 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeVaLM: A Multi-Observer Eye-Tracking Benchmark for Evaluating Clinical Realism in AI-Generated X-Rays
Apr 13, 2026We introduce GazeVaLM, a public eye-tracking dataset for studying clinical perception during chest radiograph authenticity assessment. The dataset comprises 960 gaze recordings from 16 expert radiologists interpreting 30 real and 30 synthetic chest X-rays (generated by diffusion based generative AI) under two conditions: diagnostic assessment and real-fake classification (Visual Turing test). For each image-observer pair, we provide raw gaze samples, fixation maps, scanpaths, saliency density maps, structured diagnostic labels, and authenticity judgments. We extend the protocol to 6 state-of-the-art multimodal LLMs, releasing their predicted diagnoses, authenticity labels, and confidence scores under matched conditions - enabling direct human-AI comparison at both decision and uncertainty levels. We further provide analyses of gaze agreement, inter-observer consistency, and benchmarking of radiologists versus LLMs in diagnostic accuracy and authenticity detection. GazeVaLM supports research in gaze modeling, clinical decision-making, human-AI comparison, generative image realism assessment, and uncertainty quantification. By jointly releasing visual attention data, clinical labels, and model predictions, we aim to facilitate reproducible research on how experts and AI systems perceive, interpret, and evaluate medical images. The dataset is available at https://huggingface.co/datasets/davidcwong/GazeVaLM.
Shifts in Doctors' Eye Movements Between Real and AI-Generated Medical Images
Apr 21, 2025Eye-tracking analysis plays a vital role in medical imaging, providing key insights into how radiologists visually interpret and diagnose clinical cases. In this work, we first analyze radiologists' attention and agreement by measuring the distribution of various eye-movement patterns, including saccades direction, amplitude, and their joint distribution. These metrics help uncover patterns in attention allocation and diagnostic strategies. Furthermore, we investigate whether and how doctors' gaze behavior shifts when viewing authentic (Real) versus deep-learning-generated (Fake) images. To achieve this, we examine fixation bias maps, focusing on first, last, short, and longest fixations independently, along with detailed saccades patterns, to quantify differences in gaze distribution and visual saliency between authentic and synthetic images.
Eyes Tell the Truth: GazeVal Highlights Shortcomings of Generative AI in Medical Imaging
Mar 26, 2025



The demand for high-quality synthetic data for model training and augmentation has never been greater in medical imaging. However, current evaluations predominantly rely on computational metrics that fail to align with human expert recognition. This leads to synthetic images that may appear realistic numerically but lack clinical authenticity, posing significant challenges in ensuring the reliability and effectiveness of AI-driven medical tools. To address this gap, we introduce GazeVal, a practical framework that synergizes expert eye-tracking data with direct radiological evaluations to assess the quality of synthetic medical images. GazeVal leverages gaze patterns of radiologists as they provide a deeper understanding of how experts perceive and interact with synthetic data in different tasks (i.e., diagnostic or Turing tests). Experiments with sixteen radiologists revealed that 96.6% of the generated images (by the most recent state-of-the-art AI algorithm) were identified as fake, demonstrating the limitations of generative AI in producing clinically accurate images.
Liver Cirrhosis Stage Estimation from MRI with Deep Learning
Feb 23, 2025We present an end-to-end deep learning framework for automated liver cirrhosis stage estimation from multi-sequence MRI. Cirrhosis is the severe scarring (fibrosis) of the liver and a common endpoint of various chronic liver diseases. Early diagnosis is vital to prevent complications such as decompensation and cancer, which significantly decreases life expectancy. However, diagnosing cirrhosis in its early stages is challenging, and patients often present with life-threatening complications. Our approach integrates multi-scale feature learning with sequence-specific attention mechanisms to capture subtle tissue variations across cirrhosis progression stages. Using CirrMRI600+, a large-scale publicly available dataset of 628 high-resolution MRI scans from 339 patients, we demonstrate state-of-the-art performance in three-stage cirrhosis classification. Our best model achieves 72.8% accuracy on T1W and 63.8% on T2W sequences, significantly outperforming traditional radiomics-based approaches. Through extensive ablation studies, we show that our architecture effectively learns stage-specific imaging biomarkers. We establish new benchmarks for automated cirrhosis staging and provide insights for developing clinically applicable deep learning systems. The source code will be available at https://github.com/JunZengz/CirrhosisStage.
A Novel Momentum-Based Deep Learning Techniques for Medical Image Classification and Segmentation
Aug 11, 2024



Accurately segmenting different organs from medical images is a critical prerequisite for computer-assisted diagnosis and intervention planning. This study proposes a deep learning-based approach for segmenting various organs from CT and MRI scans and classifying diseases. Our study introduces a novel technique integrating momentum within residual blocks for enhanced training dynamics in medical image analysis. We applied our method in two distinct tasks: segmenting liver, lung, & colon data and classifying abdominal pelvic CT and MRI scans. The proposed approach has shown promising results, outperforming state-of-the-art methods on publicly available benchmarking datasets. For instance, in the lung segmentation dataset, our approach yielded significant enhancements over the TransNetR model, including a 5.72% increase in dice score, a 5.04% improvement in mean Intersection over Union (mIoU), an 8.02% improvement in recall, and a 4.42% improvement in precision. Hence, incorporating momentum led to state-of-the-art performance in both segmentation and classification tasks, representing a significant advancement in the field of medical imaging.
MDNet: Multi-Decoder Network for Abdominal CT Organs Segmentation
May 10, 2024



Accurate segmentation of organs from abdominal CT scans is essential for clinical applications such as diagnosis, treatment planning, and patient monitoring. To handle challenges of heterogeneity in organ shapes, sizes, and complex anatomical relationships, we propose a \textbf{\textit{\ac{MDNet}}}, an encoder-decoder network that uses the pre-trained \textit{MiT-B2} as the encoder and multiple different decoder networks. Each decoder network is connected to a different part of the encoder via a multi-scale feature enhancement dilated block. With each decoder, we increase the depth of the network iteratively and refine segmentation masks, enriching feature maps by integrating previous decoders' feature maps. To refine the feature map further, we also utilize the predicted masks from the previous decoder to the current decoder to provide spatial attention across foreground and background regions. MDNet effectively refines the segmentation mask with a high dice similarity coefficient (DSC) of 0.9013 and 0.9169 on the Liver Tumor segmentation (LiTS) and MSD Spleen datasets. Additionally, it reduces Hausdorff distance (HD) to 3.79 for the LiTS dataset and 2.26 for the spleen segmentation dataset, underscoring the precision of MDNet in capturing the complex contours. Moreover, \textit{\ac{MDNet}} is more interpretable and robust compared to the other baseline models.
CT Liver Segmentation via PVT-based Encoding and Refined Decoding
Jan 17, 2024


Accurate liver segmentation from CT scans is essential for computer-aided diagnosis and treatment planning. Recently, Vision Transformers achieved a competitive performance in computer vision tasks compared to convolutional neural networks due to their exceptional ability to learn global representations. However, they often struggle with scalability, memory constraints, and computational inefficiency, particularly in handling high-resolution medical images. To overcome scalability and efficiency issues, we propose a novel deep learning approach, \textit{\textbf{PVTFormer}}, that is built upon a pretrained pyramid vision transformer (PVT v2) combined with advanced residual upsampling and decoder block. By integrating a refined feature channel approach with hierarchical decoding strategy, PVTFormer generates high quality segmentation masks by enhancing semantic features. Rigorous evaluation of the proposed method on Liver Tumor Segmentation Benchmark (LiTS) 2017 demonstrates that our proposed architecture not only achieves a high dice coefficient of 86.78\%, mIoU of 78.46\%, but also obtains a low HD of 3.50. The results underscore PVTFormer's efficacy in setting a new benchmark for state-of-the-art liver segmentation methods. The source code of the proposed PVTFormer is available at \url{https://github.com/DebeshJha/PVTFormer}.
Transformer based Generative Adversarial Network for Liver Segmentation
May 28, 2022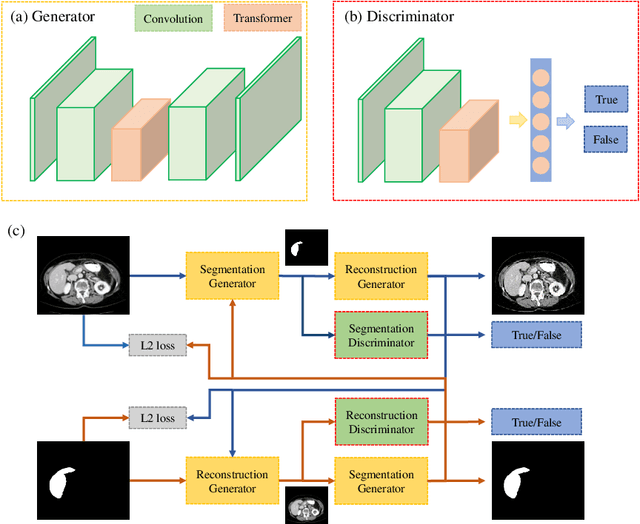

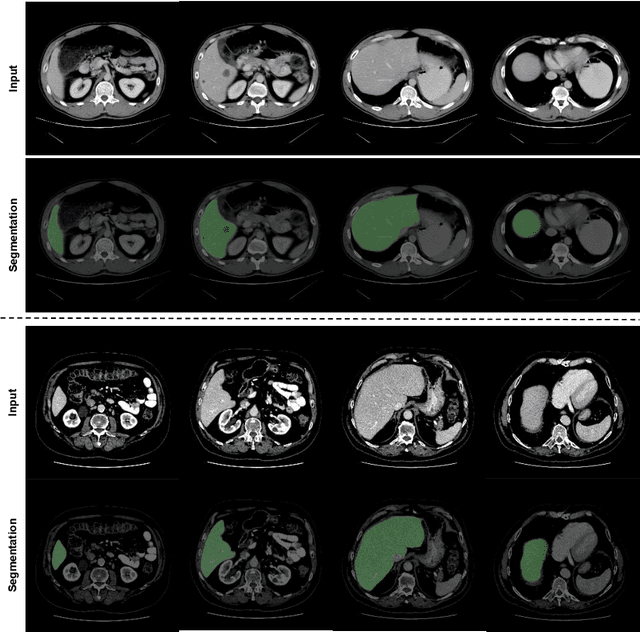
Automated liver segmentation from radiology scans (CT, MRI) can improve surgery and therapy planning and follow-up assessment in addition to conventional use for diagnosis and prognosis. Although convolutional neural networks (CNNs) have become the standard image segmentation tasks, more recently this has started to change towards Transformers based architectures because Transformers are taking advantage of capturing long range dependence modeling capability in signals, so called attention mechanism. In this study, we propose a new segmentation approach using a hybrid approach combining the Transformer(s) with the Generative Adversarial Network (GAN) approach. The premise behind this choice is that the self-attention mechanism of the Transformers allows the network to aggregate the high dimensional feature and provide global information modeling. This mechanism provides better segmentation performance compared with traditional methods. Furthermore, we encode this generator into the GAN based architecture so that the discriminator network in the GAN can classify the credibility of the generated segmentation masks compared with the real masks coming from human (expert) annotations. This allows us to extract the high dimensional topology information in the mask for biomedical image segmentation and provide more reliable segmentation results. Our model achieved a high dice coefficient of 0.9433, recall of 0.9515, and precision of 0.9376 and outperformed other Transformer based approaches.