 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Dual Information Bottleneck
Jun 08, 2020
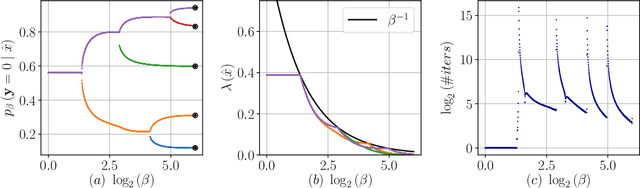
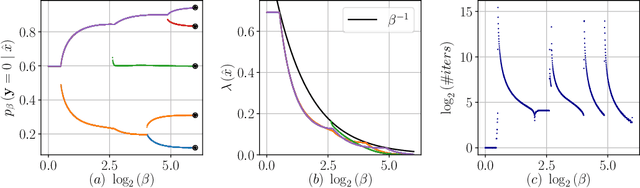
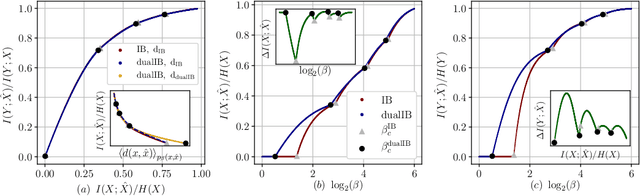
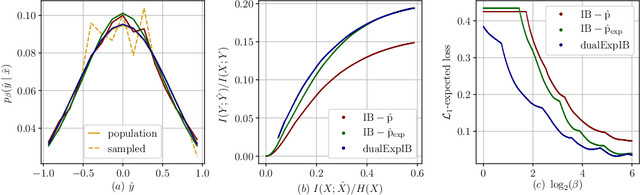
The Information Bottleneck (IB) framework is a general characterization of optimal representations obtained using a principled approach for balancing accuracy and complexity. Here we present a new framework, the Dual Information Bottleneck (dualIB), which resolves some of the known drawbacks of the IB. We provide a theoretical analysis of the dualIB framework; (i) solving for the structure of its solutions (ii) unraveling its superiority in optimizing the mean prediction error exponent and (iii) demonstrating its ability to preserve exponential forms of the original distribution. To approach large scale problems, we present a novel variational formulation of the dualIB for Deep Neural Networks. In experiments on several data-sets, we compare it to a variational form of the IB. This exposes superior Information Plane properties of the dualIB and its potential in improvement of the error.
Bounds on mutual information of mixture data for classification tasks
Jan 27, 2021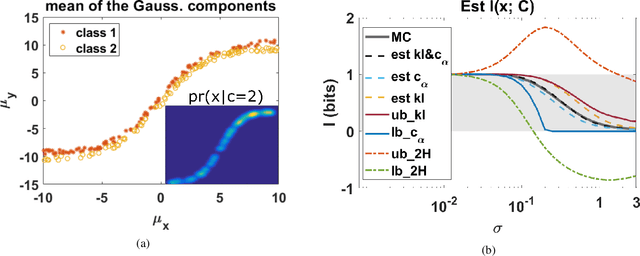
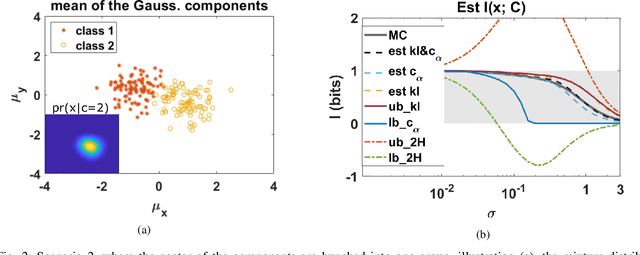
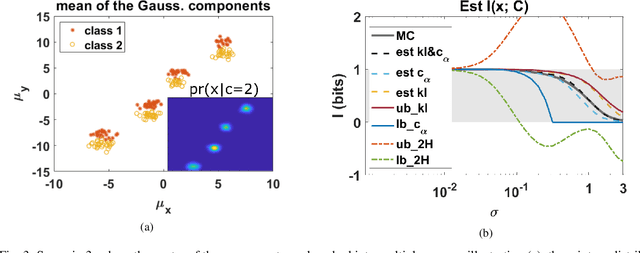
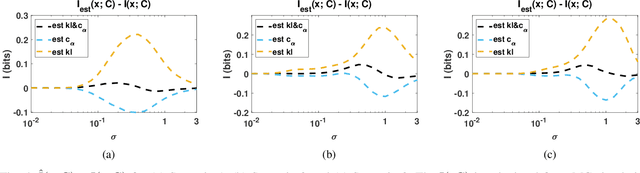
The data for many classification problems, such as pattern and speech recognition, follow mixture distributions. To quantify the optimum performance for classification tasks, the Shannon mutual information is a natural information-theoretic metric, as it is directly related to the probability of error. The mutual information between mixture data and the class label does not have an analytical expression, nor any efficient computational algorithms. We introduce a variational upper bound, a lower bound, and three estimators, all employing pair-wise divergences between mixture components. We compare the new bounds and estimators with Monte Carlo stochastic sampling and bounds derived from entropy bounds. To conclude, we evaluate the performance of the bounds and estimators through numerical simulations.
EHRKit: A Python Natural Language Processing Toolkit for Electronic Health Record Texts
Apr 13, 2022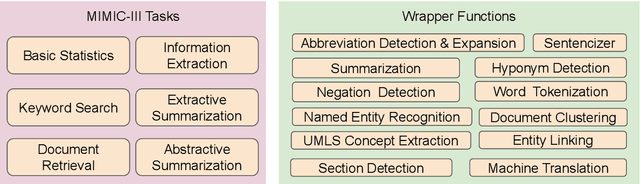

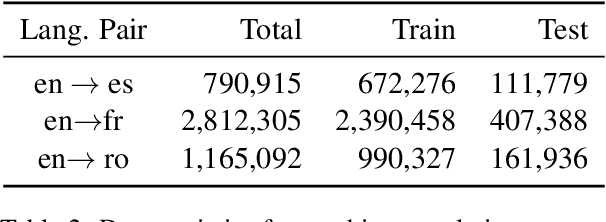
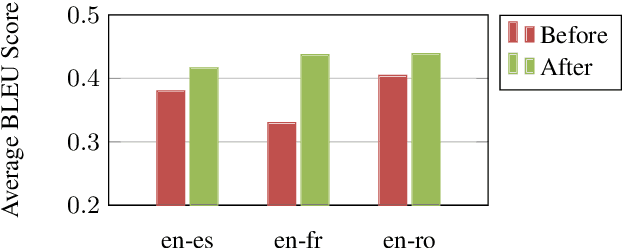
The Electronic Health Record (EHR) is an essential part of the modern medical system and impacts healthcare delivery, operations, and research. Unstructured text is attracting much attention despite structured information in the EHRs and has become an exciting research field. The success of the recent neural Natural Language Processing (NLP) method has led to a new direction for processing unstructured clinical notes. In this work, we create a python library for clinical texts, EHRKit. This library contains two main parts: MIMIC-III-specific functions and tasks specific functions. The first part introduces a list of interfaces for accessing MIMIC-III NOTEEVENTS data, including basic search, information retrieval, and information extraction. The second part integrates many third-party libraries for up to 12 off-shelf NLP tasks such as named entity recognition, summarization, machine translation, etc.
Where Was COVID-19 First Discovered? Designing a Question-Answering System for Pandemic Situations
Apr 19, 2022

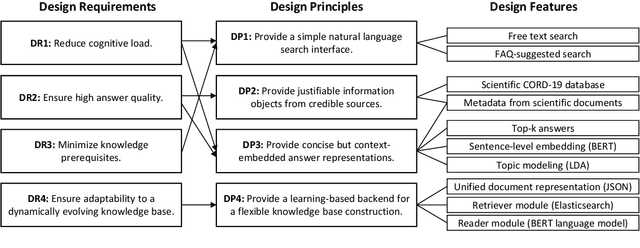

The COVID-19 pandemic is accompanied by a massive "infodemic" that makes it hard to identify concise and credible information for COVID-19-related questions, like incubation time, infection rates, or the effectiveness of vaccines. As a novel solution, our paper is concerned with designing a question-answering system based on modern technologies from natural language processing to overcome information overload and misinformation in pandemic situations. To carry out our research, we followed a design science research approach and applied Ingwersen's cognitive model of information retrieval interaction to inform our design process from a socio-technical lens. On this basis, we derived prescriptive design knowledge in terms of design requirements and design principles, which we translated into the construction of a prototypical instantiation. Our implementation is based on the comprehensive CORD-19 dataset, and we demonstrate our artifact's usefulness by evaluating its answer quality based on a sample of COVID-19 questions labeled by biomedical experts.
Exploring the Effectiveness of Video Perceptual Representation in Blind Video Quality Assessment
Jul 08, 2022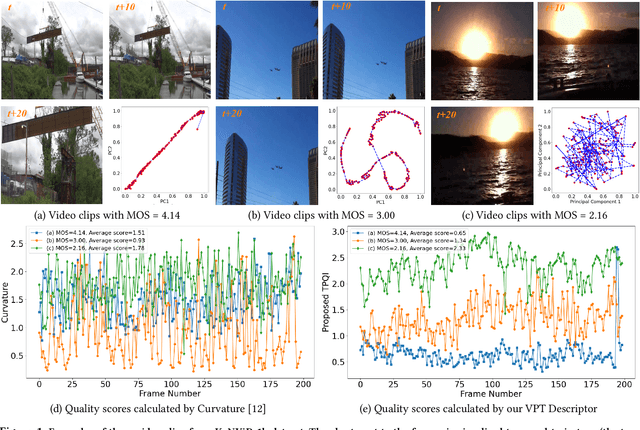
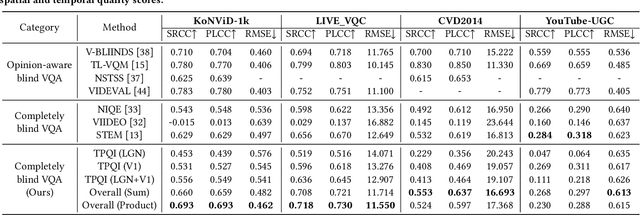
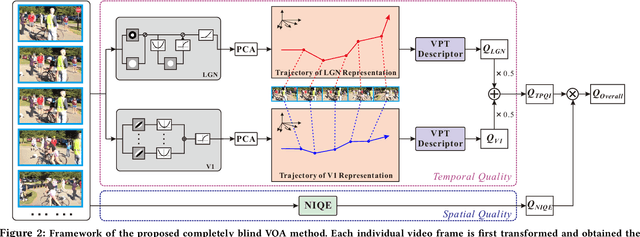
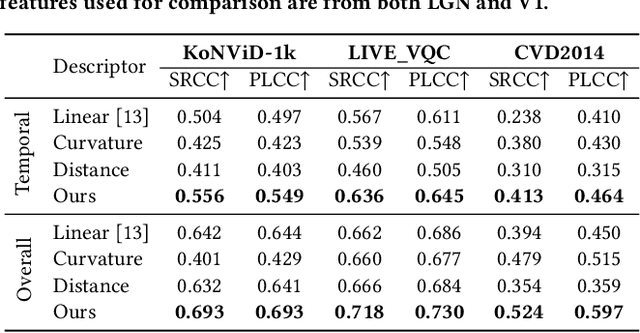
With the rapid growth of in-the-wild videos taken by non-specialists, blind video quality assessment (VQA) has become a challenging and demanding problem. Although lots of efforts have been made to solve this problem, it remains unclear how the human visual system (HVS) relates to the temporal quality of videos. Meanwhile, recent work has found that the frames of natural video transformed into the perceptual domain of the HVS tend to form a straight trajectory of the representations. With the obtained insight that distortion impairs the perceived video quality and results in a curved trajectory of the perceptual representation, we propose a temporal perceptual quality index (TPQI) to measure the temporal distortion by describing the graphic morphology of the representation. Specifically, we first extract the video perceptual representations from the lateral geniculate nucleus (LGN) and primary visual area (V1) of the HVS, and then measure the straightness and compactness of their trajectories to quantify the degradation in naturalness and content continuity of video. Experiments show that the perceptual representation in the HVS is an effective way of predicting subjective temporal quality, and thus TPQI can, for the first time, achieve comparable performance to the spatial quality metric and be even more effective in assessing videos with large temporal variations. We further demonstrate that by combining with NIQE, a spatial quality metric, TPQI can achieve top performance over popular in-the-wild video datasets. More importantly, TPQI does not require any additional information beyond the video being evaluated and thus can be applied to any datasets without parameter tuning. Source code is available at https://github.com/UoLMM/TPQI-VQA.
* Will appear on ACM MM 2022
HRFuser: A Multi-resolution Sensor Fusion Architecture for 2D Object Detection
Jun 30, 2022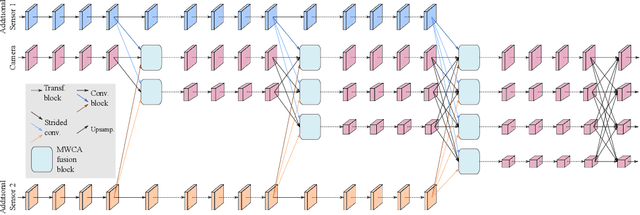
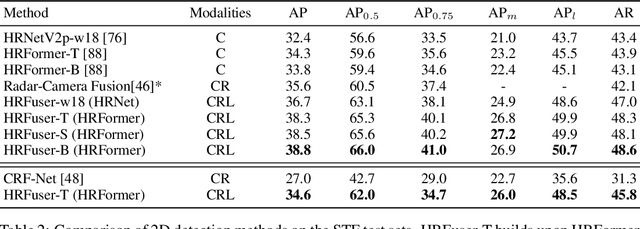
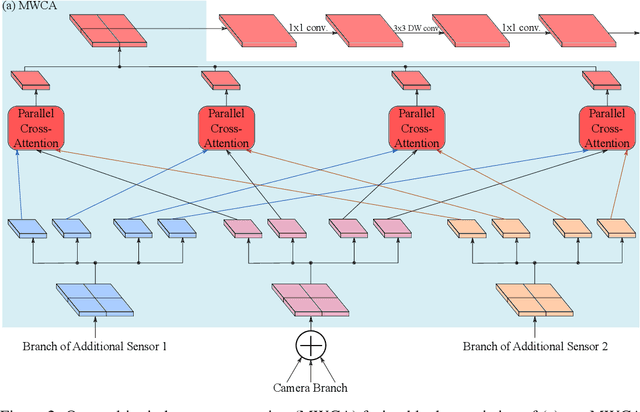

Besides standard cameras, autonomous vehicles typically include multiple additional sensors, such as lidars and radars, which help acquire richer information for perceiving the content of the driving scene. While several recent works focus on fusing certain pairs of sensors - such as camera and lidar or camera and radar - by using architectural components specific to the examined setting, a generic and modular sensor fusion architecture is missing from the literature. In this work, we focus on 2D object detection, a fundamental high-level task which is defined on the 2D image domain, and propose HRFuser, a multi-resolution sensor fusion architecture that scales straightforwardly to an arbitrary number of input modalities. The design of HRFuser is based on state-of-the-art high-resolution networks for image-only dense prediction and incorporates a novel multi-window cross-attention block as the means to perform fusion of multiple modalities at multiple resolutions. Even though cameras alone provide very informative features for 2D detection, we demonstrate via extensive experiments on the nuScenes and Seeing Through Fog datasets that our model effectively leverages complementary features from additional modalities, substantially improving upon camera-only performance and consistently outperforming state-of-the-art fusion methods for 2D detection both in normal and adverse conditions. The source code will be made publicly available.
Generating Full Length Wikipedia Biographies: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies
Apr 12, 2022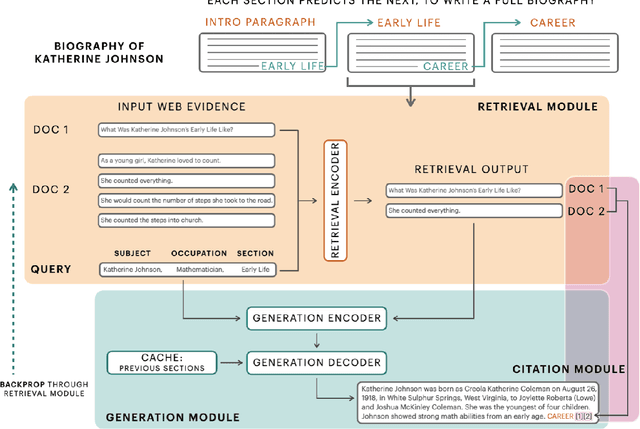

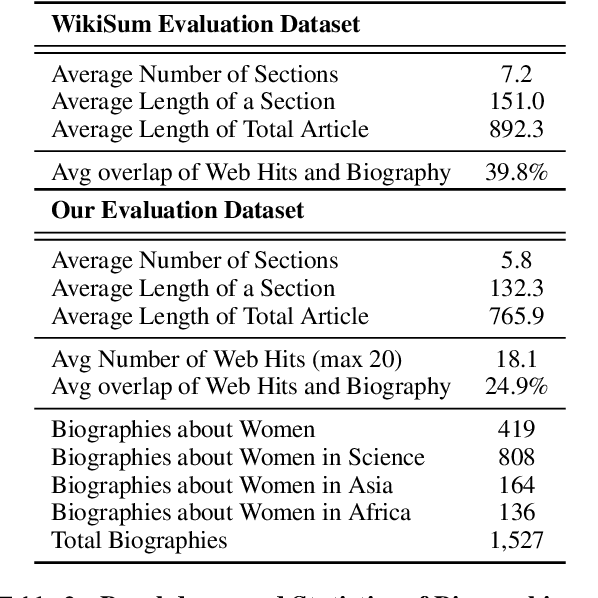

Generating factual, long-form text such as Wikipedia articles raises three key challenges: how to gather relevant evidence, how to structure information into well-formed text, and how to ensure that the generated text is factually correct. We address these by developing a model for English text that uses a retrieval mechanism to identify relevant supporting information on the web and a cache-based pre-trained encoder-decoder to generate long-form biographies section by section, including citation information. To assess the impact of available web evidence on the output text, we compare the performance of our approach when generating biographies about women (for which less information is available on the web) vs. biographies generally. To this end, we curate a dataset of 1,500 biographies about women. We analyze our generated text to understand how differences in available web evidence data affect generation. We evaluate the factuality, fluency, and quality of the generated texts using automatic metrics and human evaluation. We hope that these techniques can be used as a starting point for human writers, to aid in reducing the complexity inherent in the creation of long-form, factual text.
Jointly Harnessing Prior Structures and Temporal Consistency for Sign Language Video Generation
Jul 08, 2022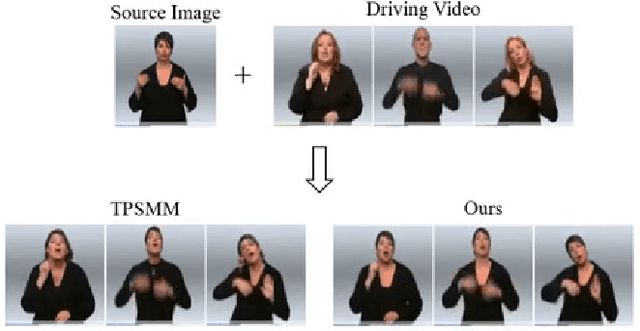
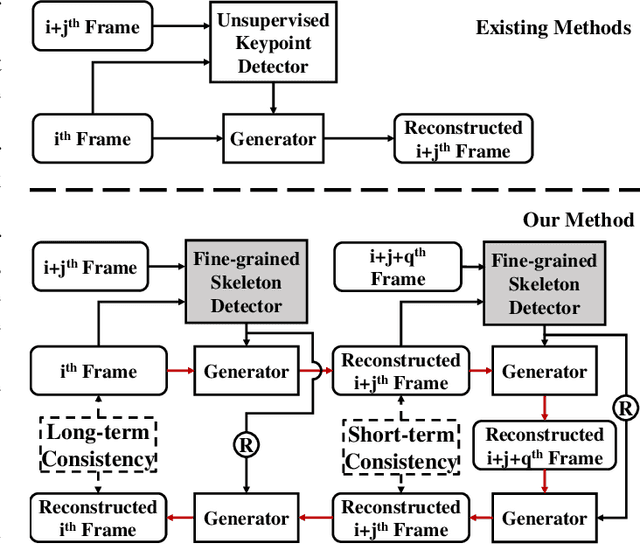
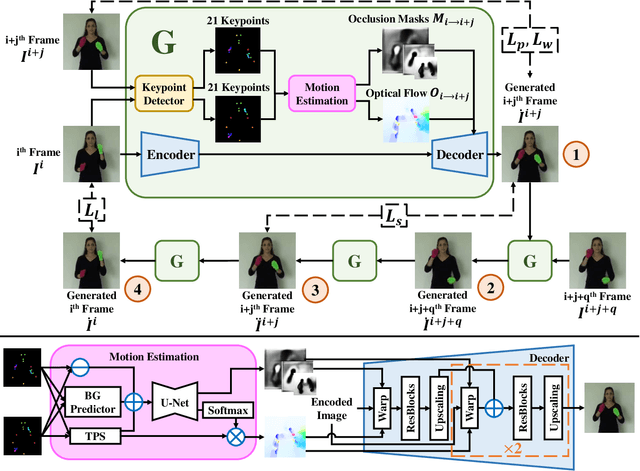

Sign language is the window for people differently-abled to express their feelings as well as emotions. However, it remains challenging for people to learn sign language in a short time. To address this real-world challenge, in this work, we study the motion transfer system, which can transfer the user photo to the sign language video of specific words. In particular, the appearance content of the output video comes from the provided user image, while the motion of the video is extracted from the specified tutorial video. We observe two primary limitations in adopting the state-of-the-art motion transfer methods to sign language generation:(1) Existing motion transfer works ignore the prior geometrical knowledge of the human body. (2) The previous image animation methods only take image pairs as input in the training stage, which could not fully exploit the temporal information within videos. In an attempt to address the above-mentioned limitations, we propose Structure-aware Temporal Consistency Network (STCNet) to jointly optimize the prior structure of human with the temporal consistency for sign language video generation. There are two main contributions in this paper. (1) We harness a fine-grained skeleton detector to provide prior knowledge of the body keypoints. In this way, we ensure the keypoint movement in a valid range and make the model become more explainable and robust. (2) We introduce two cycle-consistency losses, i.e., short-term cycle loss and long-term cycle loss, which are conducted to assure the continuity of the generated video. We optimize the two losses and keypoint detector network in an end-to-end manner.
INSTA-BNN: Binary Neural Network with INSTAnce-aware Threshold
Apr 15, 2022

Binary Neural Networks (BNNs) have emerged as a promising solution for reducing the memory footprint and compute costs of deep neural networks. BNNs, on the other hand, suffer from information loss because binary activations are limited to only two values, resulting in reduced accuracy. To improve the accuracy, previous studies have attempted to control the distribution of binary activation by manually shifting the threshold of the activation function or making the shift amount trainable. During the process, they usually depended on statistical information computed from a batch. We argue that using statistical data from a batch fails to capture the crucial information for each input instance in BNN computations, and the differences between statistical information computed from each instance need to be considered when determining the binary activation threshold of each instance. Based on the concept, we propose the Binary Neural Network with INSTAnce-aware threshold (INSTA-BNN), which decides the activation threshold value considering the difference between statistical data computed from a batch and each instance. The proposed INSTA-BNN outperforms the baseline by 2.5% and 2.3% on the ImageNet classification task with comparable computing cost, achieving 68.0% and 71.7% top-1 accuracy on ResNet-18 and MobileNetV1 based models, respectively.
Universally Expressive Communication in Multi-Agent Reinforcement Learning
Jun 14, 2022
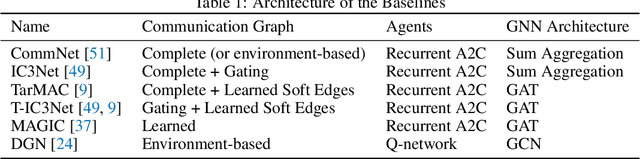

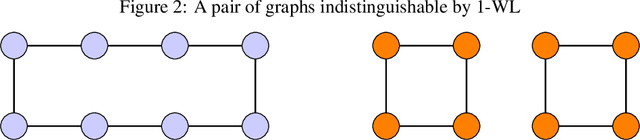
Allowing agents to share information through communication is crucial for solving complex tasks in multi-agent reinforcement learning. In this work, we consider the question of whether a given communication protocol can express an arbitrary policy. By observing that many existing protocols can be viewed as instances of graph neural networks (GNNs), we demonstrate the equivalence of joint action selection to node labelling. With standard GNN approaches provably limited in their expressive capacity, we draw from existing GNN literature and consider augmenting agent observations with: (1) unique agent IDs and (2) random noise. We provide a theoretical analysis as to how these approaches yield universally expressive communication, and also prove them capable of targeting arbitrary sets of actions for identical agents. Empirically, these augmentations are found to improve performance on tasks where expressive communication is required, whilst, in general, the optimal communication protocol is found to be task-dependent.