 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
Feb 25, 2024
Trajectory representation learning plays a pivotal role in supporting various downstream tasks. Traditional methods in order to filter the noise in GPS trajectories tend to focus on routing-based methods used to simplify the trajectories. However, this approach ignores the motion details contained in the GPS data, limiting the representation capability of trajectory representation learning. To fill this gap, we propose a novel representation learning framework that Joint GPS and Route Modelling based on self-supervised technology, namely JGRM. We consider GPS trajectory and route as the two modes of a single movement observation and fuse information through inter-modal information interaction. Specifically, we develop two encoders, each tailored to capture representations of route and GPS trajectories respectively. The representations from the two modalities are fed into a shared transformer for inter-modal information interaction. Eventually, we design three self-supervised tasks to train the model. We validate the effectiveness of the proposed method on two real datasets based on extensive experiments. The experimental results demonstrate that JGRM outperforms existing methods in both road segment representation and trajectory representation tasks. Our source code is available at Anonymous Github.
MultiContrievers: Analysis of Dense Retrieval Representations
Feb 24, 2024Dense retrievers compress source documents into (possibly lossy) vector representations, yet there is little analysis of what information is lost versus preserved, and how it affects downstream tasks. We conduct the first analysis of the information captured by dense retrievers compared to the language models they are based on (e.g., BERT versus Contriever). We use 25 MultiBert checkpoints as randomized initialisations to train MultiContrievers, a set of 25 contriever models. We test whether specific pieces of information -- such as gender and occupation -- can be extracted from contriever vectors of wikipedia-like documents. We measure this extractability via information theoretic probing. We then examine the relationship of extractability to performance and gender bias, as well as the sensitivity of these results to many random initialisations and data shuffles. We find that (1) contriever models have significantly increased extractability, but extractability usually correlates poorly with benchmark performance 2) gender bias is present, but is not caused by the contriever representations 3) there is high sensitivity to both random initialisation and to data shuffle, suggesting that future retrieval research should test across a wider spread of both.
A Heterogeneous Dynamic Convolutional Neural Network for Image Super-resolution
Feb 24, 2024Convolutional neural networks can automatically learn features via deep network architectures and given input samples. However, robustness of obtained models may have challenges in varying scenes. Bigger differences of a network architecture are beneficial to extract more complementary structural information to enhance robustness of an obtained super-resolution model. In this paper, we present a heterogeneous dynamic convolutional network in image super-resolution (HDSRNet). To capture more information, HDSRNet is implemented by a heterogeneous parallel network. The upper network can facilitate more contexture information via stacked heterogeneous blocks to improve effects of image super-resolution. Each heterogeneous block is composed of a combination of a dilated, dynamic, common convolutional layers, ReLU and residual learning operation. It can not only adaptively adjust parameters, according to different inputs, but also prevent long-term dependency problem. The lower network utilizes a symmetric architecture to enhance relations of different layers to mine more structural information, which is complementary with a upper network for image super-resolution. The relevant experimental results show that the proposed HDSRNet is effective to deal with image resolving. The code of HDSRNet can be obtained at https://github.com/hellloxiaotian/HDSRNet.
Social Media as a Sensor: Analyzing Twitter Data for Breast Cancer Medication Effects Using Natural Language Processing
Feb 26, 2024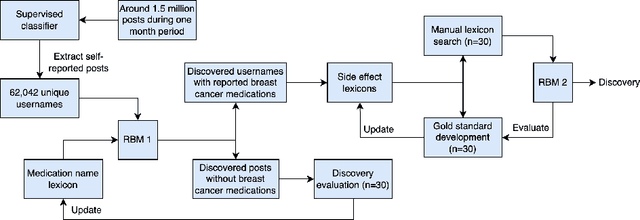
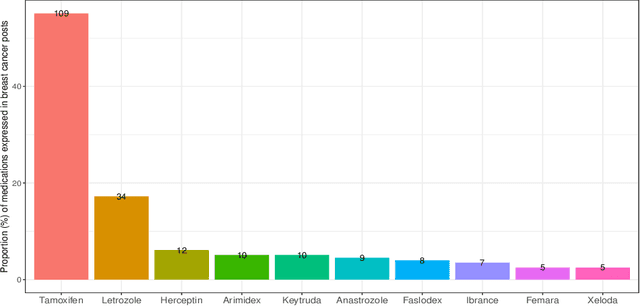
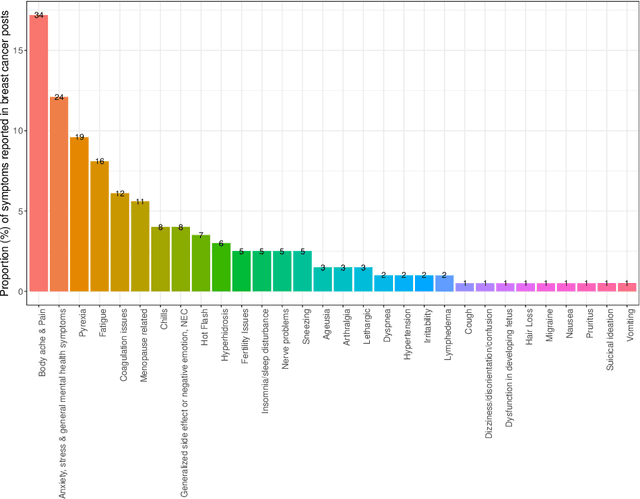
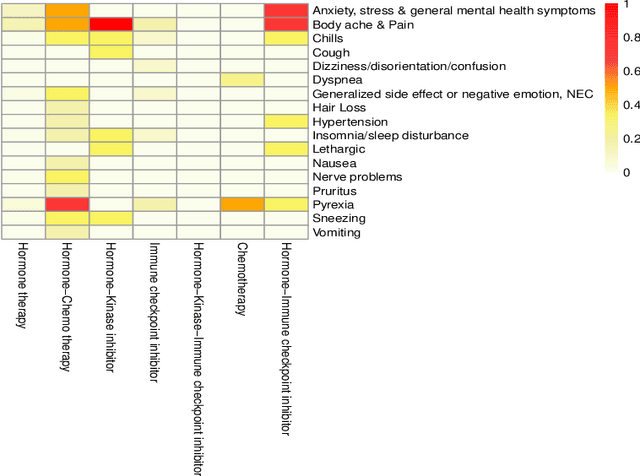
Breast cancer is a significant public health concern and is the leading cause of cancer-related deaths among women. Despite advances in breast cancer treatments, medication non-adherence remains a major problem. As electronic health records do not typically capture patient-reported outcomes that may reveal information about medication-related experiences, social media presents an attractive resource for enhancing our understanding of the patients' treatment experiences. In this paper, we developed natural language processing (NLP) based methodologies to study information posted by an automatically curated breast cancer cohort from social media. We employed a transformer-based classifier to identify breast cancer patients/survivors on X (Twitter) based on their self-reported information, and we collected longitudinal data from their profiles. We then designed a multi-layer rule-based model to develop a breast cancer therapy-associated side effect lexicon and detect patterns of medication usage and associated side effects among breast cancer patients. 1,454,637 posts were available from 583,962 unique users, of which 62,042 were detected as breast cancer members using our transformer-based model. 198 cohort members mentioned breast cancer medications with tamoxifen as the most common. Our side effect lexicon identified well-known side effects of hormone and chemotherapy. Furthermore, it discovered a subject feeling towards cancer and medications, which may suggest a pre-clinical phase of side effects or emotional distress. This analysis highlighted not only the utility of NLP techniques in unstructured social media data to identify self-reported breast cancer posts, medication usage patterns, and treatment side effects but also the richness of social data on such clinical questions.
Understanding Iterative Combinatorial Auction Designs via Multi-Agent Reinforcement Learning
Feb 29, 2024Iterative combinatorial auctions are widely used in high stakes settings such as spectrum auctions. Such auctions can be hard to understand analytically, making it difficult for bidders to determine how to behave and for designers to optimize auction rules to ensure desirable outcomes such as high revenue or welfare. In this paper, we investigate whether multi-agent reinforcement learning (MARL) algorithms can be used to understand iterative combinatorial auctions, given that these algorithms have recently shown empirical success in several other domains. We find that MARL can indeed benefit auction analysis, but that deploying it effectively is nontrivial. We begin by describing modelling decisions that keep the resulting game tractable without sacrificing important features such as imperfect information or asymmetry between bidders. We also discuss how to navigate pitfalls of various MARL algorithms, how to overcome challenges in verifying convergence, and how to generate and interpret multiple equilibria. We illustrate the promise of our resulting approach by using it to evaluate a specific rule change to a clock auction, finding substantially different auction outcomes due to complex changes in bidders' behavior.
Prompting Explicit and Implicit Knowledge for Multi-hop Question Answering Based on Human Reading Process
Feb 29, 2024Pre-trained language models (PLMs) leverage chains-of-thought (CoT) to simulate human reasoning and inference processes, achieving proficient performance in multi-hop QA. However, a gap persists between PLMs' reasoning abilities and those of humans when tackling complex problems. Psychological studies suggest a vital connection between explicit information in passages and human prior knowledge during reading. Nevertheless, current research has given insufficient attention to linking input passages and PLMs' pre-training-based knowledge from the perspective of human cognition studies. In this study, we introduce a \textbf{P}rompting \textbf{E}xplicit and \textbf{I}mplicit knowledge (PEI) framework, which uses prompts to connect explicit and implicit knowledge, aligning with human reading process for multi-hop QA. We consider the input passages as explicit knowledge, employing them to elicit implicit knowledge through unified prompt reasoning. Furthermore, our model incorporates type-specific reasoning via prompts, a form of implicit knowledge. Experimental results show that PEI performs comparably to the state-of-the-art on HotpotQA. Ablation studies confirm the efficacy of our model in bridging and integrating explicit and implicit knowledge.
Feature boosting with efficient attention for scene parsing
Feb 29, 2024The complexity of scene parsing grows with the number of object and scene classes, which is higher in unrestricted open scenes. The biggest challenge is to model the spatial relation between scene elements while succeeding in identifying objects at smaller scales. This paper presents a novel feature-boosting network that gathers spatial context from multiple levels of feature extraction and computes the attention weights for each level of representation to generate the final class labels. A novel `channel attention module' is designed to compute the attention weights, ensuring that features from the relevant extraction stages are boosted while the others are attenuated. The model also learns spatial context information at low resolution to preserve the abstract spatial relationships among scene elements and reduce computation cost. Spatial attention is subsequently concatenated into a final feature set before applying feature boosting. Low-resolution spatial attention features are trained using an auxiliary task that helps learning a coarse global scene structure. The proposed model outperforms all state-of-the-art models on both the ADE20K and the Cityscapes datasets.
A SOUND APPROACH: Using Large Language Models to generate audio descriptions for egocentric text-audio retrieval
Feb 29, 2024Video databases from the internet are a valuable source of text-audio retrieval datasets. However, given that sound and vision streams represent different "views" of the data, treating visual descriptions as audio descriptions is far from optimal. Even if audio class labels are present, they commonly are not very detailed, making them unsuited for text-audio retrieval. To exploit relevant audio information from video-text datasets, we introduce a methodology for generating audio-centric descriptions using Large Language Models (LLMs). In this work, we consider the egocentric video setting and propose three new text-audio retrieval benchmarks based on the EpicMIR and EgoMCQ tasks, and on the EpicSounds dataset. Our approach for obtaining audio-centric descriptions gives significantly higher zero-shot performance than using the original visual-centric descriptions. Furthermore, we show that using the same prompts, we can successfully employ LLMs to improve the retrieval on EpicSounds, compared to using the original audio class labels of the dataset. Finally, we confirm that LLMs can be used to determine the difficulty of identifying the action associated with a sound.
A Protein Structure Prediction Approach Leveraging Transformer and CNN Integration
Feb 29, 2024Proteins are essential for life, and their structure determines their function. The protein secondary structure is formed by the folding of the protein primary structure, and the protein tertiary structure is formed by the bending and folding of the secondary structure. Therefore, the study of protein secondary structure is very helpful to the overall understanding of protein structure. Although the accuracy of protein secondary structure prediction has continuously improved with the development of machine learning and deep learning, progress in the field of protein structure prediction, unfortunately, remains insufficient to meet the large demand for protein information. Therefore, based on the advantages of deep learning-based methods in feature extraction and learning ability, this paper adopts a two-dimensional fusion deep neural network model, DstruCCN, which uses Convolutional Neural Networks (CCN) and a supervised Transformer protein language model for single-sequence protein structure prediction. The training features of the two are combined to predict the protein Transformer binding site matrix, and then the three-dimensional structure is reconstructed using energy minimization.
Ambisonics Networks -- The Effect Of Radial Functions Regularization
Feb 29, 2024Ambisonics, a popular format of spatial audio, is the spherical harmonic (SH) representation of the plane wave density function of a sound field. Many algorithms operate in the SH domain and utilize the Ambisonics as their input signal. The process of encoding Ambisonics from a spherical microphone array involves dividing by the radial functions, which may amplify noise at low frequencies. This can be overcome by regularization, with the downside of introducing errors to the Ambisonics encoding. This paper aims to investigate the impact of different ways of regularization on Deep Neural Network (DNN) training and performance. Ideally, these networks should be robust to the way of regularization. Simulated data of a single speaker in a room and experimental data from the LOCATA challenge were used to evaluate this robustness on an example algorithm of speaker localization based on the direct-path dominance (DPD) test. Results show that performance may be sensitive to the way of regularization, and an informed approach is proposed and investigated, highlighting the importance of regularization information.