 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Speaker Error Correction using Acoustic-conditioned Large Language Models
Jan 14, 2025



Speaker Diarization (SD) is a crucial component of modern end-to-end ASR pipelines. Traditional SD systems, which are typically audio-based and operate independently of ASR, often introduce speaker errors, particularly during speaker transitions and overlapping speech. Recently, language models including fine-tuned large language models (LLMs) have shown to be effective as a second-pass speaker error corrector by leveraging lexical context in the transcribed output. In this work, we introduce a novel acoustic conditioning approach to provide more fine-grained information from the acoustic diarizer to the LLM. We also show that a simpler constrained decoding strategy reduces LLM hallucinations, while avoiding complicated post-processing. Our approach significantly reduces the speaker error rates by 24-43% across Fisher, Callhome, and RT03-CTS datasets, compared to the first-pass Acoustic SD.
Learning from human perception to improve automatic speaker verification in style-mismatched conditions
Jun 28, 2022
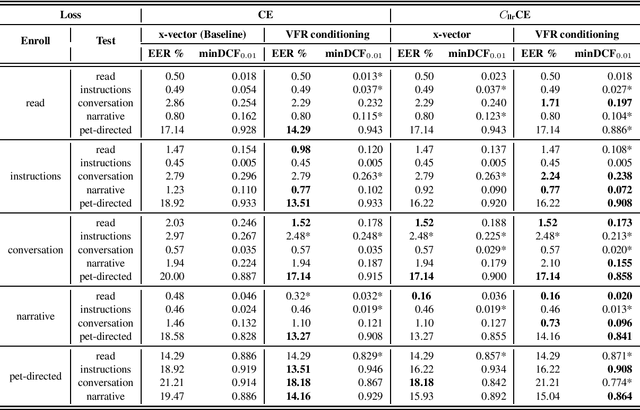
Our prior experiments show that humans and machines seem to employ different approaches to speaker discrimination, especially in the presence of speaking style variability. The experiments examined read versus conversational speech. Listeners focused on speaker-specific idiosyncrasies while "telling speakers together", and on relative distances in a shared acoustic space when "telling speakers apart". However, automatic speaker verification (ASV) systems use the same loss function irrespective of target or non-target trials. To improve ASV performance in the presence of style variability, insights learnt from human perception are used to design a new training loss function that we refer to as "CllrCE loss". CllrCE loss uses both speaker-specific idiosyncrasies and relative acoustic distances between speakers to train the ASV system. When using the UCLA speaker variability database, in the x-vector and conditioning setups, CllrCE loss results in significant relative improvements in EER by 1-66%, and minDCF by 1-31% and 1-56%, respectively, when compared to the x-vector baseline. Using the SITW evaluation tasks, which involve different conversational speech tasks, the proposed loss combined with self-attention conditioning results in significant relative improvements in EER by 2-5% and minDCF by 6-12% over baseline. In the SITW case, performance improvements were consistent only with conditioning.
Attention-based conditioning methods using variable frame rate for style-robust speaker verification
Jun 28, 2022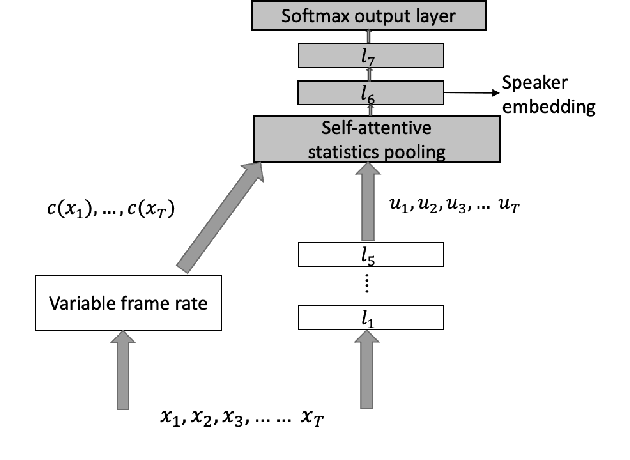
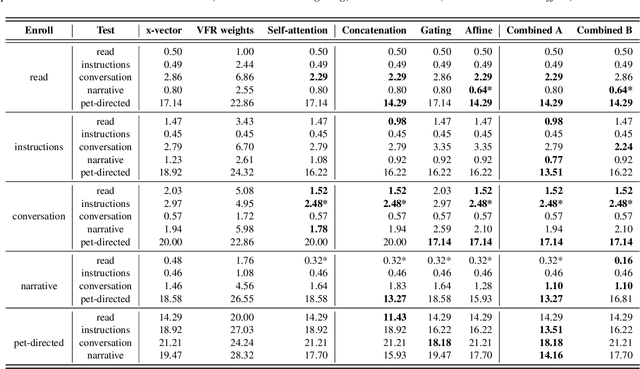
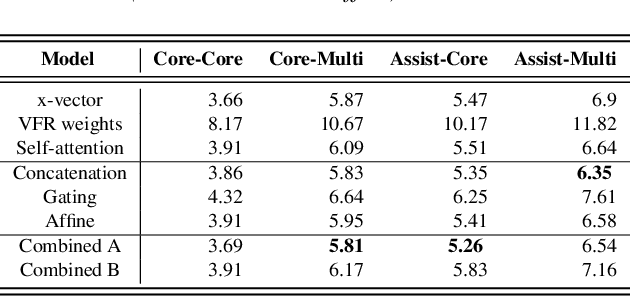
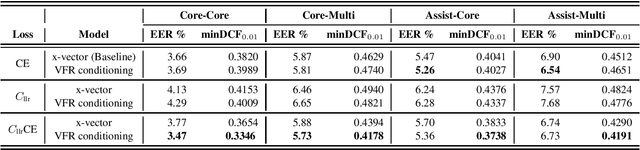
We propose an approach to extract speaker embeddings that are robust to speaking style variations in text-independent speaker verification. Typically, speaker embedding extraction includes training a DNN for speaker classification and using the bottleneck features as speaker representations. Such a network has a pooling layer to transform frame-level to utterance-level features by calculating statistics over all utterance frames, with equal weighting. However, self-attentive embeddings perform weighted pooling such that the weights correspond to the importance of the frames in a speaker classification task. Entropy can capture acoustic variability due to speaking style variations. Hence, an entropy-based variable frame rate vector is proposed as an external conditioning vector for the self-attention layer to provide the network with information that can address style effects. This work explores five different approaches to conditioning. The best conditioning approach, concatenation with gating, provided statistically significant improvements over the x-vector baseline in 12/23 tasks and was the same as the baseline in 11/23 tasks when using the UCLA speaker variability database. It also significantly outperformed self-attention without conditioning in 9/23 tasks and was worse in 1/23. The method also showed significant improvements in multi-speaker scenarios of SITW.
Sequence-level Confidence Classifier for ASR Utterance Accuracy and Application to Acoustic Models
Jun 30, 2021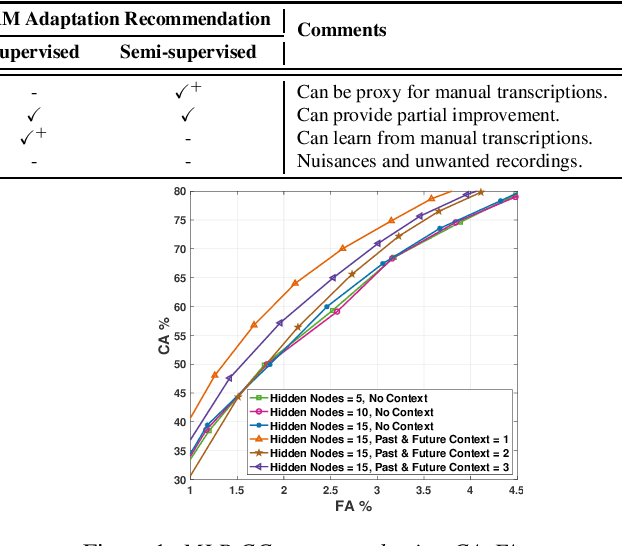
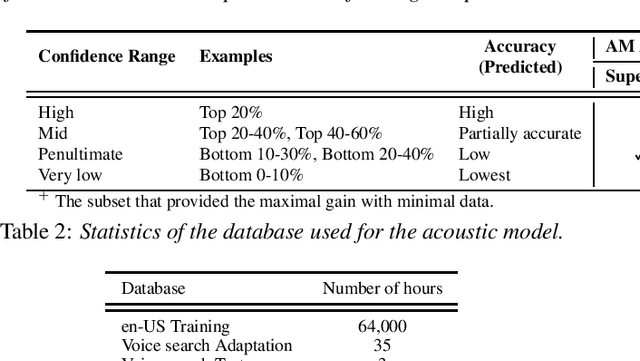
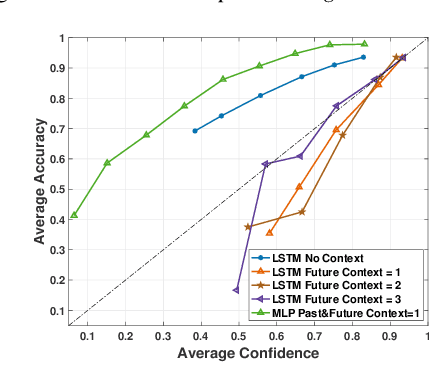

Scores from traditional confidence classifiers (CCs) in automatic speech recognition (ASR) systems lack universal interpretation and vary with updates to the underlying confidence or acoustic models (AMs). In this work, we build interpretable confidence scores with an objective to closely align with ASR accuracy. We propose a new sequence-level CC with a richer context providing CC scores highly correlated with ASR accuracy and scores stable across CC updates. Hence, expanding CC applications. Recently, AM customization has gained traction with the widespread use of unified models. Conventional adaptation strategies that customize AM expect well-matched data for the target domain with gold-standard transcriptions. We propose a cost-effective method of using CC scores to select an optimal adaptation data set, where we maximize ASR gains from minimal data. We study data in various confidence ranges and optimally choose data for AM adaptation with KL-Divergence regularization. On the Microsoft voice search task, data selection for supervised adaptation using the sequence-level confidence scores achieves word error rate reduction (WERR) of 8.5% for row-convolution LSTM (RC-LSTM) and 5.2% for latency-controlled bidirectional LSTM (LC-BLSTM). In the semi-supervised case, with ASR hypotheses as labels, our method provides WERR of 5.9% and 2.8% for RC-LSTM and LC-BLSTM, respectively.
Bi-APC: Bidirectional Autoregressive Predictive Coding for Unsupervised Pre-training and Its Application to Children's ASR
Feb 12, 2021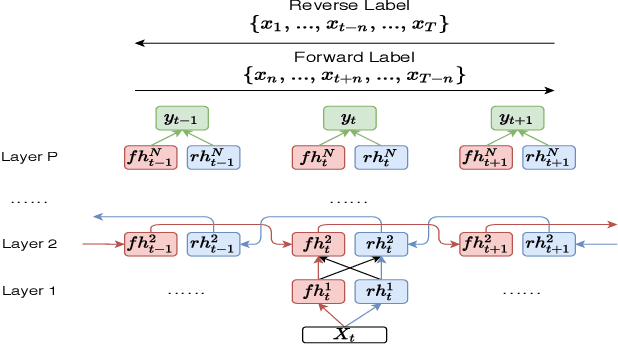
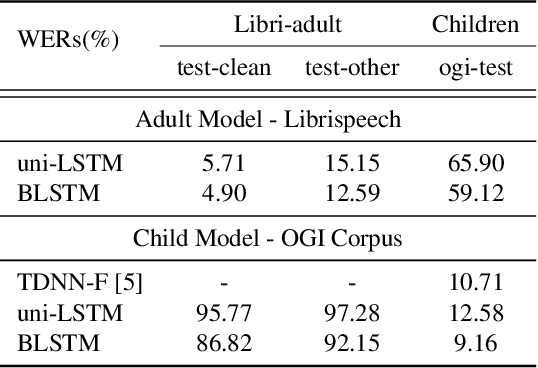
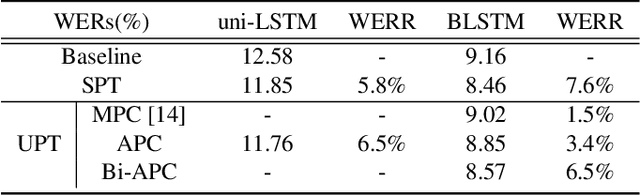
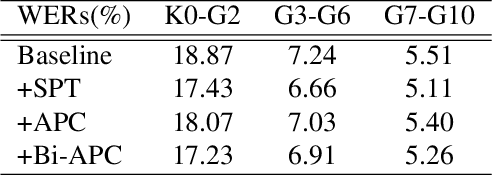
We present a bidirectional unsupervised model pre-training (UPT) method and apply it to children's automatic speech recognition (ASR). An obstacle to improving child ASR is the scarcity of child speech databases. A common approach to alleviate this problem is model pre-training using data from adult speech. Pre-training can be done using supervised (SPT) or unsupervised methods, depending on the availability of annotations. Typically, SPT performs better. In this paper, we focus on UPT to address the situations when pre-training data are unlabeled. Autoregressive predictive coding (APC), a UPT method, predicts frames from only one direction, limiting its use to uni-directional pre-training. Conventional bidirectional UPT methods, however, predict only a small portion of frames. To extend the benefits of APC to bi-directional pre-training, Bi-APC is proposed. We then use adaptation techniques to transfer knowledge learned from adult speech (using the Librispeech corpus) to child speech (OGI Kids corpus). LSTM-based hybrid systems are investigated. For the uni-LSTM structure, APC obtains similar WER improvements to SPT over the baseline. When applied to BLSTM, however, APC is not as competitive as SPT, but our proposed Bi-APC has comparable improvements to SPT.
Speaker discrimination in humans and machines: Effects of speaking style variability
Aug 08, 2020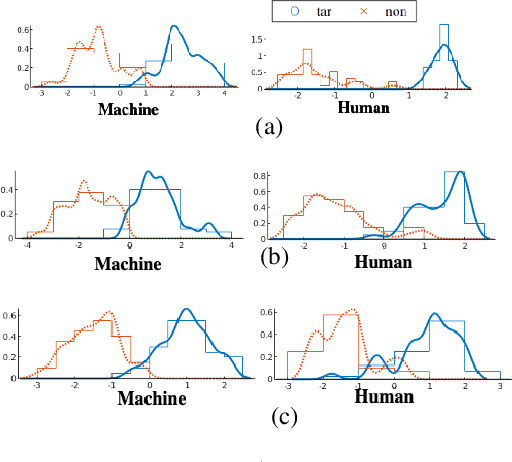
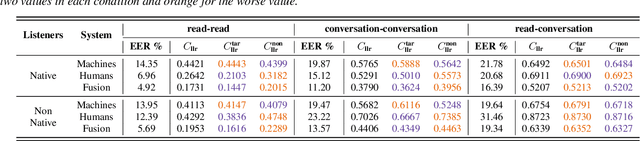
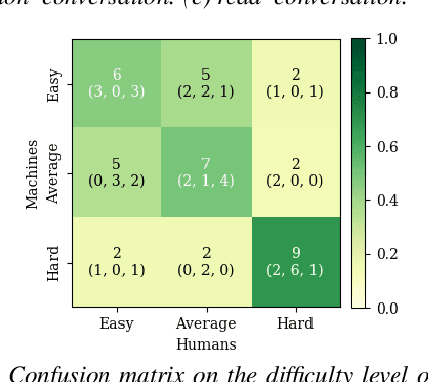
Does speaking style variation affect humans' ability to distinguish individuals from their voices? How do humans compare with automatic systems designed to discriminate between voices? In this paper, we attempt to answer these questions by comparing human and machine speaker discrimination performance for read speech versus casual conversations. Thirty listeners were asked to perform a same versus different speaker task. Their performance was compared to a state-of-the-art x-vector/PLDA-based automatic speaker verification system. Results showed that both humans and machines performed better with style-matched stimuli, and human performance was better when listeners were native speakers of American English. Native listeners performed better than machines in the style-matched conditions (EERs of 6.96% versus 14.35% for read speech, and 15.12% versus 19.87%, for conversations), but for style-mismatched conditions, there was no significant difference between native listeners and machines. In all conditions, fusing human responses with machine results showed improvements compared to each alone, suggesting that humans and machines have different approaches to speaker discrimination tasks. Differences in the approaches were further confirmed by examining results for individual speakers which showed that the perception of distinct and confused speakers differed between human listeners and machines.
Variable frame rate-based data augmentation to handle speaking-style variability for automatic speaker verification
Aug 08, 2020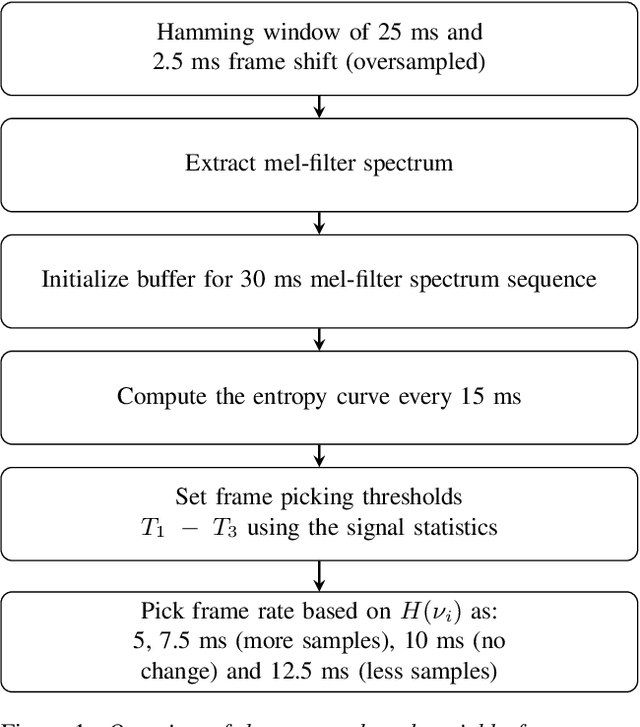
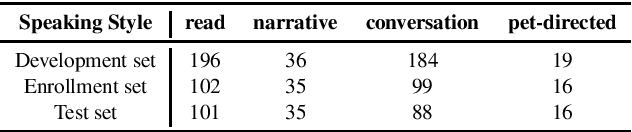
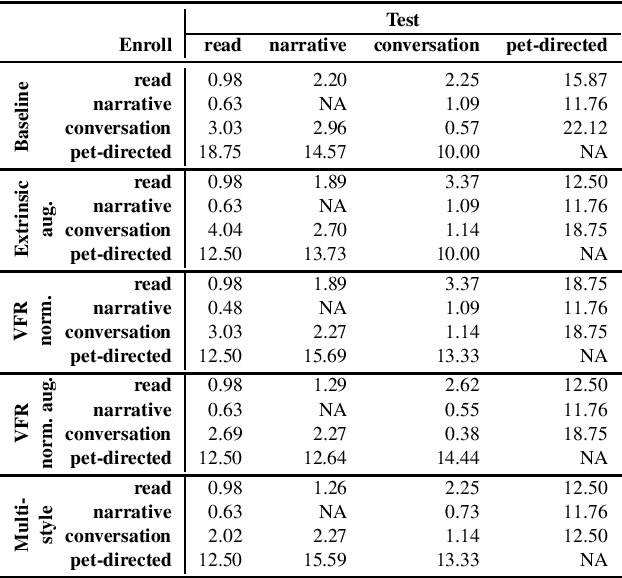
The effects of speaking-style variability on automatic speaker verification were investigated using the UCLA Speaker Variability database which comprises multiple speaking styles per speaker. An x-vector/PLDA (probabilistic linear discriminant analysis) system was trained with the SRE and Switchboard databases with standard augmentation techniques and evaluated with utterances from the UCLA database. The equal error rate (EER) was low when enrollment and test utterances were of the same style (e.g., 0.98% and 0.57% for read and conversational speech, respectively), but it increased substantially when styles were mismatched between enrollment and test utterances. For instance, when enrolled with conversation utterances, the EER increased to 3.03%, 2.96% and 22.12% when tested on read, narrative, and pet-directed speech, respectively. To reduce the effect of style mismatch, we propose an entropy-based variable frame rate technique to artificially generate style-normalized representations for PLDA adaptation. The proposed system significantly improved performance. In the aforementioned conditions, the EERs improved to 2.69% (conversation -- read), 2.27% (conversation -- narrative), and 18.75% (pet-directed -- read). Overall, the proposed technique performed comparably to multi-style PLDA adaptation without the need for training data in different speaking styles per speaker.
Exploring the Use of an Unsupervised Autoregressive Model as a Shared Encoder for Text-Dependent Speaker Verification
Aug 08, 2020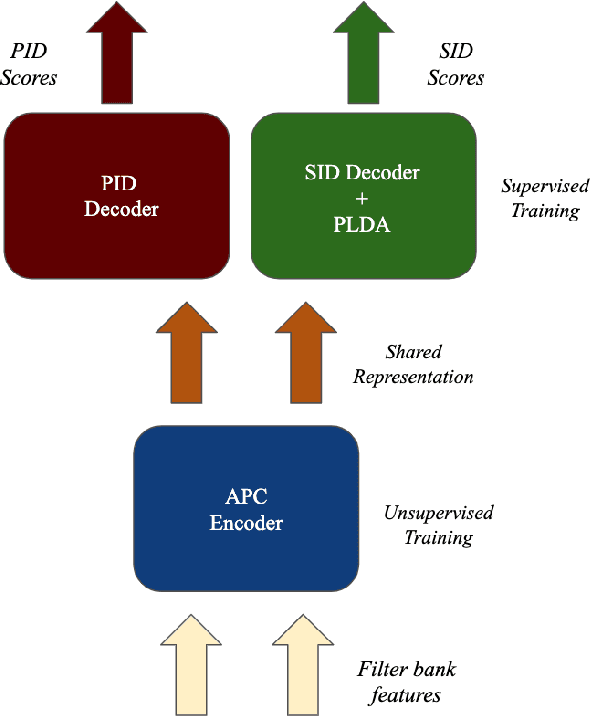
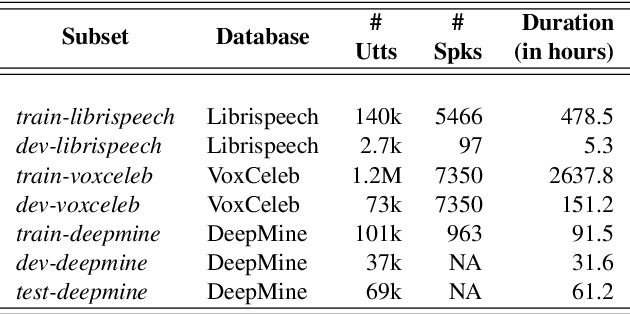
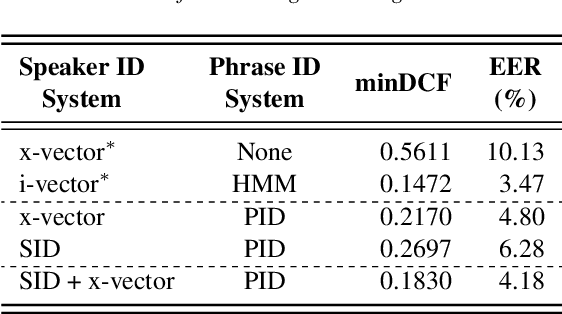
In this paper, we propose a novel way of addressing text-dependent automatic speaker verification (TD-ASV) by using a shared-encoder with task-specific decoders. An autoregressive predictive coding (APC) encoder is pre-trained in an unsupervised manner using both out-of-domain (LibriSpeech, VoxCeleb) and in-domain (DeepMine) unlabeled datasets to learn generic, high-level feature representation that encapsulates speaker and phonetic content. Two task-specific decoders were trained using labeled datasets to classify speakers (SID) and phrases (PID). Speaker embeddings extracted from the SID decoder were scored using a PLDA. SID and PID systems were fused at the score level. There is a 51.9% relative improvement in minDCF for our system compared to the fully supervised x-vector baseline on the cross-lingual DeepMine dataset. However, the i-vector/HMM method outperformed the proposed APC encoder-decoder system. A fusion of the x-vector/PLDA baseline and the SID/PLDA scores prior to PID fusion further improved performance by 15% indicating complementarity of the proposed approach to the x-vector system. We show that the proposed approach can leverage from large, unlabeled, data-rich domains, and learn speech patterns independent of downstream tasks. Such a system can provide competitive performance in domain-mismatched scenarios where test data is from data-scarce domains.