 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting the Black Box: Structural Barriers to Independent Evaluation of Consumer-Facing Health LLMs
Jun 07, 2026Background: Consumer-facing large language models are now a common source of health information, and they interpret and personalize responses rather than retrieve them. Whether their responses vary across users is a clinical, equity, and governance question, sharpened by evidence that sycophantic responses can alter judgment and increase trust. Objective: To evaluate response variation and sycophancy in consumer-facing health LLMs under conditions resembling ordinary patient use. Methods: We constructed simulated user profiles differing in geography, browsing context, expressed beliefs, and social determinants of health, drawing on literature linking social context to health attitudes. We adapted validated instruments, including the Vaccination Attitudes Examination scale and reproductive attitudes scales, into multi-turn prompts designed to elicit clinically meaningful variation across users. Results: The evaluation encountered five linked barriers. Factual prompts produced stable responses that masked sycophancy emerging over multi-turn conversation. Browser-based interfaces did not disclose which signals influence outputs and could not be reset to a clean baseline. Large-scale testing was restricted by terms of service, rate limits, and bot detection. Accuracy-based criteria could not capture tone, framing, or omission, and LLM-as-judge methods risked shared alignment bias. Models changed without traceable version identifiers, preventing reliable replication. Conclusions: No reliable independent evaluation framework yet exists for examining how consumer-facing health LLMs behave in ordinary use. Oversight requires disclosure of personalization signals, stable version identifiers, researcher safe harbor programs, and post-deployment monitoring of health-related outputs.
Write It Like You See It: Detectable Differences in Clinical Notes By Race Lead To Differential Model Recommendations
May 08, 2022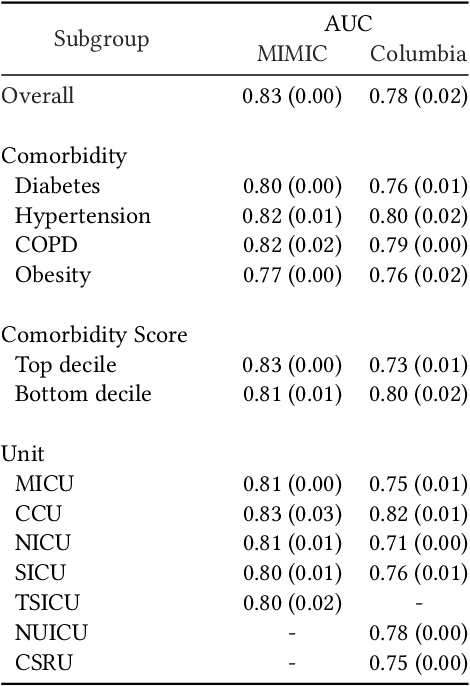
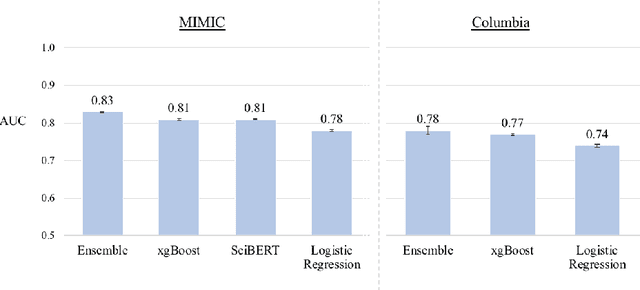


Clinical notes are becoming an increasingly important data source for machine learning (ML) applications in healthcare. Prior research has shown that deploying ML models can perpetuate existing biases against racial minorities, as bias can be implicitly embedded in data. In this study, we investigate the level of implicit race information available to ML models and human experts and the implications of model-detectable differences in clinical notes. Our work makes three key contributions. First, we find that models can identify patient self-reported race from clinical notes even when the notes are stripped of explicit indicators of race. Second, we determine that human experts are not able to accurately predict patient race from the same redacted clinical notes. Finally, we demonstrate the potential harm of this implicit information in a simulation study, and show that models trained on these race-redacted clinical notes can still perpetuate existing biases in clinical treatment decisions.