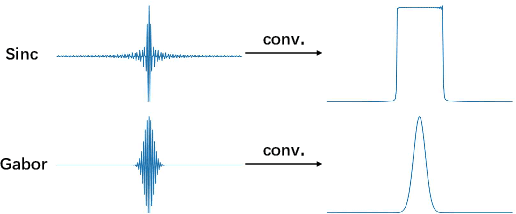
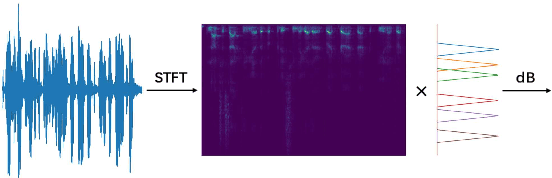
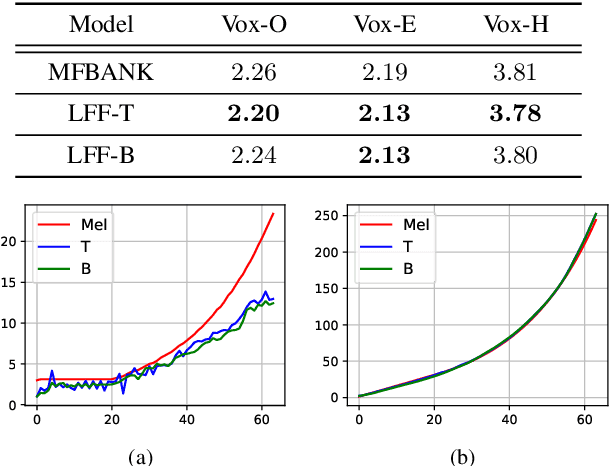
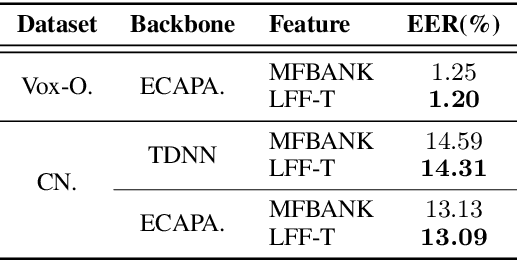
Mel-scale spectrum features are used in various recognition and classification tasks on speech signals. There is no reason to expect that these features are optimal for all different tasks, including speaker verification (SV). This paper describes a learnable front-end feature extraction model. The model comprises a group of filters to transform the Fourier spectrum. Model parameters that define these filters are trained end-to-end and optimized specifically for the task of speaker verification. Compared to the standard Mel-scale filter-bank, the filters' bandwidths and center frequencies are adjustable. Experimental results show that applying the learnable acoustic front-end improves speaker verification performance over conventional Mel-scale spectrum features. Analysis on the learned filter parameters suggests that narrow-band information benefits the SV system performance. The proposed model achieves a good balance between performance and computation cost. In resource-constrained computation settings, the model significantly outperforms CNN-based learnable front-ends. The generalization ability of the proposed model is also demonstrated on different embedding extraction models and datasets.
Generic and Trend-aware Curriculum Learning for Relation Extraction in Graph Neural Networks
May 17, 2022
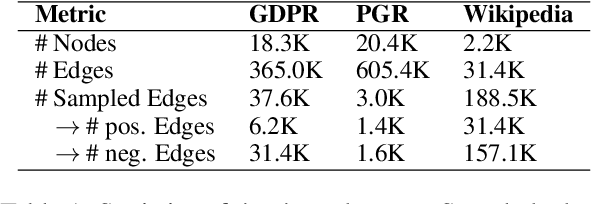
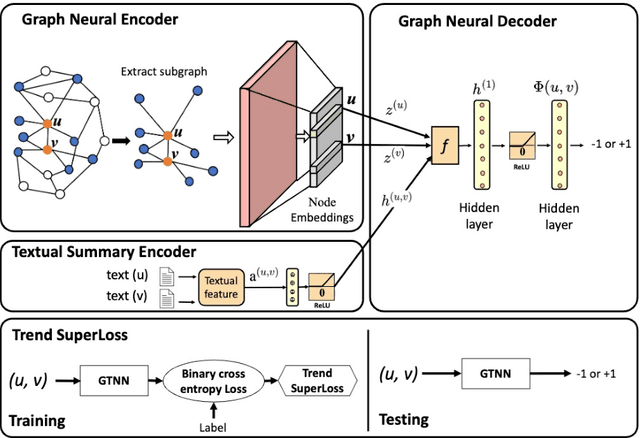
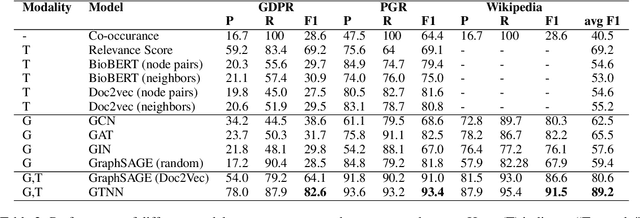
We present a generic and trend-aware curriculum learning approach for graph neural networks. It extends existing approaches by incorporating sample-level loss trends to better discriminate easier from harder samples and schedule them for training. The model effectively integrates textual and structural information for relation extraction in text graphs. Experimental results show that the model provides robust estimations of sample difficulty and shows sizable improvement over the state-of-the-art approaches across several datasets.
Connecting a French Dictionary from the Beginning of the 20th Century to Wikidata
Jun 22, 2022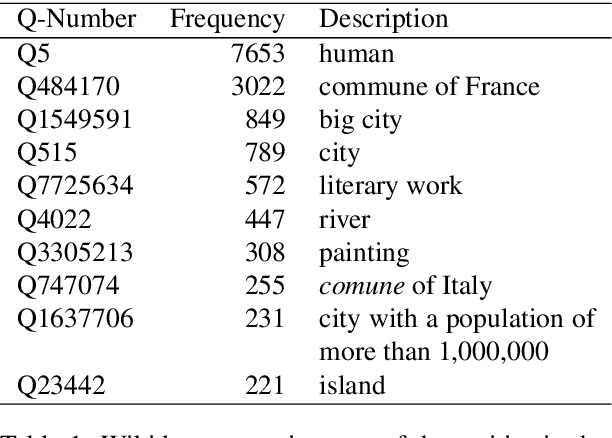
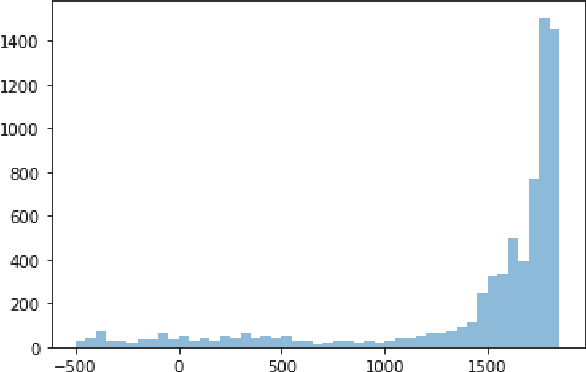
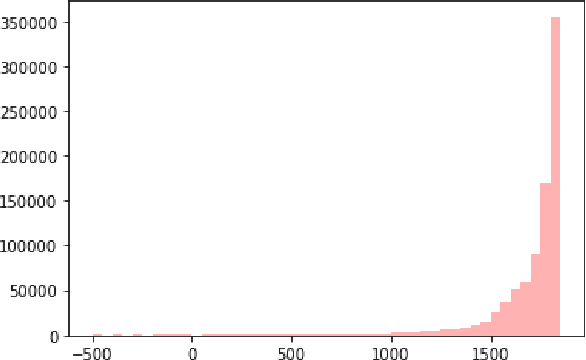
The \textit{Petit Larousse illustr\'e} is a French dictionary first published in 1905. Its division in two main parts on language and on history and geography corresponds to a major milestone in French lexicography as well as a repository of general knowledge from this period. Although the value of many entries from 1905 remains intact, some descriptions now have a dimension that is more historical than contemporary. They are nonetheless significant to analyze and understand cultural representations from this time. A comparison with more recent information or a verification of these entries would require a tedious manual work. In this paper, we describe a new lexical resource, where we connected all the dictionary entries of the history and geography part to current data sources. For this, we linked each of these entries to a wikidata identifier. Using the wikidata links, we can automate more easily the identification, comparison, and verification of historically-situated representations. We give a few examples on how to process wikidata identifiers and we carried out a small analysis of the entities described in the dictionary to outline possible applications. The resource, i.e. the annotation of 20,245 dictionary entries with wikidata links, is available from GitHub (\url{https://github.com/pnugues/petit_larousse_1905/})