 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning-Enabled Semantic Communication Systems with Task-Unaware Transmitter and Dynamic Data
Apr 30, 2022
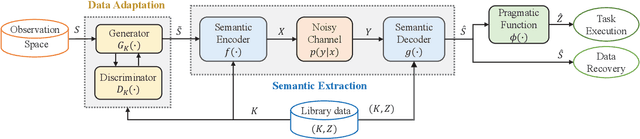
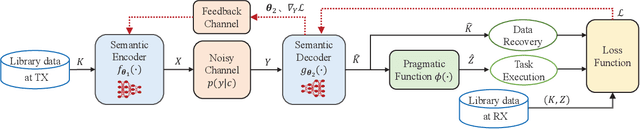
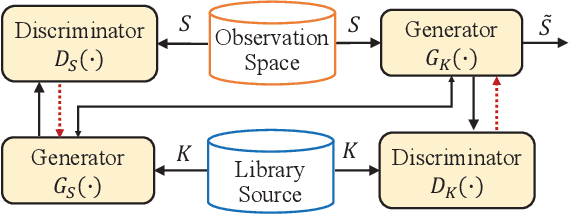
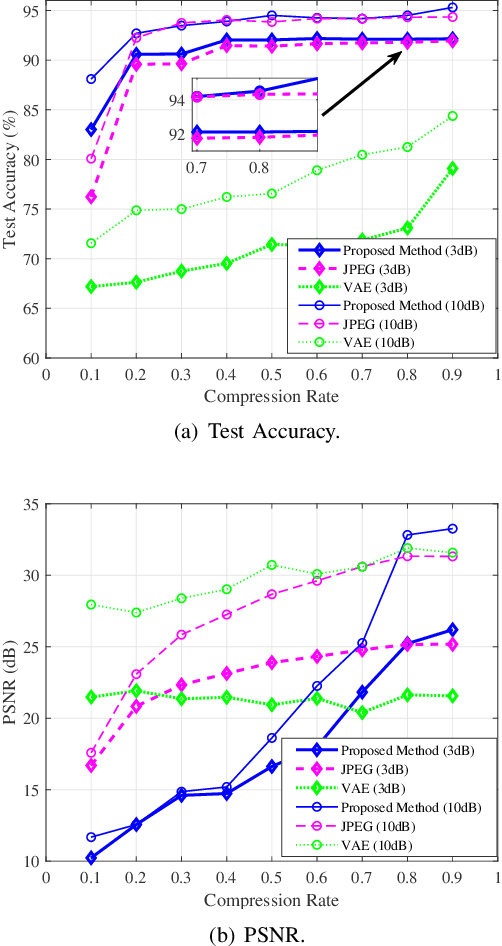
Existing deep learning-enabled semantic communication systems often rely on shared background knowledge between the transmitter and receiver that includes empirical data and their associated semantic information. In practice, the semantic information is defined by the pragmatic task of the receiver and cannot be known to the transmitter. The actual observable data at the transmitter can also have non-identical distribution with the empirical data in the shared background knowledge library. To address these practical issues, this paper proposes a new neural network-based semantic communication system for image transmission, where the task is unaware at the transmitter and the data environment is dynamic. The system consists of two main parts, namely the semantic extraction (SE) network and the data adaptation (DA) network. The SE network learns how to extract the semantic information using a receiver-leading training process. By using domain adaptation technique from transfer learning, the DA network learns how to convert the data observed into a similar form of the empirical data that the SE network can process without re-training. Numerical experiments show that the proposed method can be adaptive to observable datasets while keeping high performance in terms of both data recovery and task execution. The codes are available on https://github.com/SJTU-mxtao/Semantic-Communication-Systems.
Transformer based multiple instance learning for weakly supervised histopathology image segmentation
May 18, 2022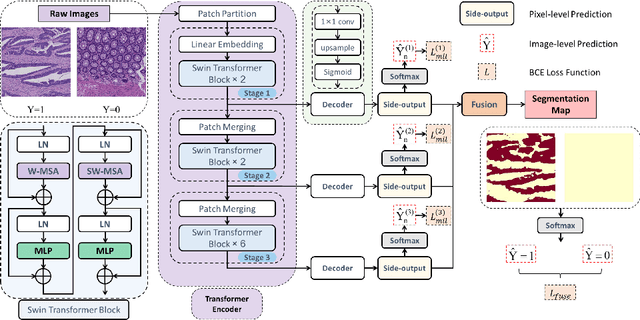
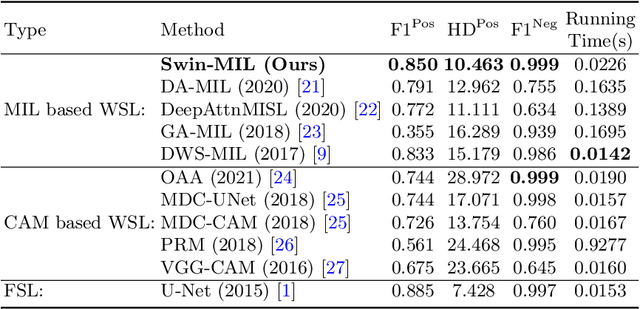
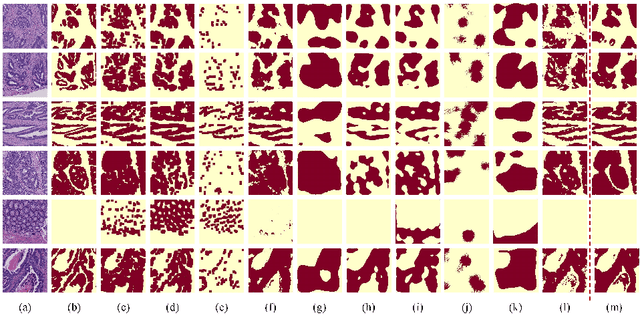
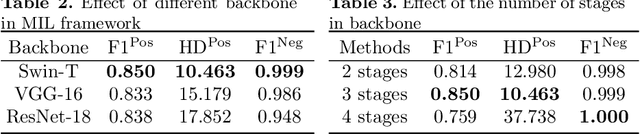
Hispathological image segmentation algorithms play a critical role in computer aided diagnosis technology. The development of weakly supervised segmentation algorithm alleviates the problem of medical image annotation that it is time-consuming and labor-intensive. As a subset of weakly supervised learning, Multiple Instance Learning (MIL) has been proven to be effective in segmentation. However, there is a lack of related information between instances in MIL, which limits the further improvement of segmentation performance. In this paper, we propose a novel weakly supervised method for pixel-level segmentation in histopathology images, which introduces Transformer into the MIL framework to capture global or long-range dependencies. The multi-head self-attention in the Transformer establishes the relationship between instances, which solves the shortcoming that instances are independent of each other in MIL. In addition, deep supervision is introduced to overcome the limitation of annotations in weakly supervised methods and make the better utilization of hierarchical information. The state-of-the-art results on the colon cancer dataset demonstrate the superiority of the proposed method compared with other weakly supervised methods. It is worth believing that there is a potential of our approach for various applications in medical images.
MIMO Symbiotic Radio with Massive Passive Devices: Asymptotic Analysis and Precoding Optimization
Jun 28, 2022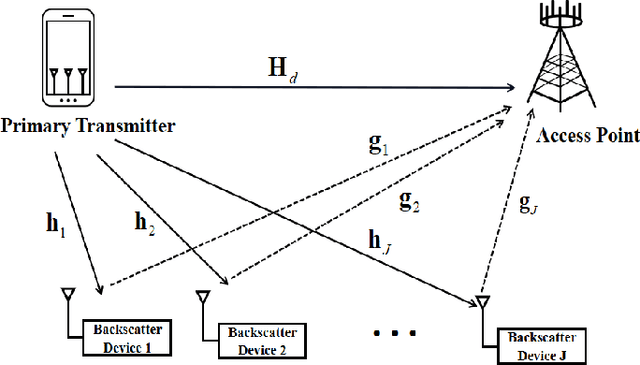
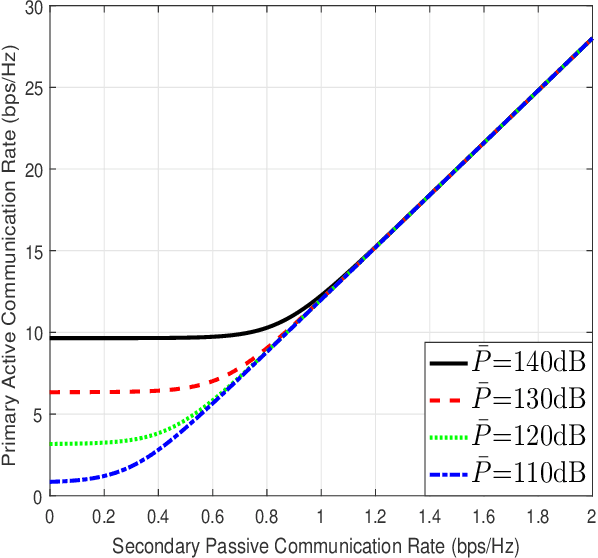
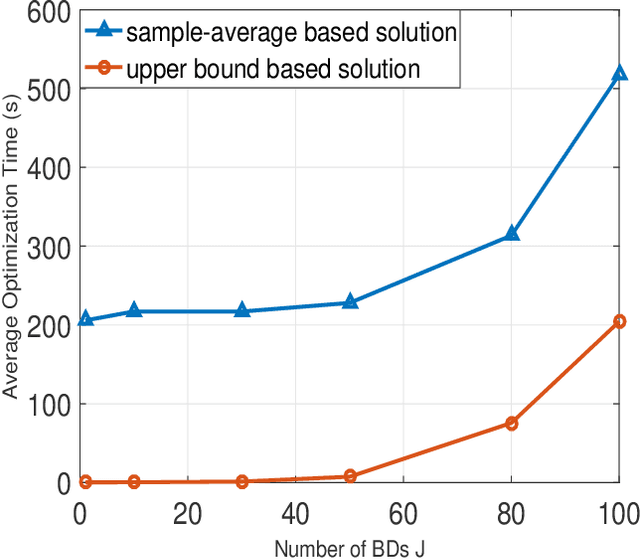
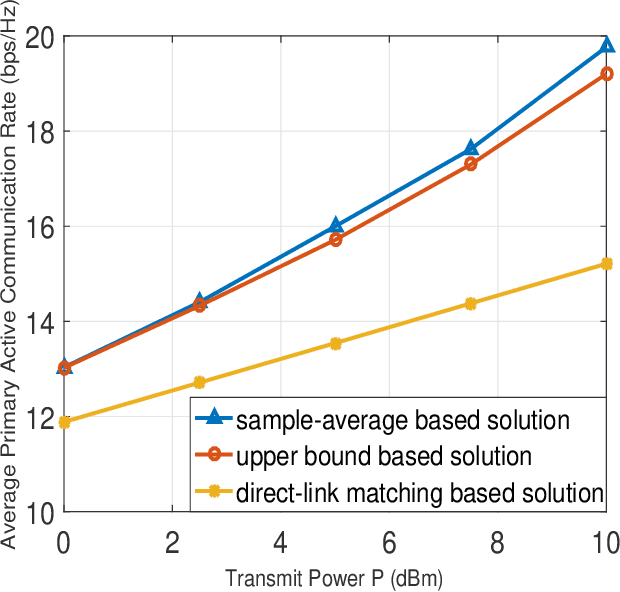
Symbiotic radio has emerged as a promising technology for spectrum- and energy-efficient wireless communications, where the passive secondary backscatter devices (BDs) reuse not only the spectrum but also the power of the active primary users to transmit their own information. In return, the primary communication links can be enhanced by the additional multipaths created by the BDs. This is known as the mutualism relationship of symbiotic radio. However, due to the severe double-fading attenuation of the passive backscattering links, the enhancement of the primary link provided by one single BD is extremely limited. To address this issue and enable full mutualism of symbiotic radio, in this paper, we study multiple-input multiple output (MIMO) symbiotic radio communication systems with massive BDs. We first derive the achievable rates of the primary active communication and secondary passive communication, and then consider the asymptotic regime as the number of BDs goes large, for which closed-form expressions are derived to reveal the relationship between the primary and secondary communication rates. Furthermore, the precoding optimization problem is studied to maximize the primary communication rate while guaranteeing that the secondary communication rate is no smaller than a certain threshold. Simulation results are provided to validate our theoretical studies.
Kleister: Key Information Extraction Datasets Involving Long Documents with Complex Layouts
May 12, 2021
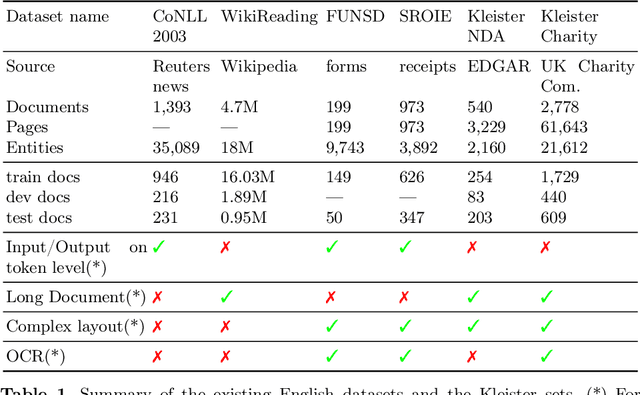
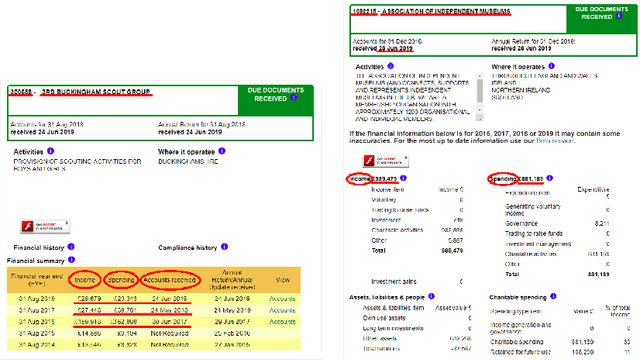
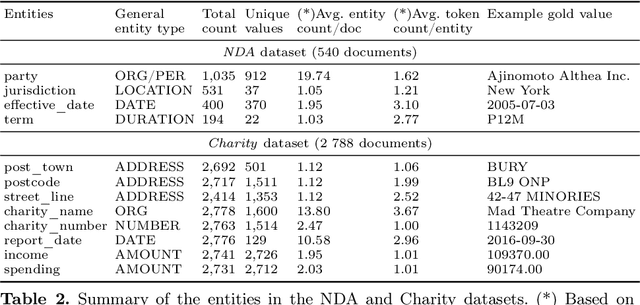
The relevance of the Key Information Extraction (KIE) task is increasingly important in natural language processing problems. But there are still only a few well-defined problems that serve as benchmarks for solutions in this area. To bridge this gap, we introduce two new datasets (Kleister NDA and Kleister Charity). They involve a mix of scanned and born-digital long formal English-language documents. In these datasets, an NLP system is expected to find or infer various types of entities by employing both textual and structural layout features. The Kleister Charity dataset consists of 2,788 annual financial reports of charity organizations, with 61,643 unique pages and 21,612 entities to extract. The Kleister NDA dataset has 540 Non-disclosure Agreements, with 3,229 unique pages and 2,160 entities to extract. We provide several state-of-the-art baseline systems from the KIE domain (Flair, BERT, RoBERTa, LayoutLM, LAMBERT), which show that our datasets pose a strong challenge to existing models. The best model achieved an 81.77% and an 83.57% F1-score on respectively the Kleister NDA and the Kleister Charity datasets. We share the datasets to encourage progress on more in-depth and complex information extraction tasks.
Attention-based conditioning methods using variable frame rate for style-robust speaker verification
Jun 28, 2022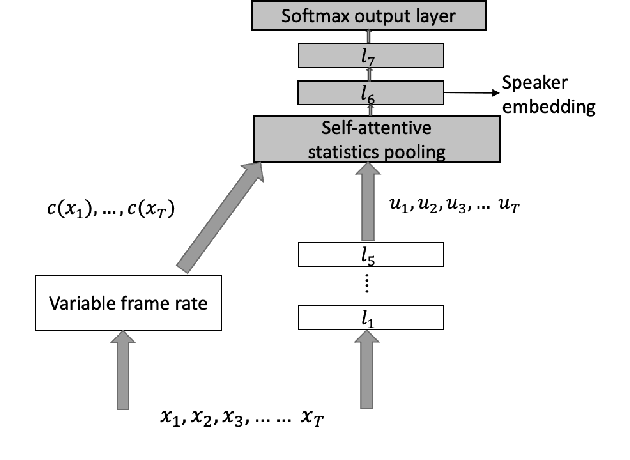
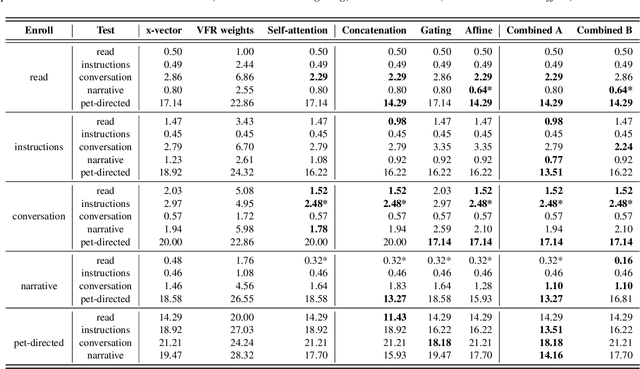
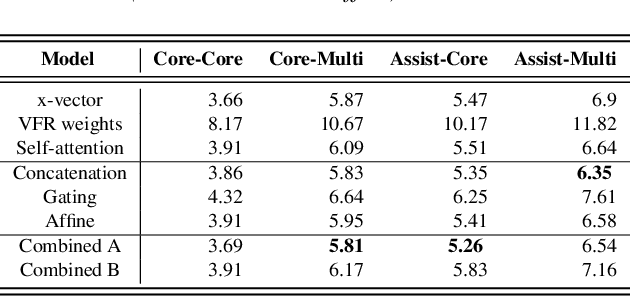
We propose an approach to extract speaker embeddings that are robust to speaking style variations in text-independent speaker verification. Typically, speaker embedding extraction includes training a DNN for speaker classification and using the bottleneck features as speaker representations. Such a network has a pooling layer to transform frame-level to utterance-level features by calculating statistics over all utterance frames, with equal weighting. However, self-attentive embeddings perform weighted pooling such that the weights correspond to the importance of the frames in a speaker classification task. Entropy can capture acoustic variability due to speaking style variations. Hence, an entropy-based variable frame rate vector is proposed as an external conditioning vector for the self-attention layer to provide the network with information that can address style effects. This work explores five different approaches to conditioning. The best conditioning approach, concatenation with gating, provided statistically significant improvements over the x-vector baseline in 12/23 tasks and was the same as the baseline in 11/23 tasks when using the UCLA speaker variability database. It also significantly outperformed self-attention without conditioning in 9/23 tasks and was worse in 1/23. The method also showed significant improvements in multi-speaker scenarios of SITW.
Image Feature Information Extraction for Interest Point Detection: A Comprehensive Review
Jul 06, 2021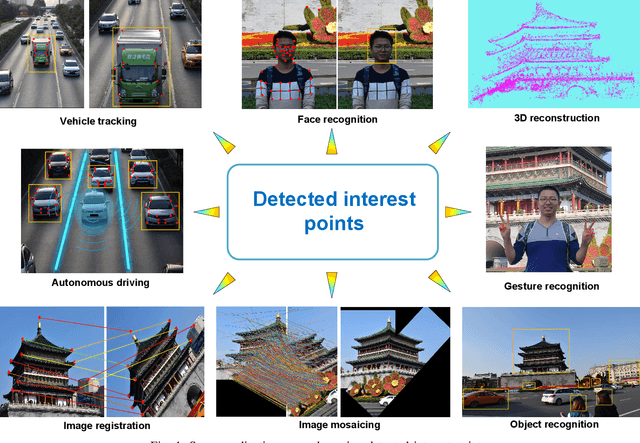
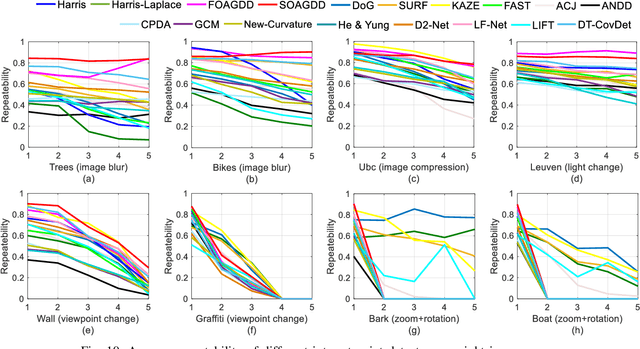

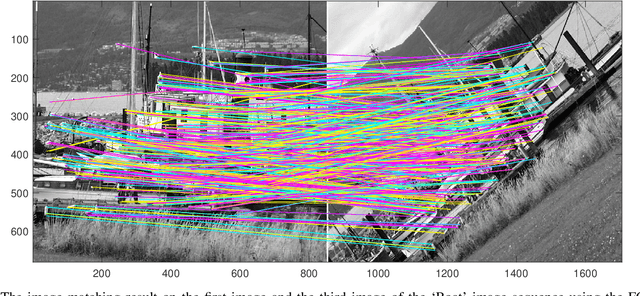
Interest point detection is one of the most fundamental and critical problems in computer vision and image processing. In this paper, we carry out a comprehensive review on image feature information (IFI) extraction techniques for interest point detection. To systematically introduce how the existing interest point detection methods extract IFI from an input image, we propose a taxonomy of the IFI extraction techniques for interest point detection. According to this taxonomy, we discuss different types of IFI extraction techniques for interest point detection. Furthermore, we identify the main unresolved issues related to the existing IFI extraction techniques for interest point detection and any interest point detection methods that have not been discussed before. The existing popular datasets and evaluation standards are provided and the performances for eighteen state-of-the-art approaches are evaluated and discussed. Moreover, future research directions on IFI extraction techniques for interest point detection are elaborated.
Dynamical System Segmentation for Information Measures in Motion
Dec 09, 2020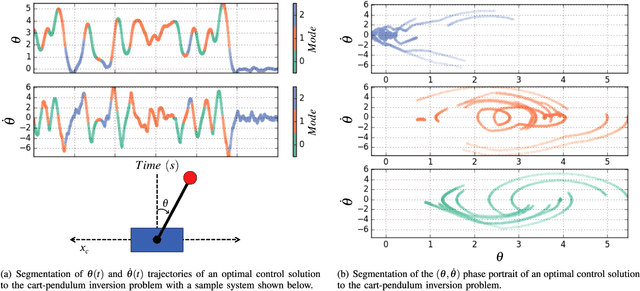
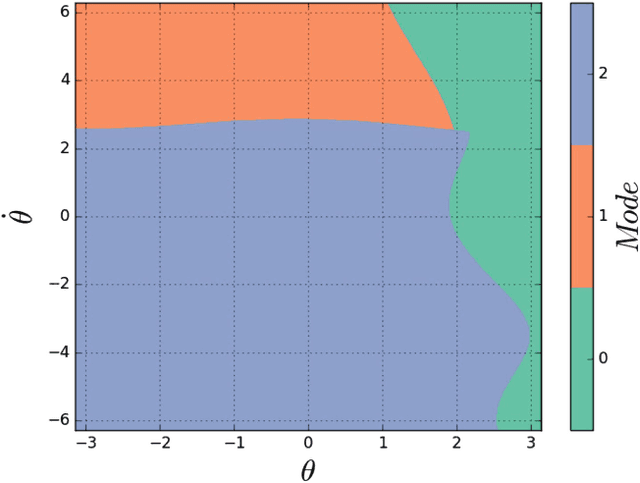
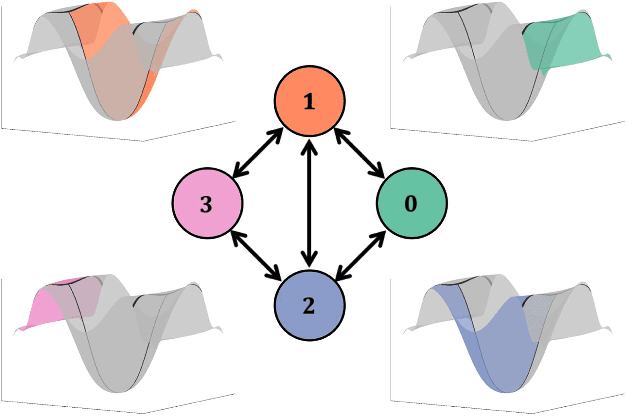
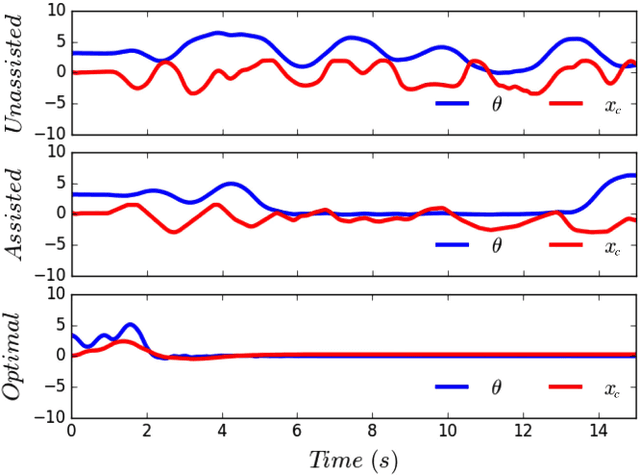
Motions carry information about the underlying task being executed. Previous work in human motion analysis suggests that complex motions may result from the composition of fundamental submovements called movemes. The existence of finite structure in motion motivates information-theoretic approaches to motion analysis and robotic assistance. We define task embodiment as the amount of task information encoded in an agent's motions. By decoding task-specific information embedded in motion, we can use task embodiment to create detailed performance assessments. We extract an alphabet of behaviors comprising a motion without \textit{a priori} knowledge using a novel algorithm, which we call dynamical system segmentation. For a given task, we specify an optimal agent, and compute an alphabet of behaviors representative of the task. We identify these behaviors in data from agent executions, and compare their relative frequencies against that of the optimal agent using the Kullback-Leibler divergence. We validate this approach using a dataset of human subjects (n=53) performing a dynamic task, and under this measure find that individuals receiving assistance better embody the task. Moreover, we find that task embodiment is a better predictor of assistance than integrated mean-squared-error.
* 8 pages
Transformer based Generative Adversarial Network for Liver Segmentation
May 21, 2022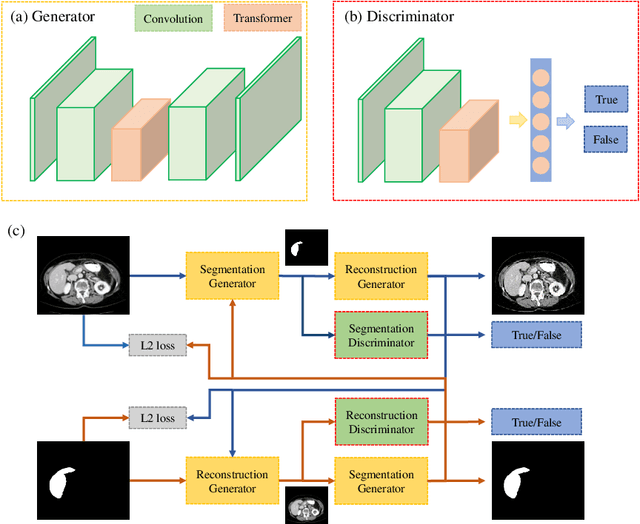

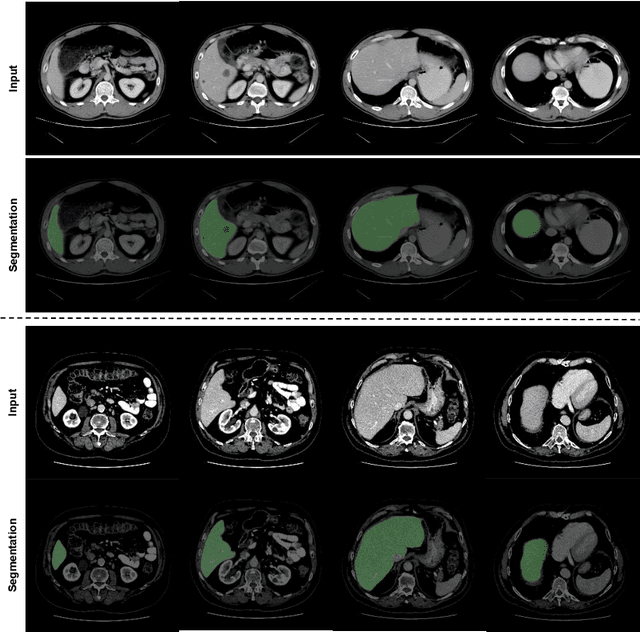
Automated liver segmentation from radiology scans (CT, MRI) can improve surgery and therapy planning and follow-up assessment in addition to conventional use for diagnosis and prognosis. Although convolutional neural networks (CNNs) have become the standard image segmentation tasks, more recently this has started to change towards Transformers based architectures because Transformers are taking advantage of capturing long range dependence modeling capability in signals, so called attention mechanism. In this study, we propose a new segmentation approach using a hybrid approach combining the Transformer(s) with the Generative Adversarial Network (GAN) approach. The premise behind this choice is that the self-attention mechanism of the Transformers allows the network to aggregate the high dimensional feature and provide global information modeling. This mechanism provides better segmentation performance compared with traditional methods. Furthermore, we encode this generator into the GAN based architecture so that the discriminator network in the GAN can classify the credibility of the generated segmentation masks compared with the real masks coming from human (expert) annotations. This allows us to extract the high dimensional topology information in the mask for biomedical image segmentation and provide more reliable segmentation results. Our model achieved a high dice coefficient of 0.9433, recall of 0.9515, and precision of 0.9376 and outperformed other Transformer based approaches.
Meta Optimal Transport
Jun 10, 2022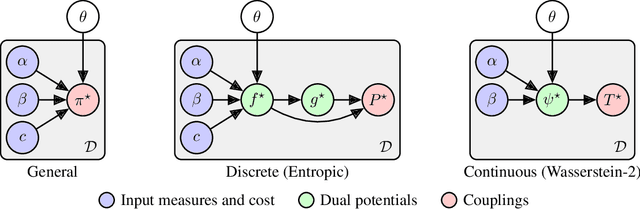


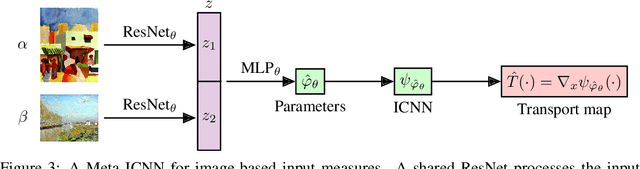
We study the use of amortized optimization to predict optimal transport (OT) maps from the input measures, which we call Meta OT. This helps repeatedly solve similar OT problems between different measures by leveraging the knowledge and information present from past problems to rapidly predict and solve new problems. Otherwise, standard methods ignore the knowledge of the past solutions and suboptimally re-solve each problem from scratch. Meta OT models surpass the standard convergence rates of log-Sinkhorn solvers in the discrete setting and convex potentials in the continuous setting. We improve the computational time of standard OT solvers by multiple orders of magnitude in discrete and continuous transport settings between images, spherical data, and color palettes. Our source code is available at http://github.com/facebookresearch/meta-ot.
Toward an ImageNet Library of Functions for Global Optimization Benchmarking
Jun 27, 2022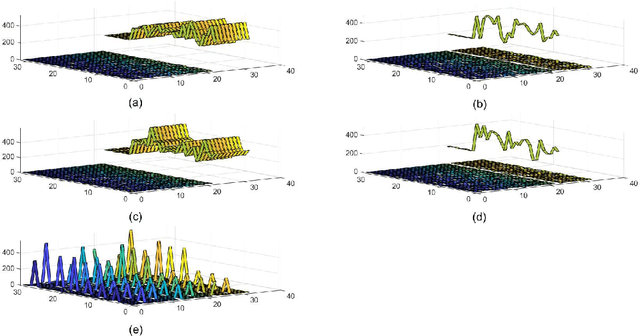
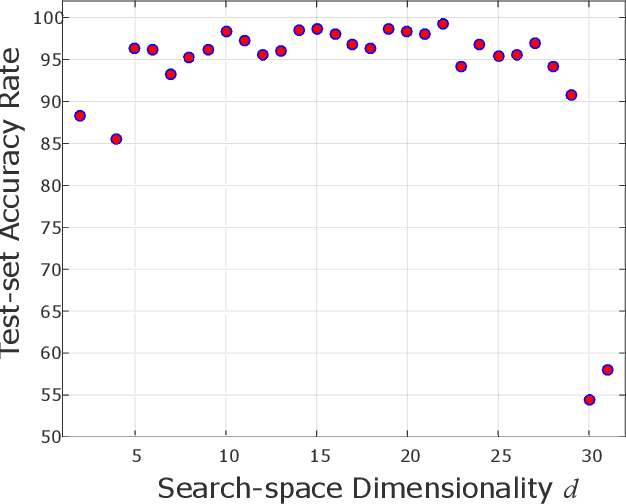
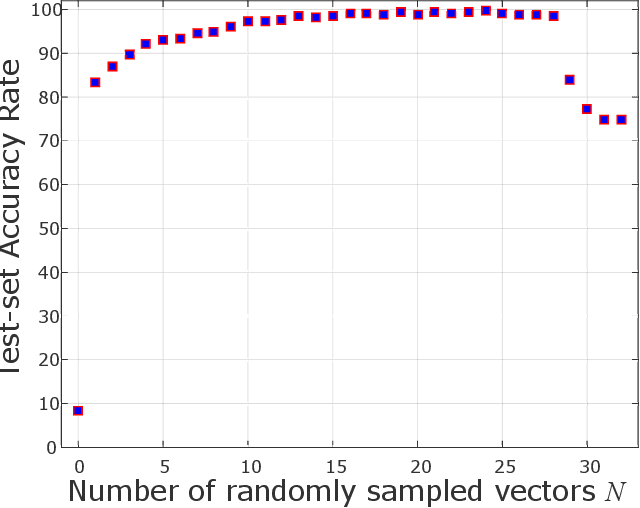
Knowledge of search-landscape features of BlackBox Optimization (BBO) problems offers valuable information in light of the Algorithm Selection and/or Configuration problems. Exploratory Landscape Analysis (ELA) models have gained success in identifying predefined human-derived features and in facilitating portfolio selectors to address those challenges. Unlike ELA approaches, the current study proposes to transform the identification problem into an image recognition problem, with a potential to detect conception-free, machine-driven landscape features. To this end, we introduce the notion of Landscape Images, which enables us to generate imagery instances per a benchmark function, and then target the classification challenge over a diverse generalized dataset of functions. We address it as a supervised multi-class image recognition problem and apply basic artificial neural network models to solve it. The efficacy of our approach is numerically validated on the noise free BBOB and IOHprofiler benchmarking suites. This evident successful learning is another step toward automated feature extraction and local structure deduction of BBO problems. By using this definition of landscape images, and by capitalizing on existing capabilities of image recognition algorithms, we foresee the construction of an ImageNet-like library of functions for training generalized detectors that rely on machine-driven features.