 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explainable Graph Theory-Based Identification of Meter-Transformer Mapping
May 19, 2022
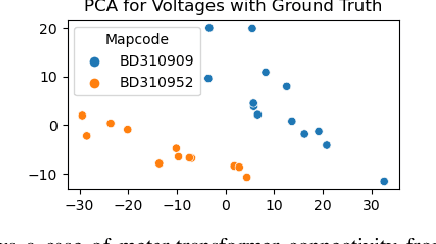

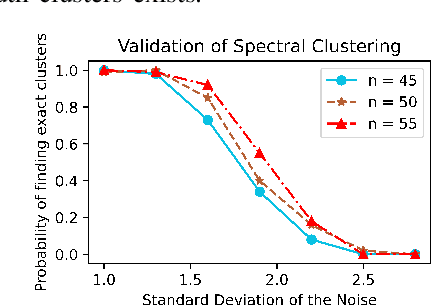
Distributed energy resources are better for the environment but may cause transformer overload in distribution grids, calling for recovering meter-transformer mapping to provide situational awareness, i.e., the transformer loading. The challenge lies in recovering meter-transformer (M.T.) mapping for two common scenarios, e.g., large distances between a meter and its parent transformer or high similarity of a meter's consumption pattern to a non-parent transformer's meters. Past methods either assume a variety of data as in the transmission grid or ignore the two common scenarios mentioned above. Therefore, we propose to utilize the above observation via spectral embedding by using the property that inter-transformer meter consumptions are not the same and that the noise in data is limited so that all the k smallest eigenvalues of the voltage-based Laplacian matrix are smaller than the next smallest eigenvalue of the ideal Laplacian matrix. We also provide a guarantee based on this understanding. Furthermore, we partially relax the assumption by utilizing location information to aid voltage information for areas geographically far away but with similar voltages. Numerical simulations on the IEEE test systems and real feeders from our partner utility show that the proposed method correctly identifies M.T. mapping.
Improve Discourse Dependency Parsing with Contextualized Representations
May 04, 2022
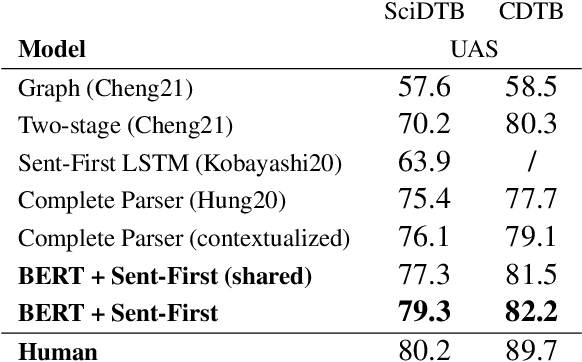
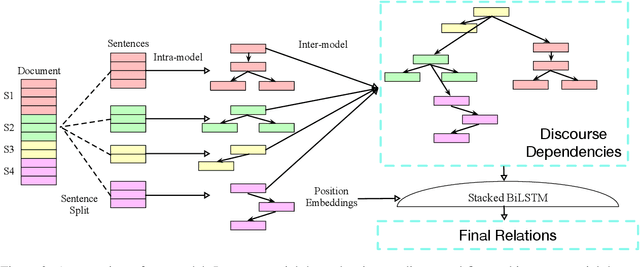
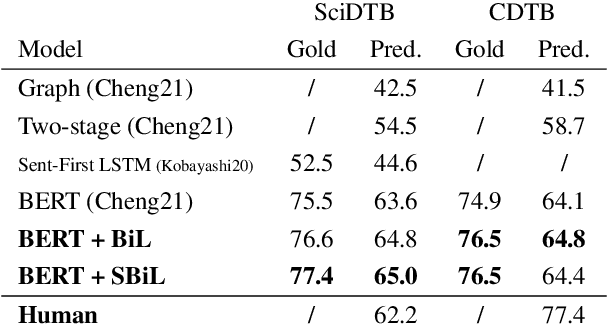
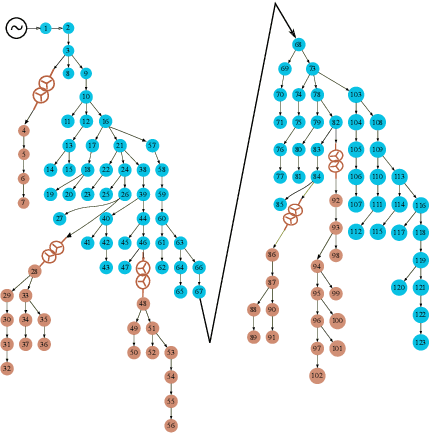
Recent works show that discourse analysis benefits from modeling intra- and inter-sentential levels separately, where proper representations for text units of different granularities are desired to capture both the meaning of text units and their relations to the context. In this paper, we propose to take advantage of transformers to encode contextualized representations of units of different levels to dynamically capture the information required for discourse dependency analysis on intra- and inter-sentential levels. Motivated by the observation of writing patterns commonly shared across articles, we propose a novel method that treats discourse relation identification as a sequence labelling task, which takes advantage of structural information from the context of extracted discourse trees, and substantially outperforms traditional direct-classification methods. Experiments show that our model achieves state-of-the-art results on both English and Chinese datasets.
Write It Like You See It: Detectable Differences in Clinical Notes By Race Lead To Differential Model Recommendations
May 08, 2022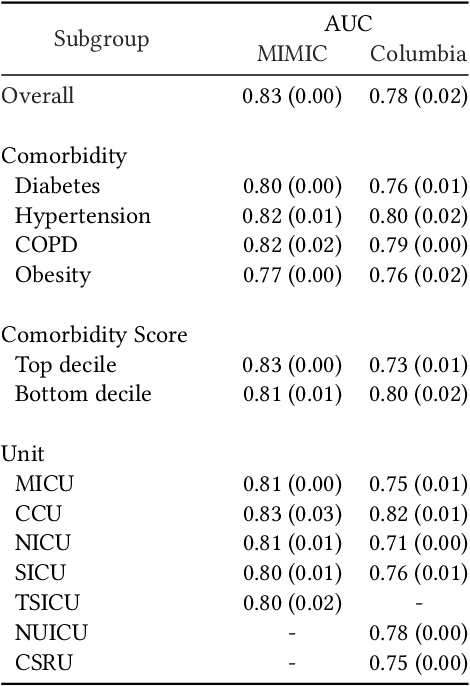
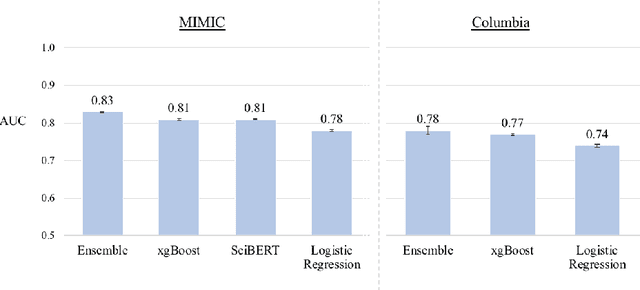


Clinical notes are becoming an increasingly important data source for machine learning (ML) applications in healthcare. Prior research has shown that deploying ML models can perpetuate existing biases against racial minorities, as bias can be implicitly embedded in data. In this study, we investigate the level of implicit race information available to ML models and human experts and the implications of model-detectable differences in clinical notes. Our work makes three key contributions. First, we find that models can identify patient self-reported race from clinical notes even when the notes are stripped of explicit indicators of race. Second, we determine that human experts are not able to accurately predict patient race from the same redacted clinical notes. Finally, we demonstrate the potential harm of this implicit information in a simulation study, and show that models trained on these race-redacted clinical notes can still perpetuate existing biases in clinical treatment decisions.
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021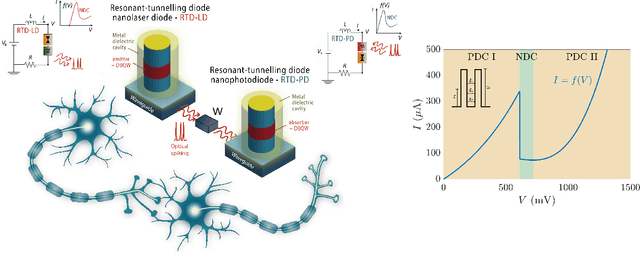
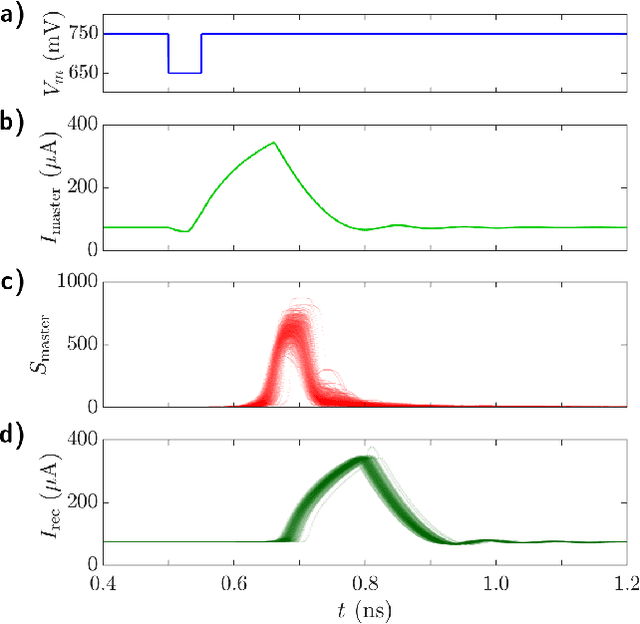
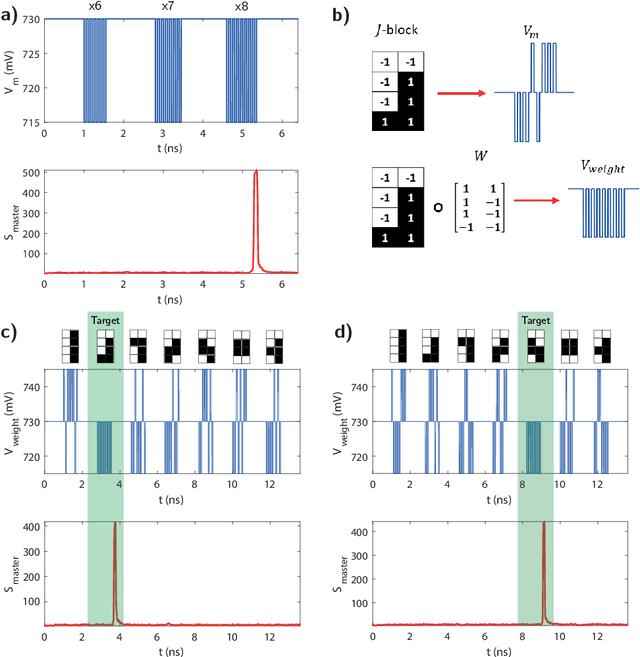
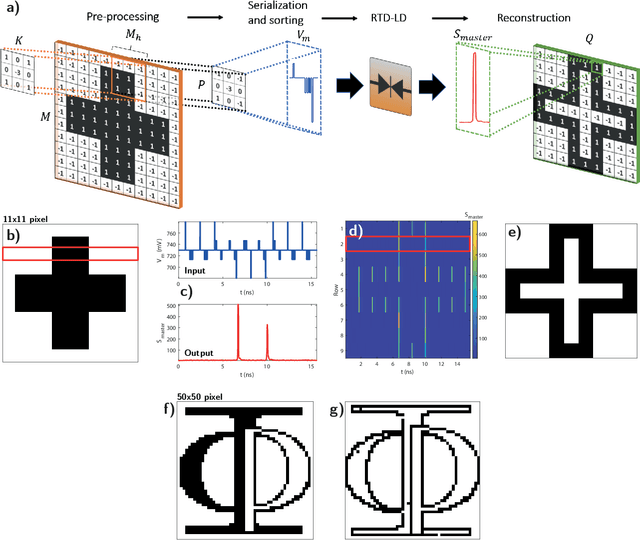
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
Sequential- and Parallel- Constrained Max-value Entropy Search via Information Lower Bound
Feb 19, 2021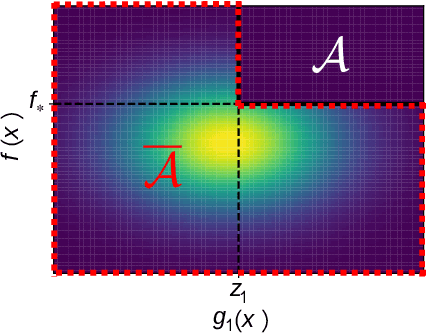
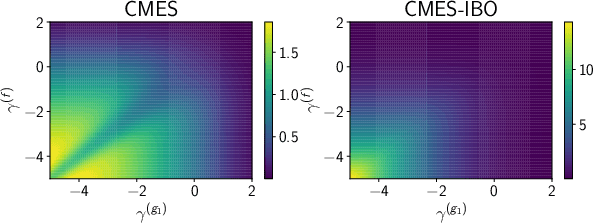
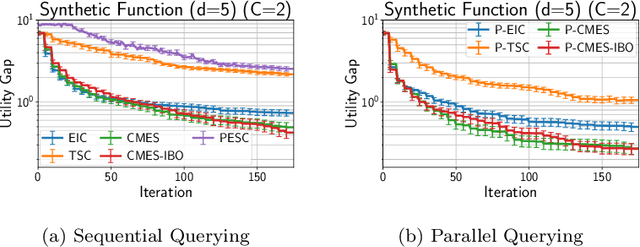
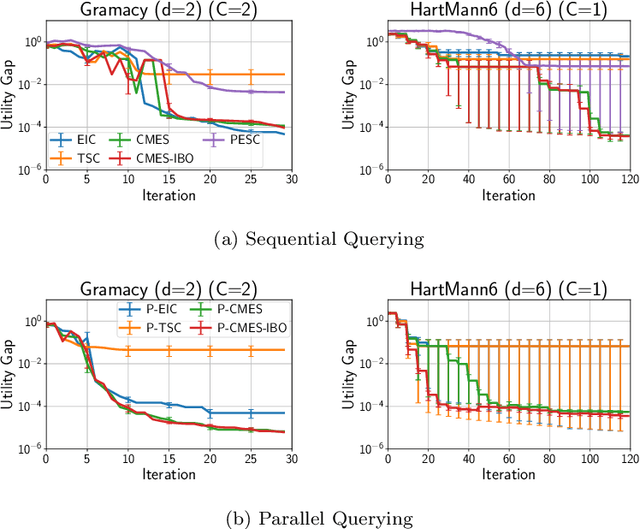
Recently, several Bayesian optimization (BO) methods have been extended to the expensive black-box optimization problem with unknown constraints, which is an important problem that appears frequently in practice. We focus on an information-theoretic approach called Max-value Entropy Search (MES) whose superior performance has been repeatedly shown in BO literature. Since existing MES-based constrained BO is restricted to only one constraint, we first extend it to multiple constraints, but we found that this approach can cause negative approximate values for the mutual information, which can result in unreasonable decisions. In this paper, we employ a different approximation strategy that is based on a lower bound of the mutual information, and propose a novel constrained BO method called Constrained Max-value Entropy Search via Information lower BOund (CMES-IBO). Our approximate mutual information derived from the lower bound has a simple closed-form that is guaranteed to be nonnegative, and we show that irrational behavior caused by the negative value can be avoided. Furthermore, by using conditional mutual information, we extend our methods to the parallel setting in which multiple queries can be issued simultaneously. Finally, we demonstrate the effectiveness of our proposed methods by benchmark functions and real-world applications to materials science.
A Large Scale Search Dataset for Unbiased Learning to Rank
Jul 07, 2022
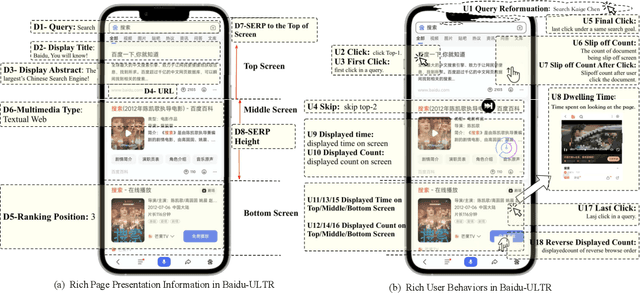
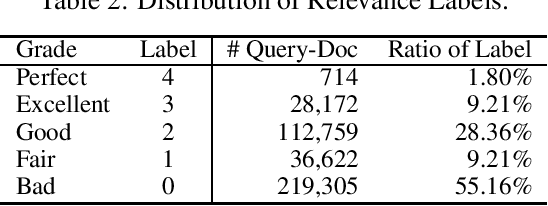
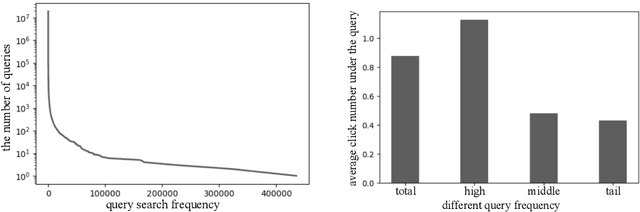
The unbiased learning to rank (ULTR) problem has been greatly advanced by recent deep learning techniques and well-designed debias algorithms. However, promising results on the existing benchmark datasets may not be extended to the practical scenario due to the following disadvantages observed from those popular benchmark datasets: (1) outdated semantic feature extraction where state-of-the-art large scale pre-trained language models like BERT cannot be exploited due to the missing of the original text;(2) incomplete display features for in-depth study of ULTR, e.g., missing the displayed abstract of documents for analyzing the click necessary bias; (3) lacking real-world user feedback, leading to the prevalence of synthetic datasets in the empirical study. To overcome the above disadvantages, we introduce the Baidu-ULTR dataset. It involves randomly sampled 1.2 billion searching sessions and 7,008 expert annotated queries, which is orders of magnitude larger than the existing ones. Baidu-ULTR provides:(1) the original semantic feature and a pre-trained language model for easy usage; (2) sufficient display information such as position, displayed height, and displayed abstract, enabling the comprehensive study of different biases with advanced techniques such as causal discovery and meta-learning; and (3) rich user feedback on search result pages (SERPs) like dwelling time, allowing for user engagement optimization and promoting the exploration of multi-task learning in ULTR. In this paper, we present the design principle of Baidu-ULTR and the performance of benchmark ULTR algorithms on this new data resource, favoring the exploration of ranking for long-tail queries and pre-training tasks for ranking. The Baidu-ULTR dataset and corresponding baseline implementation are available at https://github.com/ChuXiaokai/baidu_ultr_dataset.
Islander: A Real-Time News Monitoring and Analysis System
Apr 25, 2022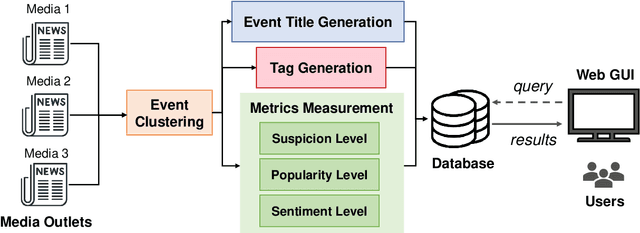
With thousands of news articles from hundreds of sources distributed and shared every day, news consumption and information acquisition have been increasingly difficult for readers. Additionally, the content of news articles is becoming catchy or even inciting to attract readership, harming the accuracy of news reporting. We present Islander, an online news analyzing system. The system allows users to browse trending topics with articles from multiple sources and perspectives. We define several metrics as proxies for news quality, and develop algorithms for automatic estimation. The quality estimation results are delivered through a web interface to newsreaders for easy access to news and information. The website is publicly available at https://islander.cc/
Asking for Knowledge: Training RL Agents to Query External Knowledge Using Language
May 12, 2022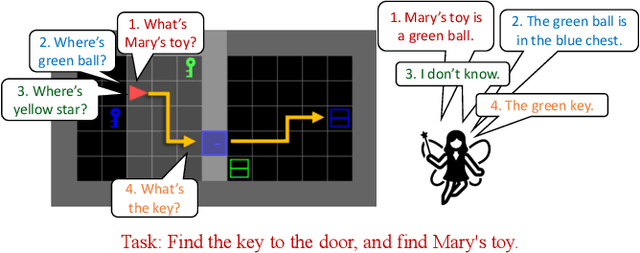
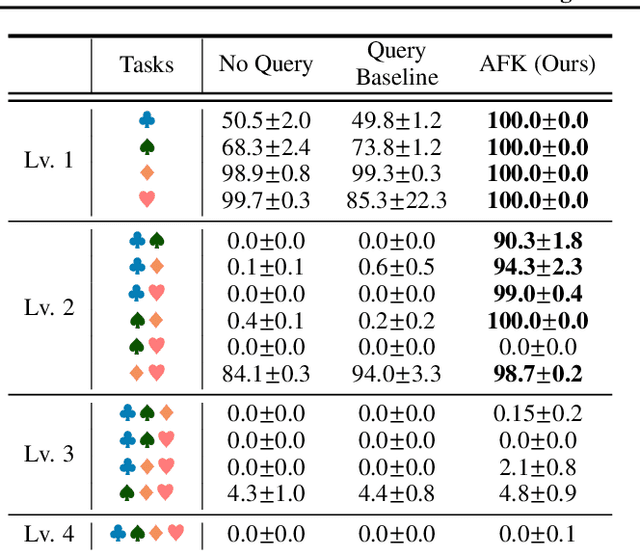


To solve difficult tasks, humans ask questions to acquire knowledge from external sources. In contrast, classical reinforcement learning agents lack such an ability and often resort to exploratory behavior. This is exacerbated as few present-day environments support querying for knowledge. In order to study how agents can be taught to query external knowledge via language, we first introduce two new environments: the grid-world-based Q-BabyAI and the text-based Q-TextWorld. In addition to physical interactions, an agent can query an external knowledge source specialized for these environments to gather information. Second, we propose the "Asking for Knowledge" (AFK) agent, which learns to generate language commands to query for meaningful knowledge that helps solve the tasks. AFK leverages a non-parametric memory, a pointer mechanism and an episodic exploration bonus to tackle (1) a large query language space, (2) irrelevant information, (3) delayed reward for making meaningful queries. Extensive experiments demonstrate that the AFK agent outperforms recent baselines on the challenging Q-BabyAI and Q-TextWorld environments.
Rethinking Minimal Sufficient Representation in Contrastive Learning
Mar 14, 2022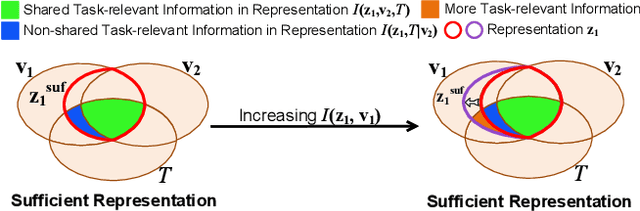

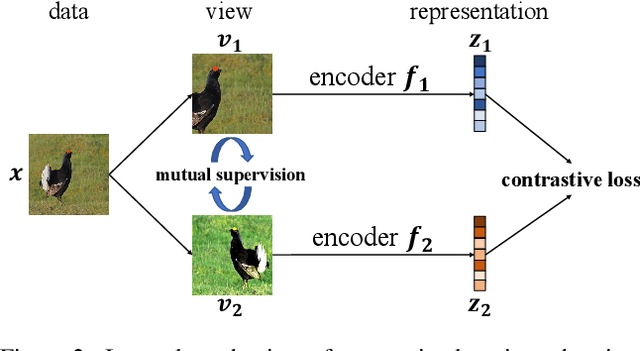
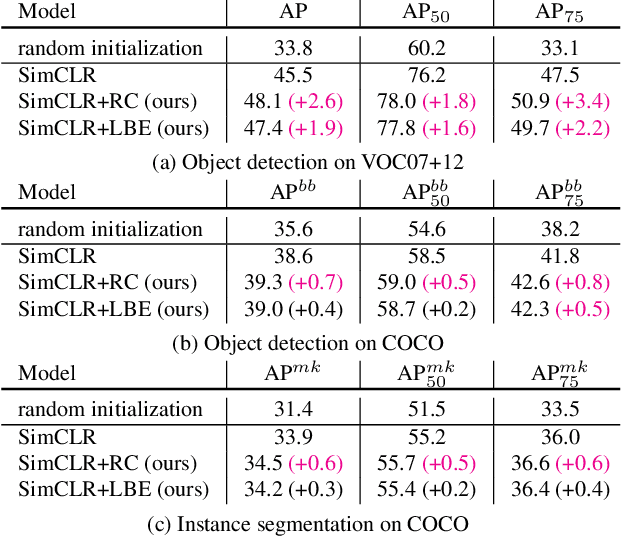
Contrastive learning between different views of the data achieves outstanding success in the field of self-supervised representation learning and the learned representations are useful in broad downstream tasks. Since all supervision information for one view comes from the other view, contrastive learning approximately obtains the minimal sufficient representation which contains the shared information and eliminates the non-shared information between views. Considering the diversity of the downstream tasks, it cannot be guaranteed that all task-relevant information is shared between views. Therefore, we assume the non-shared task-relevant information cannot be ignored and theoretically prove that the minimal sufficient representation in contrastive learning is not sufficient for the downstream tasks, which causes performance degradation. This reveals a new problem that the contrastive learning models have the risk of over-fitting to the shared information between views. To alleviate this problem, we propose to increase the mutual information between the representation and input as regularization to approximately introduce more task-relevant information, since we cannot utilize any downstream task information during training. Extensive experiments verify the rationality of our analysis and the effectiveness of our method. It significantly improves the performance of several classic contrastive learning models in downstream tasks. Our code is available at \url{https://github.com/Haoqing-Wang/InfoCL}.
Mutual Information Constraints for Monte-Carlo Objectives
Dec 01, 2020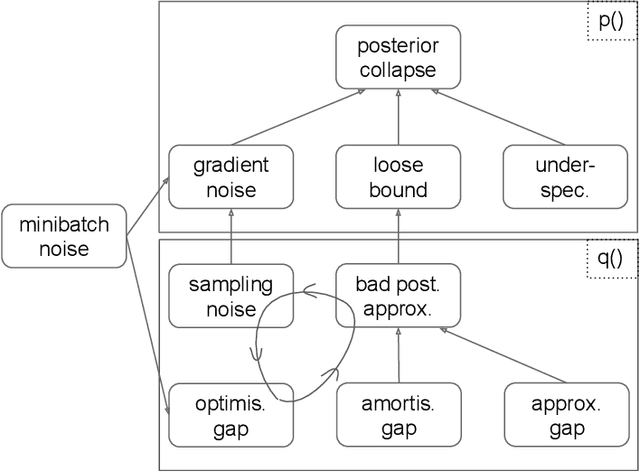
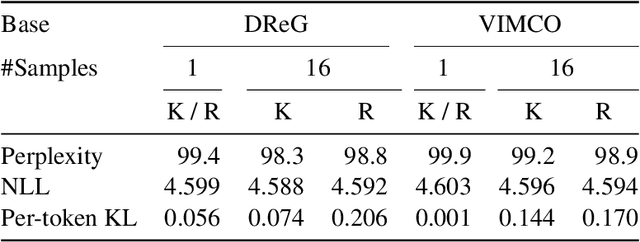
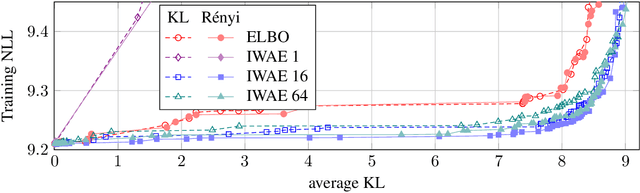
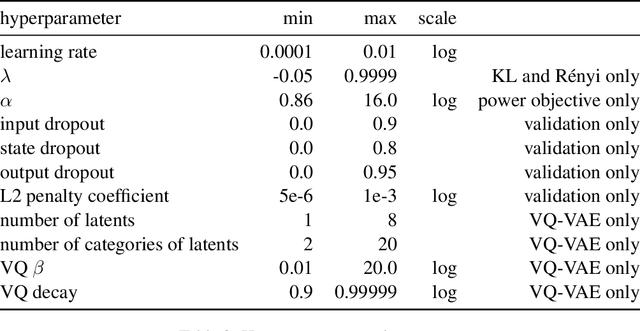
A common failure mode of density models trained as variational autoencoders is to model the data without relying on their latent variables, rendering these variables useless. Two contributing factors, the underspecification of the model and the looseness of the variational lower bound, have been studied separately in the literature. We weave these two strands of research together, specifically the tighter bounds of Monte-Carlo objectives and constraints on the mutual information between the observable and the latent variables. Estimating the mutual information as the average Kullback-Leibler divergence between the easily available variational posterior $q(z|x)$ and the prior does not work with Monte-Carlo objectives because $q(z|x)$ is no longer a direct approximation to the model's true posterior $p(z|x)$. Hence, we construct estimators of the Kullback-Leibler divergence of the true posterior from the prior by recycling samples used in the objective, with which we train models of continuous and discrete latents at much improved rate-distortion and no posterior collapse. While alleviated, the tradeoff between modelling the data and using the latents still remains, and we urge for evaluating inference methods across a range of mutual information values.